几种视觉Attention的代码详解
几种视觉Attention的代码详解
文章目录
- 几种视觉Attention的代码详解
- 1 SENet - 通道注意力
- 2 CBAM - 通道 + 空间注意力
- 3 SKEConv
- 4 self-attention
- 4.1 Self_Attn_Spatial 空间注意力
- 4.2 Self_Attn_Channel 通道注意力
- 5 Non-local
- 6 参考链接
最近看了几篇很优秀的视觉Attention介绍的文章,详细见参考链接。这里再拾人牙慧,将代码再清晰整理一遍,并自己编写了Self_Attn_Channel 注意力。
1 SENet - 通道注意力
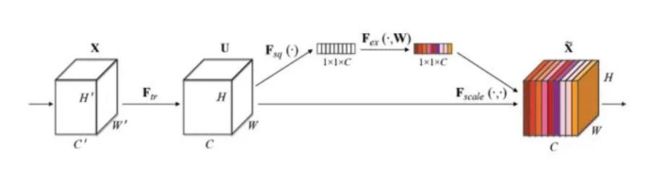

#SENet:Squeeze-and-Excitation Networks
#通道注意力
#论文地址:https://arxiv.org/abs/1709.01507
#代码地址:https://github.com/hujie-frank/SENet
class SELayer(nn.Module):
'''
func: 实现通道Attention.
parameters:
channel: input的通道数, input.size = (batch,channel,w,h) if batch_first else (channel,batch,,w,h)
reduction: 默认4. 即在FC的时,存在channel --> channel//reduction --> channel的转换
batch_first: 默认True.如input为channel_first,则batch_first = False
'''
def __init__(self, channel,reduction = 2, batch_first = True):
super(SELayer, self).__init__()
self.batch_first = batch_first
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel,channel // reduction, bias = False),
nn.ReLU(inplace = True),
nn.Linear(channel // reduction, channel, bias = False),
nn.Sigmoid()
)
def forward(self, x):
'''
input.size == output.size
'''
if not self.batch_first:
x = x.permute(1,0,2,3)
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b,c) #size = (batch,channel)
y = self.fc(y).view(b,c,1,1) #size = (batch,channel,1,1)
out = x * y.expand_as(x) #size = (batch,channel,w,h)
if not self.batch_first:
out = out.permute(1,0,2,3) #size = (channel,batch,w,h)
return out
x = torch.randn(size = (4,8,20,20))
selayer = SELayer(channel = 8, reduction = 2, batch_first = True)
out = selayer(x)
print(out.size())
'''
output:
torch.Size([4, 8, 20, 20])
'''
2 CBAM - 通道 + 空间注意力



#CBAM:Convolutional Block Attention Module(CBAM)
class ChannelAttention(nn.Module):
'''
func: 实现通道Attention.
parameters:
in_channels: input的通道数, input.size = (batch,channel,w,h) if batch_first else (channel,batch,,w,h)
reduction: 默认4. 即在FC的时,存在in_channels --> in_channels//reduction --> in_channels的转换
batch_first: 默认True.如input为channel_first,则batch_first = False
'''
def __init__(self,in_channels, reduction = 4, batch_first = True):
super(ChannelAttention,self).__init__()
self.batch_first = batch_first
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, kernel_size = 1, bias = False),
nn.ReLU(inplace = True),
nn.Conv2d(in_channels // reduction, in_channels, kernel_size = 1, bias = False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
if not self.batch_first:
x = x.permute(1,0,2,3)
avgout = self.sharedMLP(self.avg_pool(x)) #size = (batch,in_channels,1,1)
maxout = self.sharedMLP(self.max_pool(x)) #size = (batch,in_channels,1,1)
w = self.sigmoid(avgout + maxout) #通道权重 size = (batch,in_channels,1,1)
out = x * w.expand_as(x) #返回通道注意力后的值 size = (batch,in_channels,w,h)
if not self.batch_first:
out = out.permute(1,0,2,3) #size = (channel,batch,w,h)
return out
class SpatialAttention(nn.Module):
'''
func: 实现空间Attention.
