CSDN课程学习——知识点小结
1.补码运算

给定负数求原码:负数加绝对值 算出此时它的原码 再 取反 加1 则为 此负数的原码.
给定原码求负数:负数原码取反加一既可.
2.一个浮点数由三个基本成分构成:符号(sigh) 阶码(exponent) 尾数(mentissa)
3.整形常量


4.printf


当实际宽度大于域宽的时候,按实际输出
其中的[标志]

5.scanf

注意 有%c时可以使用空格隔开
例如 %c%c需变为%c %c 或者%d%c 变为%d %c
6.putchar(10);意为换行.
7.隐式转换

8.强制转换

以上实例表明 计算机存储浮点数时会有不准确的现象
使用强制转换 一般是对程序的补救措施。
末尾练习:

返回值为4321
解释:首先输出i,43,这是两位数,然后返回值是2,输出2,这时是1位数,输出1
9.算数运算符
1.+++在编译原理上叫大嘴法则, 例如a+++b 计算机在运行a+的时候发现后面不是一个表达式,随后将后面的吃掉 变成a++尝试看看能否运算 .
2.不要写自己看不懂,又不知道机器怎么运行,又不知平台差异的东东。
10.排序 以及排序的优化
图二是图一的优化版 (比较而不一一替换)


11.线性查找

思路是遍历全数组 找到返回idx 没找到返回-1
12.折半查找

条件:数组需要已经排序好的
思路:由数组中间开始 比较中间元素与查找元素大小 大于查找元素则右边界限变为中间元素的前一个 然后继续折半查找 最后看返回的midIdx即可
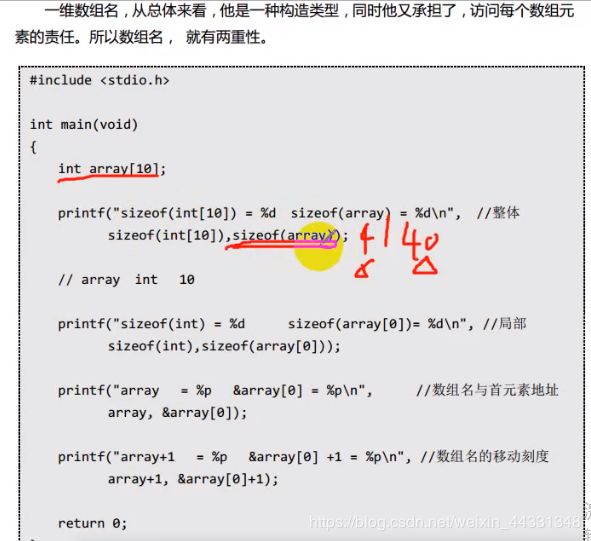
13.数组
数组的三要素:范围 步长(类型) 起始地址
14.指针
指针的实质是 有类型的地址

指针是一个int型 即4个单元的地址 0x12345678 分为 12 34 56 78 分别从上到下存在单元里面 char为一个单元 从内存底开始读取 即78 short int 类似

指针地址+1 则为加一个int型的长度
常量+1则 数值+1
对于指针的理解:
int *p 相当于 ((int)0x12345678)
*p中的 * 相当于 计算机中默认4字节的存储
int *p中的int即指针的类型
所以p相当于0x12345678 是一个地址 则p是一个地址
*p为地址里面的内容
知识点:
注意区别 数值+1 和指针+1
指针+1 是步长 加的是步长(类型)
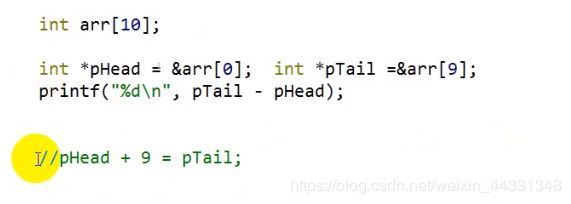
可以清楚地理解 开始读取头部是内存单元的底部 指针的相减为内存单元的相差 不能以单看他的数值差距

