使用yolov3-tiny训练自己的图像数据以及在jetson Nano上的测试
这里写自定义目录标题
- 1. yolov3-tiny简介
- 2 安装darknet
- 3.下载预训练模型yolov3-tiny.weights
- 4. 简单地测试
- 4.1 测试图片
- 4.2 测试实时视频
- 5. 制作自己的数据集
- 5.1 准备数据集
- 5.2 打乱顺序并重命名
- 5.3 数据标注
- 第一种方法:
- 第二种方法:
- 5.4 指定训练集和测试集
- 5.5 指定训练集和测试集的实际路径和标签文件
- 5.6 修改一些必要文件
- 5.6.1 修改data目录下的voc.names
- 5.6.2 修改 cfg目录下的voc.data文件
- 5.6.3 修改 cfg目录下的yolov3-tiny.cfg文件
- 5.6.4 生成预训练模型
- 6.训练
- 7.测试
- 7.1 使用c进行图片检测
- 7.2 使用c进行实时检测
- 7.2 使用python进行图片检测
- 7.3 使用python进行实时检测
1. yolov3-tiny简介
2 安装darknet
首先下载darknet,执行如下命令:
git clone https://github.com/pjreddie/darknet
下载完成后,进入darknet目录,并打开Makefile文件,因为Jetson Nano支持GPU,且已预安装了OPENCV和CUDNN.所以在编译的时候我们需要修改下Makefile文件,如下:将
GPU=0
CUDNN=0
OPENCV=1
OPENMP=0
DEBUG=1
修改为
GPU=1
CUDNN=1
OPENCV=1
OPENMP=0
DEBUG=1
然后执行如下命令进行编译:
$ cd darknet
$ make
此时darkent安装完成.
3.下载预训练模型yolov3-tiny.weights
执行如下命令下载预训练模型:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
等待其下载完成后,会在darknet根目录下看到该预训练模型.
4. 简单地测试
4.1 测试图片
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
4.2 测试实时视频
./darknet detector demo cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.weights
5. 制作自己的数据集
本次训练的目标是为了能够检测出四类不同的物体,即西瓜,手套,电池和鞋,如图所示:
每种物体采集700张,命名方式以数字形式进行命名.
5.1 准备数据集
然后切换到darkent根目录,依次建立如下几个文件夹:
$ cd scripts
$ mkdir -p VOCdevkit && cd VOCdevkit
$ mkdir -p VOC2019 && cd VOC2019
$ mkdir -p Annotations && mkdir -p ImageSets && mkdir -p JPEGImages && mkdir -p labels
建立完之后的目录为:
├── VOCdevkit
│ └── VOC2019
│ ├──── Annotations
│ ├──-── ImageSets
│ ├──-──JPEGImages
│ └─────labels
将采集到的图像全部放入JPEGImages文件夹下.
5.2 打乱顺序并重命名
将JPEGImages文件夹下的图像文件打乱顺序并重新命名.方法是执行如下的python脚本文件:
# -*- coding:utf-8 -*-
import os
import random
class ImageRename():
def __init__(self):
self.path = '/home/jetbot/darknet-master/scripts/VOCdevkit/VOC2019/JPEGImages'#图片所在文件夹
def rename(self):
filelist = os.listdir(self.path)
random.shuffle(filelist)
total_num = len(filelist)
i = 0
for item in filelist:
if item.endswith('.jpg'):
src = os.path.join(os.path.abspath(self.path), item)
dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg')
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
newname = ImageRename()
newname.rename()
5.3 数据标注
该步骤用于对每张图片生成描述文件,我们需要认为指定图片里哪一块区域是我们要检测的物体.每张图片都要以一个xml文件进行描述.数据标注的工具很多,在这里我们选择labelImg.首先安装,在这里该插件对python版本有要求,python2和python3的安装方式不同,选择任意一种即可,区别在于最后执行过程.
