Python爬取拉勾网职位 - 分析学历与薪资关系及技能词云
Python拉勾网职位爬取及数据分析可视化
文章目录
- Python拉勾网职位爬取及数据分析可视化
- 1.工具准备
- (1)安装第三方库
- (2)安装及配置Chromedriver无头浏览器
- (3)谷歌浏览器xpath插件安装及配置
- (4)使用Pycharm
- 2.爬取准备
- (1)分析网站数据获取方式
- (2)选择爬取方式
- 3.数据爬取及提取保存
- (1)爬取器
- (2)解析器
- (3)下载器
- 4.数据分析及可视化
- (1)分析器及可视化
- 5.爬取数据
- (1)==主函数==
- (2)运行程序
1.工具准备
(1)安装第三方库
pip install selenium
pip install lxml
pip install matplotlib
pip install numpy
pip install wordcloud
pip install xlwt
pip install xlrd
(2)安装及配置Chromedriver无头浏览器
-
请参考另一篇博客
-
或者参照下面链接:
谷歌无头浏览器下载:谷歌无头浏览器下载
谷歌无头浏览器版本对照: 谷歌无头浏览器版本对照
查看已安装谷歌浏览器版本:chrome://version
谷歌无头浏览器安装及配置:谷歌无头浏览器安装及配置
谷歌无头浏览器操作:
https://www.cnblogs.com/jieliu8080/p/10636355.html
https://www.cnblogs.com/BigFishFly/p/6380024.html
https://blog.csdn.net/chang995196962/article/details/93712385
注意:谷歌浏览器与Chromedriver的版本对应关系
(3)谷歌浏览器xpath插件安装及配置
谷歌xpath插件安装教程: 谷歌xpath插件安装教程
(4)使用Pycharm
环境: pyhton 3.5-64 bit
2.爬取准备
(1)分析网站数据获取方式
- 打开网页
拉勾网

输入搜索内容 “数据挖掘” ,跳转到对应网页。

- 分析页面跳转:职位信息无需登录就可通过搜索得到,给数据抓取提供了方便
- 分析网址信息:职位搜索可以通过更改拼接网址获得
https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98?labelWords=&fromSearch=true&suginput=
- 查看网页源码:发现无职位信息,即职位信息是通过ajax动态加载的
- 抓包分析:利用谷歌开发者工具,抓包分析得到动态数据文件
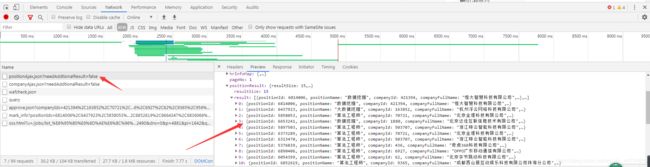
- 查看头部信息:获得数据请求方式
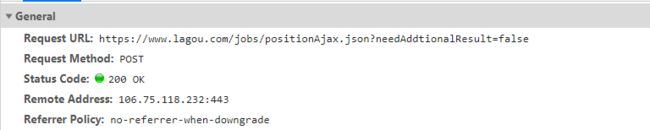

- 构建Post请求获取数据:IP被封禁

代码:
# 建立会话发起post请求
import requests
s = requests.session()
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
}
form_data = {
'first': 'true',
'pn': '1',
'kd': '大数据',
}
r = s.post(url = url,data = form_data,headers = headers)
print(r.text)
s.close()