一位数组中 arr表示arr[0]的地址 相当于对arr[0]取地址 即&arr[0]
intpa =&arr[0] arr[0]是int型 对它&取地址相当于使用 int 对它取地址 所以pa是一个地址 所以有pa=&arr[0];
arr是数组名用时也是数组的起始地址


指针与数组

((arr+1)+j) 表示的是内容
使用指针打印数组的方法(一位数组)

注意此小结是对于一位数组的
1.第5.6点 可以与前面 arr+1 和 arr[0]+1 前者是地址+类型(步长) 后者为arr[0]这个值加1
对于二维数组

二维数组 arr[0]+1 这是arr[0][1]
arr+1则为arr[1][0]
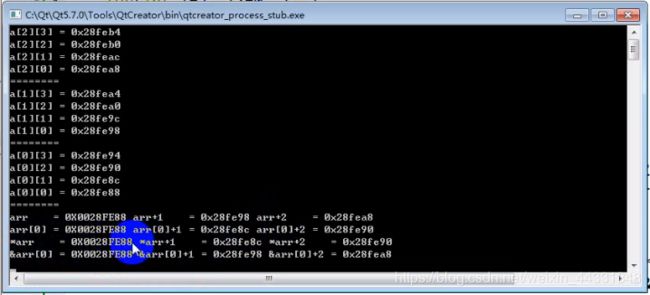
1.二维数组中 *arr+1 即为arr[0][1] *arr+2 即为arr[0][2]的地址
2.而&arr[0]+1 则表示 arr[1][0]的洞中 &arr[0]+2 表示arr[2][0]的地址
3.arr+2 到 (arr+2) 意为解引用
4.((*arr+2)+1) ——>arr[2][1] 即第三行第二列 ——>A[n] == *(A+n)
5.二维数组名的本质是二维指针
二维数组小结

15.随机数


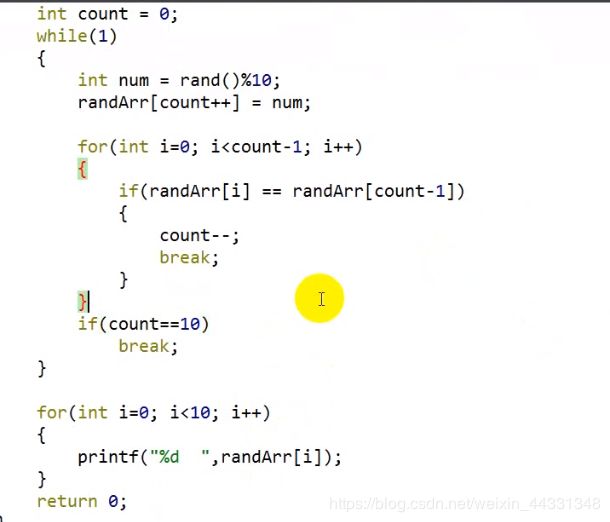
随机产生10个不相同个位数的整数 并打印出来
思路:若产生的数值相同则 数组位置退一位重新进行while循环 直到到达数组个数break退出
16.函数的作用

17.常用的库函数
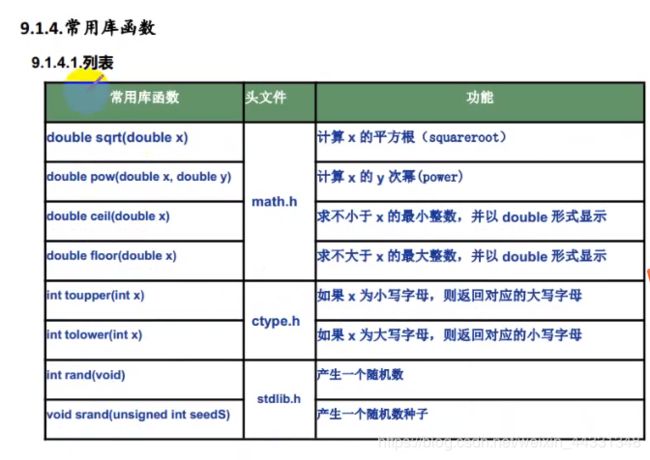
18.关于函数的知识

还需注意一点:地址对于不同作用域来说,总是开放的
19.调用函数中如何调用数组(一维)

