SVM算法研究
SVM算法研究
目录
- SVM算法研究
- 一、线性数据处理
- 1、未标准化的原始数据显示
- 2、决策边界绘制
- 3、再次实例化一个SVC,并传入一个较小的 CC
- 二、非线性数据处理
- 1、生成月亮数据
- (1)月亮数据生成
- (2)月亮数据显示
- 2、增加噪声点
- 3、通过多项式特征的SVM分类
- 4、高维空间线性SVM处理
- 三、核函数
- 1、核函数定义
- 2、高斯核函数
- 3、测试数据集生成
- 4、数据集升维处理
- 四、超参数
- 1、超参数定义
- 2、生成数据集
- 3、定义一个RBF核的SVM
- 4、修改$\gamma$值
- (1)$\gamma$=100
- (2)$\gamma$=10
- (3)$\gamma$=0.1
一、线性数据处理
1、未标准化的原始数据显示
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X [y<2,:2] #只取y<2的类别,也就是0 1 并且只取前两个特征
y = y[y<2] # 只取y<2的类别
# 分别画出类别0和1的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
# 标准化
standardScaler = StandardScaler()
standardScaler.fit(X) #计算训练数据的均值和方差
X_standard = standardScaler.transform(X) #再用scaler中的均值和方差来转换X,使X标准化
svc = LinearSVC(C=1e9) #线性SVM分类器
svc.fit(X_standard,y) # 训练svm
原始数据显示结果如下:
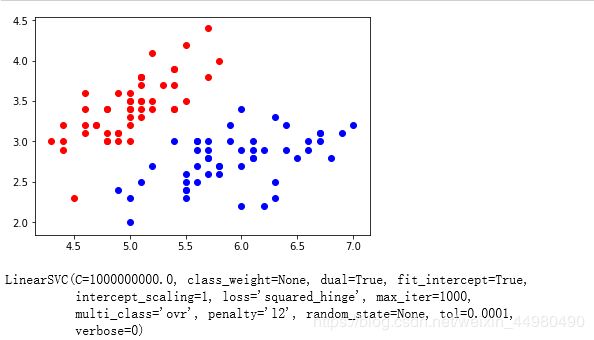
2、决策边界绘制
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
# 绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
边界绘制结果显示如下:
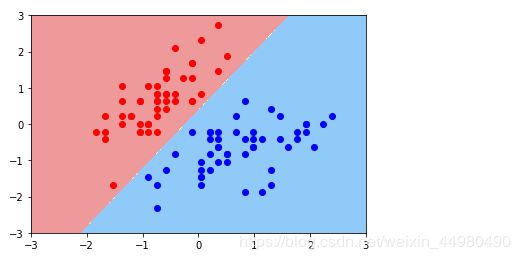
3、再次实例化一个SVC,并传入一个较小的 CC
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
结果显示如下:
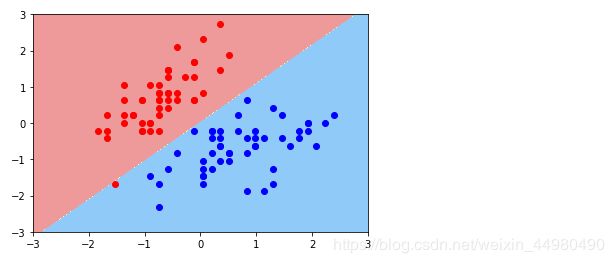
由两个图片可知,两次决策边界的绘制很明显存在差异 。
二、非线性数据处理
1、生成月亮数据
(1)月亮数据生成
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons() #使用生成的数据
print(X.shape) # (100,2)
print(y.shape) # (100,)
![]()
(2)月亮数据显示
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
月亮数据显示结果如下:
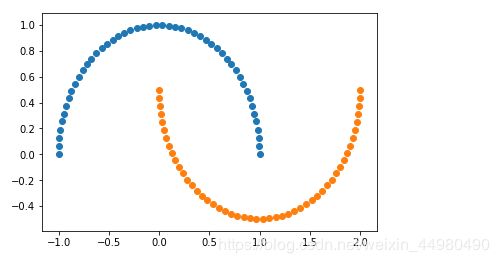
2、增加噪声点
X, y = datasets.make_moons(noise=0.15,random_state=777) #随机生成噪声点,random_state是随机种子,noise是方差