(2)选择爬取方式
不如直接干脆地爬取数据,选择终极爬取方法:selenium+无头浏览器Chromedriver。安装第三方库,配置环境,准备爬取。
![]()
3.数据爬取及提取保存
- 导入使用到的库及配置环境等
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from lxml import etree
import urllib.parse
import xlwt,xlrd
from matplotlib import pyplot as plt
from pylab import mpl
import numpy as np
import wordcloud
import time,datetime
# from selenium.webdriver.support.wait import WebDriverWait
# from selenium.webdriver.support import expected_conditions as EC
# from selenium.webdriver.common.by import By
chrome_options = Options()
#后面的两个是固定写法 用于隐藏浏览器界面
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 设置user-agent
user_ag='Win7+ie9:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 2.0.50727; SLCC2; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; Tablet PC 2.0; .NET4.0E)'
chrome_options.add_argument('user-agent=%s'%user_ag)
# 构建浏览器对象
path = r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chromedriver.exe'
browser = webdriver.Chrome(executable_path=path,chrome_options=chrome_options)
url_part = 'https://www.lagou.com/jobs/list_{}/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
# 设置全局变量info,用于接收缓存中间数据
info = {
'job':[],
'salary':[],
'company':[],
'adress':[],
'scale':[],
'treatment':[],
'education':[],
'skill':[]
}
(1)爬取器
设置等待时间:必须设置等待时间,防止弹出登录窗口,绕开反爬机制。经过试验,8秒最佳。
# 爬取器
class spider(object):
def __init__(self,url_part,key_word):
self.url_part = url_part
self.key_word = key_word
def build_url(self):
key_word = urllib.parse.quote(self.key_word)
url = self.url_part.format(key_word)
browser.get(url)
html = etree.HTML(browser.page_source)
# 隐式的等待
browser.implicitly_wait(3)
# 消除弹窗
elem1 = html.xpath('//div[@class="body-box"]/div[@class="body-btn"]')[0]
# elem2 = html.xpath('//div[@class="modal-footer"]/button[@class="cancelBtn"]')[0]
try:
if elem1 is not None:
browser.find_element_by_xpath('//div[@class="body-box"]/div[@class="body-btn"]').click()
except:
pass
# if elem2 is not None:
# browser.find_element_by_xpath('//div[@class="modal-footer"]/button[@class="cancelBtn"]').click()
# time.sleep(2)
return url
def get_html(self,html):
if html!='':
# 点击翻页
elem = browser.find_element_by_xpath('//div[@id="s_position_list"]/div[@class="item_con_pager"]/div/span[last()]').click()
# 显式等待
# WebDriverWait(browser, 20, 0.5).until(EC.presence_of_all_elements_located((By.CLASS_NAME,'pager_container')))
# 设置足够等待时间,避免被识别弹出登录窗口
time.sleep(8)
# 获取动态加载后的网页
html = etree.HTML(browser.page_source)
return html
(2)解析器
# 解析器
class parser(object):
def get_data(self,html):
# 筛选并缓存数据
info['job'] = info['job']+html.xpath('//a/h3/text()')
info['salary'] = info['salary']+html.xpath('//div[@class="li_b_l"]/span[@class="money"]/text()')