下列是调用数组的正确方法

其sizeof的值相等 表明为传地址
二维数组的调用方法(暂放)


20.函数的调用

函数的调用 return 时再进入本身的调用而不会去计算后面的运算 (如图的+2) 而是等到函数调用结束返回时候 才真正进行值的运算
还需注意以下例题

输出结果为 0 2 5 10
注意点为:当调用完成返回时候的值 是在返回到当前函数的内容(值)
例如 最后i=0 调用一次打印0后 继续return回上一层函数 而此时的i值是当前函数的i值为2 以此类推。
Day9的知识点

auto 只能修饰局部变量 可以省略,局部变量若无其他的修饰,则默认为auto 特点是随用随开,用完即消 这是在C中的 而C++中又有新的定义

register 可以将内存中的变量升级到CPU寄存器中储存,这样访问速度会更快,但由于CPU寄存器数量相当有限,通常会在程序优化阶段,被优化为auto类型变量

extern 可以将在该文件中没有定义的变量 先通过编译 例如p(a)调用a 但是并没有定义a 这时可以加 extern 类型 a; 将其编译通过




static的一个案例
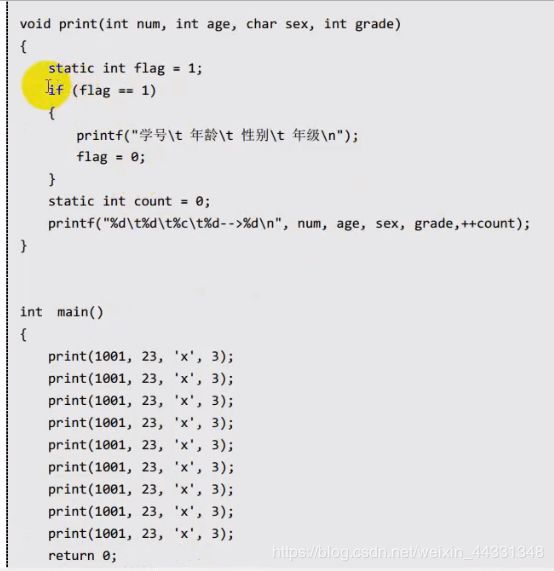
static的功能: 调用次数案例,或是加载资源文件 也可以限制全局变量的外延性 、

