Axial Attention 和 Criss-Cross Attention及其代码实现
Axial Attention 和 Criss-Cross Attention及其代码实现
文章目录
- Axial Attention 和 Criss-Cross Attention及其代码实现
- 1 Criss - Cross Attention介绍
- 1.1 引言
- 1.2 理论实现
- 1.2.1 获取权重A
- 1.2.2 Affinity操作
- 1.3.3 全部信息获取
- 1.3 代码实现
- 1.3.1 官方实现
- 1.3.2 纯pytorch实现
- 2 Axial Attention 介绍
- 2.1 引言
- 2.2 理论实现
- 2.3 代码实现
- 2.3.1 Row Attention
- 2.3.2 Col Attention
- 2.3.4 总结
- 2.4 开源的Axial Attention
- 参考链接
传统的卷积操作感受野受限于卷积核大小和stride, 因此对一个尺寸较大的二维图片来说,其左上角的像素点如果要能和右下角的像素点发生联系的话,必须通过不断的加深卷积层层数。而计算机视觉中的 self Attention机制能够实现目标像素点与任意一个像素点之间的关联,即融合了全局信息。但目前Self Attention中,以non-local attention为例,计算量较大,尤其在特征图很大时,计算效率非常低下。 那么怎么能既融合全局信息,保持长距离的空间依赖性,又降低计算量呢?Axial Attention 和 Criss-Cross Attention可以很好的解决这个问题。
1 Criss - Cross Attention介绍
1.1 引言
CCNet(Criss Cross Network)的核心是重复十字交叉注意力模块。该模块通过两次CC Attention,可以实现目标特征像素点与特征图中其他所有点之间的相互关系,并用这样的相互关系对目标像素点的特征进行加权,以此获得更加有效的目标特征。
- non-local 模型中, 因为要考虑特征图每个像素点与所有像素点的关系,时间复杂度和空间复杂度为 O(HW*HW)。
- 在CC Attention模块中,计算特征图中每个像素点与其对应的行列的像素点的关系,时间复杂度和空间复杂度O(HW*(H + W - 1)) ,相比前者降低了一个1~2个数量级。

1.2 理论实现
还是基于***self attention***的思路,使用Q和K向量来确定权重,再与V值取权重和。
H: (batch,c1,h,w) #输入特征图
Q: (batch,c2,h,w) #Query查询向量
K: (batch,c1,h,w) #Key 键值向量
V: (batch,c1,h,w) #Value 值向量
1.2.1 获取权重A
暂先不考虑Batch
- step1: 取Q中特征图中某一像素点的所有通道值:q = Q(i,j) , size = (1, c2)
- step2: 取K特征图中与q同一行和同一列的所有像素点的所有通道值, 交叉位置取了两次,只选一次. k的 size = (c2, h+w - 1)
- step3: q*k, 得到q_atten, size = (1, h+w - 1), 并对这(h + w -1) 个值进行softmax操作,即权重和为1.
- step4: 对Q中的所有像素点重复step2 和 step3, 即得到了每个像素点的归一权重。此时atten.size = (batch, h,w, h + w - 1)
1.2.2 Affinity操作
上面已经获取了Atten — (batch, h, w, h + w - 1)。接下来将权重施加在V上。 先不考虑batch
- step1: 获取Atten中某个像素点的所有权重, A = Atten(i,j) , size = (1, h + w -1)
- step2: 取V的某一通道Cn 的特征图Vn, size = (h, w) , 选取Vn上与A对应位置的同一行和同一列的数值,记作vn,size = (1, h + w - 1)
- step3: vn 与 A.T 相乘,即得到加权后的vn值,size = (1,1)
- step4: 对V中的所有通道重复step2 和 step3操作。
- step5: 对Atten中的所有像素点重复上述4步操作。
- step6: 残差网络:H‘ = CCAtten(H) + H
ICCV2019语义分割文章CCNet详解 该文章有很好的动图展示,有助理解。

1.3.3 全部信息获取
一个CCAttention,只能获取当前位置上同一行和一列的信息,如果两个叠加两个CCAttention,就可以获取全局信息。

如目标像素点是(Ux,Uy) ,想要获取(θx, θy)的关系。
loop1: 像素点(Ux, θy)和 (θx, Uy)通过一次CCAtten 可以建立与(θx, θy)的关系;
loop2: 像素点是(Ux,Uy) 通过CCAtten可以获取与 像素点(Ux, θy)和 (θx, Uy)的联系,从而间接取得与(θx, θy)的联系。
即通过两次CCAtten , 可以建立目前像素点与任意像素点的信息融合。
1.3 代码实现
1.3.1 官方实现
虽然上面给出了对CCAttention 的理论逻辑的理解,但如果按照该逻辑使用循环进行代码设计,很占计算资源,计算速度也会很慢,而且反向传播也不易做到。我有查看网上的一些实现(包括官方源码),似乎需要自定义的cuda算子,这个扩展性并不友好。
https://github.com/speedinghzl/CCNet

1.3.2 纯pytorch实现
参考: https://github.com/yearing1017/CCNet_PyTorch ,我在这里添加了详细的注释,有助理解更透彻。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
def INF(B,H,W):
'''
生成(B*W,H,H)大小的对角线为inf的三维矩阵
Parameters
----------
B: batch
H: height
W: width
'''
return -torch.diag(torch.tensor(float("inf")).repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
class CC_module(nn.Module):
def __init__(self,in_dim, device):
'''
Parameters
----------
in_dim : int
channels of input
'''
super(CC_module, self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1)).to(device)