若为python3,安装过程如下:
$ sudo apt-get install pyqt5-dev-tools
$ sudo pip3 install lxml
$ cd darknet && mkdir -p software && cd software
$ git clone https://github.com/tzutalin/labelImg.git
$ cd labelImg
$ make all
若为python2,安装过程如下:
$ sudo apt-get install pyqt4-dev-tools
$ sudo pip install lxml
$ cd darknet && mkdir -p software && cd software
$ git clone https://github.com/tzutalin/labelImg.git
$ cd labelImg
$ make all
至此,安装已完成,下面可以运行如下命令打开该软件进行标注了:
若为python3安装,则打开软件的方式为:
$ python3 labelImg.py #打开labelImg
若为python2安装,则打开软件的方式为:
$ python labelImg.py #打开labelImg
软件界面如下:

然后点击左侧的"Open Dir"按键,选择我们存放数据图片的文件夹JPEGImages,如下:
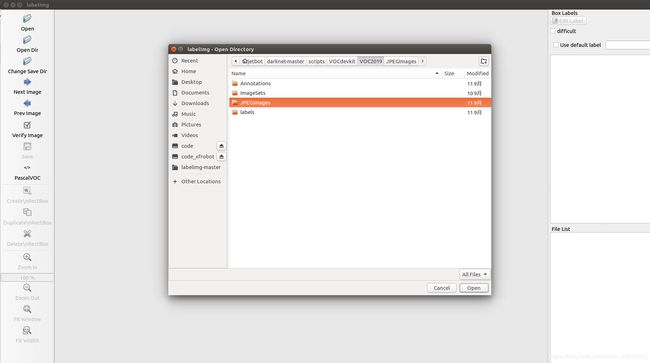 然后点击"Open",之后会出现第一张图片,对于一张图片的标注,一般分如下几个步骤:
然后点击"Open",之后会出现第一张图片,对于一张图片的标注,一般分如下几个步骤:
1)点击左侧的"Create \n RectBox"按键,然后找准我们要识别的物体,从左上角到右下角拖一个矩形,
2) 在弹出的窗口种创建标签,如下图所示,我们需要选择"watermenlon",如果不出现,要手动敲一个,添加进去,并选择,如果图片中有多个待识别的物体,则再此拉矩形框,并选择类别.
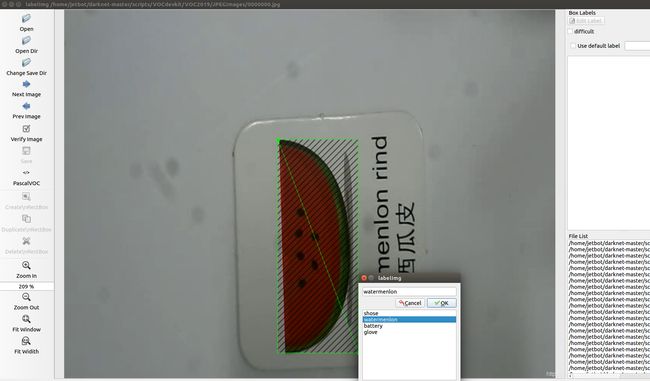
3) 选择完成后,点击保存或者键盘按"ctrl+s",则会在JPEGImages文件夹下生成对应00001.jpg的xml文件00001.xml.
4)按键盘"n"来进入下一张图片.
按照上述步骤依次进行,直到标注完毕.
注: 若在标注过程中,有些图片比较模糊,我们可以不进行标注,直接进入下一张图片.
标注全部完成后,我们会在JPEGImages文件夹中看到jpg文件和xml文件共存,在这这里还需要删除我们之前没有标注的图片,它们不具备任何作用.所以就需要我们进行排查和清除,方法有两个,对于样本较少的,建议第一种:
第一种方法:
打开文件夹,将文件夹水平方向缩小为只能包含两列,即左侧为jpg图片,右侧为xml文件,若某一行出现有两个jpg图片,则删除左边那个,不断向下拖动滑动条,直到尾断即完成了排查和删除.