字符串与数组
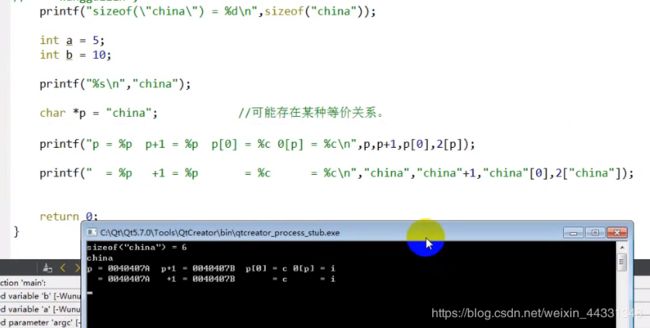



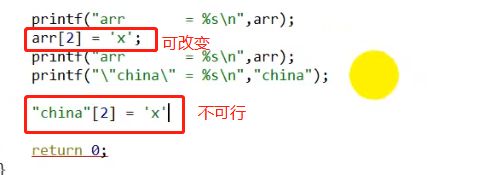

将data rodata的一串字符,拷贝到arr代表的字符串中,此时操作字符数组,就等于操作一个字符串







Day10的知识小结
strlen的自实现

以下是优化版


strcat的自实现

更简化的strcat

strcpy的自实现

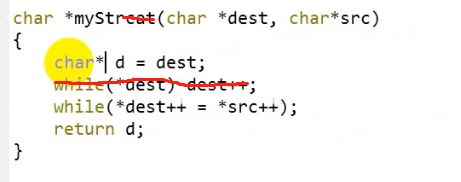
strcmp自实现
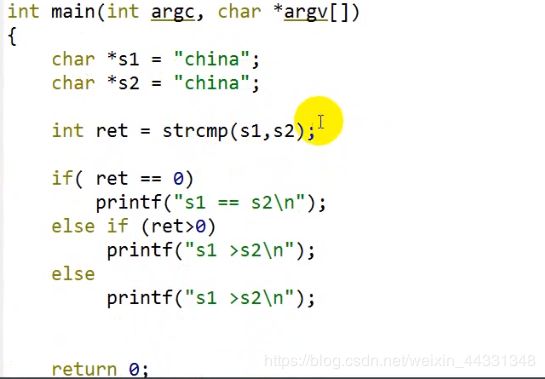





多文件编程xx.h与xx.c


‘0’表示48

栈内存与堆内存的基本概念
1.栈的大小并不大,它的意义在于数据交换 从高地址向低地址储存
2.堆大小,是想象中的无穷大,对于栈来说,大空间申请 ,唯此无它耳 从低地址向高地址储存,但实际使用时,受限于实际内存的大小和内存是否连续性
堆内存的申请malloc以及有关知识
1.malloc 申请和初始化的最小单元均是字节
2.12345678 每两个分别为一个字节 int为4个字节

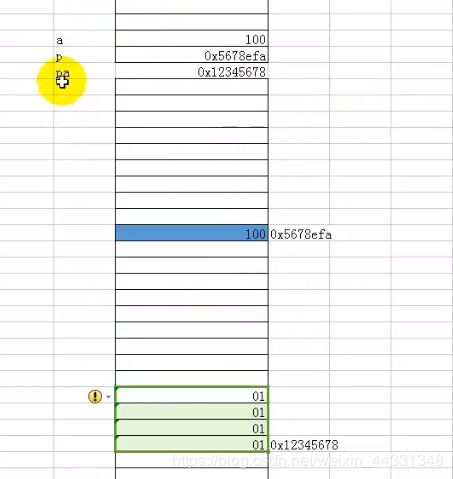
1.pa本身在栈上 申请的东西在堆上 相当于把堆的地址放在栈的pa里面 对pa输入数据相当于对堆输入
2.去pa里面内容时pa[i]不可用*pa++代替 地址++ 相当于移动堆内的地址 一直到数组的最后(pa地址的尾部)才 free掉 而此时后台 在堆里面寻首地址到尾地址储存的数据时候已经找不到了 所以会挂掉 ,不可以使用
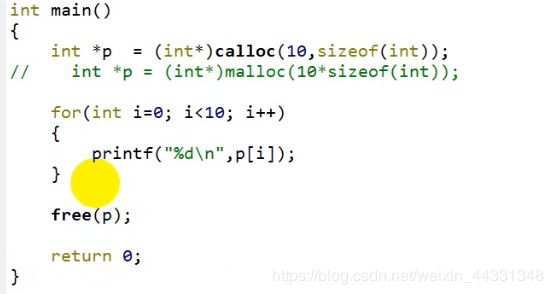
3.堆申请之后 记得free掉