self.device = device
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x) #size = (b,c2,h,w), c1 = in_dim, c2 = c1 // 8
#size = (b*w, h, c2)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
#size = (b*h, w, c2)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x) #size = (b,c2,h,w)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width) #size = (b*w,c2,h)
proj_value = self.value_conv(x) #size = (b,c1,h,w)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height) #size = (b*w,c1,h)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width) #size = (b*h,c1,w)
#size = (b*w, h,h) ,其中[:,i,j]表示Q所有W的第Hi行的所有通道值与K上所有W的第Hj列的所有通道值的向量乘积
energy_H = torch.bmm(proj_query_H, proj_key_H)
#size = (b,h,w,h) #这里为什么加 INF并没有理解
energy_H = (energy_H + self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
#size = (b*h,w,w),其中[:,i,j]表示Q所有H的第Wi行的所有通道值与K上所有H的第Wj列的所有通道值的向量乘积
energy_W = torch.bmm(proj_query_W, proj_key_W)
energy_W = energy_W.view(m_batchsize,height,width,width) #size = (b,h,w,w)
concate = self.softmax(torch.cat([energy_H, energy_W], 3)) #size = (b,h,w,h+w) #softmax归一化
#concate = concate * (concate>torch.mean(concate,dim=3,keepdim=True)).float()
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height) #size = (b*w,h,h)
#print(concate)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width) #size = (b*h,w,w)
#size = (b*w,c1,h) #[:,i,j]表示V所有W的第Ci行通道上的所有H 与att_H的所有W的第Hj列的h权重的乘积
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1))
out_H = out_H.view(m_batchsize,width,-1,height).permute(0,2,3,1) #size = (b,c1,h,w)
#size = (b*h,c1,w) #[:,i,j]表示V所有H的第Ci行通道上的所有W 与att_W的所有H的第Wj列的W权重的乘积
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1))
out_W = out_W.view(m_batchsize,height,-1,width).permute(0,2,1,3) #size = (b,c1,h,w)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + x
if __name__ == '__main__':
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cuda:0' if torch.cuda.device_count() > 1 else 'cpu')
model = CC_module(8,device)
x = torch.randn(4, 8, 20, 20).to(device)
out = model(x).(device)
print(out.shape)
需要注意的是: 这里的self-attention, 主要是空间注意力,并没有涉及通道注意力。
2 Axial Attention 介绍
2.1 引言
Axial Attention,即轴向注意力。之前关注到Axial Attention,是在谷歌的天气预报模型Metnet中有使用到。

于是去翻看了Axial Attention注意力。

2.2 理论实现
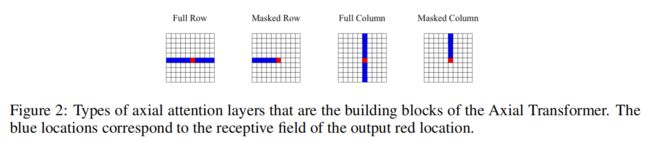
这里不谈他后续怎么设计的***Transformer***的,单纯的Axial Attention来看,其实有点类似之前的CC-Attention。
- CC-Attention 的感受野是与目标像素的同一行和同一列的(H + W - 1)个像素
- Axial Attention 的感受野是目标像素的同一行(或者同一列) 的W(或H)个像素
具体的思路也还是self-attention。理论实现方法与CC-Attention大同小异,这里就不赘述了。
2.3 代码实现
这里先根据个人理解,给出Axial Attention中的 Row-Attention 和 Col-Attention。
2.3.1 Row Attention
#实现轴向注意力中的 row Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cuda:0' if torch.cuda.device_count() > 1 else 'cpu')
class RowAttention(nn.Module):
def __init__(self, in_dim, q_k_dim, device):
'''
Parameters
----------
in_dim : int
channel of input img tensor
q_k_dim: int
channel of Q, K vector
device : torch.device
'''
super(RowAttention, self).__init__()
self.in_dim = in_dim
self.q_k_dim = q_k_dim