info['company'] = info['company']+html.xpath('//div[@class="company_name"]/a/text()')
info['adress'] = info['adress']+html.xpath('//span[@class="add"]/em/text()')
info['scale'] = info['scale']+html.xpath('//div[@class="industry"]/text()')
info['treatment'] = info['treatment']+html.xpath('//div[@class="li_b_r"]/text()')
info['education'] = info['education']+html.xpath('//div[@class="li_b_l"]/text()')
info['skill'] = info['skill']+html.xpath('//div//li/div[@class="list_item_bot"]/div[@class="li_b_l"]/span/text()')
def pure_data(self):
# 去除冗杂数据,主要去除换行、空格以及空元素
scale = info['scale']
education = info['education']
for i in range(0,len(scale)):
scale[i] = scale[i].strip()
for i in range(0,len(education)):
education[i] = education[i].strip()
education = [i for i in education if(len(str(i))!=0)]
info['scale'] = scale
info['education'] = education
(3)下载器
# 下载器
class saver(object):
def save_data(self,key_word):
# 创建工作簿
book = xlwt.Workbook(encoding='utf-8')
# 创建表格
job_data = book.add_sheet('job_data')
# 写入数据
title = ['序号','职位名称','薪资','公司名称','地址','公司规模','公司待遇','学历要求']
# 写入标题
for i in range(len(title)):
job_data.write(0,i,title[i])
for i in range(len(info['job'])):
job_data.write(i+1,0,i)
job_data.write(i+1,1,info['job'][i])
job_data.write(i+1,2,info['salary'][i])
job_data.write(i+1,3,info['company'][i])
job_data.write(i+1,4,info['adress'][i])
job_data.write(i+1,5,info['scale'][i])
job_data.write(i+1,6,info['treatment'][i])
job_data.write(i+1,7,info['education'][i])
# 保存到一个xls文件中
book.save('{}-{}.xls'.format(key_word,datetime.date.today()))
return True
4.数据分析及可视化
分析学历与薪资关系及技能词云
(1)分析器及可视化
# 分析器及可视化
class analy_visual(object):
# 数据分析
def data_com(self,key_word):
# 设置默认字体,解决中文显示乱码问题
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 读取xls数据,获取对应工作薄
job_book = xlrd.open_workbook('{}-{}.xls'.format(key_word,datetime.date.today()))
# 获取对应工作表
job_table = job_book.sheet_by_name('job_data')
# 获取行数据值,返回列表
salary = job_table.col_values(2,1)
education = job_table.col_values(7,1)
# 数据格式化整理(薪资单位:k)
data = {'大专':[],
'本科':[],
'硕士':[],
'博士':[],
'不限':[]
}
for i in range(len(salary)):
salary[i] = salary[i].replace('k','').replace('以上','').split('-')
if len(salary[i])==1:
salary[i].append(0)
salary[i] = [int(salary[i][0]),int(salary[i][1])]
for i in range(len(education)):
education[i] = education[i].replace(' ','').split('/')
data[education[i][1]].append(salary[i])
# 创建数组
data1 = np.array(data['大专'])
data2 = np.array(data['本科'])
data3 = np.array(data['硕士'])
data4 = np.array(data['博士'])
data5 = np.array(data['不限'])
# 数据计算
mean_m = []
max_m = []
min_m = []
Doc = [data1,data2,data3,data4,data5]
for doc in Doc:
if doc.size != 0:
min_m.append(doc.min())
max_m.append(doc.max())
