学习笔记-MySQL数据库入门实战
文章目录
- 一、MySQL介绍与安装配置
- 1.MySQL简介
- 2.MySQL的安装与配置
- 二、数据库与表的基本操作
- 1.DDL之数据库
- 2.DDL之数据表
- 3.DML:插入、修改、删除数据
- 4.数据完整性
- 三、数据查询语言
- 1.简单查询
- 2.条件查询(单条件,多条件)
- 3.IN和LIKE的使用
- 4.MySQL常用函数讲解
- 5.查询结果与分页
- 6.GROUP BY与HAVING的使用
- 7.GROUP_CONCAT函数的使用
- 8.使用DISTINCT去除重复数据
- 9.表连接(内连接、外连接、自连接)
- 10.自连接查询的场景及使用
- 11.子查询EXISTS和IN的使用
- 四、数据控制语言DCL
- 1.用户管理
- 2.权限管理(授予与回收)
- 3.禁止ROOT用户远程登录
- 4.忘记root用户密码的解决方法
- 五、索引的使用
- 1.慢查询日志
- 2.查询分析器EXPLAIN
- 3.索引的基本使用
- 4.复合索引前导列特性
- 5.覆盖索引
- 六、MySQL高级进阶
- 1.事务控制
- 2.分区表
- 3.视图
- 4.存储过程的基本使用
- 5.存储过程实战:给指定用户发邮件通知
- 6.触发器实战:给新用户发邮件
- 7.预处理(绑定变量)
- 8.查询缓存
- 9.复制表的几种方式
- 10、导出数据
- 11.定时备份数据库
- 12.导入数据
- 13.字符集
- 14.SQL注入
- 15.如何恢复误删的数据
- 16.审计功能
- 17.MySQL图形化管理工具
- 18.Windows下my.ini配置文件修改后无法启动的问题解决
- 七、MySQL 8.0新特性
- 1.MySQL8.0 新特性
- 2.Navicat无法连接MySQL 8.0的问题解决
- 3.默认字符集utf8mb4
- 4.原子DDL
- 5.NoSQL文档存储
一、MySQL介绍与安装配置
1.MySQL简介
- MySQL是一个小型关系型数据库管理系统(RDBMS),开发者为瑞典MySQL AB公司。在2008年
1月16号被Sun公司收购,而2009年,SUN又被Oracle收购。 - 目前MySQL被广泛地应用在Internet上的中小型网站中,由于其体积小、速度快、总体拥有成本低,
尤其是开放源码这一特点,许多中小型网站为了降低成本而选择MySQL数据库。
2.MySQL的安装与配置
- MySQL最新版本8.0.18的下载地址
- 启停MySQL服务
- 图形界面
1.启动windows的【服务】
a)dos窗口执行:services.msc
b)依次点击控制面板-管理工具-服务
2.右键启停mysql服务 - 2.命令行
- 图形界面
#启动mysql服务:
net start mysql80
#停止mysql服务:
net stop mysql80
二、数据库与表的基本操作
1.DDL之数据库
- SQL是Structured Query Language的缩写,即结构化查询语言。SQL是一门标准的计算机语言,
用于访问和操作数据库,其主能包括数据定义、数据操纵、数据查询和数据控制。 - 按照功能用途,可以将SQL语言分为4类:DDL、DML、DQL和DCL。