self.device = device
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.in_dim, kernel_size=1)
self.softmax = Softmax(dim=2)
self.gamma = nn.Parameter(torch.zeros(1)).to(self.device)
def forward(self, x):
'''
Parameters
----------
x : Tensor
4-D , (batch, in_dims, height, width) -- (b,c1,h,w)
'''
## c1 = in_dims; c2 = q_k_dim
b, _, h, w = x.size()
Q = self.query_conv(x) #size = (b,c2, h,w)
K = self.key_conv(x) #size = (b, c2, h, w)
V = self.value_conv(x) #size = (b, c1,h,w)
Q = Q.permute(0,2,1,3).contiguous().view(b*h, -1,w).permute(0,2,1) #size = (b*h,w,c2)
K = K.permute(0,2,1,3).contiguous().view(b*h, -1,w) #size = (b*h,c2,w)
V = V.permute(0,2,1,3).contiguous().view(b*h, -1,w) #size = (b*h, c1,w)
#size = (b*h,w,w) [:,i,j] 表示Q的所有h的第 Wi行位置上所有通道值与 K的所有h的第 Wj列位置上的所有通道值的乘积,
# 即(1,c2) * (c2,1) = (1,1)
row_attn = torch.bmm(Q,K)
########
#此时的 row_atten的[:,i,0:w] 表示Q的所有h的第 Wi行位置上所有通道值与 K的所有行的 所有列(0:w)的逐个位置上的所有通道值的乘积
#此操作即为 Q的某个(i,j)与 K的(i,0:w)逐个位置的值的乘积,得到行attn
########
#对row_attn进行softmax
row_attn = self.softmax(row_attn) #对列进行softmax,即[k,i,0:w] ,某一行的所有列加起来等于1,
#size = (b*h,c1,w) 这里先需要对row_atten进行 行列置换,使得某一列的所有行加起来等于1
#[:,i,j]即为V的所有行的某个通道上,所有列的值 与 row_attn的行的乘积,即求权重和
out = torch.bmm(V,row_attn.permute(0,2,1))
#size = (b,c1,h,2)
out = out.view(b,h,-1,w).permute(0,2,1,3)
out = self.gamma*out + x
return out
#实现轴向注意力中的 cols Attention
x = torch.randn(4, 8, 16, 20).to(device)
row_attn = RowAttention(in_dim = 8, q_k_dim = 4,device = device).to(device)
print(row_attn(x).size())
2.3.2 Col Attention
#实现轴向注意力中的 column Attention
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('cuda:0' if torch.cuda.device_count() > 1 else 'cpu')
class ColAttention(nn.Module):
def __init__(self, in_dim, q_k_dim, device):
'''
Parameters
----------
in_dim : int
channel of input img tensor
q_k_dim: int
channel of Q, K vector
device : torch.device
'''
super(ColAttention, self).__init__()
self.in_dim = in_dim
self.q_k_dim = q_k_dim
self.device = device
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.q_k_dim, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels = self.in_dim, kernel_size=1)
self.softmax = Softmax(dim=2)
self.gamma = nn.Parameter(torch.zeros(1)).to(self.device)
def forward(self, x):
'''
Parameters
----------
x : Tensor
4-D , (batch, in_dims, height, width) -- (b,c1,h,w)
'''
## c1 = in_dims; c2 = q_k_dim
b, _, h, w = x.size()
Q = self.query_conv(x) #size = (b,c2, h,w)
K = self.key_conv(x) #size = (b, c2, h, w)
V = self.value_conv(x) #size = (b, c1,h,w)
Q = Q.permute(0,3,1,2).contiguous().view(b*w, -1,h).permute(0,2,1) #size = (b*w,h,c2)
K = K.permute(0,3,1,2).contiguous().view(b*w, -1,h) #size = (b*w,c2,h)
V = V.permute(0,3,1,2).contiguous().view(b*w, -1,h) #size = (b*w,c1,h)
#size = (b*w,h,h) [:,i,j] 表示Q的所有W的第 Hi行位置上所有通道值与 K的所有W的第 Hj列位置上的所有通道值的乘积,
# 即(1,c2) * (c2,1) = (1,1)
col_attn = torch.bmm(Q,K)
########
#此时的 col_atten的[:,i,0:w] 表示Q的所有W的第 Hi行位置上所有通道值与 K的所有W的 所有列(0:h)的逐个位置上的所有通道值的乘积
#此操作即为 Q的某个(i,j)与 K的(i,0:h)逐个位置的值的乘积,得到列attn
########
#对row_attn进行softmax