第二种方法:
执行如下脚本进行排查:
import os
import os.path
h = 0
a = ''
b = ''
dele = []
pathh = "/home/jetbot/darknet-master/scripts/VOCdevkit/VOC2019/JPEGImages"
#dele.remove(1)
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
if h==0:
a = filename
h = 1
elif h==1:
#print(filename)
b = filename
if a[0:a.rfind('.', 1)]==b[0:b.rfind('.', 1)]:
h = 0
#print(filename)
else:
h = 1
dele.append(a)
a = b
else:
print("wa1")
print(dele)
for file in dele:
os.remove(pathh+file)
print("remove"+file+" is OK!")
#再循环一次看看有没有遗漏的单身文件
for filenames in os.walk(pathh):
filenames = list(filenames)
filenames = filenames[2]
for filename in filenames:
print(filename)
if h==0:
a = filename
h = 1
elif h==1:
#print(filename)
b = filename
if a[0:a.rfind('.', 1)]==b[0:b.rfind('.', 1)]:
h = 0
#print(filename)
else:
h = 1
dele.append(a)
a = b
else:
print("wa1")
print (dele)
至此数据标注工作完毕,我们还需要一个小工作,就是将xml文件全部从JPEGImages移出到Annotations文件夹下,方法为:
$ cd JPEGImages
$ mv *.xml ../Annotations/
至此,JPEGImages为全部的图像数据,Annotations中为对应的xml描述文件.
5.4 指定训练集和测试集
我们做好的数据集要一部分作为训练集来训练模型,需要另一部分作为测试集来帮助我们验证模型的可靠性.因此首先要将所有的图像文件随机分配为训练集和测试集.
首先切换到ImageSets目录中,新建Main目录,然后在Main目录中新建两个文本文档train.txt和val.txt.分别用于存放训练集的文件名列表和测试集的文件名列表.
$ cd ImageSets
$ mkdir -p Main && cd Main
$ touch train.txt test.txt
然后执行如下脚本文件来生成训练集和测试集,注意该文件中的2400为我选择的训练集的个数.400默认为测试集.
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/jetbot/darknet-master/scripts/VOCdevkit/VOC2019/JPEGImages/' # 修改为自己的路径
dest='/home/jetbot/darknet-master/scripts/VOCdevkit/VOC2019/ImageSets/Main/train.txt' # 修改为自己的路径
dest2='/home/jetbot/darknet-master/scripts/VOCdevkit/VOC2019/ImageSets/Main/val.txt' # 修改为自己的路径
file_list=os.listdir(source_folder)
train_file=open(dest,'a')
val_file=open(dest2,'a')
count = 0
for file_obj in file_list:
count += 1