- 在DDL中,对数据库的操作主要有两种:创建和删除。
#创建数据库
CREATE DATABASE 数据库名
#删除数据库
DROP DATABASE 数据库名
2.DDL之数据表
- 在创建数据表时,准确的定义字段的数据类型是非常重要的。MySQL支持多种数据类型,但大致可以分为3类:数值、日期/时间和字符串(字符)类型。
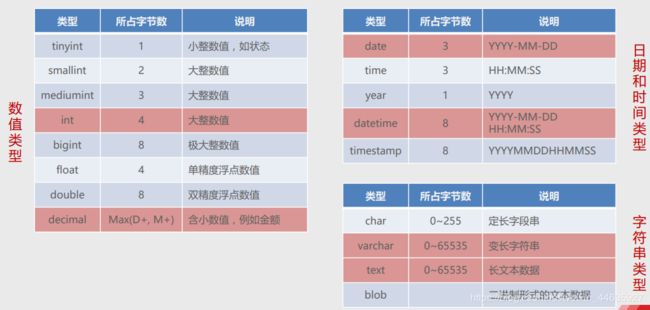
- 创建数据表,需要定义的信息主要包括:表名、字段名、字段类型。
#MySQL的建表语法
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name [(create_definition,…)] [table_options]
[select_statement]
说明:
TEMPORARY:表示创建临时表,在当前会话结束后将自动消失
IF NOT EXISTS:在建表前,先判断表是否存在,只有该表不存在时才创建
create_definition:建表语句的关键部分,用于定义表中各列的属性
table_options:表的配置选项,例如:表的默认存储引擎、字符集
select_statement:通过select语句建表
- 对于已经存在的表,可以使用alter命令添加、修改、删除字段,也可以对表进行删除操作。
#添加字段sex,类型为VARCHAR(1)
ALTER TABLE contacts ADD sex VARCHAR(1);
#修改字段sex的类型为tinyint
ALTER TABLE contacts MODIFY sex tinyint;
#删除字段sex
ALTER TABLE contacts DROP COLUMN sex;
#删除contacts表
DROP TABLE contacts;
3.DML:插入、修改、删除数据
- 在MySQL中,使用insert into语句向数据表中插入数据。
#INSERT 插入单条数据:
INSERT INTO table_name (field1, field2, ..., fieldN) VALUES (value1, value2, ..., valueN);
#INSERT 插入多条数据:
INSERT INTO table_name (field1, field2, ..., fieldN) VALUES (valueA1, valueA2, ..., valueAN), (valueB1,valueB2, ..., valueBN), …, (valueN1, valueN2, ..., valueNN);
注意事项:
1、如果字段是字符型,值必须使用单引号或者双引号,如”value”;如果值本身带单引号或双引号,需要转义
2、如果所有列都要添加数据,insert into语句可以不指定列,即 INSERT INTO table_name VALUES (value1, value2, ..., valueN);
- 在MySQL中,使用update语句来修改数据表中的数据。
#update语法:
UPDATE table_name SET field1=newValue1, field2=newValue2 [WHERE Clause]
注意事项:
1、可以同时更新一个或多个字段
2、可以通过where子句来指定更新的范围,如果不带where,则更新数据表中的所有记录
- 在MySQL中,使用delete语句来删除数据表中的数据。
#delete语法:
DELETE FROM table_name [WHERE Clause]
注意事项:
1、可以通过where子句来指定删除的范围,如果不带where,则删除数据表中的所有记录
4.数据完整性
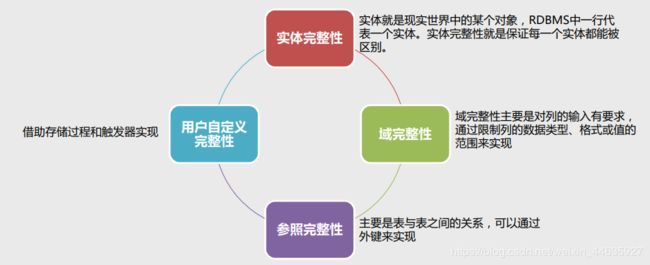
- 实体完整性:
实体完整性要求每张表都有唯一标识符,每张表中的主键字段不能为空且不能重复。
约束方法:唯一性约束、主键约束、标识列 - 域完整性:
域完整性是针对某一具体关系数据库的约束条件,它保证表中某些列不能输入无效的值。
域完整性指列的值域的完整性,如数据类型、格式、值域范围、是否允许空值等。
约束方法:限制数据类型、检查约束、默认值、非空约束 - 参照完整性:
参照完整性要求关系中不允许引用不存在的实体。
约束方法:外键约束 - 用户自定义完整性:
用户自定义完整性是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须
满足的语义要求。
约束方法:规则、存储过程、触发器
- 唯一性约束:
在MySQL中,可以使用关键字 UNIQUE 实现字段的唯一性约束,从而保证实体的完整性。
1.UNIQUE 意味着任何两条数据的同一个字段不能有相同值。
2.一个表中可以有多个 UNIQUE 约束。
#在创建表时添加唯一性约束
create table person(
id int not null auto_increment primary key comment '主键id',
name varchar(30) comment '姓名',
id_number varchar(18) unique comment '身份证号'
);
- 外键约束:
外键(FOREIGN KEY)约束定义了表之间的一致性关系,用于强制参照完整性。
外键约束定义了对同一个表或其他表的列的引用,这些列具有PRIMARY KEY或UNIQUE约束。
#成绩表
create table sc(
id int not null auto_increment primary key comment '主键id',
stu_no int not null comment '学号',
course varchar(30) comment '课程',
grade int comment '成绩',
foreign key(stu_no) references stu(stu_no)
);
三、数据查询语言
1.简单查询
- 在SQL中,使用select语句来查询数据。不同的关系数据库,select语法会有细微差别,在MySql官网 可以查到支持的select语法。
- 使用select查询数据
SELECT column_name1, column_name2
FROM table_name
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
2.条件查询(单条件,多条件)
- where子句(单条件查询):
在SQL中,insert、update、delete和select后面都能带where子句,用于插入、修改、删除或查
询指定条件的记录。
#SQL语句中使用where子句语法
SELECT column_name FROM table_name WHERE column_name 运算符 value
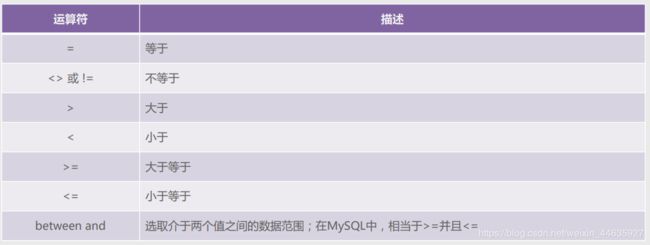
- where子句(多条件查询):
在where子句中,使用and、or可以把两个或多个过滤条件结合起来。
#and、or运算符语法
SELECT column_name FROM table_name WHERE condition1 AND condition2 OR condition3