col_attn = self.softmax(col_attn) #对列进行softmax,即[k,i,0:w] ,某一行的所有列加起来等于1,
#size = (b*w,c1,h) 这里先需要对col_atten进行 行列置换,使得某一列的所有行加起来等于1
#[:,i,j]即为V的所有行的某个通道上,所有列的值 与 col_attn的行的乘积,即求权重和
out = torch.bmm(V,col_attn.permute(0,2,1))
#size = (b,c1,h,w)
out = out.view(b,w,-1,h).permute(0,2,3,1)
out = self.gamma*out + x
return out
#实现轴向注意力中的 cols Attention
x = torch.randn(4, 8, 16, 20).to(device)
col_attn = ColAttention(8, 4, device = device)
print(col_attn(x).size())
2.3.4 总结
单独使用Row Atten(或者Col Attention),即使是堆叠好几次,也是无法融合全局信息的。一般来说,Row Attention 和 Col Attention要组合起来使用才能更好的融合全局信息。
建议方式:
- 方法1:out = RowAtten(x) + ColAtten(x)
- 方法2:x1 = RowAtten(x), out = ColAtten(x1)
- 方法3:x1 = ColAtten(x), out = RowAtten(x1)
这样的一次 out 类似于 一次CCAtten(x) 操作 。
所以一般至少需要迭代两次上述的任意方法,才能融合到全局信息。
2.4 开源的Axial Attention
github上有人开源了Axial Attention,并且灵活度很高。 https://github.com/lucidrains/axial-attention ,直接安装使用即可。
- 适用图片
- 适用视频
- 适用通道注意力
- 使用了多头结构
- 适用Transformer结构
pip install axial_attention #安装
#Image
import torch
from axial_attention import AxialAttention
img = torch.randn(1, 3, 256, 256)
attn = AxialAttention(
dim = 3, # embedding dimension
dim_index = 1, # where is the embedding dimension
dim_heads = 32, # dimension of each head. defaults to dim // heads if not supplied
heads = 1, # number of heads for multi-head attention
num_dimensions = 2, # number of axial dimensions (images is 2, video is 3, or more)
)
img_attn = attn(img)
print(img_attn.size())
#%%
#Channel-last image latents
import torch
from axial_attention import AxialAttention
img = torch.randn(1, 20, 20, 512)
attn = AxialAttention(
dim = 512, # embedding dimension
dim_index = -1, # where is the embedding dimension
heads = 8, # number of heads for multi-head attention
num_dimensions = 2, # number of axial dimensions (images is 2, video is 3, or more)
)
img_attn = attn(img)
print(img_attn.size())
#%%
#Video
import torch
from axial_attention import AxialAttention
video = torch.randn(1, 5, 10, 20, 20)
attn = AxialAttention(
dim = 10, # embedding dimension
dim_index = 2, # where is the embedding dimension
heads = 5, # number of heads for multi-head attention
num_dimensions = 3, # number of axial dimensions (images is 2, video is 3, or more)
)
video_atten = attn(video)
print(video_atten.size())
#%%
# Image Transformer, with reversible network
import torch
from torch import nn
from axial_attention import AxialImageTransformer
conv1x1 = nn.Conv2d(3, 128, 1)
transformer = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
img = torch.randn(1, 3, 20, 20)
img1 = transformer(conv1x1(img))
print(img1.size())
目前这个源码还没有啃清楚,有明白的同学欢迎交流。
参考链接
ICCV2019语义分割文章CCNet详解
CCNet: Criss-Cross Attention for Semantic Segmentation论文解读
https://github.com/yearing1017/CCNet_PyTorch/tree/master/CCNet
https://github.com/speedinghzl/CCNet
论文:CCNet: Criss-Cross Attention for Semantic Segmentation
https://github.com/lucidrains/axial-attention
Axial Attention in Multidimensional Transformers
MetNet: A Neural Weather Model for Precipitation Forecasting