parameters:
kernel_size: 卷积核大小, 可选3,5,7,
batch_first: 默认True.如input为channel_first,则batch_first = False
'''
def __init__(self, kernel_size = 3, batch_first = True):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,5,7), "kernel size must be 3 or 7"
padding = kernel_size // 2
self.batch_first = batch_first
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
if not self.batch_first:
x = x.permute(1,0,2,3) #size = (batch,channels,w,h)
avgout = torch.mean(x, dim=1, keepdim=True) #size = (batch,1,w,h)
maxout,_ = torch.max(x, dim=1, keepdim=True) #size = (batch,1,w,h)
x1 = torch.cat([avgout, maxout], dim=1) #size = (batch,2,w,h)
x1 = self.conv(x1) #size = (batch,1,w,h)
w = self.sigmoid(x1) #size = (batch,1,w,h)
out = x * w #size = (batch,channels,w,h)
if not self.batch_first:
out = out.permute(1,0,2,3) #size = (channels,batch,w,h)
return out
class CBAtten_Res(nn.Module):
'''
func:channel attention + spatial attention + resnet
parameters:
in_channels: input的通道数, input.size = (batch,in_channels,w,h) if batch_first else (in_channels,batch,,w,h);
out_channels: 输出的通道数
kernel_size: 默认3, 可选[3,5,7]
stride: 默认2, 即改变out.size --> (batch,out_channels,w/stride, h/stride).
一般情况下,out_channels = in_channels * stride
reduction: 默认4. 即在通道atten的FC的时,存在in_channels --> in_channels//reduction --> in_channels的转换
batch_first:默认True.如input为channel_first,则batch_first = False
'''
def __init__(self,in_channels,out_channels,kernel_size = 3,
stride = 2, reduction = 4,batch_first = True):
super(CBAtten_Res,self).__init__()
self.batch_first = batch_first
self.reduction = reduction
self.padding = kernel_size // 2
#h/2, w/2
self.max_pool = nn.MaxPool2d(3, stride = stride, padding = self.padding)
self.conv_res = nn.Conv2d(in_channels, out_channels,
kernel_size = 1,
stride = 1,
bias = True)
#h/2, w/2
self.conv1 = nn.Conv2d(in_channels, out_channels,
kernel_size = kernel_size,
stride = stride,
padding = self.padding,
bias = True)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace = True)
self.ca = ChannelAttention(out_channels, reduction = self.reduction,
batch_first = self.batch_first)
self.sa = SpatialAttention(kernel_size = kernel_size,
batch_first = self.batch_first)
def forward(self,x):
if not self.batch_first:
x = x.permute(1,0,2,3) #size = (batch,in_channels,w,h)
residual = x
out = self.conv1(x) #size = (batch,out_channels,w/stride,h/stride)
out = self.bn1(out)
out = self.relu(out)
out = self.ca(out)
out = self.sa(out) #size = (batch,out_channels,w/stride,h/stride)
residual = self.max_pool(residual) #size = (batch,in_channels,w/stride,h/stride)
residual = self.conv_res(residual) #size = (batch,out_channels,w/stride,h/stride)
out += residual #残差
out = self.relu(out) #size = (batch,out_channels,w/stride,h/stride)
if not self.batch_first:
out = out.permute(1,0,2,3) #size = (out_channels,batch,w/stride,h/stride)
return out
x = torch.randn(size = (4,8,20,20))
cba = CBAtten_Res(8,16,reduction = 2,stride = 1)
y = cba(x)
print('y.size:',y.size())
'''
y.size: torch.Size([4, 16, 20, 20])
'''
3 SKEConv
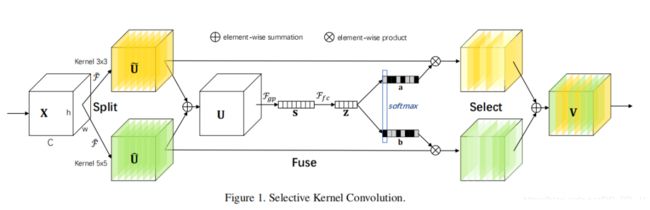

#SKENet: Selective Kernel Networks
# 论文地址:https://arxiv.org/abs/1903.06586
# 代码地址:https://github.com/implus/SKNet
class SKEConv(nn.Module):
'''
func: 实现Selective Kernel Networks(SKE) Attention机制。主要由Spit + Fuse + Select 三个模块组成
parameters:
in_channels: input的通道数;
M: Split阶段. 使用不同大小的卷积核(M个)对input进行卷积,得到M个分支,默认2;
G: 在卷积过程中使用分组卷积,分组个数为G, 默认为2.可以减小参数量;
stride: 默认1. split卷积过程中的stride,也可以选2,降低输入输出的w,h;
L: 默认32;
reduction: 默认2,压缩因子; 在线性部分压缩部分,输出特征d = max(L, in_channels / reduction);
batch_first: 默认True;
'''
def __init__(self,in_channels, M = 2, G = 2, stride = 1, L = 32, reduction = 2, batch_first = True):
super(SKEConv,self).__init__()
self.M = 2
self.in_channels = in_channels