file_name,file_extend=os.path.splitext(file_obj)
if(count<2400): # 可以修改这个数字,这个数字用来控制训练集合验证集的分割情况
train_file.write(file_name+'\n')
else :
val_file.write(file_name+'\n')
train_file.close()
val_file.close()
运行完成后可以在train.txt和val.txt文件如下所示:
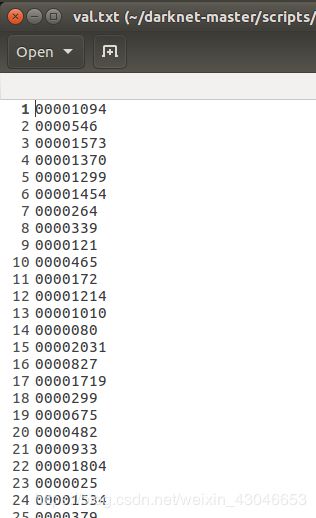
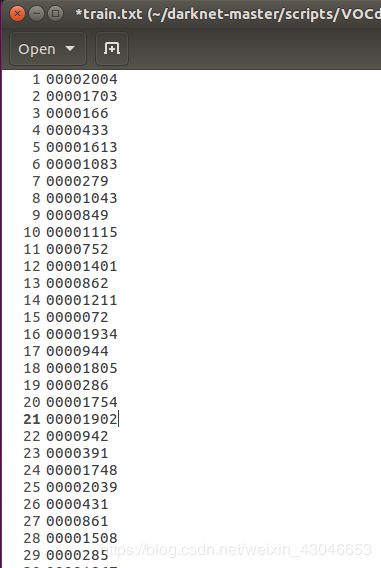
5.5 指定训练集和测试集的实际路径和标签文件
修改script文件夹根目录下的voc_label.py文件,需要修改几处:
- sets=[ (‘2019’, ‘train’), (‘2019’, ‘val’)] ,2019为我们设置的文件夹标识 ,"train"和"val"指代训练集和测试集
2)classes = [“shose”, “glove”, “battery”, “watermenlon”] ,修改为我们要识别的四类物体名称
如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[ ('2019', 'train'), ('2019', 'val')]
classes = ["shose", "glove", "battery", "watermenlon"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2019_train.txt 2019_val.txt > train.txt")
修改完成后,执行如下命令,即可在labels文件夹下生成标签文件.如下:
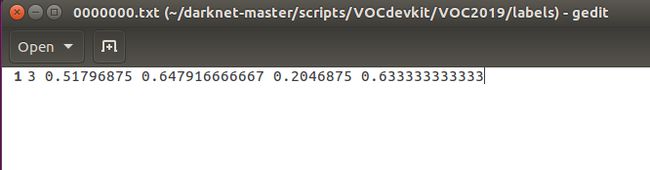
在scripts根目录下,也会生成2019_train.txt和2019_var.txt文件,与之前Main中的train.txt和var.txt文件不同,其内容全部为训练图片或测试图片的实际路径.
5.6 修改一些必要文件
5.6.1 修改data目录下的voc.names
将文件中coco数据集的标签,修改为我们需要的四类标签,如下:
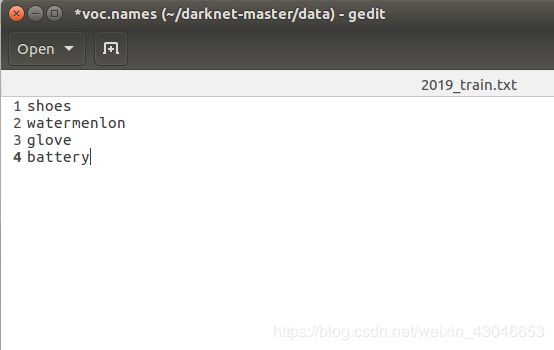
5.6.2 修改 cfg目录下的voc.data文件
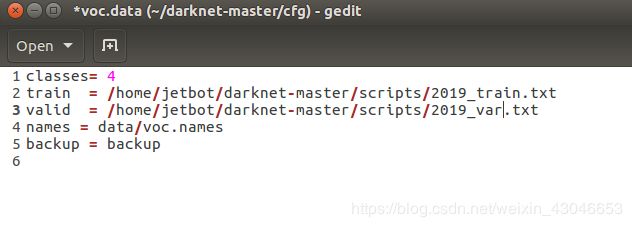
主要修改的点为:
1)classes 因为,我们是4类,所以,classes = 4;
2) 修改训练集:train = /home/jetbot/darknet-master/scripts/2019_train.txt
3) 修改测试集valid = /home/jetbot/darknet-master/scripts/2019_var.txt
4) 修改标签名: names = data/voc.names
5) 修改训练过程中生成的过程结果存放地址
修改后,如下:
5.6.3 修改 cfg目录下的yolov3-tiny.cfg文件
修改地方主要有如下几个:
- 有两处需要修改classes和filters,从下往上有两处,类似如下字样处:
[convolutional]
size = 1
stride =1
pad =1
filters = %%%
actication = linear
[yolo]
mask = ...
anchors = ...
classes = %%%
num = ...
将classes 修改为4,因为我们只有4类;将卷积层数修改为27 ,计算方式为3*(类别数+5).若为3类,则是3*(3+5) = 24.
- 我们任务是测试,则需要将该文件上方Testing下两行的batch=1,subdivisions=1全部注释掉,将# Training下两行的batch=64,subdivisions=16全部取消注释.
至此,训练前的准备工作已全部完成了.