3.IN和LIKE的使用
- 运算符in的使用:
运算符 IN 允许我们在 WHERE 子句中过滤某个字段的多个值。
#where子句使用in语法
SELECT column_name FROM table_name WHERE column_name IN(value1, value2, …)
- 运算符like的使用:
在where子句中,有时候我们需要查询包含xxx 字符串的所有记录,这时就需要用到运算符like。
#where子句使用like语法
SELECT column_name FROM table_name WHERE column_name LIKE ‘%value%’
说明:
1、LIKE子句中的%类似于正则表达式中的*,匹配任意0个或多个字符
2、LIKE子句中的_匹配任意单个字符
3、LIKE子句中如果没有%和_,就相当于运算符=的效果
4.MySQL常用函数讲解
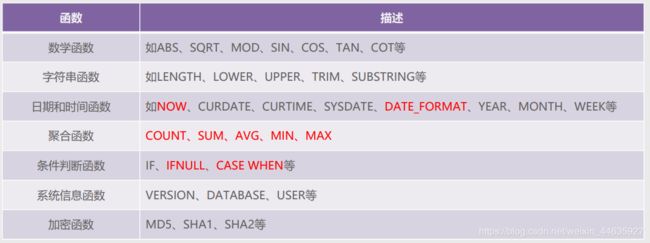
- 函数now():
函数now()用于返回当前的日期和时间。
应用场景:
在实际应用中,大多数业务表都会带一个创建时间create_time字段,用于记录每一条数据的产生时间。在向表中插入数据时,就可以在insert语句中使用now()函数
insert into user(id, name, create_time) values(1, 'zhangsan', now());
- 函数date_format():
函数date_format()用于以指定的格式显示日期/时间。
应用场景:
在实际应用中,一般会按照标准格式存储日期/时间,如 2019-12-13 14:15:16 。在查询使用数据时,往往又会有不同的格式要求,这时就需要使用date_format()函数进行格式转换
select name, date_format(birthday, '%Y/%m/%d') from user;
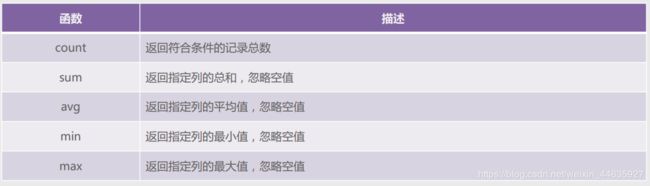
- 聚合函数:
聚合函数是对一组值进行计算,并返回单个值。
MySQL常用的聚合函数有5个,分别是count、sum、avg、min和max。
- 函数ifnull():
函数ifnull()用于处理NULL值。
ifnull(v1,v2),如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。 - case when:
case when是流程控制语句,可以在SQL语句中使用case when来获取更加准确和直接的结果。
SQL中的case when类似于编程语言中的if else或者switch。
#case when的语法有2种
CASE [col_name] WHEN [value1] THEN [result1]…ELSE [default] END
CASE WHEN [expr] THEN [result1]…ELSE [default] END
5.查询结果与分页
- order by的使用:
在SQL中,使用order by对查询结果集进行排序,可以按照一列或多列进行排序。
#order by语法
SELECT column_name1, column_name2
FROM table_name1, table_name2
ORDER BY column_name, column_name [ASC|DESC]
说明:
1. ASC表示按升序排列,DESC表示按降序排列。
2. 默认情况下,对列按升序排列。
- limit的使用
在SELECT语句中使用LIMIT子句来约束要返回的记录数,通常使用LIMIT实现分页。
#limit语法
SELECT column_name1, column_name2
FROM table_name1, table_name2
LIMIT [offset,] row_count
说明:
1. offset指定要返回的第一行的偏移量。第一行的偏移量是0,而不是1。
2. row_count指定要返回的最大行数。
#【经验分享】limit的分页公式:
limit (page-1)*row_count, row_count
6.GROUP BY与HAVING的使用
- group by的使用:
group by表示根据某种规则对数据进行分组,它必须配合聚合函数进行使用,对数据进行分组后可以进行count、sum、avg、max和min等运算。
#group by语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
GROUP BY column_name
说明:
1. aggregate_function表示聚合函数。
2. group by可以对一列或多列进行分组。
- having的使用:
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。HAVING 子句可以对分组后的各组数据进行筛选。
#having语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value
7.GROUP_CONCAT函数的使用
- group_concat的使用:
group_concat配合group by 一起使用,用于将某一列的值按指定的分隔符进行拼接,MySQL默认的分隔符为逗号。
#group_concat语法
group_concat([distinct] column_name [order by column_name asc/desc] [separator '分隔符'])
8.使用DISTINCT去除重复数据
- distinct的使用:
distinct用于在查询中返回列的唯一不同值(去重复),支持单列或多列。在实际的应用中,表中的某一列含有重复值是很常见的,如employ表的dept列。如果在查询数据时,希望得到某列的所有不同值,可以使用distinct。
#distinct语法
SELECT DISTINCT column_name, column_name
FROM table_name;
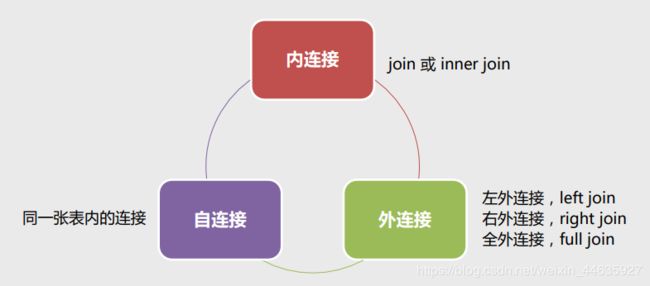
9.表连接(内连接、外连接、自连接)
- 什么是表连接:
表连接(JOIN)是在多个表之间通过一定的连接条件,使表之间发生关联,进而能从多个表之间获取数据。
#表连接语法
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column2;
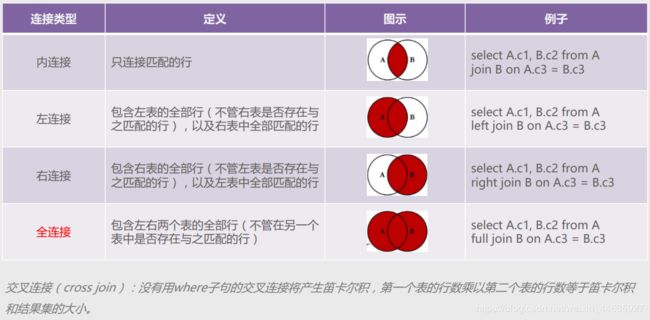
- 表连接几种方式和区别
10.自连接查询的场景及使用
- 什么是自连接
自连接是一种特殊的表连接,它是指相互连接的表在物理上同为一张表,但是逻辑上是多张表。
自连接通常用于表中的数据有层次结构,如区域表、菜单表、商品分类表等。
#自连接语法
SELECT A.column, B.column
FROM table A, table B
WHERE A.column = B.column;
11.子查询EXISTS和IN的使用
- 子查询in:
如果运算符 in 后面的值是来源于某个查询结果,并非是指定的几个值,这时就需要用到子查询。子查询又称为内部查询或嵌套查询,即在 SQL 查询的 WHERE 子句中嵌入查询语句。
#子查询in语法
SELECT column_name FROM table_name
WHERE column_name IN(
SELECT column_name FROM table_name [WHERE]
);
- 子查询exists:
EXISTS是子查询中用于测试内部查询是否返回任何行的布尔运算符。将主查询的数据放到子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定主查询的数据结果是否保留。
#where子句使用exists语法
SELECT column_name1
FROM table_name1
WHERE EXISTS (SELECT * FROM table_name2 WHERE condition);
四、数据控制语言DCL
1.用户管理
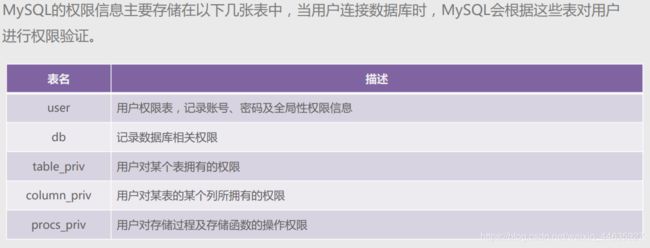
- DCL是数据控制语言,主要用于管理用户和权限。
DCL主要能做什么?- 创建用户
- 删除用户
- 修改密码
- 给用户赋予权限
- 撤销用户权限
- MySQL的权限体系

