Python-线性判别分析(Fisher判别分析)使用鸢尾花数据集 Iris
本博客运行环境为Jupyter Notebook、Python3。使用的数据集是鸢尾花数据集。
目录
- 线性判别分析
- 代码实现
- 缺少一组数据的问题已解决!代码已更新!
线性判别分析
线性判别分析(Linear Discriminant Analysis,简称LDA)是一种经典的线性学习方法,在二分类问题.上因为最早由[Fisher, 1936]提出,亦称“Fisher判别分析”。
LDA的基本思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
下图是LDA的二维示意图,“+”、“-”分别代表正倒和反倒,椭圆表示数据簇的外轮廓,虚线表示投影,红色实心圆和实心三角形分别表示两类样本投影后的中心点。

线性判别函数的一般形式可以表示为:
g ( X ) = W T X + w 0 g(X)=W^TX+w_{0} g(X)=WTX+w0
其中,

Fisher选择投影方向W的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求。
(1)W的确定
各类样本均值向量mi

样本类内离散度矩阵 Si 和总类内离散度矩阵 Sw

样本类间离散度矩阵 Sb

在投影后的一维空间中,各类样本均值

样本类内离散度和总类内离散度

样本类间离散度

Fisher准则函数为

(2)阈值的确定
W0 是个常数,称为阈值权,对于两类问题的线性分类器可以采用下属决策规则:

如果g(x)>0,则决策x属于W1;如果g(x)<0,则决策x属于W2;如果g(x)=0,则可将x任意分到某一类,或拒绝。
(3)Fisher线性判别的决策规则
Fisher准则函数满足两个性质:
1.投影后,各类样本内部尽可能密集,即总类内离散度越小越好。
2.投影后,各类样本尽可能离得远,即样本类间离散度越大越好。
根据性质确定准则函数,根据使准则函数取得最大值,可求出

这就是Fisher判别准则下的最优投影方向。
得到决策规则
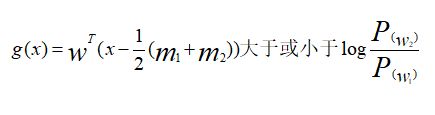
若上述规则成立,则有
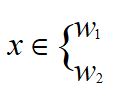
对于某一个未知类别的样本向量x,如果y=WT·x>y0,则x∈w1;否则x∈w2。
(4)“群内离散度”与“群间离散度”
“群内离散度”要求的是距离越远越好;而“群间离散度”的距离越近越好。
“群内离散度”(样本类内离散矩阵)的计算公式为
S i = ∑ x ∈ X i ( x − m i ) ( x − m i ) T S_i=\sum_{x∈X_i}(x-m_i)(x-m_i)^T Si=x∈Xi∑(x−mi)(x−mi)T
因为每一个样本有多维数据,因此需要将每一维数据代入公式计算后最后在求和即可得到样本类内离散矩阵。存在多个样本,重复该计算公式即可算出每一个样本的类内离散矩阵。
“群间离散度”(总体类离散度矩阵)的计算公式为
S w i j = S i + S j S_wij=S_i+S_j Swij=Si+Sj
代码实现
例如鸢尾花数据集,将数据集分为三类样本,然后得到三个总体类离散度矩阵,三个总体类离散度矩阵根据上述公式计算即可。
IRIS数据集以鸢尾花的特征作为数据来源,数据集包含150个数据集,有4维,分为3 类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中非常常用的测试集、训练集。
Python代码如下:
df = pd.read_csv(r’Iris.csv’,header = None)这句是数据集存储路径,我已将数据集保存为.csv文件,需要修改为自己的路径。若使用sklearn库引用可以参看后面的代码。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#path=r'Iris.csv'
#df = pd.read_csv(path, header=None)
df = pd.read_csv(r'Iris.csv',header = None)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
#s2=s2+np.dot((Iris2[i,:]-m2).T,(Iris2[i,:]-m2))
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及T
#需要先将m1-m2转化成矩阵才能进行求其转置矩阵
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
#print(m1+m2) #1x4维度 invsw12 4x4维度 m1-m2 4x1维度
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(30,50):
x=Iris1[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
kind1=kind1+1
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
#print(newiris1)
for i in range(30,50):
x=Iris2[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
kind2=kind2+1
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,50):
x=Iris3[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
kind3=kind3+1
correct=(kind1+kind2+kind3)/60
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print('-----------------------------------------------------------------------------------------------')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('-----------------------------------------------------------------------------------------------')
print('判断出来的综合正确率:',correct*100,'%')
sklearn库引入数据集:
只需替换引入数据集的部分代码。
from sklearn.datasets import make_multilabel_classification
from sklearn import datasets
iris_datas = datasets.load_iris()
x, y = make_multilabel_classification(n_samples=20, n_features=2,
n_labels=1, n_classes=1,
random_state=2) # 设置随机数种子,保证每次产生相同
运行结果如下:

缺少一组数据的问题已解决!代码已更新!
原始代码主要是文件导入那儿的问题。header=0改为header=None;如果还有错,需要把path更改为df = pd.read_csv(r’Iris.csv’,header = None),直接使用数据集。
我这输出的综合准确率只有91.6%,而有些同学比较好的能有96.7%。我一开始怀疑是数据集少了一组数据的原因,后面发现确实少了一组数据,在excel中打开数据集完整,但是运行起来就少一组。但别人使用该数据集时没有出现这种情况。我只好换成sklearn引入数据集,然而输出结果是一致的。不得而解。若有知道该问题的小伙伴,希望可以指导我一下哦。

参考教程:机器学习-西瓜书-周志华