4.使用格式


malloc中 堆内存使用的逻辑是:申请判空,使用,释放,置空
5.给一个字符串申请堆内存的模板
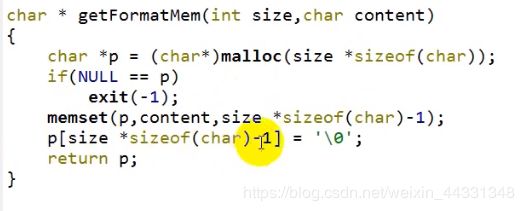
6.calloc 在malloc之上 多加一个初始化0
7.realloc用法以及优化

有可能是在原有空间后面增加大小
也可能原有的没有空间了 则开辟一个新的空间
为了避免增加空间而原有的空间不足以增加的情况 做了以下优化

堆内存常见的错误与栈空间返回
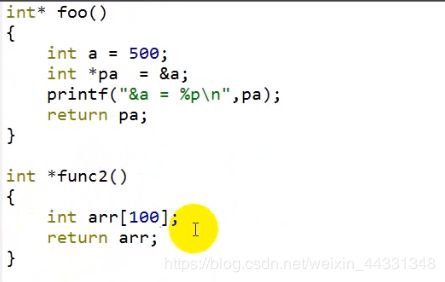
地址可以返回 但是栈上的空间不可返回 即不可再对这段地址进行赋值等操作,原理是函数 随用随开 用完即消
总结:

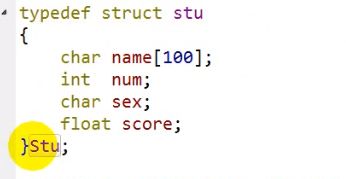
结构体以及结构体类型定义




下列定义的使用方法

为了方便以及程序的整洁性引入了一下优化

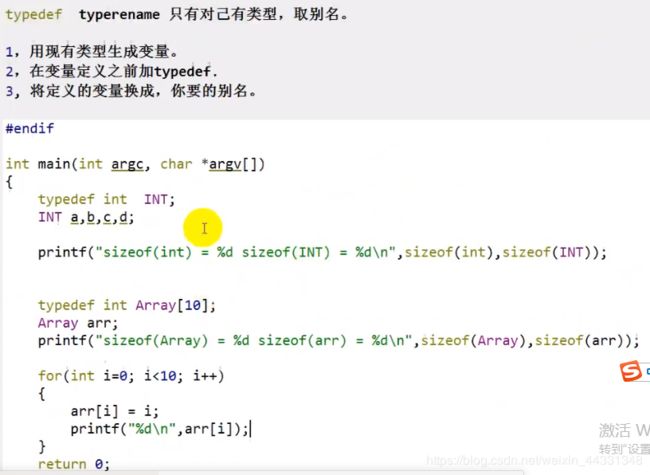
typedef 实际就是定义后面的变量或指针与 原先(INT)的类型相同
typedef与define的区别:

上图char* m,n; 原来 Dpchar m,n;
define的本质:将char* 换到Dpchar的位置
分别来char* m 和 char n;

结构体的初始化以及赋值传参作返回值


(对应上面名字以及定义不同 ,只参考定义)
不可以s.name="???"的原因 :例如 char arr[10]=“china” 是初始化 而不是赋值
当一个指针指向一个结构体时
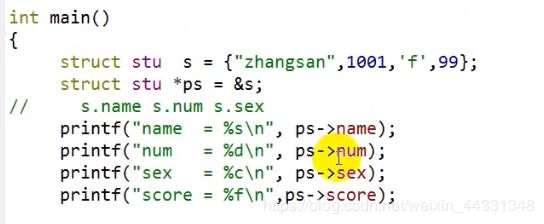
使用访问指向成员运算符 ->
又因为*pa=s s.name 相当于 *ps.name *ps->name 等同于 s.name

结构体申请堆内存的格式


以下为运用typedef的优势
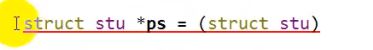
![]()