- 用户管理
在MySQL中,使用CREATE USER来创建用户,用户创建后没有任何权限。
#创建用户
CREATE USER '用户名' [@'主机名'] [IDENTIFIED BY '密码'];
注意:MySQL的用户账号由两部分组成:用户名和主机名,即用户名@主机名,主机名可以是IP或机器名称,
主机名为%表示允许任何地址的主机远程登录MySQL数据库。
#删除用户
DROP USER '用户名' [@'主机名'];
#修改密码
ALTER USER '用户名'@'主机名' IDENTIFIED BY '新密码';
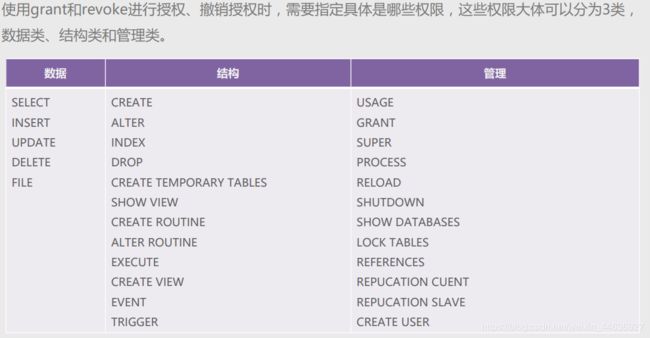
2.权限管理(授予与回收)
- 权限管理:
在MySQL数据库中,使用grant命令授权、revoke命令撤销授权。
#授权
grant all privileges on databaseName.tableName to '用户名' [@'主机名'] ;
#撤销授权
revoke all privileges on databaseName.tableName from '用户名' [@'主机名'] ;
#刷新权限
FLUSH PRIVILEGES;
#查看权限
show grants for '用户名' [@'主机名'] ;
3.禁止ROOT用户远程登录
- 为什么要禁止root远程登录?
- root是MySQL数据库的超级管理员,几乎拥有所有权限,一旦泄露后果非常严重;
- root是MySQL数据库的默认用户,所有人都知道,如果不禁止远程登录,可以针对root用户暴力破解密码;
update user set host='localhost' where user ='用户名';
4.忘记root用户密码的解决方法
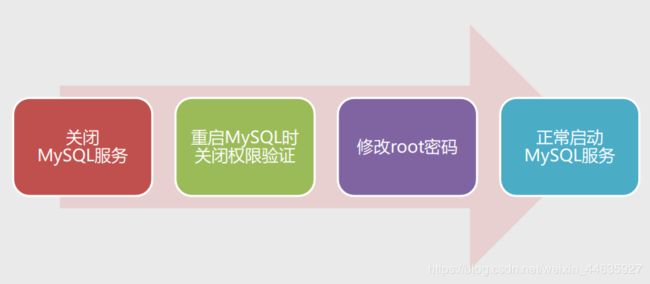
- 重启MySQL时关闭权限验证
#关闭权限验证
mysqld --defaults-file="C:\ProgramData\MySQL\MySQL Server 8.0\my.ini" --console --skip-granttables
--shared-memory
说明:参数--defaults-file的值为配置文件my.ini的完整路径。
- 修改root用户密码
#刷新权限
FLUSH PRIVILEGES;
#修改root用户的密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
五、索引的使用
1.慢查询日志
- MySQL的日志类型

- 慢查询日志
慢查询日志用于记录MySQL数据库中响应时间超过指定阈值的语句。慢查询日志通常也被称之为慢日志,因为它不仅仅只针对SELECT语句,像INSERT、UPDATE、DELETE等语句,只要响应时间超过所设定阈值都会记录在慢查询日志中。

慢查询日志可以通过命令临时设置,也可以修改配置文件永久设置。
#查看是否开启慢查询日志
show variables like 'slow%';
#临时开启慢查询日志
set slow_query_log='ON';
set long_query_time=1;
#慢查询日志文件所在位置
show variables like '%datadir%';
2.查询分析器EXPLAIN
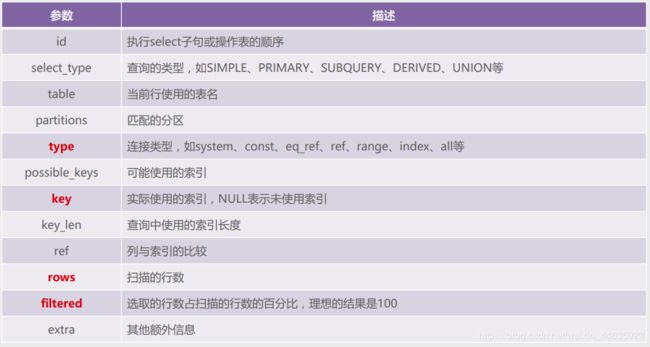
- explain简介
explain命令可以查看SQL语句的执行计划。当explain与SQL语句一起使用时,MySQL将显示来自优化器的有关语句执行计划的信息。也就是说,MySQL解释了它将如何处理语句,包括有关如何联接表以及以何种顺序联接表的信息。
explain能做什么?- 分析出表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
- explain的使用:
只需要在SQL语句之前加上explain命令即可,除select语句外,explain也能分析insert、update和delete语句。 - explain结果解析
3.索引的基本使用
- 什么是索引
索引是一种特殊的数据结构,类似于图书的目录,它能够极大地提升数据库的查询效率。如果没有索引,在查询数据时必须扫描表中的所有记录才能找出符合条件的记录,这种全表扫描的查询效率非常低。 - 常见的索引种类
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定记录。

- 索引的使用
# 创建普通索引
CREATE INDEX indexName ON tableName(columnName(length));
# 创建唯一索引
CREATE UNIQUE INDEX indexName ON tableName(columnName(length));
# 创建复合索引
CREATE INDEX indexName ON tableName(columnName1, columnName2, …);
#删除索引
DROP INDEX [indexName] ON tableName;
#查看索引
SHOW INDEX FROM tableName;
4.复合索引前导列特性
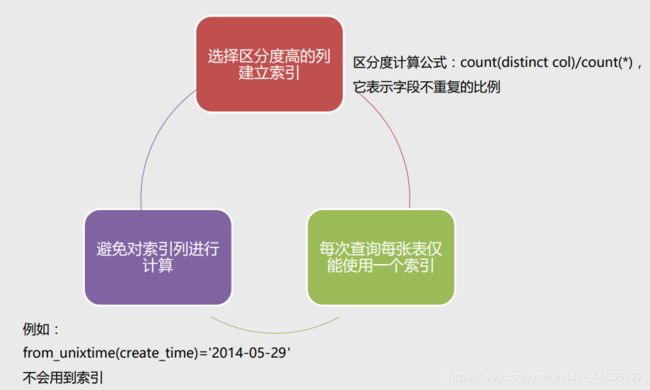
- 复合索引前导列特性
在MySQL中,如果创建了复合索引(name, salary, dept),就相当于创建了(name, salary, dept)、(name, salary)和(name)三个索引,这被称为复合索引前导列特性,因此在创建复合索引时应该将最常用作查询条件的列放在最左边,依次递减。
5.覆盖索引
- 什么是覆盖索引
覆盖索引又称之为索引覆盖,即select的数据列只从索引中就能得到,不必读取数据行,也就是只需扫描索引就可以得到查询结果。
关于覆盖索引的几点说明:- 使用覆盖索引,只需要从索引中就能检索到需要的数据,而不要再扫描数据表;
- 索引的体量往往要比数据表小很多,因此只读取索引速度会非常快,也会极大减少数据访问量;
- MySQL的查询优化器会在执行查询前判断,是否有一个索引可以覆盖所有的查询列;
- 并非所有类型的索引都可以作为覆盖索引,覆盖索引必须要存储索引列的值。像哈希索引、空间索引、全文索引等并不会真正存储索引列的值。
- 如何判断使用了覆盖索引
当一个查询使用了覆盖索引,在查询分析器EXPLAIN的Extra列可以看到“Using index” 。
六、MySQL高级进阶
1.事务控制
- 什么是事务控制
事务(Transaction)是指作为一个逻辑工作单元执行的一系列操作,这些操作要么全部成功,要么全部失败。事务确保对多个数据的修改作为一个单元来处理。
在MySQL中,只有使用了Innodb存储引擎的数据库或表才支持事务。
事务用于维护数据库的完整性,保证成批的sql语句要么都执行,要么都不执行。
事务用于管理INSERT、UPDATE和DELETE语句。 - 事务的四个特性
如果某个数据库声称支持事务,那么该数据库必须具备ACID四个特性,即Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)和Durability(持久性)。

