2020考研如此激烈,还怕获得不了最新的调剂信息么?来对小木虫考研调剂信息爬取
一、说明
由于国家线快出了,故写了一份爬取小木虫网站调剂信息的爬虫代码,方便信息查看。此代码仅用于学习,不作为任何商业用途。
本代码可爬取小木虫任何年份,任何专业的调剂信息。
二、代码
#!~/opt/anaconda3/bin/python
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
import os
# 获取网页
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
# 获取数据
def getDataInfo(infoList, url, pre_params, *args):
params = []
count = -1
for i in args:
count += 1
par_ = pre_params[count] + i
params.append(par_)
# 根据参数获取访问链接
for param in params:
url += param + '&'
# print(url)
html = getHTMLText(url)
soup = BeautifulSoup(html, 'html.parser')
# 获取页码数,并处理空页异常
try:
pages_tag = soup.find_all('td', 'header')[1].string
pages = int(re.split('/', pages_tag)[1])
except:
pages = 0
# 判读是否只有一页
if pages == 0:
pages += 1
for i in range(pages): # 遍历每一页
page = i + 1
url = url + '&page=' + str(page)
html = getHTMLText(url)
soup = BeautifulSoup(html, 'html.parser')
tbody = soup.find_all('tbody', 'forum_body_manage')[0]
trs = tbody.find_all('tr') # 每个学校的全部信息被tr标签包围
for tr in trs: # 遍历每一个学校
dicts = {}
href = tr.find_all('a')[0].get('href') # 定位至a标签,提取href的属性值
tds = tr.find_all('td') # 每个学校的各个信息包含在td标签内
lens = len(tds)
for i in range(lens): # 将各个学校信息添加至字典中
if i == 0:
title = tds[i].find('a').string
dicts[i] = title
else:
dicts[i] = tds[i].string
dicts['href'] = href
print(dicts)
infoList.append(dicts) # 每一个学校的信息,添加至列表
def outputCSV(infoList, path):
data = pd.DataFrame(infoList)
# with open(r'./info.csv','w+',encoding='utf-8') as f:
try:
data.columns = ['标题', '学校', '门类/专业', '招生人数', '发布时间', '链接']
except:
print('没有调剂信息...')
try:
if not os.path.exists(path):
data.to_csv(path)
print('保存成功')
else:
print('路径存在')
except:
print('保存失败')
# 设定查询参数 -- 专业、年份
def parameters(pro_='', pro_1='', pro_2='', year=''):
paramsList = [pro_, pro_1, pro_2, year]
return paramsList
def main():
url = 'http://muchong.com/bbs/kaoyan.php?'
path = './2020计算机调剂信息(截止4.09).csv'
pre_params = ['r1%5B%5D=', 'r2%5B%5D=', 'r3%5B%5D=', 'year=']
params = parameters(pro_='08', pro_1='0812',year='2020')
dataList = []
getDataInfo(dataList, url, pre_params, *params)
outputCSV(dataList, path)
main()
三、代码使用参数说明
def parameters(pro_='', pro_1='', pro_2='', year=''):
paramsList = [pro_, pro_1, pro_2, year]
return paramsList
def main():
url = 'http://muchong.com/bbs/kaoyan.php?'
path = './data_info.csv'
pre_params = ['r1%5B%5D=', 'r2%5B%5D=', 'r3%5B%5D=', 'year=']
params = parameters(pro_='08', pro_1='0801')
dataList = []
getDataInfo(dataList, url, pre_params, *params)
outputCSV(dataList, path)
主体代码已写完,只需要修改main函数中params中的相关参数,即可使用。
parameters函数主要用于返回查询的参数。默认参数都为空。如果都不填,则是爬取小木虫全部年份,全部专业的所有调剂信息。
params具体参数说明:
-
pro_所要查询的学科门类。可查询的见下图:

只要查询填写对应学科门类前的数字即可。例如工学,则:
pro_='08'注意:填写的为字符串格式
-
pro_1填写的一级学科代码。如下图:

以电子科学与技术为例,同样只需要填写前面代码即可。如:
pro_2='0806'如果这一项不填,则查询的是前一个填写的整个学科门类所有信息。
-
pro_2填写的二级学科代码。如图:

例如查询物理电子学调剂信息,同上。则填:pro_2='080901'。如果不填,则默认查询的是上一级学科下的所有调剂信息。例如,这里就是全部的电子科学与技术的调剂信息。 -
year查询年份。例如查询2020年。
year='2020'。注意:同样是字符串类型。如果不填,则是查询全部的年份。其中,
main()函数中的保存路径path,可自定义修改。
**总结:**只需修改params和保存路径url即可。
四、效果图
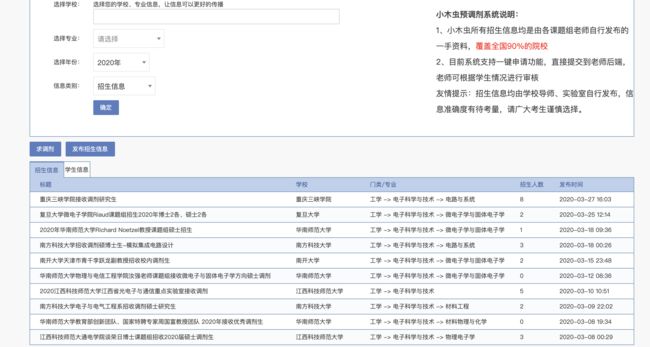
附
小木虫调剂信息网站:http://muchong.com/bbs/kaoyan.php
下载源码–并附有截止在4.09前计算机类的调剂信息