链表
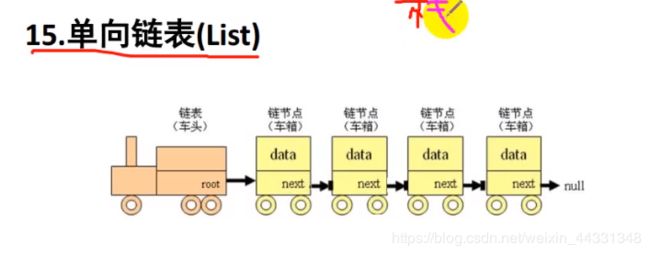
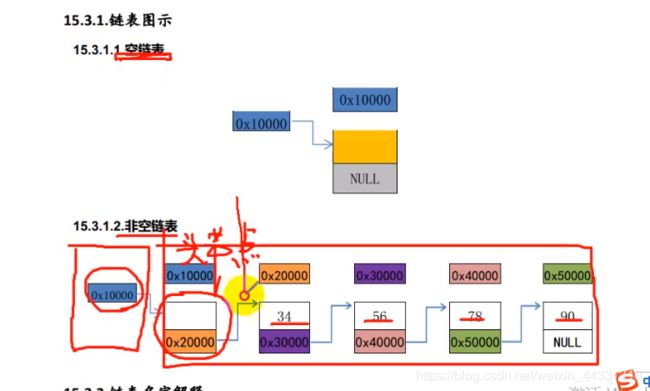

链表的应用:
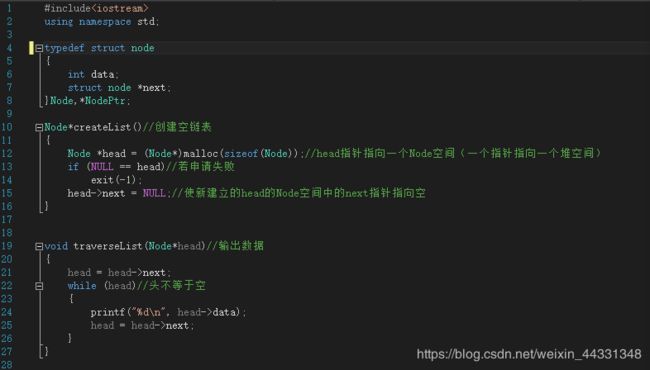
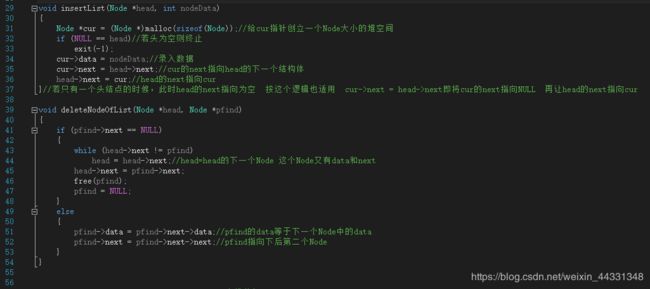




Day14知识点


其中 \n和flcose(); 都有刷缓存的功能











文件加密


fgets的使用方法



fgets常见问题

这种情况可能输入相同但是 登录失败 原因是fgets时候后面可能会有\t 此时过滤掉即可
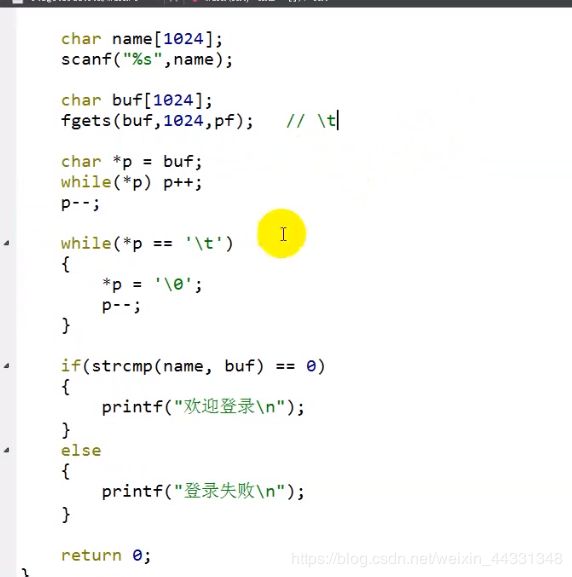
先到buf \0的前一个 在判断是不是\t 在进行操作
类似例题:

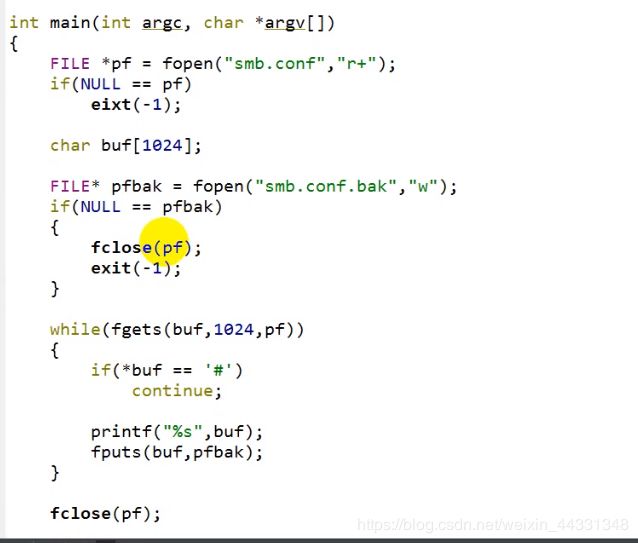
若第二个打开失败了 就关闭第一个
对于以上的操作可以应用一个函数解决

fwrite 和 fread的使用
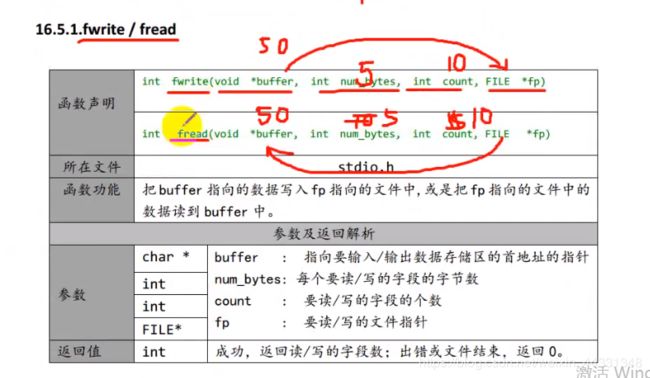

第一个fputs到\0结束 (puts遇到\0结束)
第二个fgets到\n 停止(以行的形式读取)
fwrite和fread则会过滤掉一些符号 例如\n \0 \t 等等

fputs((char*)arr,pf) 不可行 因为arr此时并不是一个字符串 不能读取他的一行数据进入



结论:前面最好写最小字节数 即类型的单位


Day16





左移

右移

左右移若移动位数高于32则取余

左右移 本质不改变本身数值 只有赋值号“=”的时候才赋值
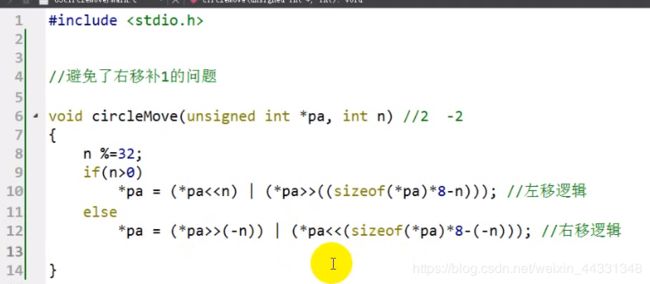
unsigned 无字符 右边不会补1.
32位机器 照妖镜

无参交换


简单的字符串加密

头文件内容