- MySQL的事务控制
在默认情况下,MySQL是自动提交事务的,即每一条INSERT、UPDATE、DELETE的SQL语句提交后会立即执行COMMIT操作。因此,要开启一个事务,可以使用start transaction或begin,或者将autocommit的值设置为0。
默认情况下,autocommit的值为1,表示自动提交事务。
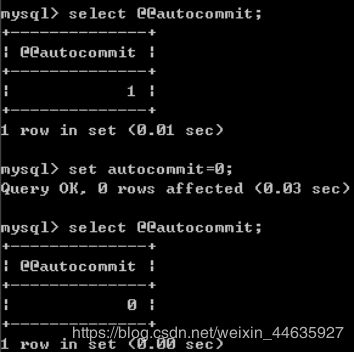
使用start transaction或begin开启事务。
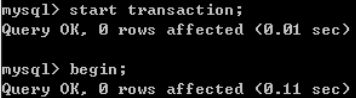
对于一个事务,要么回滚,要么提交。
2.分区表
- 什么是分区表
分区表就是按照某种规则将同一张表的数据分段分到多个存储位置。对数据的分区存储提高了数据库的性能,被分区存储的数据在物理上是多个文件,但在逻辑上仍是一个表,对表的任何操作都跟没分区之前一样。在执行增删改查等操作时,数据库会自动找到对应的分区,然后执行操作。 - 分区表的好处
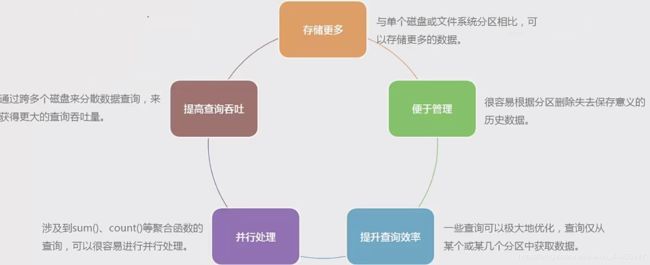
- 分区表的四种类型
MySQL支持的分区类型包括Range、List、Hash和Key,其中Range最常用。
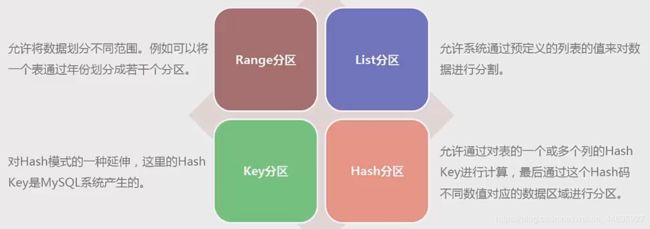
- Range分区
Range分区是基于属于一个给定连续区间的列值,把多行分配给分区。
#Range分区示例
create table user_range(
id int not null auto_increment,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,age)
)
#主键必须包含分区字段
partition by RANGE(age)(
partition p1 VALUES LESS THAN (20)DATA DIRECTORY='c:/data/p1',
partition p2 VALUES LESS THAN (40)DATA DIRECTORY='c:/data/p2',
partition p3 VALUES LESS THAN (60)DATA DIRECTORY='c:/data/p3',
partition p4 VALUES LESS THAN MAXVALUE DATA DIRECTORY='c:/data/p4'
);
- List分区
List 分区是基于列值匹配一个离散值集合中的某个值来进行选择。
#List分区示例
create table user_list(
id int not null auto_increment,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,province)
)
partition by List(province)(
partition p1 VALUES IN (1,3,5,7,9,11,13,15,17,19,21),
partition p2 VALUES IN (2,4,6,8,10,12,14,16,18,20,22),
partition p3 VALUES IN (23,24,25,26,27,28,29,30,31,32,33,34)
);
- Hash分区
Hash分区是基于用户定义的表达式的返回值来进行选择的分区。
#Hash分区示例
create table user_hash(
id int not null auto_increment,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,birthday)
)
partition by HASH(YEAR(birthday))
partition 5;
- Key分区
Key分区类似于Hash分区,但这里的Hash Key是有由MySQL系统产生的。
#Key分区示例
create table user_range(
id int not null auto_increment,
name varchar(30),
age int,
birthday date,
province int,
primary key(id,age)
)
partition by Key(age)
partition 5;
- 分区的其他操作
#新增分区
alter table 'user' add partition (partition p5 VALUES LESS THAN MAXVALUE);
#对已在的表进行分区
alter table 'user' partition by RANGE(age)(
partition p1 VALUES LESS THAN (20)DATA DIRECTORY='c:/data/p1',
partition p2 VALUES LESS THAN (40)DATA DIRECTORY='c:/data/p2',
partition p3 VALUES LESS THAN (60)DATA DIRECTORY='c:/data/p3',
partition p4 VALUES LESS THAN MAXVALUE DATA DIRECTORY='c:/data/p4'
);
#删除分区(分区下的数据也会被删除)
alter table 'user' drop partition p5;
#移除分区(数据不会被删除)
alter table 'user' REMOVE PARTITIONING;
3.视图
- 什么是视图
视图是一个虚拟表,其内容由select查询语句定义。和真实的表一样,视图也包含行和列,对视图的操作与对表的操作基本一致。视图中的数据是在使用视图时动态生成,视图中的数据都存储在基表中。