mean_m.append(doc.mean())
else:
min_m.append(0)
max_m.append(0)
mean_m.append(0)
min_m = np.array(min_m)
max_m = np.array(max_m)
mean_m = np.array(mean_m)
# 设置横坐标刻度值
x = np.array([1,2,3,4,5])
plt.xticks(x,['大专','本科','硕士','博士','不限'])
# 显示标题
plt.title('{}-学历与薪资关系(折线图)'.format(key_word))
# 绘制折线图
plt.plot(x,min_m,marker = 'o',label='最小值')
plt.plot(x,max_m,marker = 's',label = '最大值')
plt.plot(x,mean_m,marker = '^',label = '均值')
# x、y轴标签
plt.xlabel('学历类别')
plt.ylabel('薪资/单位:千元')
#设置数字标签
for a,b in zip(x,min_m):
plt.text(a,b+0.05,'%.1f'%b,ha='center',va='bottom',fontsize=12)
for a,b in zip(x,max_m):
plt.text(a,b+0.05,'%.1f'%b,ha='center',va='bottom',fontsize=12)
for a,b in zip(x,mean_m):
plt.text(a,b+0.05,'%.1f'%b,ha='center',va='bottom',fontsize=12)
# 显示图例
plt.legend()
# 保存图形文件
plt.savefig('{}-数据对比.png'.format(key_word))
# plt.show()
return True
# 生成词云
def pro_wcloud(self,key_word):
# 生成词本
text = ' '.join(info['skill'])
# 设置背景及字体路径,font_path的设置以显示中文
imag = wordcloud.WordCloud(background_color = 'white',max_words = 100,font_path = 'C:\Windows\Fonts\simfang.ttf',width = 800,height = 600)
# 根据文本生成词云
imag.generate(text)
# 输出词云
imag.to_file("{}-技能词云.png".format(key_word))
return True
5.爬取数据
(1)主函数
# 主函数
def main():
try:
key_word = input("请输入要搜索的职业:")
print("------开始爬取 {} ------".format(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
# 生成爬虫对象 lagou_spider
lagou_spider = spider(url_part,key_word)
# 生成解析器对象 lagou_parser
lagou_parser = parser()
# 生成下载器对象 lagou_saver
lagou_saver = saver()
# 生成数据分析器及可视化对象
lagou_analy = analy_visual()
html = ''
# 构建URL 并初始化到该网址
url = lagou_spider.build_url()
html = lagou_spider.get_html(html)
# 获取结果页数
pages = int(html.xpath('//div[@id="s_position_list"]/div[@class="item_con_pager"]/div/span[last()-1]/text()')[0])
# 循环爬取内容
for page in range(1,pages+1):
print("正在爬取第{}/{}页数据…………".format(page,pages))
lagou_parser.get_data(html)
html = lagou_spider.get_html(html)
print("结束爬取第{}/{}页数据!".format(page,pages))
# 关闭浏览器
browser.close()
# 保存数据到本地
print("正在保存数据…………")
lagou_parser.pure_data()
if lagou_saver.save_data(key_word):
print("数据保存成功!")
# 数据分析成功
if (lagou_analy.data_com(key_word = key_word)):
print('------>数据分析及可视化成功!<------')
if (lagou_analy.pro_wcloud(key_word = key_word)):
print('------>生成词云成功!<------')
print("------结束爬取 {} ------".format(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))))
except:
print("未知错误!!!")
if __name__ == '__main__':
main()
(2)运行程序
搜索‘数据挖掘’招聘信息
爬取结束
爬取结果
- 一共450条数据。
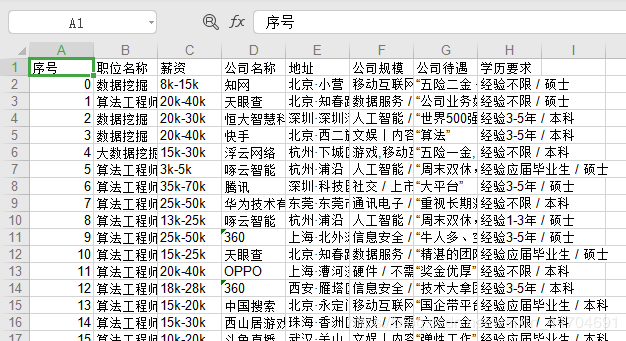
数据分析结果
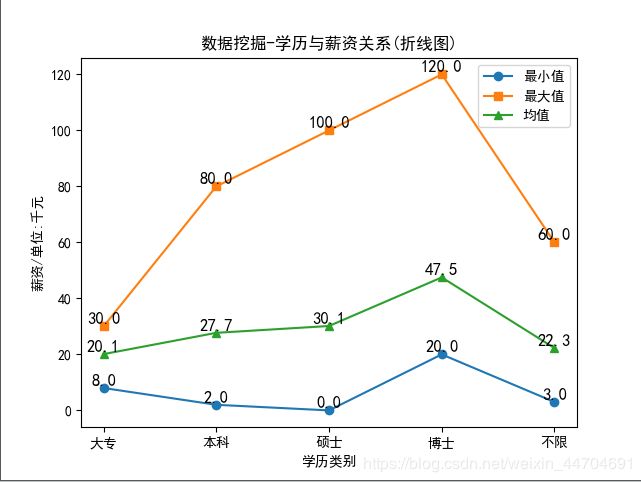
结论:从上面折线图可以看出薪资与学历成正比。
上述结论只是整体趋势,不代表个例。至于要不要考取更高的学历来换取更优的工作,还要考虑很多因素。当然,学历越高薪资相对越丰厚。所以还是要好好学习,这亦是一个知识能够变现的时代。

技能词云


学海无涯,回头是岸!