self.batch_first = batch_first
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(
nn.Sequential(
nn.Conv2d(in_channels, in_channels,
kernel_size = 3 + i*2,
stride = stride,
padding = 1 + i,
groups = G),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace = True)
))
self.d = max(int(in_channels / reduction), L)
self.fc = nn.Linear(in_channels, self.d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(nn.Linear(self.d,in_channels))
self.softmax = nn.Softmax(dim = 1)
def forward(self, x):
if not self.batch_first:
x = x.permutation(1,0,2,3)
for i ,conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim = 1) #size = (batch,1,in_channels,w,h)
if i == 0:
feas = fea
else:
feas = torch.cat([feas,fea],dim = 1) #size = (batch,M,in_channels,w,h)
fea_U = torch.sum(feas,dim = 1) #size = (batch,in_channels,w,h)
fea_s = fea_U.mean(-1).mean(-1) #size = (batch,in_channels)
fea_z = self.fc(fea_s) #size = (batch,d)
for i,fc in enumerate(self.fcs):
vector = fc(fea_z).unsqueeze_(dim=1) #size = (batch,1,in_channels)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors,vector],
dim = 1) #size = (batch,M,in_channels)
attention_vectors = self.softmax(attention_vectors) #size = (batch,M,in_channels)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1) #size = (batch,M,in_channels,w,h)
fea_v = (feas * attention_vectors).sum(dim=1) #size = (batch,in_channels,w,h)
if not self.batch_first:
fea_v = fea_v.permute(1,0,2,3)
return fea_v
#%%
x = torch.randn(size = (4,8,20,20))
ske = SKEConv(8,stride = 2)
y = ske(x)
print('y.size:',y.size())
'''
y.size: torch.Size([4, 16, 10, 10])
'''
4 self-attention

4.1 Self_Attn_Spatial 空间注意力
#视觉应用中的self-attention机制
class Self_Attn_Spatial(nn.Module):
"""
func: Self attention Spatial Layer 自注意力机制.通过类似Transformer中的Q K V来实现
inputs:
in_dim: 输入的通道数
out_dim: 在进行self attention时生成Q,K矩阵的列数, 一般默认为in_dim//8
"""
def __init__(self,in_dim,out_dim):
super(Self_Attn_Spatial,self).__init__()
self.chanel_in = in_dim
self.out_dim = out_dim
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = out_dim , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = out_dim , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize,C,width ,height = x.size()
#proj_query中的第i行表示第i个像素位置上所有通道的值。size = B X N × C1
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1)
#proj_key中的第j行表示第j个像素位置上所有通道的值,size = B X C1 x N
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height)
#Energy中的第(i,j)是将proj_query中的第i行与proj_key中的第j行点乘得到
#energy中第(i,j)位置的元素是指输入特征图第j个元素对第i个元素的影响,
#从而实现全局上下文任意两个元素的依赖关系
energy = torch.bmm(proj_query,proj_key) # transpose check
#对行的归一化,对于(i,j)位置即可理解为第j位置对i位置的权重,所有的j对i位置的权重之和为1
attention = self.softmax(energy) # B X N X N
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1)) #B X C X N
out = out.view(m_batchsize,C,width,height) #B X C X W X H
#跨连,Gamma是需要学习的参数
out = self.gamma*out + x #B X C X W X H
return out,attention
x = torch.randn(size = (4,16,20,20))
self_atten_spatial = Self_Attn_Spatial(16,4)
y = self_atten_spatial(x)
print('y.size:',y[0].size())
'''
y.size: torch.Size([4, 16, 20, 20])
'''
4.2 Self_Attn_Channel 通道注意力
- 注意:目前的non_local 和 self_attention基本都是空间注意力,没有实现通道注意力。
- 这里作者根据自己对Transformer注意力的理解,给出了Self_Attn_Channel,即通道注意力。
class Self_Attn_Channel(nn.Module):
"""
func: Self attention Channel Layer 自注意力机制.通过类似Transformer中的Q K V来实现
inputs:
in_dim: 输入的通道数
out_dim: 在进行self attention时生成Q,K矩阵的列数, 默认可选取为:in_dim
"""
def __init__(self,in_dim,out_dim ):
super(Self_Attn_Channel,self).__init__()
self.chanel_in = in_dim
self.out_dim = out_dim
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = out_dim , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = out_dim , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = out_dim , kernel_size= 1)