- 视图的基本操作
视图是一个虚拟表,其内容由select查询语句定义。和真实的表一样,视图也包含行和列,对视图的操作与对表的操作基本一致。视图中的数据是在使用视图时动态生成,视图中的数据都存储在基表中。视图表的数据变化会影响到基表,基表的数据变化也会影响视图表。
#创建视图
CREATE VIEW view_name AS SELECT…;
#修改视图
ALTER VIEW view_name AS SELECT…;
#查看视图创建语句
SHOW CREATE VIEW view_name;
#查看有哪些视图
SHOW TABLE STATUS WHERE comment='view';
#删除视图
DROP VIEW view_name;
4.存储过程的基本使用
-
什么是存储过程
存储过程(Stored Procedure)是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行,类似于编程语言中的方法或函数。
存储过程的优点:- 存储过程是对SQL语句的封装,增强可复用性
- 存储过程可以隐藏复杂的业务逻辑、商业逻辑
- 存储过程支持接收参数,并返回运算结果
存储过程的缺点:
- 存储过程的可移植性较差,如果更换数据库,要重写存储过程
- 存储过程难以调试和扩展
- 无法使用Explain对存储过程进行分析
- 《阿里巴巴Java开发手册》中禁止使用存储过程
-
存储过程示例
#存储过程定义:求两数之和
delimiter //
create procedure my_sum(in a int, in b int, out result int)
begin
set result = a + b;
end
//
delimiter ;
#存储过程调用
call my_sum(10, 20, @result);
select @result;
#存储过程定义:计算1+2+...+n的和
delimiter //
create procedure my_n_sum(in n int, out result int)
begin
declare i int default 1;
declare sum int default 0;
while i<=n do
set sum = sum + i;
set i = i + 1;
end while;
set result = sum;
end;
//
delimiter ;
5.存储过程实战:给指定用户发邮件通知
#测试数据及需求描述
drop table if exists user_info;
drop table if exists email_info;
create table user_info(
id int not null auto_increment primary key,
name varchar(30),
email varchar(50)
);
insert into user_info(id, name, email) values(1, '柳峰', '[email protected]');
insert into user_info(id, name, email) values(2, '张三', '[email protected]');
create table email_info(
id int not null auto_increment primary key,
email varchar(50),
content text,
send_time datetime
);
#存储过程实现
#存储过程示例:根据用户id和邮件内容content给用户发邮件
delimiter //
create procedure send_email(in user_id int, in content text)
begin
/* 根据用户id查询邮箱email */
set @user_email=(select email from user_info where id=user_id);
/* 模拟发送邮件 */
insert into email_info(email, content, send_time) values(@user_email, content, now());
end;
//
delimiter ;
call send_email(1, '欢迎加入MySQL阵营!');
6.触发器实战:给新用户发邮件
- 什么是触发器
触发器(trigger)用于监视某种情况并触发某种操作,它是与表事件相关的特殊的存储过程,它的
执行不是由程序调用,而是由事件来触发。例如,当对某张表进行insert、delete、update操作时就会触发执行它。
#创建触发器语法
CREATE TRIGGER trigger_name trigger_time trigger_event ON table_name FOR EACH ROW
trigger_stmt
参数说明:
trigger_name:触发器名称
trigger_time:触发时间,取值有before、after
trigger_event:触发事件,取值有insert、update、delete
table_name:触发器监控的表名
trigger_stmt:触发执行的语句,可以使用OLD、NEW来引用变化前后的记录内容
NEW.columnName:获取INSERT触发事件中新插入的数据
OLD.columnName:获取UPDATE和DELETE触发事件中被更新、删除的数据
- 触发器实战:给新用户发邮件
#测试数据及需求描述
drop table if exists user_info;
drop table if exists email_info;
create table user_info(
id int not null auto_increment primary key,
name varchar(30),
email varchar(50)
);
insert into user_info(id, name, email) values(1, '柳峰', '[email protected]');
insert into user_info(id, name, email) values(2, '张三', '[email protected]');
create table email_info(
id int not null auto_increment primary key,
email varchar(50),
content text,
send_time datetime
);
#触发器实战:给新用户发邮件
delimiter //
CREATE TRIGGER send_email_trigger AFTER INSERT ON user_info FOR EACH ROW
BEGIN
insert into email_info(email, content, send_time) values(NEW.email, '欢迎加入MySQL阵营!', now());
END
//
delimiter ;
7.预处理(绑定变量)
- 什么是预处理
从MySQL 4.1开始,就支持预处理语句(Prepared statement),这大大提高了客户端和服务器端数据传输的效率。当创建一个预定义SQL时,客户端向服务器发送一个SQL语句的原型;服务器端接收到这个SQL语句后,解析并存储这个SQL语句的部分执行计划,返回给客户端一个SQL语句处理句柄,以后每次执行这条SQL,客户端都指定使用这个句柄。

- 预处理的优势

- 预处理的基本使用
# 定义预处理语句
PREPARE stmt_name FROM preparable_stmt;
# 执行预处理语句
EXECUTE stmt_name [USING @var_name [, @var_name] ...];
# 删除(释放)定义
{DEALLOCATE | DROP} PREPARE stmt_name;
8.查询缓存
- 什么是查询缓存
MySQL将缓存存放在一个引用表中,类似于HashMap的数据结构,Key查询SQL语句,Value则是查询结果。当发起查询时,会使用SQL语句去缓存中查询,如果命中则立即返回缓存的结果集。
注意:- 可以使用 SQL_NO_CACHE 在 SELECT 中禁止缓存查询结果,例如:SELECT SQL_NO_CACHE …
- MySQL 8.0已删除查询缓存功能
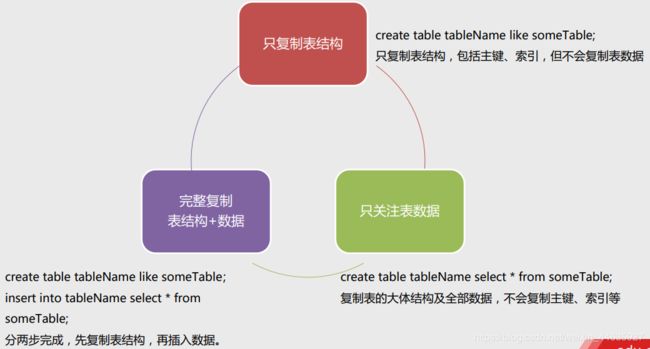
9.复制表的几种方式
10、导出数据
- select…into outfile
在MySQL中,可以使用SELECT…INTO OUTFILE语句将查询结果数据导出到文本文件。
#select…into outfile示例
SELECT * FROM employee INTO OUTFILE 'D:\\employee.txt' /*文件存储路径*/
FIELDS TERMINATED BY ',' /*字符分隔符*/
ENCLOSED BY '"' /*值用双引号引起*/
LINES TERMINATED BY '\r\n'; /*行间分隔符*/