5.6.4 生成预训练模型
该过程用于生成较小的预训练模型
$ ./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
6.训练
执行如下命令即可进行训练:
$ ./darknet detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15 | tee person_train_log.txt
保存log时会生成两个文件,一个保存的是网络加载信息和checkout点保存信息,另一个保存的是训练信息。
训练耗时较长,查看log当loss较小,且不再发生变化时,可按"ctrl+c"终止训练.我训练到了90000次就停止了,在这个过程中在backup文件夹下会保存对应迭代次数的中间结果,前1000次内每100次保存一个,超过1000次,每1000保存一次,依次.在这个过程中,我么可以随时拿中间结果进行测试.
7.测试
7.1 使用c进行图片检测
将yolov3-tiny90000.weights拷贝到Nano上即可进行测试,其测试方法同第4节,主要提该模型文件即可.如:
执行如下命令,即可用于图片检测.
$ ./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny90000.weights data/dog.jpg
7.2 使用c进行实时检测
执行如下命令,即可用于测试实时视频.
$ ./darknet detector demo cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny90000.weights
7.2 使用python进行图片检测
若想使用python文件进行测试,可以进入examples目录下,修改detector.py文件,主要修改如下内容:
dn.set_gpu(0)
net = dn.load_net("../cfg/yolov3-tiny.cfg", "../backup/yolov3-tiny_70000.weights", 0)
meta = dn.load_meta("../cfg/voc.data")
修改完的内容如下:
#!/usr/bin/env python
# Stupid python path shit.
# Instead just add darknet.py to somewhere in your python path
# OK actually that might not be a great idea, idk, work in progress
# Use at your own risk. or don't, i don't carefanhui
import sys, os
sys.path.append(os.path.join(os.getcwd(),'python/'))
import darknet as dn
import cv2 as cv
dn.set_gpu(0)
net = dn.load_net("../cfg/yolov3-tiny.cfg", "../backup/yolov3-tiny_70000.weights", 0)
meta = dn.load_meta("../cfg/voc.data")
r = dn.detect(net, meta, "../data/2.jpg")
print r
运行如下命令即可对指定的图片进行检测:
$ python detector.py
7.3 使用python进行实时检测
为了对实时视频进行目标检测,我们需要将上述检测图片的代码进行修改,
$ cd examples
$ touch detector_real_time.py
内容如下:
#!/usr/bin/env python
# Stupid python path shit.
# Instead just add darknet.py to somewhere in your python path
# OK actually that might not be a great idea, idk, work in progress
# Use at your own risk. or don't, i don't carefanhui
import sys, os
sys.path.append(os.path.join(os.getcwd(),'python/'))
import darknet as dn
import cv2 as cv
dn.set_gpu(0)
net = dn.load_net("../cfg/yolov3-tiny.cfg", "../backup/yolov3-tiny_70000.weights", 0)
meta = dn.load_meta("../cfg/voc.data")
r = dn.detect(net, meta, "../data/2.jpg")
print r
# And then down here you could detect a lot more images like:
cap = cv.VideoCapture(0)
while True:
ret,frame = cap.read()
if ret:
cv.imwrite("./a.jpg",frame)
r = dn.detect(net, meta, "./a.jpg")
print r
if len(r):
a= int(r[0][2][0]-(r[0][2][2]/2))
b= int(r[0][2][1]-(r[0][2][3]/2))
c= int(r[0][2][0]+(r[0][2][2]/2))
d= int(r[0][2][1]+(r[0][2][3]/2))
cv.rectangle(frame,(a,b),(c,d),(255,0,0),thickness=2)
m= int(r[0][2][0]-(r[0][2][2]/2)-10)
n= int(r[0][2][1]-(r[0][2][3]/2)-10)
cv.putText(frame,"%s:%.2f"%(r[0][0],r[0][1]),(m,n),cv.FONT_HERSHEY_SIMPLEX,0.7,(0,0,255),2,0)
cv.imshow("result",frame)
c = cv.waitKey(50)
if c==27:
break
else:
print "nothing"
continue
else:
break
cap.release()
运行该python文件,即可看到试试检测的画面,在Nnao上实测帧率为6fps.注意,要用python2来运行,即:
$ python detector_real_time.py