self.x_conv = nn.Conv2d(in_channels = in_dim , out_channels = out_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C0 X W X H)
returns :
out : self attention value + input feature
attention: B X C1 X C1 (N is Width*Height)
"""
#C0 = in_dim; C1 = out_dim
m_batchsize,C0,width ,height = x.size()
#proj_query中的第i行表示第i个通道位置上所有像素的值: size = B X C1 × N
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height)
#proj_key中的第j行表示第j个通道位置上所有像素的值,size = B X N x C1
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1)
#Energy中的第(i,j)是将proj_query中的第i行与proj_key中的第j行点乘得到
#energy中第(i,j)位置的元素是指输入特征图第j个通道对第i个通道的影响,
#从而实现全局上下文任意两个通道的依赖关系. size = B X C1 X C1
energy = torch.bmm(proj_query,proj_key) # transpose check
#对于(i,j)位置即可理解为第j通道对i通道的权重,所有的j对i通道的权重之和为1
#对行进行归一化,即每行的所有列加起来为1
attention = self.softmax(energy) # B X C1 X C1
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C1 X N
out = torch.bmm(attention, proj_value) #B X C1 X N
out = out.view(m_batchsize,self.out_dim, width,height) #B X C1 X W X H
#跨连,Gamma是需要学习的参数
out = self.gamma*out + self.x_conv(x) #B X C1 X W X H
return out,attention
x = torch.randn(size = (4,8,20,20))
self_atten_channel = Self_Attn_Channel(8, 8)
y = self_atten_channel(x)
print('y.size:',y[0].size())
'''
output:
y.size: torch.Size([4, 8, 20, 20])
'''
5 Non-local

import torch
from torch import nn
from torch.nn import functional as F
class NonLocalBlockND(nn.Module):
"""
func: 非局部信息统计的注意力机制
inputs:
in_channels:输入的通道数,输入是batch_first = True。
inter_channels: 生成attention时Conv的输出通道数,一般为in_channels//2.
如果为None, 则自动为in_channels//2
dimension: 默认2.可选为[1,2,3],
1:输入为size = [batch,in_channels, width]或者[batch,time_steps,seq_length],可表示时序数据
2: 输入size = [batch, in_channels, width,height], 即图片数据
3: 输入size = [batch, time_steps, in_channels, width,height],即视频数据
sub_sample: 默认True,是否在Attention过程中对input进行size降低,即w,h = w//2, h//2
bn_layer: 默认True
"""
def __init__(self,
in_channels,
inter_channels=None,
dimension=2,
sub_sample=True,
bn_layer=True):
super(NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
# 进行压缩得到channel个数
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels,
out_channels=self.in_channels,
kernel_size=1,
stride=1,
padding=0), bn(self.in_channels))
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels,
out_channels=self.in_channels,
kernel_size=1,
stride=1,
padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
self.phi = conv_nd(in_channels=self.in_channels,
out_channels=self.inter_channels,
kernel_size=1,
stride=1,
padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x):
#if dimension == 3 , N = w*h*t ; if sub_sample: N1 = (w//2) * (h//2) * t ,else: N1 = N
#if dimension == 2 , N = w*h
#if dimension == 1 , N = w
#C0 = in_channels; C1 = inter_channels
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1) #[B, C1, N1]
g_x = g_x.permute(0, 2, 1) #[B, N1, C1]
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1) #[B, C1, N]
theta_x = theta_x.permute(0, 2, 1) #[B, N, C1]
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1) #[B, C1, N1]
f = torch.matmul(theta_x, phi_x) #[B,N,N1]
# print(f.shape)
f_div_C = F.softmax(f, dim=-1)
y = torch.matmul(f_div_C, g_x) #[B,N,N1] *[B, N1, C1] = [B,N,C1]
y = y.permute(0, 2, 1).contiguous() #[B,C1,N]
size = [batch_size, self.inter_channels] + list(x.size()[2:])
y = y.view(size) #size = [B,N,C1,x.size()[2:]]
W_y = self.W(y) #1 × 1 卷积 size = x.size()
z = W_y + x #残差连接
return z
x = torch.randn(size = (4,16,20,20))
non_local = NonLocalBlockND(16,inter_channels = 8,dimension = 2)
y = non_local(x)
print('y.size:',y.size())
'''
output:
y.size: torch.Size([4, 16, 20, 20])
'''
6 参考链接
注意力机制在分类网络中的应用:SENet、SKNet、CBAM
来聊聊 ResNet 及其变种
Self-attention机制及其应用:Non-local网络模块
Attention综述:基础原理、变种和最近研究
一文看懂 Attention(本质原理+3大优点+5大类型)
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用