- mysql命令重定向查询结果
通常,我们使用mysql命令连接数据库,mysql命令有一个-e选项,可以执行指定的SQL语句,再结合DOS的重定向操作符”>”可以将查询结果导出到文件。
#示例
mysql -h localhost -u root -p -D mydb -e "select * from employee" > E:\employee.txt
- 使用mysqldump导出数据
mysqldump是MySQL用于转存储数据库的实用程序,它主要产生一个SQL脚本,其中包含创建数据库、创建数据表、插入数据所必需的SQL语句。
# 导出mydb数据库(含数据)
mysqldump -h localhost -u root -p mydb > d:/mydb.sql
# 导出mydb数据库(不含数据)
mysqldump -h localhost -u root -p mydb --no-data > d:/mydb.sql
# 导出mydb.employee数据表
mysqldump -h localhost -u root -p mydb employee > d:/employee.sql
# 导出mydb数据库,忽略contacts表
mysqldump -h localhost -u root -p mydb --ignore-table mydb.contacts > d:/employee.sql
11.定时备份数据库
- 定时备份数据库的解决方案
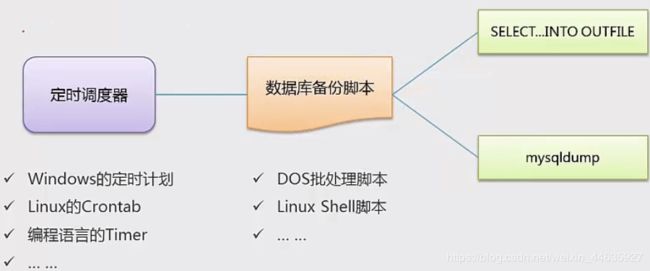
- Windows上实现定时备份MySQL
schtasks.exe用于安排命令和程序在指定时间内运行或定期运行,它可以从计划表中添加和删除任按需要启动和停止任务、显示和更改计划任务。
#备份数据库的脚本mysql_mydb-backup.bat
mysqldump -h localhost -uroot -p123456 mydb > d:\backup\mydb.sql
#创建计划任务(每隔指定时间备份一次MySQL)
schtasks/create/sc minute/mo 1/tn 定期备份MySQL/tr d:\backup\mysql_mydb_backup.bat
#删除计划任务
schtasks/delete/tn 定期备份MySQL
- Linux上实现定时备份MySQL
#!/bin/bash
#备份目录
backup_dir=/home/liufeng/backup
#备份文件名
backip_filename="mydb-'date+%Y%m%d'.sql"
#进入备份目录
cd $backup_dir
#备份数据库
mysqldump -h localhost -uroot -p123456 mydb > ${backup_dir}/${backup_filename}
#删除7天以前的备份
find${backup_dir} -mtime+7 -name "*.sql" -exec rm -rf{}\;
#每天凌晨01:30执行shell脚本(备份数据库)
30 1 *** bash/home/liufeng/backup/mysql_mydb_backup.sh
12.导入数据
- LOAD DATA
在MySQL中,可以使用LOAD DATA语句将文本文件数据导入到对应的数据库表中,可以将LOAD DATA语句看成是SELECT…INTO OUTFILE的反操作。
#示例
LOAD DATA INFILE 'D:\\employee.txt' INTO TABLE employee character set utf8 /*数据文件位置*/
FIELDS TERMINATED BY ',' /*字段间分隔符*/
ENCLOSED BY '"' /*值用双引号引起*/
LINES TERMINATED BY '\r\n'; /*行间分隔符*/
- source命令
在MySQL中,可以使用source命令导入较大的SQL文件。source命令可以导入使用mysqldump备份的sql文件。
# source命令的使用示例
source d:/mydb.sq
13.字符集
- 什么是字符集
- 字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
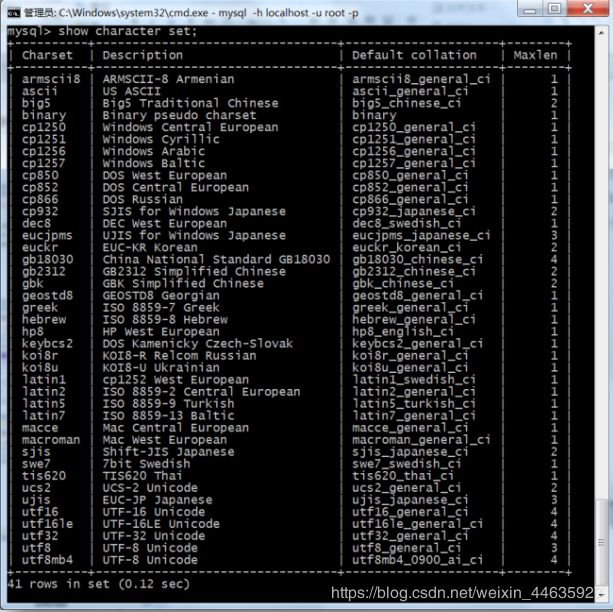
- 字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见的字符集有ASCII、GB2312、GBK、 GB18030、Unicode等。计算机要准确的处理各种字符集文字,就需要进行字符编码,以便计算机能够识别和存储各种文字。

- MySQL支持的字符集
- 设置字符集
#数据库
# 创建数据库时指定字符集
CREATE DATABASE databaseName CHARSET utf8 COLLATE utf8_general_ci;
# 查看数据库的字符集
SHOW CREATE DATABASE databaseName;
#表
# 创建表时指定字符集
CREATE TABLE tableName(…) DEFAULT CHARSET=utf8;
# 查看数据库的字符集
SHOW CREATE TABLE tableName;
#字段
CREATE TABLE tableName(…, name varchar(50) not null CHARSET utf8, …);
14.SQL注入
- 什么是SQL注入
SQL注入(SQL Injection)是指应用程序对用户输入数据的合法性没有判断、没有过滤,攻击者可以在应用程序中通过表单提交特殊的字符串,该特殊字符串会改变SQL的运行结果,从而在管理员毫不知情的情况下实现非法操作,以此来实现欺骗数据库执行非授权的任意查询。

- 如何进行SQL注入
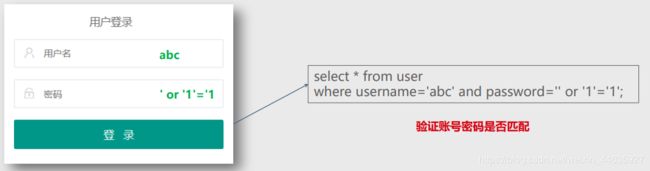
15.如何恢复误删的数据
- 什么是binlog日志
二进制日志binlog记录了所有的DDL和DML语句(除了数据查询语句select),以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。 - 使用binlog恢复误删数据
#查看所有二进制日志列表
show master logs;
#查看正在使用的二进制日志
show master stsaus;
#刷新日志(重新开始新的binlog日志文件)
flush logs
#查询指定的binlog
show binlog events in 'WQ-20160823MDKU-bin.000050' from 10668\G;
#导出恢复数据用的sql
mysqlbinlog "C:\ProgramData\MySQL\MySQL Server 8.0\Data\WQ-20160823MDKU-bin.000057" --
start-position 528 --stop-position 1191 >d:\backup\test.sql
16.审计功能
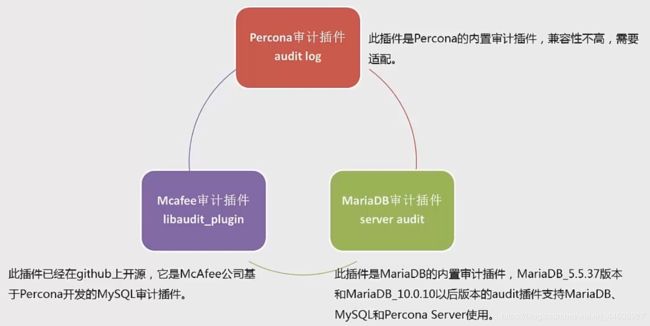
- MySQL审计功能
审计是数据库安全中很重要的一个环节,它能实时记录数据库的操作记录,帮助数据库管理员对数据库异常行为进行分析审核。审核会详细记录谁、在什么时间、执行了什么操作。MySQL社区版没有自带的审计功能或插件,MySQL商业版中有审计功能。 - 第三方的审计功能
17.MySQL图形化管理工具

