《Python自然语言处理-雅兰·萨纳卡(Jalaj Thanaki)》学习笔记:09 NLU和NLG问题中的深度学习
09 NLU和NLG问题中的深度学习
- 9.1 人工智能概览
- 9.1.1 人工智能的基础
- 9.1.2 人工智能的阶段
- 9.1.3 人工智能的种类
- 9.1.4 人工智能的目标和应用
- 9.2 NLU和NLG之间的区别
- 9.2.1 自然语言理解
- 9.2.2 自然语言生成
- 9.3 深度学习概览
- 9.4 神经网络基础
- 9.4.1 神经元的第一个计算模型
- 9.4.2 感知机
- 9.4.3 理解人工神经网络中的数学概念
- 9.5 实现神经网络
- 9.5.1 单层反向传播神经网络
- 9.5.2 练习
- 9.6 深度学习和深度神经网络
- 9.6.1 回顾深度学习
- 9.6.2 深度神经网络的基本架构
- 9.6.3 NLP中的深度学习
- 9.6.4 传统NLP和深度学习NLP技术的区别
- 9.7 深度学习技术和NLU
- 9.7.1 机器翻译
- MLT (EN to FR ) TensorFlow
- Brief Overview of the Contents
- Data preprocessing
- Build model
- Training
- Prediction
- 9.8 深度学习技术和NLG
- 9.8.1 练习
- 9.8.2 菜谱摘要和标题生成
- 9.9 基于梯度下降的优化
- 9.9.1 基本梯度下降
- 9.9.2 随机梯度下降
- 9.9.3 小批量梯度下降
- 9.9.4 动量
- 9.9.5 Nesterov加速梯度
- 9.9.6 Adagrad
- 9.9.7 adadelta
- 9.9.8 Adam
- 9.10 人工智能与人类智能
- 9.11 总结
在前面的章节中,我们已经看到了基于规则的方法和各种机器学习技术来解决NLP任务。在本章中,我们将看到机器学习技术,称为深度学习(DL)子集。在过去的四到五年里,神经网络和深度学习技术在人工智能领域引起了广泛的关注,因为许多技术巨头使用这些尖端技术来解决现实生活中的问题,这些技术的成果令人印象深刻。谷歌、苹果、亚马逊、OpenAI等科技巨头花费大量时间和精力为现实生活中的问题创造创新的解决方案。这些努力主要是为了发展人工通用智能,使世界成为人类更好的地方。
我们首先要了解整个人工智能,总的来说,给你一个的概念,为什么深度学习现在正在高速发展。我们将在本章中讨论以下主题:
NLU和NLG之间的区别
神经网络基础
使用各种深度学习技术构建NLP和NLG应用程序
在了解了DL的基础知识之后,我们将接触到在深度学习领域中发生的一些最新的创新。那么,让我们开始吧!
9.1 人工智能概览
在本节中,我们将看到人工智能的各个方面以及深度学习与人工智能的关系。我们将看到人工智能的组成部分、人工智能的不同阶段和不同类型的人工智能;在本节的最后,我们将讨论为什么深度学习是实现人工智能最有希望的技术之一。
9.1.1 人工智能的基础
当我们谈论人工智能时,我们想到的是智能机器,这是人工智能的基本概念。人工智能是一个科学领域,它不断朝着使机器具有人类水平智能的方向发展。人工智能背后的基本思想是在机器中启用智能,以便它们也可以执行一些仅由人类执行的任务。我们正在尝试使用一些很酷的算法技术来实现机器中的人类级智能;在这个过程中,机器获取的任何类型的智能都是人工生成的。各种用于为机器生成人工智能的算法技术主要是机器学习技术的一部分。在进入核心机器学习和深度学习部分之前,我们将了解与人工智能相关的其他事实。人工智能受许多分支的影响;在图9.1中,我们将把那些严重影响人工智能的分支视为单个分支:
首先,我们将看到人工智能的关键组成部分。这些组成部分对于我们理解世界的发展方向是非常有用的。据我所知,有两个组件,如图9.2所示:

自动化
自动化是人工智能的一个著名组成部分。全世界的人们都在高度自动化方面工作,我们在机器执行的自动化任务方面取得了巨大的成功。我们将查看一些足够直观的例子,以便您理解人工智能中的自动化概念。
在汽车行业,我们使用自动机器人制造汽车。这些机器人遵循一套指令,执行特定的任务。在这里,这些机器人不是智能机器人,它们可以与人类互动、提问或回应人类。但这些机器人只是遵循一套指令来实现高速制造的高精度和高效率。所以这些机器人就是人工智能领域自动化的例子。
另一个例子是DevOps领域。现在,DevOps正在使用机器学习来自动化许多人类密集型的过程,例如,为了维护内部服务器,DevOps团队在分析各种服务器日志后获得一系列建议,在获得建议后,另一个机器学习模型优先处理警报和建议。这种应用程序确实为DevOps团队节省了时间来按时交付大量工作。这些应用程序确实帮助我们理解自动化是人工智能的一个非常重要的组成部分。
智力
当我们说智力,作为人类,我们的期望真的很高。我们的目标是让机器了解我们的行为和情绪。我们还希望机器根据人类的行为做出智能的反应,机器产生的所有反应都应该是模仿人类智能的。我们希望从20世纪90年代中期开始实现这一目标。在全球范围内,许多研究人员、科学家团体和社区正在进行大量的酷的研究,以使机器像人类一样智能化。
我们希望在获得智能之后,机器能够以更好的精度为人类完成大部分任务,这是一个单一的广泛的期望。在过去的45年中,我们已经开始成功地实现这一广泛的目标,因此,经过多年的努力,谷歌最近宣布,谷歌助手可以从人类身上听到自然语言,并能像人类一样准确地解释语音信号。另一个例子是,Facebook的研究小组进行了一项非常强大的研究,以建立一个善于对问题和答案进行推理的系统。特斯拉和谷歌的自动驾驶汽车是一个复杂的人工智能系统,但非常有用和智能。自动驾驶汽车和聊天机器人是窄人工智能的一部分。你也可以在网上找到很多其他的例子,这些例子时不时会出现。有些子组件可以作为信息的一部分。参见图9.3:
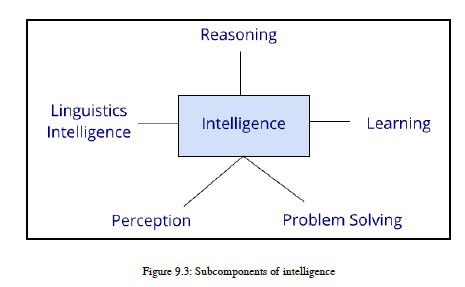
智能是前面图中描述的所有组件的组合。所有这些成分——推理、学习、从经验中学习、解决问题、感知和语言智能——都是人类的天性,而不是机器的天性。所以我们需要能够为机器提供智能的技术。
在学习本章后面将要使用的技术名称之前,让我们先了解人工智能的各个阶段。
9.1.2 人工智能的阶段
人工智能系统有三个主要阶段。我们将详细介绍以下几个阶段:
机器学习
机器智能
机器意识
在了解人工智能各个阶段的详细信息之前,请参阅图9.4:
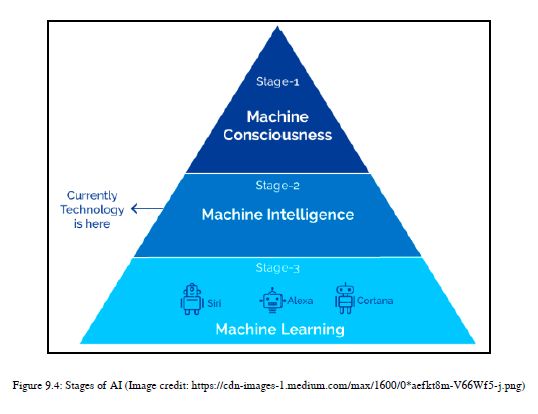
我们将从下到上,因此我们将首先了解机器学习阶段,然后了解机器智能,最后了解机器意识。
机器学习
在前面的章节中,您已经学习了很多关于机器学习的知识,但是我想在本章中给您一个人工智能的视角。
ML技术是一组解释如何生成或达到定义的输出的算法。这种算法被试图从经验中学习的智能系统所使用。使用ML算法的系统热衷于从历史数据或实时数据中学习。因此,在人工智能的这个阶段,我们关注学习模式或特定的算法
使用我们提供给ML系统的特性从数据中得到的结构。为了说明这一点,让我们举个例子。
假设您想要构建一个情绪分析应用程序。我们可以使用历史标记数据、手工制作的特性和朴素的Bayes ML算法。因此,我们可以拥有一个从其学习示例中学习到的智能系统——如何为看不见的新数据实例提供情感标签。
机器智能
机器智能又是一套算法,但大多数算法都严重受人脑学习和思考方式的影响。利用神经科学、生物学和数学,人工智能研究人员提出了一套高级算法,帮助机器从数据中学习,而不提供手工制作的特征。在此阶段,算法使用未标记或标记的数据。在这里,您只需定义最终目标,高级算法就可以找到实现预期结果的方法。
如果您将我们在这个阶段使用的算法与传统的ML算法进行比较,那么主要的区别在于,在机器智能阶段,我们不会将手工制作的特征作为任何算法的输入。当这些算法受到人脑的启发时,算法本身就学习特征和模式并生成输出。目前,人工智能的世界正处于这个阶段。全世界的人们都使用这些先进的算法,似乎很有希望为机器实现类似人类的智能。
利用人工神经网络和深度学习技术实现机器智能。
机器意识
机器意识是人工智能中讨论最多的主题之一,因为我们的最终目标是达到这里。
我们希望机器学习人类的学习方式。作为人类,我们不需要太多的数据;我们不需要太多时间来理解抽象概念。我们从少量数据或没有数据中学习。大多数时候,我们从经验中学习。如果我们想建立一个和人类一样有意识的系统,那么我们应该知道如何为机器产生意识。然而,我们是否完全知道我们的大脑是如何工作和反应的,以便把这些知识转移到机器上,使它们像我们一样有意识?不幸的是,现在我们还没有意识到这一点。我们期望在这一阶段,机器在没有数据或数据量非常小的情况下学习,并利用自己的经验来实现定义的输出。
9.1.3 人工智能的种类
人工智能有三种类型,如下所示:
弱人工智能
通用人工智能
人工超级智能
弱人工智能
弱人工智能(ANI)是一种人工智能,它涵盖了一些基本任务,如基于模板的聊天机器人、基本的个人助理应用程序,如苹果公司的Siri初始版本。
这种智能主要集中在应用程序的基本原型设计上。这种类型的智能是任何应用程序的起点,然后您可以改进基本原型。您可以通过添加人工通用智能来添加下一层智能,但前提是最终用户确实需要这种功能。我们在第7章,NLP的基于规则的系统中也看到了这种基本聊天机器人。
通用人工智能
通用人工智能(AGI)是一种人工智能,用于构建能够执行人级任务的系统。我所说的人工级别的任务是什么意思?建造自动驾驶汽车等任务。谷歌自动驾驶汽车和特斯拉自动驾驶仪是最著名的例子。类人机器人也尝试使用这种人工智能。
NLP级的例子是复杂的聊天机器人,它们忽略拼写错误和语法错误,并理解您的查询或问题。深度学习技术对于人类理解自然语言似乎非常有希望。我们现在正处在一个世界各地的人们和社区使用基本概念的阶段,通过相互参照对方的研究成果,尝试构建具有敏捷性的系统。
人工超级智能
实现人工超级智能(ASI)的方法对我们来说有点困难,因为在这种人工智能中,我们期望机器比人类更聪明,以便学习特定的任务,并且能够像人类在生活中一样执行多个任务。这种超级智能现在是我们的梦想,但我们正试图在这样一个机器和系统始终是人类技能的补充,不会对人类造成威胁。
9.1.4 人工智能的目标和应用
这是我们需要了解各个领域人工智能的目标和应用程序的时间和部分。这些目标和应用程序只是为了让您了解启用人工智能的应用程序的当前状态,但是如果您可以在任何领域想到一些疯狂但有用的应用程序,那么您应该尝试将其包括在这个列表中。您应该尝试在该应用程序中实现各种类型和阶段的人工智能。
现在,让我们看看我们想要集成人工智能各个阶段并使这些应用程序启用人工智能的领域:
推理
机器学习
自然语言处理
机器人学
实施一般情报
计算机视觉
自动化学习和调度
语音分析
您可以参考图9.5,它显示了许多不同的领域和相关的应用程序:
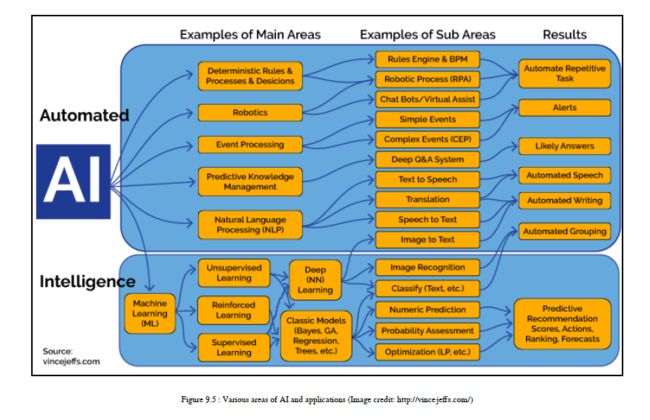
支持人工智能的应用程序
在这里,我将向您简要介绍启用人工智能的应用程序。一些应用程序也与NLP域相关:
- 对任何系统进行推理都是非常令人兴奋的事情。在这方面,我们可以建立一个Q/A系统,利用推理得出问题的答案。
- 如果我们能够对基于人工智能的系统进行推理,那么这些系统将非常擅长决策,并将改进现有的决策系统。
- 在机器学习中,我们需要一个基于ML的应用程序的完美架构,它可以由机器自己决定。据我所知,这是一个支持人工智能的ML应用程序。
- 当我们谈论人工智能的NLP应用程序时,我们真的需要能够理解人类自然语言的上下文并作出反应,表现得更像人类的NLP系统。
- 类人机器人是描述人工智能系统的最佳应用。机器人应该获得感知,这是一个长期的人工智能目标。我认为,当我们谈论一般智能时,系统的反应应该更像人类。尤其是机器反应应该与人类的真实行为相匹配。在分析了某些情况后,机器的反应应该比人类相同或更好
- 如今,计算机视觉有许多应用,为我们提供了可靠的证据,证明人工智能将很快在这一领域实现。这些应用包括物体识别、图像识别、使用图像识别技术检测皮肤癌、从机器生成面部图像、为图像生成文本(反之亦然)等。所有这些应用程序给出了人工智能驱动计算机视觉的具体证明。
- 自动学习和日程安排是一种为您个人提供帮助并管理日程安排的构建系统。关于人工智能部分,我们真的希望系统的每个用户都能获得个性化的体验,因此自动化学习一个人的个人选择对于人工智能驱动的调度非常重要。为了实现这一目标,自动化学习系统还应该学习如何为特定用户选择最适合的模型。
- 语言分析是nl的另一种形式,但不幸的是,我们在本书中没有讨论这个概念。在这里,我们讨论的是一个语音识别系统的潜在人工智能启用领域。通过使用这个语音识别区域启用人工智能,我们可以了解生成的人类环境和思维过程。
- 一个人在的社会学、心理学和哲学的影响下。我们也可以预测他们的性格。在看到所有这些迷人的应用程序之后,我们想到了三个真正有趣的问题:什么是导致我们生产人工智能驱动系统的原因,为什么时间如此适合我们构建人工智能驱动系统,以及我们如何构建一个人工智能系统?
自20世纪90年代中期以来,我们一直在尝试将智能引入机器。在这一阶段,研究人员和科学家给出了许多很酷的概念。例如,人工神经元,也被称为McCulloch-Pitts模型(MCP),受人脑的启发,这个概念的目的是理解人脑的生物工作过程,并从数学和物理的角度来表示这个过程。因此,对机器实现人工智能有一定的帮助。
他们成功地给出了单个神经元如何工作的数学表示,但是这个模型有一个结果不适合用于训练目的。因此,研究人员Frank Rosenblatt在1958年的论文中提出了感知器,引入了动态权重和阈值概念。在此之后,许多研究者在早期概念的基础上发展了诸如反向传播和多层神经网络等概念。研究团体希望在实际应用中实现已开发的概念,第一位研究员Geoffrey Hinton演示了使用广义反向传播算法训练多层神经网络。从那时起,研究人员和社区开始使用这种通用模型,但在20世纪末,数据量比现在少,计算设备既慢又昂贵。所以我们没有得到预期的结果。然而,随着当时取得的成果,研究人员相信这些概念将被用来实现人工智能驱动的世界。现在我们有了大量的数据和计算设备,这些设备速度快、价格便宜,并且能够处理大量的数据。当我们在当前时代应用人工神经网络的旧概念开发通用机器翻译系统、语音识别系统、图像识别系统等应用时,我们得到了非常有前途的结果。让我们举个例子。谷歌正在利用人工神经网络开发一个通用的机器翻译系统,该系统将翻译多种语言。这是因为我们有大量可用的数据集和快速的计算能力,可以帮助我们使用ANN处理数据集。我们使用的神经网络不是一层或两层,而是多层的。取得的成果令人印象深刻,以至于每一个大型科技巨头都在使用深度学习模型来开发一个人工智能系统。据我所知,数据、计算能力和可靠的基础概念是开发人工智能驱动系统的关键组件。您可以参考图9.6了解神经网络的简要历史:
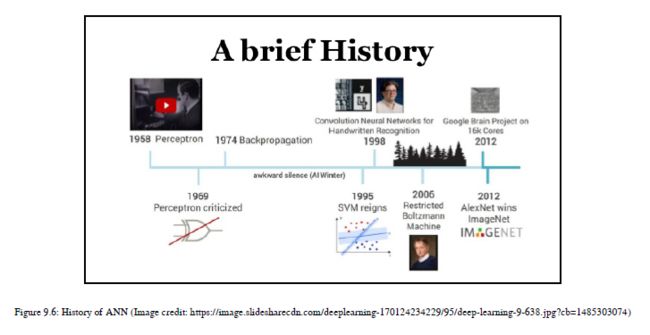
图9.7将向您介绍神经网络的长期历史:

现在让我们进入下一个问题:我们如何启用人工智能?答案是深度学习。这是使人工智能适用于非人工智能系统的最常用技术之一。在少数情况下,深度学习不用于启用人工智能,但在NLP领域,深度学习主要用于启用人工智能。为了发展一般智力,我们可以利用深度学习。我们从这项技术中得到了非常有希望的结果。在嘈杂的环境中,诸如生成人脸的机器能更准确地理解人类的语言,自动驾驶汽车、问答系统的推理等实验只是其中的一小部分。深度学习技术利用大量的数据和高计算能力来训练系统对给定数据的学习。当我们在大量数据上应用正确的深度学习模型时,我们会得到一个神奇的、令人印象深刻的、有希望的结果。这就是为什么深度学习在当今引起了很多轰动。所以我想现在你知道为什么深度学习是人工智能世界的流行词了。
9.2 NLU和NLG之间的区别
在第3章,我们已经看到了NLU和NLG的定义,细节,以及句子理解结构中的差异。在本节中,我们将从启用人工智能的应用程序的角度比较NLP的这两个子区域。
9.2.1 自然语言理解
早些时候,我们已经看到,NLU更多的是处理对语言结构的理解,无论是单词、短语还是句子。NLU更多的是在已经生成的NL上应用各种ML技术。在NLU中,我们关注语法和语义。我们还试图解决与语法和语义相关的各种类型的歧义。我们已经看到了词汇歧义、句法歧义、语义歧义和语用歧义。
现在让我们看看在哪里我们可以使用人工智能,帮助机器更准确、更有效地理解语言结构和含义。人工智能和人工智能技术在解决本地语言的这些方面并不落后。举个例子,深入学习使我们在机器翻译方面取得了令人印象深刻的成果。现在,当我们讨论解决句法歧义和语义歧义时,我们可以使用深度学习。假设您有一个命名实体识别工具,它将使用深度学习和word2vec,那么我们就可以解决语法上的歧义。这只是一个应用程序,但您也可以改进解析器结果和词性标注器。
现在我们来谈谈语用歧义,我们真正需要的是AGI和ASI。这种歧义发生在你试图理解一个句子与其他先前写的或说的句子的长距离上下文时,它还取决于说话者的说话或写作意图。
让我们来看一个语用歧义的例子。你和你的朋友正在谈话,你的朋友很久以前就告诉你,她加入了一个非政府组织,会为贫困学生做一些社会活动。现在你问她社交活动怎么样了。在这种情况下,你和你的朋友知道你在谈论什么社会活动。这是因为作为人类,我们的大脑存储信息,并知道何时获取这些信息,如何解释这些信息,以及获取的信息与您当前与朋友的对话有何关联。你和你的朋友都能理解对方问题和答案的上下文和相关性,但是机器没有这种理解上下文和说话者意图的能力。
这就是我们对智能机器的期望。我们希望机器也能理解这种复杂的情况。支持这种解决语用歧义的能力包含在MSI中。这在将来肯定是可能的,但现在,我们正处于机器试图采用AGI并使用统计技术来理解语义的阶段。
9.2.2 自然语言生成
NLG是一个我们试图教机器如何以合理的方式生成NL的领域。这本身就是一项具有挑战性的人工智能任务。深入学习真的帮助我们完成了这类具有挑战性的任务。让我举个例子。如果你正在使用谷歌的新收件箱,那么你可能会注意到,当你回复任何邮件时,你会得到三个最相关的回复,以句子的形式回复给你的邮件。谷歌使用了数百万封电子邮件,并制作了一个NLG模型,该模型通过深度学习来生成或预测任何给定邮件的最相关回复。您可以参考图9.8:
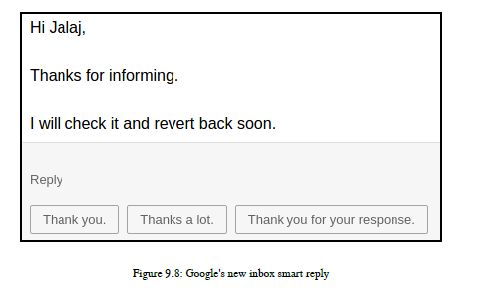
除了这个应用程序之外,还有另一个应用程序:看到图像后,机器将提供特定图像的标题。这也是一个使用深度学习的NLG应用程序。生成语言的任务比生成nl要简单,也就是说,连贯性,这就是我们需要AGI的地方。
我们已经讨论了很多关于“深度学习”这个词的内容,但它实际上是如何工作的?为什么它如此有前途?我们将在本章的下一节中看到这一点。我们将解释NLU和NLG应用程序的编码部分。我们还将从头开始开发NLU和NLG应用程序。在此之前,你必须了解ANN和深度学习的概念。我将在接下来的部分中加入数学,并尽我所能保持简单。
9.3 深度学习概览
机器学习是人工智能的一个分支,深度学习是ML的一个分支,参见图9.9:

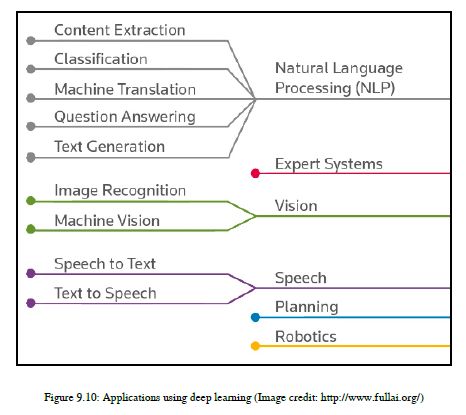
深度学习使用的人工神经网络不仅是一个或两个层次,而是许多层次的深度,称为深度神经网络(DNN)。当我们使用DNN通过预测同一个问题的可能结果来解决给定的问题时,它被称为深度学习。深度学习可以使用标记的数据或未标记的数据,因此我们可以说深度学习可以用于有监督的技术,也可以用于无监督的技术。使用深度学习的主要思想是,使用DNN和大量的数据,我们希望机器概括特定的任务,并为我们提供一个我们认为只有人类才能生成的结果。深度学习包括一系列的技术和算法,可以帮助我们解决NLP中的各种问题,如机器翻译、问答系统、总结等。除了NLP,您还可以找到其他应用领域,如图像识别、语音识别、对象识别、手写数字识别、人脸检测和人工人脸生成。
深度学习对我们来说似乎是有希望的,以便建立AGI和ASI。您可以在图9.10中看到一些使用了深度学习的应用程序:
9.4 神经网络基础
神经网络的概念是ML中最古老的技术之一。神经网络源于人脑。在这一部分中,我们将看到人脑的组成部分,然后推导出神经网络。
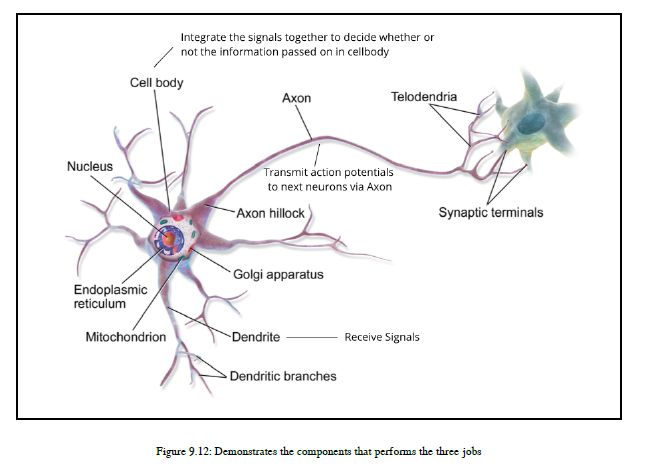
为了理解神经网络,我们首先需要了解人脑的基本工作流程。您可以参考图9.11:

人脑由几千亿个被称为神经元的神经细胞组成,每个神经元执行以下三个任务:
接收信号:它从树突接收一组信号
决定将信号传递给细胞体:将这些信号整合在一起,决定是否应将信息传递给细胞体。
发送信号:如果一些信号通过某个阈值,它会通过轴突将这些称为动作电位的信号发送给下一组神经元。您可以参考图9.12,它演示了用于在生物神经网络中执行这三项工作的组件:
这是我们大脑如何学习和处理某些决定的一个非常简短的概述。现在的问题是:我们能建立一个使用像硅或其他金属这样的非生物基底的人工神经网络吗?我们可以构建它,然后通过提供大量的计算机电源和数据,我们可以比人类更快地解决问题。人工神经网络是一种生物启发的算法,学习识别数据集中的模式。
9.4.1 神经元的第一个计算模型
1943年年中,研究人员McCulloch-Pitts发明了第一个神经元计算模型,他们的模型相当简单。该模型有一个接收二进制输入的神经元,对其求和,如果总和超过某个阈值,则输出为1,如果不是,则输出为零。您可以在图9.13中看到图示:
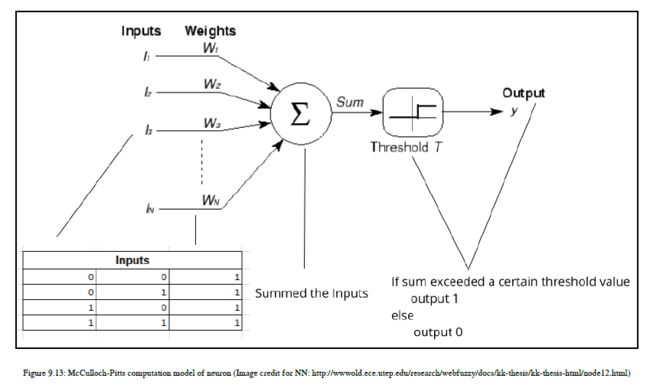
它看起来很简单,但是就像人工智能早期发明的那样,这种模型的发明是一件非常大的事情。
9.4.2 感知机
在发明了第一个神经元计算模型的几年后,心理学家Frank Rosenblatt发现,McCulloch-Pitts模型没有从输入数据中学习的机制。所以他发明了神经网络,建立在第一个神经元计算模型的基础上。Frank Rosenblatt称这个模型为感知器。它也被称为单层前馈神经网络。我们称这个模型为前馈神经网络,因为在这个神经网络中,数据只朝一个方向流动——正向。
现在让我们来理解感知器的工作,它包含了在给定输入上拥有权重的思想。如果您提供一些输入输出示例的训练集,它应该根据给定输入示例的输出,通过不断增加和减少每个训练示例的权重来从中学习函数。这些权重值在数学上应用于输入,以便在每次迭代之后,输出预测变得更准确。整个过程称为训练。参考图9.14了解Rosenblatt的感知器原理图:

9.4.3 理解人工神经网络中的数学概念
这一节非常重要,因为ML、ANN和DL使用了一系列数学概念,我们将看到其中一些最重要的概念。这些概念将真正帮助您优化ML、ANN和DL模型。我们还将看到不同类型的激活函数和一些关于您应该选择哪个激活函数的提示。我们将看到以下数学概念:
梯度下降
激活函数
损失函数
梯度下降
梯度下降是一种非常重要的优化技术,已被几乎所有的神经网络所采用。为了解释这些技术,我想举个例子。我有一个学生成绩和学习时间的数据集。我们想通过学生的学习时间来预测他的考试成绩。您会说这看起来像一个ML线性回归示例。你说得对,我们用线性回归来做预测。为什么是线性回归,与梯度下降有什么关系?让我回答这个问题,然后我们将看到代码和一些很酷的可视化效果。
线性回归是使用统计方法的ML技术,它允许我们研究两个连续定量变量之间的关系。在这里,这些变量是学生的分数和学习时间。通常在线性回归中,我们试图得到一条最适合我们数据集的线,这意味着无论我们做什么计算,都只是为了得到一条最适合给定数据集的线。得到这条最佳拟合线是线性回归的目标。
我们来谈谈线性回归与梯度下降的关系。梯度下降是我们用来优化线性回归精度和最小化损失或误差函数的最常用的优化技术。梯度下降是使误差函数最小化、预测精度最大化的技术,其数学定义是一阶迭代优化算法。该算法利用梯度下降法求函数的局部极小值。每一步都与当前点的函数梯度的负值成正比。您可以使用这个实际例子来考虑梯度下降。假设你在山顶上,现在你想到达一个有美丽湖泊的底部,所以你需要开始下降它。现在你不知道该往哪个方向走。在这种情况下,你观察你附近的土地,并试图找到土地倾向于下降的方式。这会让你知道你应该朝什么方向走。如果你沿着下降的方向迈出第一步,并且每次都遵循同样的逻辑,那么你很可能会到达湖边。这正是我们使用梯度下降的数学公式所做的。在ML和DL中,我们从优化的角度考虑所有问题,因此梯度下降是一种用于随时间最小化损失函数的技术。
另一个例子是你有一个深碗,你把一个小球从它的一端放进去,你可以观察到,过了一段时间后,球会减速并试图到达碗的底部。参见图9.15:

这个图显示了使用梯度下降获得最佳拟合线的过程或步骤。它只是可视化,让您全面了解我们将在代码中做什么。顺便说一下,损失函数、误差函数和成本函数是彼此的同义词。梯度下降也称为最陡下降。首先,让我们了解数据集。它是学生考试成绩和学习时间的数据集。我们知道,在这两个属性之间,应该有一种关系——你学习的数量越少,学生的分数越差,你学习的越多,分数就越好。我们将用线性回归证明这一关系,x值表示数据集的第一列,即学生学习的小时数,y值表示第二列,即考试分数。参见图9.16:

我们调用了一个函数,用来计算误差和实际的梯度下降。
from numpy import *
# y = mx + b
# m is slope, b is y-intercept
# here we are calculating the sum of squared error by using the equation which we have seen in the book.
def compute_error_for_line_given_points(b, m, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (m * x + b)) ** 2
return totalError / float(len(points))
def step_gradient(b_current, m_current, points, learningRate):
b_gradient = 0
m_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# Here we are coding up out partial derivatives equations and
# generate the updated value for m and b to get the local minima
b_gradient += -(2/N) * (y - ((m_current * x) + b_current))
m_gradient += -(2/N) * x * (y - ((m_current * x) + b_current))
# we are multiplying the b_gradient and m_gradient with learningrate
# so it is important to choose ideal learning rate if we make it to high then our model learn nothing
# if we make it to small then our training is to slow and there are the chances of over fitting
# so learning rate is important hyper parameter.
new_b = b_current - (learningRate * b_gradient)
new_m = m_current - (learningRate * m_gradient)
return [new_b, new_m]
def gradient_descent_runner(points, starting_b, starting_m, learning_rate, num_iterations):
b = starting_b
m = starting_m
for i in range(num_iterations):
# we are using step_gradient function to calculate the actual partial derivatives for error function
b, m = step_gradient(b, m, array(points), learning_rate)
return [b, m]
让我们读取数据集和执行运算
# Step 1 : Read data
# genfromtext is used to read out data from data.csv file.
points = genfromtxt("./gradientdescentexample/data.csv", delimiter=",")
# Step2 : Define certain hyperparameters
# how fast our model will converge means how fast we will get the line of best fit.
# Converge means how fast our ML model get the optimal line of best fit.
learning_rate = 0.0001
# Here we need to draw the line which is best fit for our data.
# so we are using y = mx + b ( x and y are points; m is slop; b is the y intercept)
# for initial y-intercept guess
initial_b = 0
# initial slope guess
initial_m = 0
# How much do you want to train the model?
# Here data set is small so we iterate this model for 1000 times.
num_iterations = 1000
# Step 3 - print the values of b, m and all function which calculate gradient descent and errors
# Here we are printing the initial values of b, m and error.
# As well as there is the function compute_error_for_line_given_points()
# which compute the errors for given point
print("Starting gradient descent at b = {0}, m = {1}, error = {2}".format(initial_b, initial_m,
compute_error_for_line_given_points(initial_b, initial_m, points)))
print("Running...")
# By using this gradient_descent_runner() function we will actually calculate gradient descent
[b, m] = gradient_descent_runner(points, initial_b, initial_m, learning_rate, num_iterations)
# Here we are printing the values of b, m and error after getting the line of best fit for the given dataset.
print("After {0} iterations b = {1}, m = {2}, error = {3}".format(num_iterations, b, m, compute_error_for_line_given_points(b, m, points)))
Starting gradient descent at b = 0, m = 0, error = 5565.107834483211
Running...
After 1000 iterations b = 0.08893651993741346, m = 1.4777440851894448, error = 112.61481011613473
我们调用了两个函数:compute_error_for_line_points(),它将计算实际值和预测值之间的误差,以及gradient_descent_runner(),它将为我们计算梯度。
- 计算误差或损失
有许多方法可以计算ML算法的误差,但在本章中,我们将使用最流行的技术之一:平方距离误差之和。现在我们直接讨论细节,这个误差函数对我们有什么作用?回想一下我们的目标:我们希望得到最适合我们的数据集的行。参考图9.19,这是线路坡度方程。这里,m是直线的斜率,b是y的截距,x和y是数据点——在我们的例子中,x是学生学习的小时数,y是测试分数。参见图9.19:

利用前面的方程,我们画出直线,从斜率m和y截距b的随机值开始,用第一列数据点作为x的值,得到y的值。在训练数据中,我们已经得到y的值,这意味着我们知道每个学生的考试分数。所以对于每个学生,我们需要计算出误差。让我们以一个非常直观的例子为例,注意我们正在使用虚拟值进行解释。假设您通过放置m和b的随机值得到y值41.0。现在您得到y的实际值,即52.5,那么预测值和实际值之间的差为11.5。这只是一个数据点,但我们需要计算每个数据点。因此,为了进行这种误差计算,我们使用的是平方距离误差之和。
现在我们如何计算平方距离误差之和,为什么要使用平方距离误差之和?
那么让我们从第一个问题开始,计算平方距离误差和的公式如图9.20所示:

如您所见,最后一部分mxi+b是我们通过选择m和b的随机值绘制的线,我们实际上可以将y替换为mxi+b。因此,我们在这里计算原始y值与生成y值之间的差。我们将减去原始Y值和生成的Y值,并将每个数据点的该值平方。我们之所以对值进行平方,是因为我们不想处理负值,因为我们在计算平方后进行求和,并且我们想测量整体的大小。我们不需要实际的价值,因为我们正试图最小化这个整体的规模。现在回到方程,我们已经计算了原始y值和生成y值之差的平方。现在我们对所有这些点执行求和;我们将使用sigma表示法来指示数据集中所有数据点的求和操作。此时,我们有一个指示误差大小的和值,我们将用这些值除以数据点的总数。之后,我们将得到我们想要的实际错误值。您可以看到,为了生成最适合我们的数据集的行,行正在为每个迭代移动。我们正在根据误差值更新m和b的值。现在,对于每个时间戳,行是静态的,我们需要计算误差。参照图9.21:
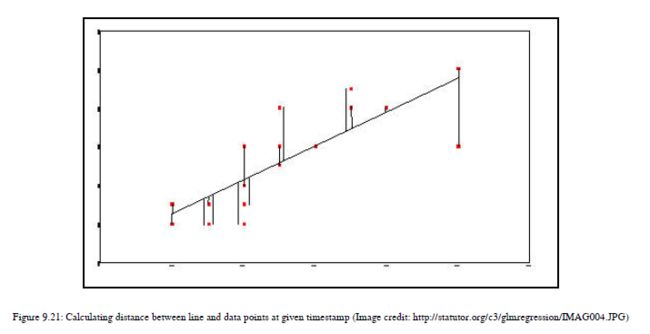
现在我们需要根据给定的方程,用技术的方式来表达直观的例子和方程。在这里,我们计算从每个数据点到我们画的直线的距离,将它们平方,求和,然后除以总点数。所以,在每次迭代或时间戳之后,我们可以计算我们的错误值,并了解我们的行有多糟糕,或者我们的行有多好。如果我们的行是差的,那么为了得到最适合的行,我们更新m和b的值。因此,错误值为我们提供了指示是否有改进的可能性,以生成最佳匹配的行。因此,我们最终想要最小化我们在这里得到的错误值,以便生成最佳拟合线。我们如何将这个错误最小化并生成最佳拟合线?下一步称为梯度下降。
平方和误差的原因有两个:对于线性回归,这是最常用的计算误差的方法。如果您有一个大的数据集,也可以使用它。
让我们看一下编码部分,然后我们将跳到计算梯度下降的核心部分。def compute_error_for_line_given_points(b, m, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
totalError += (y - (m * x + b)) ** 2
return totalError / float(len(points))
- 计算梯度
使用错误函数,我们知道是否应该更新行以生成最佳匹配的行,但是如何更新行将在本节中看到。我们如何将这个错误最小化并生成最佳拟合线?为了回答这个问题,首先,让我们对梯度下降和编码部分有一些基本的了解,我们只剩下最后一个函数,gradient_descent_runner(),参考图9.23
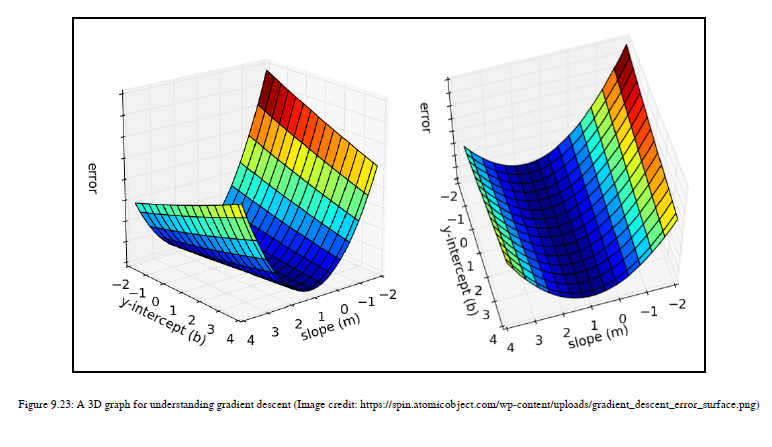
如图9.23所示,这是一个三维图。这两个图是相同的,它们的视角是不同的。这些图显示了斜率m,y截距b和误差的所有可能值。这是三个值的对,包括m、b和error。这里,x轴是一个斜率值,y轴是y轴截距,z轴是误差值。我们试图找出错误最少的地方。如果你仔细看图表,那么你可以观察到在曲线的底部,误差值是最小的。值最小的点称为ml中的局部极小值。在复杂的数据集中,可以找到多个局部极小值;这里我们的数据集很简单,因此我们有一个局部极小值。如果您有一个复杂的高维数据集,其中有多个局部极小值,那么您需要进行二阶优化来决定应该选择哪个局部极小值以获得更好的精度。我们不会在这本书中看到二阶优化。现在让我们回顾一下我们的图表,在这里我们可以直观地识别出给我们最小误差值的点,同样的点也给出了y截距的理想值,即b和斜率值,即m。当我们得到b和m的理想值时,我们将把这些值放入我们的y=mx+c方程中,然后魔法就会发生,我们将得到最佳拟合线。这不是获得最佳拟合线的唯一方法,但我的目的是让您对梯度下降有一个深入的了解,以便我们以后可以在DL中使用这个概念。现在从视觉上看,你可以看到误差最小的点,但是如何达到这个点呢?答案是通过计算梯度。梯度也称为坡度,但这不是坡度值m,因此不要混淆。我们讨论的是斜坡的方向,使我们到达那个最小的误差点。所以我们有一些b值和m值,在每次迭代之后,我们更新这些b值和m值,这样我们就可以达到最小的误差值点。所以从三维图像的角度来看,如果你在曲线的顶部,每次迭代,我们计算梯度和误差,然后更新m和b的值,到达曲线的底部。我们需要到达曲线的底部,通过计算梯度值,我们得到了我们下一步应该采取的方向。所以梯度是一条切线,它不断地告诉我们,我们需要移动的方向,无论是向上还是向下,以达到最小的误差点,并获得理想的B和M值来生成最佳拟合线。参见图9.24:
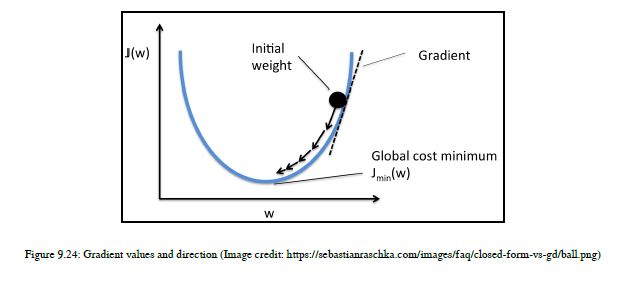
现在让我们看看最后一个但不是最不重要的计算梯度下降的方程。在图9.25中,你可以看到梯度下降方程,它只是我们误差函数的偏导数。我们采用平方误差和方程,对m和b进行偏导数,计算梯度下降。结果如图9.25所示:
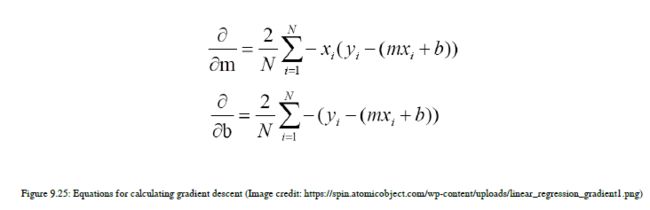
左侧符号是偏导数的符号。这里,我们有两个方程,因为我们取了误差函数,生成了关于变量m的偏导数,在第二个方程中,我们生成了关于变量b的偏导数。通过这两个方程,我们将得到b和m的更新值。为了计算梯度,我们需要导出偏导数。误差函数,对于ml和dl中的一些问题,我们不知道误差函数的偏导数,这意味着我们找不到梯度。所以我们不知道如何处理这种函数。你的误差函数应该是可微的,这意味着你的误差函数应该有偏导数。这里的另一件事是我们使用的是线性方程,但是如果你有高维的数据,那么你可以使用非线性函数,如果你知道误差函数的话。当我们第一次开始时,梯度下降并没有给我们最小值。梯度只是告诉我们如何更新m和b值,无论我们应该更新为正值还是负值。所以梯度给了我们一个如何更新m和b值的概念,也就是说,通过计算梯度,我们得到了方向,并试图达到我们得到m和b的最小误差值和最佳值的点。def step_gradient(b_current, m_current, points, learningRate):
b_gradient = 0
m_gradient = 0
N = float(len(points))
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# Here we are coding up out partial derivatives equations and
# generate the updated value for m and b to get the local minima
b_gradient += -(2/N) * (y - ((m_current * x) + b_current))
m_gradient += -(2/N) * x * (y - ((m_current * x) + b_current))
# we are multiplying the b_gradient and m_gradient with learningrate
# so it is important to choose ideal learning rate if we make it to high then our model learn nothing
# if we make it to small then our training is to slow and there are the chances of over fitting
# so learning rate is important hyper parameter.
new_b = b_current - (learningRate * b_gradient)
new_m = m_current - (learningRate * m_gradient)
return [new_b, new_m]在代码中,我们将m_gradient和b_gradient与学习速率相乘,因此学习速率是一个重要的超参数。选择它的值时要小心。如果您选择一个非常高的值,您的模型可能根本不会训练。如果你选择了一个非常低的值,那么训练会花费很多时间,而且也有可能过度拟合。请参阅图9.27,它为您提供了关于良好学习率的直觉:

激活函数
让我们先看看激活函数。我想给你一个概念,在什么阶段的神经网络,我们将使用这个激活函数。在我们对感知器的讨论中,我们说,如果超过某个阈值,神经网络将生成一个输出;否则,输出将为零。整个机制计算阈值并生成基于此阈值的输出由激活函数负责。
激活函数能够为我们提供介于0和1之间的值。之后,使用阈值,我们可以生成输出值1或输出值0。假设我们的阈值是0.777,我们的激活函数输出是0.457,那么我们的结果输出是0;如果我们的激活函数输出是0.852,那么我们的结果输出是1。所以,下面是激活函数在ANN中的工作原理。通常,在神经网络中,每个神经元都有一定的权重和输入值。我们正在求和并生成加权和值。当我们通过非线性函数传递这些值时,这个非线性函数激活一定数量的神经元以获得复杂任务的输出;这个神经元的激活过程使用一定的非线性数学函数被称为激活函数或传递函数。激活函数将输入节点映射到输出节点。以某种方式使用某些数学运算。
在人工神经网络中具有激活函数的目的是在网络中引入非线性。让我们一步一步地了解这一点。
让我们集中讨论一下ANN的结构。该神经网络结构可进一步分为三个部分:
架构:架构就是决定神经网络中神经元和层的排列。
激活:为了生成复杂任务的输出,我们需要看到神经元的活动——一个神经元如何响应另一个神经元以生成复杂行为。
学习规则:当ANN生成输出时,我们需要在每个时间戳更新ANN权重,以使用误差函数优化输出。
激活函数是激活部分的一部分。如前所述,我们将把非线性引入神经网络。其背后的原因是,没有非线性,神经网络不能产生复杂的行为来解决复杂的任务。在数字语言中,大多数情况下,我们使用非线性激活函数来获得复杂的行为。除此之外,我们还希望以非线性方式将输入映射到输出。
如果您不使用非线性激活函数,那么对于复杂的任务,ANN将不会为您提供大量有用的输出,因为您正在传递矩阵,并且如果您在ANN中使用多个具有线性激活函数的层,则会得到一个输出,该输出是输入值、权重和偏差的总和。所有层。这个输出给你另一个线性函数,这意味着这个线性函数将多层人工神经网络的行为转换为单层人工神经网络。这种行为对于解决复杂的任务一点都不没有用。
我想强调一下连接主义的概念。神经网络中的连接主义是利用相互连接的神经元产生复杂的行为,就像人脑一样,如果不在神经网络中引入非线性,我们就无法实现这种行为。参见图9.29了解激活功能:
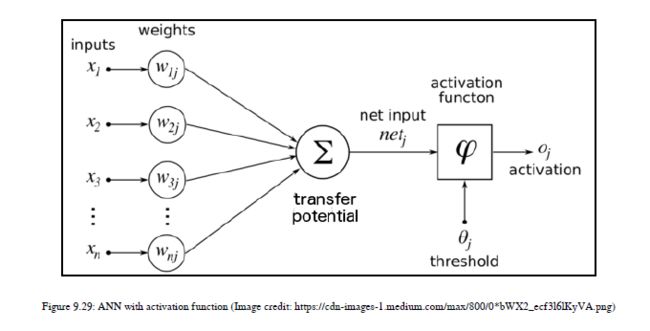
这里,我们将介绍上图中提到的这些功能:
Transfer potential:这是一个集合输入和权重的函数。更具体地说,此函数执行输入和权重的总和
Activation function:该函数将传递势函数的输出作为输入,并使用激活函数进行非线性数学变换。
Threshold function:基于激活功能,阈值功能激活神经元或不激活。传递势是一个简单的求和函数,它将输入的内积和连接的权值相加。如图9.30所示:

这种传递势通常是点积,但它可以使用任何数学方程,如多二次函数。
另一方面,激活函数应该是任何可微的非线性函数。它必须是可微的,这样我们才能计算误差梯度,而且这个函数必须具有非线性特性才能从神经网络中获得复杂的行为。通常,我们使用sigmoid函数作为激活函数,这需要将潜在输出值作为输入,计算最终输出,然后计算实际输出和生成输出之间的误差。然后,我们将利用误差梯度的计算概念以及应用反向传播优化策略来更新神经网络连接的权重。
图9.31用theta表示传递势函数,也称为logit,我们将在logistic-sigmoid激活函数方程中使用该函数:
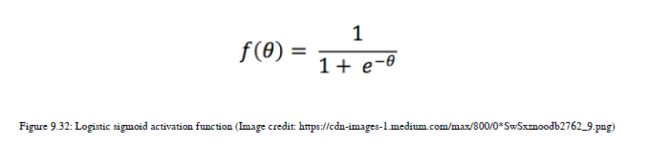
您可以在图9.32中看到logistic-sigmoid函数的方程:

激活函数背后的整个想法大致模拟了神经元在大脑中相互交流的方式。每一个都是通过它的动作电位被激活的,如果达到某个阈值,那么我们就知道是否激活一个神经元。激活功能模拟大脑动作电位的峰值。深度神经网络(DNN)被称为通用近似函数,因为它们可以在任何情况下计算任何函数。它们可以计算任何可微的线性函数和非线性函数。现在您可能会问我何时使用这个激活函数。我们将在下一段中看到这一点。有多种激活函数可用。使用时要小心。我们不应该仅仅因为它们听起来很新很酷就使用它们。在这里,我们将讨论您如何知道应该使用哪一个。我们将看到三个主要的激活函数,因为它们在DL中的广泛使用,尽管还有其他的激活函数可以使用。
Sigmoid
Tanh
ReLU 及其变体
Sigmoid
就其数学概念而言,Sigmoid函数很容易理解。其数学公式如图9.33所示:
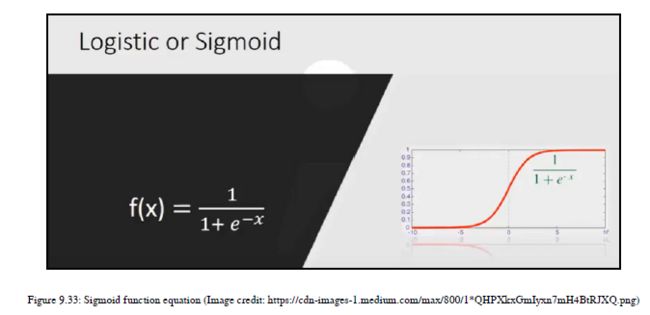
如图9.33所示,sigmoid函数将采用给定的方程,取一个数字,并在0和1的范围内挤压该数字。它产生一条S形曲线。这个函数是第一个在神经网络中作为激活函数使用的函数,因为它可以解释为神经元的激活率——零意味着没有激活,一个是完全饱和的激活。当我们在DNN中使用这个激活函数时,我们了解到这个激活函数的一些局限性,这使得它现在不那么流行。
这些功能的一些基本问题如下:
它有梯度消失问题
它的收敛速度很慢
它不是一个以零为中心的函数
让我们详细了解每个问题:消失梯度问题:
当使用基于梯度的方法训练某些神经网络时,尤其是在使用反向传播的神经网络中,可以发现这个问题。这个问题使得学习和调整神经网络早期层的参数变得非常困难。当你向你的人工神经网络添加更多的层时,这就变得更加困难了。如果我们明智地选择激活函数,那么这个问题就可以得到解决。我想先给你详细介绍一下这个问题,然后我们再讨论它背后的原因。
基于梯度的方法通过了解输入参数和权重的微小变化如何影响神经网络的输出来学习参数值。如果这个梯度太小,那么参数的变化将导致神经网络输出的变化非常小。在这种情况下,经过一些迭代后,神经网络不能有效地学习参数,并且不会以我们想要的方式收敛。这就是梯度消失问题中发生的情况。网络输出相对于早期层参数的梯度变得非常小。可以说,即使输入层和权重的参数值发生了很大的变化,也不会对输出产生很大的影响。
我给你所有这些细节,因为你也可以面对同样的问题与sigmoid函数。最基本的问题是这个消失梯度问题取决于你的激活函数的选择。sigmoid函数以非线性方式将输入压缩成一个小范围的输出。如果您给sigmoid函数一个实数,它将把这个数压缩到[0,1]的范围内。所以输入空间中有很大的区域被映射到一个非常小的范围。即使输入参数发生很大的变化,也会导致因为这个区域的梯度很小,所以输出变化很小。对于sigmoid函数,当一个神经元饱和接近零或一时,这个区域的梯度非常接近零。在反向传播过程中,这个局部梯度将乘以每个层的输出的梯度。因此,如果第一层映射到一个大的输入区域,我们得到一个非常小的梯度以及第一层输出的非常小的变化。这一微小的变化传递到下一层,并在第二层的输出中产生更小的变化。如果我们有一个DNN,那么在某些层之后输出就不会发生变化。这是sigmoid函数的问题。
低收敛速度:
由于这个消失梯度问题,有时具有sigmoid函数的神经网络收敛非常慢。
非零中心功能:
sigmoid函数不是零中心激活功能。这意味着,sigmoid函数的输出范围是[0,1],这意味着函数的输出值将始终为正,从而使权重的梯度变为全部正或全部负。这使得梯度更新在不同的方向上走得太远,这使得优化更加困难。
由于这些限制,sigmoid函数最近没有在DNN中使用。虽然您可以使用其他函数来解决这些问题,但是您也可以只在您的神经网络的最后一层使用sigmoid函数。
TanH
为了克服sigmoid函数的问题,我们将引入一个激活函数,叫做双曲正切函数(tanh)。tanh方程如图9.34所示:
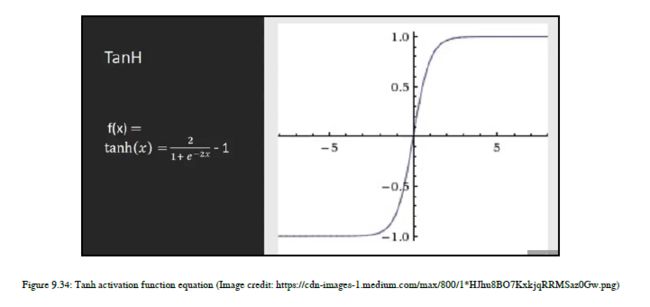
此函数将输入区域压缩到范围[-1,1]内,因此其输出是以零为中心的,这使得优化对我们来说更加容易。这个函数也有消失梯度问题,所以我们需要看到其他的激活函数。
ReLU 及其变体
整流线性单元(ReLU )是工业上最流行的函数。看它的方程式在图9.35中:

如果你会看到ReLU数学方程,那么你就会知道它只是max(0,x),这意味着当x小于零时,值为零,当x大于或等于零时,值与斜率1成线性关系。一位名叫Krizhevsky的研究人员发表了一篇关于图像分类的论文,并说他们使用ReLU作为激活函数,可以更快地收敛六倍。你可以点击阅读这篇研究论文http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf.这个函数很简单,没有任何复杂的计算,而且比Sigmoid和Tanh更简单。这就是这个函数学习更快的原因。除此之外,它也没有消失梯度问题。
我们曾经在DNN中存在的每一层中应用激活函数。目前,ReLU已被广泛应用于大部分的DNN,但它被应用于DNN的隐藏层。如果要解决分类问题,输出层应该使用SoftMax,因为SoftMax函数为我们提供了每个类的概率。我们在word2vec算法中使用了softmax激活函数。对于回归问题,输出层应该使用线性函数,因为信号通过不变。除了ReLU的所有这些优点外,它还有一个问题:在训练过程中,神经网络的某些单元可能会脆弱并死亡,这意味着通过ReLU神经元的大梯度可能会导致权重更新,使其不再在任何数据点上激活。所以流过它的梯度,从那一点开始总是零。为了克服ReLU的这种局限性,引入了一种ReLU的变体——Leaky ReLU。当x小于0(x<0)时,Leaky ReLU的负斜率较小,而不是函数为零。参见图9.36:

还有一种变体叫做maxout,它是ReLU和Leaky ReLU的广义形式,但它使每个神经元的参数加倍,这是一个缺点。
现在您已经对激活函数有了足够的了解,那么应该使用哪个函数呢?答案是ReLU,但是如果太多的神经元死亡,那么使用Leaky ReLU或maxout。此激活功能应用于隐藏层。对于输出层,如果要解决分类问题,请使用SoftMax函数;如果要解决回归问题,请使用线性激活函数。Sigmoid和Tanh不应用于DNNS。这是一个非常有趣的研究领域,有很大的空间来提出伟大的激活功能。
还有其他的激活函数可以检查:标识函数、二进制步进函数、arctan等等。在这里,我们将检查第三个重要概念——损失函数
损失函数
有时,损失函数也被称为成本函数或误差函数。损失函数给我们提供了一个关于给定训练示例的神经网络性能的概念。因此,首先,我们定义了误差函数,当我们开始训练我们的神经网络时,我们将得到输出。我们将生成的输出与作为训练数据一部分给出的预期输出进行比较,并计算该误差函数的梯度值。我们反向传播网络中的误差梯度,以便更新现有的权重和偏差值,以优化生成的输出。误差函数是训练的主要部分。有多种误差函数可用。如果你问我选择哪个错误函数,那么就没有具体的答案,因为所有的人工神经网络训练和优化都是基于这个损失函数。所以这取决于你的数据和问题陈述。如果你问某人你在你的神经网络中使用了哪个误差函数,那么你间接地问他们训练算法的整个逻辑。无论您将使用什么误差函数,请确保该函数必须是可微的。我列出了一些最流行的错误函数:
二次成本函数,又称均方误差或和方误差
交叉熵成本函数,也称为伯努利负对数似然或二进制交叉熵
Kullback-Leibler散度也称为信息散度、信息增益、相对熵或klic。
除此之外,还有许多其他的损失函数,如指数成本、海林格距离、广义Kullback-Leibler散度和Itakura-Saito距离。
一般来说,我们在回归中使用平方和误差,在分类数据和分类任务中使用交叉熵。
9.5 实现神经网络
在本节中,我们将使用numpy作为依赖项在python中实现我们的第一个ANN,在这个实现过程中,您可以将梯度下降、激活函数和损失函数集成到我们的代码中。除此之外,我们将看到反向传播的概念。
我们将看到使用反向传播的单层NN的实现。
9.5.1 单层反向传播神经网络
在一个单层神经网络中,我们有输入,我们把它输入到第一层。这些层连接有一些权重。我们使用输入、权重和偏差,并对它们求和。这个和通过激活函数并生成输出。这是一个重要的步骤;无论生成什么输出,都应该与实际的预期输出进行比较。根据误差函数计算误差。现在使用误差函数的梯度并计算误差梯度。这个过程和我们在梯度下降部分看到的一样。这个误差梯度给出了如何优化生成的输出的指示。误差梯度流回神经网络并开始更新权重,以便在下一个迭代中得到更好的输出。在人工神经网络中,为了产生更精确的输出,通过返回误差梯度来更新权重的过程称为反向传播。总之,后向传播是一种通过梯度下降更新权值来训练神经网络的常用训练技术。
计算和数学的所有其他方面将显示在编码部分。所以让我们用反向传播来编写我们自己的单层前馈神经网络。首先,我们将定义主要功能和抽象步骤。这里,我们将给出输入和输出值。因为我们的数据是标记的,所以它是一个有监督的学习示例。第二步是训练,我们将重复训练,重复10000次。我们将首先从随机权重开始,并根据激活函数和误差函数调整权重。
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
# Seed the random number generator, so it generates the same numbers
# every time the program runs.
random.seed(1)
# We model a single neuron, with 3 input connections and 1 output connection.
# We assign random weights to a 3 x 1 matrix, with values in the range -1 to 1
# and mean 0.
self.synaptic_weights = 2 * random.random((3, 1)) - 1
# The Sigmoid function, which describes an S shaped curve.
# We pass the weighted sum of the inputs through this function to
# normalise them between 0 and 1.
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
# The derivative of the Sigmoid function.
# This is the gradient of the Sigmoid curve.
# It indicates how confident we are about the existing weight.
def __sigmoid_derivative(self, x):
return x * (1 - x)
# We train the neural network through a process of trial and error.
# Adjusting the synaptic weights each time.
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in range(number_of_training_iterations):
# Pass the training set through our neural network (a single neuron).
output = self.think(training_set_inputs)
# Calculate the error (The difference between the desired output
# and the predicted output).
error = training_set_outputs - output
# Multiply the error by the input and again by the gradient of the Sigmoid curve.
# This means less confident weights are adjusted more.
# This means inputs, which are zero, do not cause changes to the weights.
adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output))
# Adjust the weights.
self.synaptic_weights += adjustment
# The neural network thinks.
def think(self, inputs):
# Pass inputs through our neural network (our single neuron).
return self.__sigmoid(dot(inputs, self.synaptic_weights))
#Intialise a single neuron neural network.
neural_network = NeuralNetwork()
print("Random starting synaptic weights: ")
print(neural_network.synaptic_weights)
# The training set. We have 4 examples, each consisting of 3 input values
# and 1 output value.
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
# Python store output in horizontally so we have use transpose
training_set_outputs = array([[0, 1, 1, 0]]).T
# Train the neural network using a training set.
# Do it 10,000 times and make small adjustments each time.
neural_network.train(training_set_inputs, training_set_outputs, 10000)
print("New synaptic weights after training: ")
print(neural_network.synaptic_weights)
# Test the neural network with a new situation.
print("Considering new situation [1, 0, 0] -> ?: ")
print(neural_network.think(array([1, 0, 0])))
Random starting synaptic weights:
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
New synaptic weights after training:
[[ 9.67299303]
[-0.2078435 ]
[-4.62963669]]
Considering new situation [1, 0, 0] -> ?:
[ 0.99993704]
这里,我们使用Sigmoid作为激活函数。我们将使用Sigmoid导数来计算Sigmoid曲线的梯度。我们的损失函数是从生成的输出中减去实际输出。我们用这个误差值乘以梯度得到误差梯度,这有助于我们调整神经网络的权重。新更新的权值和输入再次通过神经网络,计算出Sigmoid曲线的梯度下降和误差梯度,并调整权值直到得到最小误差。
9.5.2 练习
使用numpy作为依赖项构建三层深度人工神经网络。(提示:在单层人工神经网络中,我们使用单层,但在这里,您将使用三层。反向传播通常使用递归取导数,但在我们的单层演示中,没有递归。所以需要应用递归导数。)
9.6 深度学习和深度神经网络
现在,从ANN到DNN。在接下来的部分中,我们将看到深度学习、DNN的体系结构,并比较DL用于NLP和ML用于NLP的方法。
9.6.1 回顾深度学习
我们已经看到了有关DL的一些基本细节。在这里,目的只是为了让你回忆起一些事情。不是两层或三层而是多层深的人工神经网络称为DNN。当我们在大量数据上使用多层深度神经网络时,使用大量的计算能力,我们称之为深度学习过程。让我们看看深层神经网络的结构。
9.6.2 深度神经网络的基本架构
在本节中,我们将看到DNN的体系结构。图形表示看起来很简单,并用一些很酷的数学公式定义,如激活函数、隐层激活函数、损失函数等。在图9.41中,您可以看到DNN的基本架构:

现在为什么我们要使用多层深度神经网络,有什么原因可以这样做吗?有多层的意义是什么?
让我解释一下为什么我们使用多层DNN。假设,作为一名编码人员,您希望开发一个识别水果图像的系统。现在你有了一些橙子和苹果的图像,你开发了一个逻辑,比如我可以使用水果的颜色来识别图像,你还添加了形状作为识别参数。您进行了一些编码,并准备好了结果。现在,如果有人告诉你,我们也有黑白图像。现在您需要重做编码工作。有些种类的图像对你来说太复杂了,作为一个人,无法编码,尽管你的大脑非常擅长识别水果的实际名称。因此,如果你有一个如此复杂的问题,你不知道如何编码,或者你不太了解那些有助于机器解决问题的特征或参数,那么你就使用一个深度神经网络。原因有以下几种:
- DNN是用人脑工作原理的抽象概念推导出来的。
- 使用DNN,我们改变了编码的方法。最初,我们为机器提供颜色、形状等功能,以识别给定图像中的水果名称,但通过DNN和DL,我们为机器提供了许多示例,机器将自己了解这些功能。之后,当我们为机器提供一个新的水果图像时,它将预测水果的名称。
现在,您真的想知道dnn如何自己学习特性,所以让我们重点强调以下几点:
-
DNN使用多层非线性处理单元的级联,用于特征提取和转换。每个连续的DNN层都使用前一层的输出作为输入,这个过程与人脑如何将信息从一个神经元传输到另一个神经元非常相似。所以我们试图在DNN的帮助下实现相同的结构。
-
在DL中,在DNN的帮助下,使用多个表示级别学习了特性。更高级别的特征或表示是从较低级别的特征派生而来的。所以我们可以说,在DNN中派生特征或表示的概念是分层的。我们用这个较低层次的想法学习一些新东西,并尝试学习一些额外的东西。我们的大脑也以层次结构的方式使用和派生概念。这种不同级别的特性或表示与不同级别的抽象相关。
-
DNN的多层有助于机器导出层次表示,这是将多层作为体系结构的一部分的重要性。
-
借助DNN和数学概念,机器能够模拟人脑的某些过程。
-
DL可以应用于有监督和无监督的数据集,以开发NLP应用程序,如机器翻译、总结、问答系统、论文生成、图像标题标记等。
9.6.3 NLP中的深度学习
NLP的早期是基于基于规则的系统,对于许多应用来说,早期的原型是基于基于规则的系统,因为我们没有大量的数据。现在,我们正在应用ML技术来处理自然语言,使用基于统计和概率的方法,在这种方法中,我们以一种热编码格式或共现矩阵的形式表示单词。在这种方法中,我们得到的主要是句法表示,而不是语义表示。当我们尝试基于词汇的方法时,例如词袋、n-grams等等,我们无法区分特定的上下文。
我们希望所有这些问题都能通过DNN和DL解决,因为现在我们有大量的数据可以使用。为了捕捉自然语言的语义方面,我们开发了好的算法,如word2vec、glove等。除此之外,DNN和DL还提供了一些很酷的功能,如下所示:
可表达性:这种能力表示机器对通用函数的逼近程度
可训练性:这种能力对于NLP应用程序非常重要,它表明一个DL系统能够很好、快速地了解给定的问题并开始生成大量的输出。
可归纳性:这表示机器能够很好地归纳给定的任务,以便它能够预测或生成未知数据的准确结果。
除了上述三种功能外,DL还为我们提供了其他功能,如可解释性、模块性、可传输性、延迟、对抗稳定性和安全性。
我们知道语言是复杂的事情,有时我们也不知道如何解决某些NLP问题。这背后的原因是,世界上有如此多的语言,它们有自己的句法结构、单词用法和意义,你不能用同样的方式用其他语言表达。所以我们需要一些帮助我们概括问题并给出良好结果的技术。所有这些原因和因素都引导我们朝着将dnn和dl用于nlp应用的方向发展。
现在让我们看看经典的NLP技术和dl nlp技术之间的区别,因为这将连接我们的点,说明dl在解决与nlp域相关的问题上是如何更有用的。
9.6.4 传统NLP和深度学习NLP技术的区别
在这一节中,我们将比较经典的NLP技术和用于NLP的DL技术。参见图9.42:

在经典的NLP技术中,我们在数据生成特征之前对数据进行了早期的预处理。在下一阶段,我们使用手工制作的特性,这些特性是使用NER工具、POS标记器和解析器生成的。我们将这些特性作为ML算法的输入并训练模型。我们将检查精度,如果精度不好,我们将优化算法的一些参数,并尝试生成更精确的结果。根据NLP应用程序的不同,可以包括检测语言并生成功能的模块。
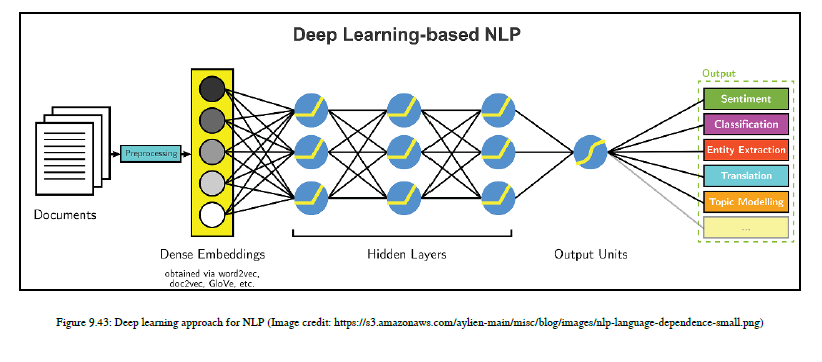
现在,让我们看看NLP应用程序的深入学习技术。在这种方法中,我们对我们拥有的数据进行一些基本的预处理。然后我们将文本输入数据转换为密集向量的形式。为了产生密集向量,我们将使用word2vec、glove、doc2vec等嵌入技术,并将这些密集向量嵌入到dnn中。这里,我们不使用手工制作的特性,而是根据NLP应用程序使用不同类型的dnn,例如机器翻译,我们使用的是dnn的变体,称为序列到序列模型。总而言之,我们使用的是另一种变体,即长短期内存单元(lstms)。DNN的多层概括了目标,并学习了实现定义目标的步骤。在这个过程中,机器学习了层次表示,并给出了根据需要对模型进行验证和优化的结果。下一节是本章最有趣的部分。我们将构建两个主要应用程序:一个用于NLU,另一个用于NLG。我们使用TensorFlow和Keras作为主要依赖项来编写示例代码。我们将理解dnn的变体,例如sequence-to-sequence和LSTM,因为我们对它们进行编码以更好地理解它们。
猜猜我们要建造什么?我们将构建一个机器翻译程序作为NLP应用程序的一部分,我们将从中生成一个摘要。那么让我们跳到编码部分!我会给你做一些有趣的练习!
9.7 深度学习技术和NLU
人类说、写或读的语言太多了。你试过学一门新语言吗?如果是的话,那么你就知道掌握说一种新语言或写一种新语言的技能是多么困难。你有没有想过谷歌翻译是如何被用来翻译语言的?如果您好奇,那么让我们开始使用深度学习技术开发机器翻译应用程序。不要担心我们将使用哪种类型的DNN,因为我正在向您详细解释。我们来翻译一下吧!
注意,DL需要大量的计算能力,所以我们不打算实际训练模型,尽管我将向您详细介绍训练代码,但我们将使用训练模型来复制最终的结果。给你一个想法:谷歌连续一周使用100 GPU来训练语言翻译模型。所以我们通过代码,理解概念,使用一个已经训练过的模型,并看到结果。
9.7.1 机器翻译
机器翻译(MT)是NLU领域中一个广泛应用的领域。研究人员和科技巨头们正在进行大量的实验,以制造一个可以翻译任何语言的单一机器翻译系统。这种机器翻译系统被称为通用机器翻译系统。因此,我们的长期目标是建立一个单一的机器翻译系统,可以把英语翻译成德语,同样的机器翻译系统也应该把英语翻译成法语。我们正试图建立一个能帮助我们翻译任何语言的系统。让我们来谈谈迄今为止研究人员为建立一个通用的机器翻译系统所做的努力和实验。
1954年,进行了第一次机器翻译演示,翻译了250个俄语和英语单词。这是一种基于词典的方法,这种方法使用源语言和目标语言的单词映射。在这里,翻译是逐字进行的,它不能捕获句法信息,这意味着准确性不好。
下一个版本是中间语言;它使用源语言并生成中间语言来编码和表示源语言语法、语法等的特定规则,然后从中间语言生成目标语言。与第一种方法相比,这种方法很好,但很快就被统计机器翻译(SMT)技术所取代。
IBM使用了这种SMT方法;他们将文本分成若干段,然后将其与对齐的双语语料库进行比较。之后,使用统计技术和概率,选择最有可能的翻译。
世界上使用最多的SMT是Google翻译,最近,Google发表了一篇论文,指出他们的机器翻译系统使用深度学习来产生巨大的效果。我们正在使用TensorFlow库,这是一个由Google提供的用于深度学习的开源库。我们将通过编码了解如何使用深度学习进行机器翻译。
我们使用电影字幕作为数据集。此数据集包括德语和英语。我们正在建立一个模型,将德语翻译成英语,反之亦然。您可以从http://opus.lingfil.uu.se/opensubitles.php下载数据。这里,我使用的是pickle格式的数据。使用pickle(依赖于python),我们可以序列化数据集。
首先,我们使用的是用于记住长期和短期依赖关系的LSTMS网络。我们正在使用TensorFlow的内置数据实用程序类对数据进行预处理。然后我们需要定义训练模型的词汇大小,这里,我们的数据集有一个很小的词汇大小,所以我们考虑数据集中的所有单词,但是我们定义词汇(词汇)大小,比如30000个单词,也就是说,一个小的训练数据集。我们将使用data_utils类从数据目录中读取数据。这个类提供两种语言的标记化和格式化单词。然后我们定义TensorFlow的占位符,它是输入的编码器和解码器。这两者都是表示离散值的整数张量。它们被嵌入到密集的表示中。我们将把词汇输入编码器,并将学习到的编码表示输入解码器。以下非原书内容,请参考:
Clone the GitHub Repository:
https://github.com/deep-diver/EN-FR-MLT-tensorflow
MLT (EN to FR ) TensorFlow
In this project, I am going to build language translation model called seq2seq model or encoder-decoder model in TensorFlow. The objective of the model is translating English sentences to French sentences. I am going to show the detailed steps, and they will answer to the questions like how to preprocess the dataset, how to define inputs, how to define encoder model, how to define decoder model, how to build the entire seq2seq model, how to calculate the loss and clip gradients, and how to train and get prediction. Please open the IPython notebook file to see the full workflow and detailed descriptions.
This is a part of Udacity’s Deep Learning Nanodegree. Some codes/functions (save, load, measuring accuracy, etc) are provided by Udacity. However, majority part is implemented by myself along with much richer explanations and references on each section.
You can find only the model part explained in my medium post. https://medium.com/@parkchansung/seq2seq-model-in-tensorflow-ec0c557e560f
Brief Overview of the Contents
Data preprocessing
In this section, you will see how to get the data, how to create lookup table, and how to convert raw text to index based array with the lookup table.
Build model
In short, this section will show how to define the Seq2Seq model in TensorFlow. The below steps (implementation) will be covered.
- (1) define input parameters to the encoder model
enc_dec_model_inputs
- (2) build encoder model
encoding_layer
- (3) define input parameters to the decoder model
enc_dec_model_inputs,process_decoder_input,decoding_layer
- (4) build decoder model for training
decoding_layer_train
- (5) build decoder model for inference
decoding_layer_infer
- (6) put (4) and (5) together
decoding_layer
- (7) connect encoder and decoder models
seq2seq_model
- (8) train and estimate loss and accuracy
Training
This section is about putting previously defined functions together to build an actual instance of the model. Furthermore, it will show how to define cost function, how to apply optimizer to the cost function, and how to modify the value of the gradients in the TensorFlow’s optimizer module to perform gradient clipping.
Prediction
Nothing special but showing the prediction result.
9.8 深度学习技术和NLG
在本节中,我们将为NLG构建一个非常简单但直观的应用程序。我们将从shot文章生成一行摘要。我们将在本节中看到有关汇总的所有详细信息。
这个应用程序花费了大量的训练时间,所以您可以将您的模型放到CPU上进行训练,同时,您还可以执行一些其他任务。如果你没有其他任务,我给你一个。
9.8.1 练习
试着通过提供一些起始字符序列来找出如何生成维基百科文章。别误会我!我是认真的!你真的需要好好想想。
这是您可以使用的数据集:
https://einstein.ai/research/the-wikitext-long-term-dependency-language-modelin
G数据集。跳转到下载部分,下载这个名为下载wikitext-103字级(181MB)的数据集。
(提示:请参阅此链接,https://github.com/kumikokashii/lstm文本生成器。)
别担心,在理解了总结的概念之后,你可以尝试一下。让我们开始总结之旅吧!
9.8.2 菜谱摘要和标题生成
在开始编写代码之前,我想简单介绍一下总结的背景知识。架构和其他技术部分将被理解为我们的代码。
语义在NLP中是一个非常重要的问题。随着数据在文本密度上的增加,信息也会增加。现在,你周围的人真的希望你能在短时间内有效地说出最重要的事情。
文本总结始于90年代,加拿大政府建立了一个名为天气预报生成器(FOG)的系统,该系统使用天气预报数据并生成摘要。这是基于模板的方法,机器只需要填写某些值。让我举个例子,星期六是晴天,有10%的机会下雨。单词阳光和10%实际上是由雾产生的。
其他领域包括金融、医疗等。近年来,医生发现总结病人的病史非常有用,能够有效地诊断病人。
总结有两种类型,如下所示:
Extractive
Abstractive过去的大多数摘要工具都是抽取式的;它们从文章中选择现有的一组单词来创建文章摘要。作为人类,我们做更多的事情;也就是说,当我们总结时,我们构建了一个我们所读内容的内部语义表示。使用这种内部语义表达,我们可以对文本进行总结,这种总结称为抽象总结。因此,让我们使用KERA构建一个抽象的总结工具。
Keras是TensorFlow和Theano的高级包装。这个例子需要多个GPU超过12小时。如果你想在你的终端重现结果,那么它需要大量的计算能力。1. Clone the GitHub Repository:
https://github.com/jalajthanaki/recipe-summarization
2. Initialized submodules:
git submodule update --init -recursive
3. Go inside the folder:
python src/config.p
4. Install dependencies:
pip install -r requirements.txt
5. Set up directories:
python src/config.py
6. Scrape recipes from the web or use the existing one at this link:
wget -P recipe-box/data https://storage.googleapis.com/recipebox/
recipes_raw.zip; unzip recipe-box/data/recipes_raw.zip -d recipebox/
data
7. Tokenize the data:
python src/tokenize_recipes.py
8. Initialize word embeddings with GloVe vectors:
- Get the GloVe vectors trained model:
wget -P data http://nlp.stanford.edu/data/glove.6B.zip;
unzip data/glove.6B.zip -d data - Initialize embeddings:
python src/vocabulary-embedding.py - Train the model:
python src/train_seq2seq.py - Make predictions:
use src/predict.ipynb在这里,对于矢量化,我们使用Glove是因为我们需要一个用于总结的单词的全局级表示,并且我们使用Sequence-to-Sequence模型(seq2seq模型)来训练我们的数据。seq2seq与我们在机器翻译部分讨论的模型相同。我知道总结示例需要大量的计算能力,并且可能会出现本地计算机没有足够内存(RAM)来运行此代码的情况。在这种情况下,不用担心;您可以使用各种云选项。您可以使用Google Cloud、Amazon Web Services(AWS)或任何其他服务。现在您对NLU和NLG应用程序有了足够的了解。我还在此Github链接上放置了一个与NLG域相关的应用程序:
https://github.com/tensorflow/models/tree/master/im2xt
此应用程序生成图像标题;这是一种计算机视觉和NLG的组合应用程序。Github上有必要的详细信息,所以也可以查看这个例子。
在下一节中,我们将看到基于梯度下降的优化策略。
TensorFlow为我们提供了梯度下降算法的一些变体。一旦我们了解了所有这些变体是如何工作的,以及它们各自的缺点和优势是什么,那么我们就可以很容易地为我们的dl算法的优化选择最佳选项。让我们来了解基于梯度下降的优化。
9.9 基于梯度下降的优化
在本节中,我们将讨论TensorFlow提供的基于梯度下降的优化选项。最初,您不清楚应该使用哪种优化选项,但是当您了解DL算法的实际逻辑时,它会变得更加清晰。
我们使用基于梯度下降的方法来开发一个智能系统。使用此算法,机器可以学习如何从数据中识别模式。在这里,我们的最终目标是获得局部最小值,目标函数是机器将要做出的最终预测或机器生成的结果。在基于梯度下降的算法中,我们并不是集中在如何在第一步实现目标函数的最佳最终目标上,而是通过迭代或反复的小步骤,选择中间的最佳选项,使我们获得最终的最佳选项,即我们的局部极小值。这种有教育意义的猜测和检验方法很好地获得了局部极小值。当dl算法得到局部极小值时,可以得到最佳的结果。我们已经看到了基本的梯度下降算法。如果面临过拟合和欠拟合的情况,可以使用不同类型的梯度下降来优化算法。有各种各样的梯度下降方式,可以帮助我们生成理想的局部极小值,控制算法的方差,更新我们的参数,并引导我们收敛我们的ML或DL算法。让我们举个例子。如果函数y=x2,那么给定函数的偏导数是2x。当我们随机猜测状态值时,我们从x=3开始,然后y=2(3)=6,为了得到局部极小值,我们需要朝负方向迈出一步,所以y=6。在第一次迭代之后,如果你猜到x=2.3,那么y=2(2.3)=4.6,我们需要再次向负方向移动——y=-4.6——因为我们得到了一个正值。如果我们得到一个负值,那么我们就朝着正值移动。经过一定的迭代,y的值非常接近于零,这就是我们的局部极小值。现在我们从基本梯度下降开始。让我们开始探索各种梯度下降。
9.9.1 基本梯度下降
在基本梯度下降中,我们根据整个训练数据集中存在的参数计算损失梯度函数,我们需要计算整个数据集中的梯度来执行单个更新。对于单个更新,我们需要考虑整个训练数据集以及所有参数,因此速度非常慢。如图9.58所示:

您可以在图9.59中找到用于理解目的的示例逻辑代码:

由于该方法速度较慢,我们将引入一种新的技术,称为随机梯度下降。
9.9.2 随机梯度下降
在这种技术中,我们更新每个训练示例和标签的参数,因此我们只需要为我们的训练数据集添加一个循环,这种方法更新参数的速度比基本梯度下降更快。如图9.60所示:
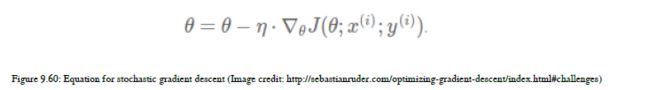
您可以在图9.61中找到用于理解目的的示例逻辑代码:

这种方法也有一些问题。这种方法使得收敛复杂,有时参数更新太快。该算法可以超越局部极小值并保持运行。为了避免这个问题,另一种方法被称为小批量梯度下降。
9.9.3 小批量梯度下降
在这种方法中,我们将从基本梯度下降和随机梯度下降两个方面得到最好的部分。我们将把训练数据集的一个子集作为批处理,并从中更新参数。这种梯度下降用于神经网络的基本类型,如图9.62所示:

您可以在图9.63中找到用于理解目的的示例逻辑代码:

如果我们有一个高维数据集,那么我们可以使用其他的梯度下降方法;让我们从动量开始。
9.9.4 动量
如果所有可能的参数值的曲面曲线在一个维度上比在另一个维度上陡得多,那么在这种情况下,这在局部最优中非常常见。在这些情况下,SGD在斜坡上振荡。为了解决这个振荡问题,我们将使用动量法。如图9.64所示:
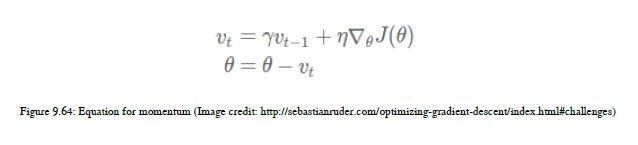
如果你看到这个方程,我们将从上一个时间步到当前步的梯度方向的一个分数相加,然后我们在正确的方向放大参数更新,从而加快收敛速度并减少振荡。在这里,动量的概念与物理学中动量的概念相似。当获得局部极小值时,这种变化不会减慢,因为此时动量很高。在这种情况下,我们的算法可以完全忽略局部极小值,而这个问题可以通过Nesterov加速梯度来解决。
9.9.5 Nesterov加速梯度
这种方法是Yurii Nesterov发明的。他试图解决动量技术中出现的问题。他发表了一篇论文,你可以在这个链接上看到:你可以在图9.65中看到等式:
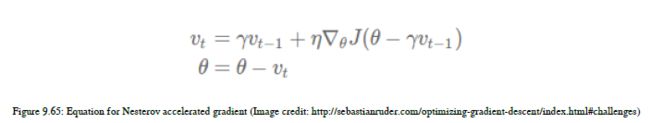
正如你所看到的,我们做的计算和动量的计算是一样的,但是我们改变了计算的顺序。在动量中,我们计算梯度使动量放大的那个方向上的跳跃,而在Nesterov加速梯度法中,我们首先根据先前的动量进行跳跃,然后计算梯度,然后添加修正并生成参数的最终更新。这有助于我们更动态地提供参数值。
9.9.6 Adagrad
Adagrad代表自适应梯度。该方法允许学习率根据参数进行调整。该算法对不常用参数进行大更新,对常用参数进行小更新。如图9.66所示:

该方法根据对该参数计算的过去梯度,为给定时间戳的每个参数提供不同的学习速率。在这里,我们不需要手动调整学习速度,尽管它有限制。根据方程,学习率总是随着分母中平方梯度的累积总是正的而下降,并且随着分母的增长,整个学期都会下降。有时,学习率变得非常小,以至于ML模型停止学习。解决这个问题。图中出现了名为adadelta的方法。
9.9.7 adadelta
adadelta是adagrad的扩展。在Adagrad中,我们不断地将平方根加到和上,导致学习率下降。我们没有求和所有过去的平方根,而是将窗口限制为一个固定大小的累积过去梯度。您可以看到图9.67中的公式:
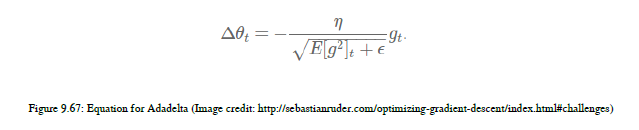
正如你在方程中看到的,我们将使用梯度之和作为所有过去平方梯度的衰减平均值。在这里,给定时间戳的运行平均值e[g2]t取决于以前的平均值和当前的梯度。
在看过所有的优化技术之后,你知道我们如何计算每个参数的单个学习率,如何计算动量,以及如何防止学习率的衰减。尽管如此,通过应用一些自适应动量还有改进的空间,这将引导我们找到最终的优化方法Adam。
9.9.8 Adam
Adam代表自适应动量估计。当我们计算每个参数的学习速率时,我们也可以分别存储每个参数的动量变化。您可以看到图9.68中的方程式:
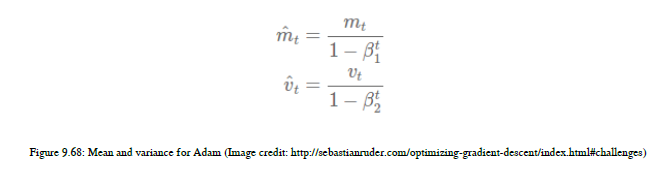
首先,我们将计算梯度的平均值,然后我们将计算梯度的非中心方差,并使用这些值更新参数。就像一个三角洲。你可以在图9.69中看到Adam的方程:
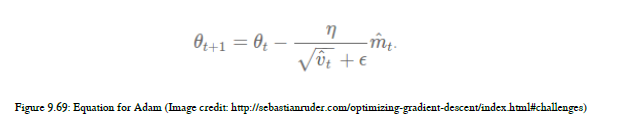
所以现在你想知道我们应该使用哪种方法;根据我的说法,亚当是最好的整体选择,因为它优于其他方法。您也可以使用adadelta和adagrad。如果您的数据是稀疏的,那么您不应该使用sgd、momentum或nesterov。
9.10 人工智能与人类智能
从过去的一年开始,你可能听到过这种问题。在人工智能领域,这类问题已经变得普遍。人们大肆宣传人工智能将使人类消失,机器将夺走我们所有的力量。现在让我告诉你,这不是事实。这些威胁听起来像科幻小说。据我所知,人工智能正处于高速发展阶段,但其目的是为了补充人类,使人类生活更容易。我们仍在研究宇宙中一些复杂和未知的真理,这些真理可以帮助我们对如何构建辅助系统提供更多的见解。所以人工智能将完全帮助我们。人工智能肯定会让我们的生活大吃一惊,但它不会很快被它的发明所淹没。因此,享受这个人工智能阶段,以积极的方式为人工智能生态系统做出贡献。
人们担心人工智能会夺走我们的工作。它不会夺走你的工作。这会使你的工作更容易。如果你是一名医生,想在一些癌症报告上发表最后一句话,人工智能将帮助你。在信息技术(IT)行业,有一种担忧,即人工智能将取代编码器。如果你相信,研究人员和科技公司很快就能制造出比人类更强大的机器,而且人工智能的转变很快就会发生,机器将夺走我们的工作,那么你最好能获得ML、DL和AI相关技能集来工作,也许你是这个星球上最后一个拥有S的人。我要做的工作!我们假设人工智能会夺走一些就业机会,但这种人工智能生态系统也会创造许多新的就业机会。所以别担心!这个讨论可以继续进行,但我想给你们一些时间来思考这个问题。
9.11 总结
恭喜你们!我们已经读到最后一章了!我非常感谢你的努力。在这一章中,你学到了很多东西,比如人工智能方面,它们帮助你理解为什么深度学习是当今的流行词。我们已经看到了人工神经网络的概念。我们已经看到了诸如梯度下降、各种激活函数和损失函数等概念。我们已经看到了dnn和dl生命周期的结构。我们还讨论了sequence-to-sequence模型的基础知识,并开发了机器翻译、标题生成和摘要等应用程序。我们还看到了基于梯度下降的优化技术。
接下来的部分是附录A到C,它将向您提供有关框架(如Hadoop、Spark等)的概述。您还可以看到这些框架以及其他工具和库的安装指南。除此之外,如果您不熟悉Python,您还可以找到许多Python库的备忘表,这些备忘表非常方便。如果你真的想提高你的数据科学和NLP技能,我有一些建议。我还在附录中提供了Gitter链接,您可以使用它与我联系,以防您有任何问题。
致谢
《Python自然语言处理》1 2 3,作者:【印】雅兰·萨纳卡(Jalaj Thanaki),是实践性很强的一部新作。为进一步深入理解书中内容,对部分内容进行了延伸学习、练习,在此分享,期待对大家有所帮助,欢迎加我微信(验证:NLP),一起学习讨论,不足之处,欢迎指正。

参考文献
https://github.com/jalajthanaki ↩︎
《Python自然语言处理》,(印)雅兰·萨纳卡(Jalaj Thanaki) 著 张金超 、 刘舒曼 等 译 ,机械工业出版社,2018 ↩︎
Jalaj Thanaki ,Python Natural Language Processing ,2017 ↩︎