18.Windows下my.ini配置文件修改后无法启动的问题解决
在Windows中,修改了MySQL 8.0的配置文件my.ini后会发现启动MySQL失败,错误提示如下。
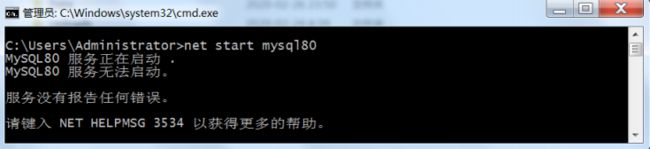
在Windows中,MySQL配置文件的编码为ANSI,但是修改配置文件后默认保存的编码为UTF-8,这会导致MySQL解析配置文件错误,无法启动。只需要将配置文件另存为ANSI编码即可。

七、MySQL 8.0新特性
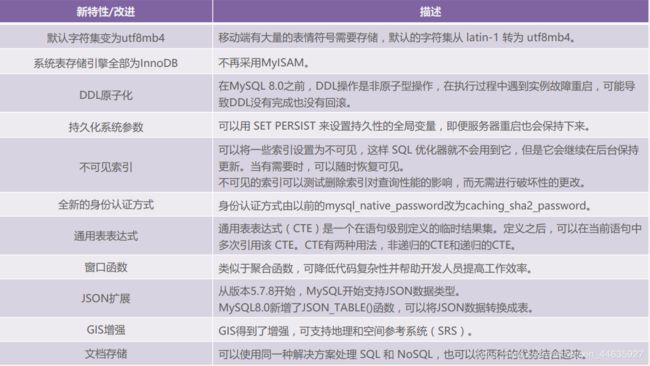
1.MySQL8.0 新特性
2.Navicat无法连接MySQL 8.0的问题解决
老版本的Navicat连接能正常连接MySQL 5.x,但是连接MySQL 8.0却报错,错误提示如图所示。

MySQL 5.x的身份认证方式为 mysql_native_password,也就是Navicat客户端支持的认证方式。但是MySQL 8.0升级了身份认证方式,默认为 caching_sha2_password。因此,在不升级Navicat版本的情况下,可以将MySQL 8.0的身份认证方式修改为 mysql_native_password。
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';
flush privileges;
3.默认字符集utf8mb4
MySQL在5.5.3之后增加了utf8mb4编码,mb4是most bytes 4的缩写,专门用于兼容四字节字符,如Emoji表情,部分中文“ ”。MySQL中的utf8是utf8mb3的别名,utf8mb4兼容utf8,且比utf8能表示更多的字符。MySQL 8.0将utf8mb4作为默认字符集。
4.原子DDL
-
什么是原子DDL
MySQL 8.0 开始支持原子性的数据定义语言(DDL),也称为原子 DDL。一个原子 DDL 语句将相关的数据字典更新、存储引擎操作以及写入二进制日志组合成单一的原子事务。当事务正在处理时出现服务器故障,该事务可能被提交,相应的变更会保存到数据字典更新、存储引擎更改以及二进制日志中;也可能被整体回滚。目前,只有 InnoDB 存储引擎支持原子 DDL。
支持原子DDL- 数据库、表空间、表、索引的 CREATE、ALTER 以及 DROP 语句,以及 TRUNCATE TABLE 语句
- 存储过程、触发器、视图以及用户定义函数(UDF)的 CREATE 和 DROP 语句,以及适用的 ALTER 语句
- 用户和角色的 CREATE、ALTER、DROP 语句,以及 GRANT 和 REVOKE 语句
不支持原子DDL
- 非 InnoDB 存储引擎上的表相关 DDL 语句
- INSTALL PLUGIN 和 UNINSTALL PLUGIN 语句
- INSTALL COMPONENT 和 UNINSTALL COMPONENT 语句
- CREATE SERVER、ALTER SERVER 以及 DROP SERVER 语句
-
原子DDL的使用
任何 DDL 语句,包括原子性或其他的 DDL,都会隐式地结束当前事务,就像在执行语句之前执行了COMMIT 操作一样。这就意味着 DDL 语句不能位于其他事务之中,不能位于事务控制语句(如START TRANSACTION … COMMIT)之中,也不能与同一个事务中的其他语句组合使用。
5.NoSQL文档存储
- 什么是NoSQL
- NoSQL是Not Only SQL的简称,意思是“不仅仅是SQL”。
- 目前,我们常用的都是关系型数据库,如Oracle、DB2、MySQL、SQL Server等。实践证明,
关系模型是非常适合于客户服务器编程,它是结构化数据存储在网络和商务应用的主导技术。 - NoSQL,指的是非关系型的数据库,它是对不同于传统的关系型数据库的数据库管理系统的统称。
- NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
- NoSQL数据库的分类

- MySQL的文档存储
在关系数据库中,需要先定义表才能存储数据。文档存储更加灵活,不需要事先定义数据结构、数据约束等就可以直接存储数据。将MySQL用作文档存储时,集合是容器,集合包含可以添加、查找、更新和删除的JSON文档。

- 文档存储的基本使用
#使用MySQL Shell连接数据库(支持文档存储)
mysqlsh root@localhost:33060/mydb
#查看当前数据库
db
#查看当前数据库有哪些集合
db.getCollections()
#创建集合
db.createCollection("employee_doc")
#删除集合
db.dropCollection("employee_doc")
#添加文档
db.employee_doc.add({
"id":1,
"name":"张三",
"sex":"男",
"salary":5500,
"dept":"部门A"
})
#查询文档
db.employee_doc.find("name='柳峰'")
#删除文档
db.employee_doc.remove("name='柳峰'")
#删除所有文档
db.employee_doc.remove("true")