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
增加噪声点后,月亮数据集显示如下:
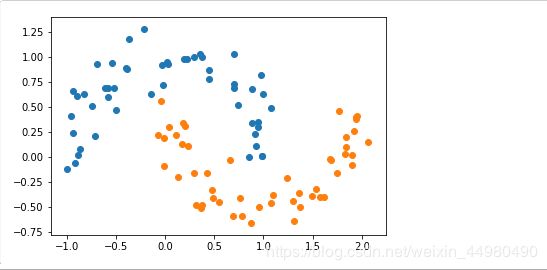
3、通过多项式特征的SVM分类
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([
("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
多项式分类结果如下:
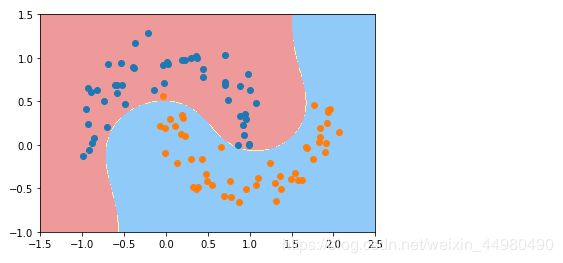
4、高维空间线性SVM处理
我们还可以使用核技巧来对数据进行处理,使其维度提升,使原本线性不可分的数据,在高维空间变成线性可分
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([
("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
高维空间线性分类显示如下:
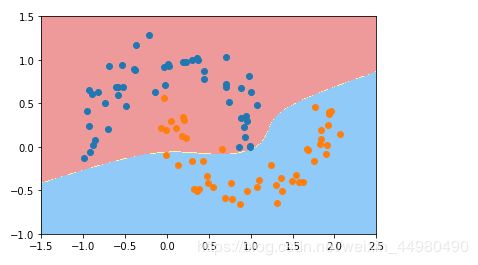
SVC(kernel=“poly”) 中参数 kernel ,就是核函数
三、核函数
1、核函数定义
核函数包括线性核函数、多项式核函数、高斯核函数等,其中高斯核函数最常用,可以将数据映射到无穷维,也叫做径向基函数(Radial Basis Function 简称 RBF),是某种沿径向对称的标量函数。
在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:
- 线性:K(v_1,v_2)= < v 1 , v 2 >
- 多项式:K(v_1,v_2)= ( γ < v 1 , v 2 > + c ) n (\gamma
- Radial basis function: K ( v 1 , v 2 ) = exp ( − γ ∣ ∣ v 1 − v 2 ∣ ∣ 2 ) K(v_1,v_2)=\exp(-\gamma||v_1-v_2||^2) K(v1,v2)=exp(−γ∣∣v1−v2∣∣2)
- Sigmoid:K(v_1,v_2)= tan h ( γ < v 1 , v 2 > + c ) \tan h(\gamma
2、高斯核函数
高斯函数
g ( x ) = 1 σ 2 π e − 1 2 ( x − μ σ ) 2 g(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2} g(x)=σ2π1e−21(σx−μ)2
高斯核函数和高斯函数很像
高斯核函数:
K ( v 1 , v 2 ) = exp ( − γ ∣ ∣ v 1 − v 2 ∣ ∣ 2 ) K(v_1,v_2)=\exp(-\gamma||v_1-v_2||^2) K(v1,v2)=exp(−γ∣∣v1−v2∣∣2)
高斯核函数的本质是将每个样本点映射到一个无穷多维度的特征空间中。
核函数都是依靠升维使得原本线性不可分的数据变得线性可分。
3、测试数据集生成
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-4,5,1)#生成测试数据
y = np.array((x >= -2 ) & (x <= 2),dtype='int')
plt.scatter(x[y==0],[0]*len(x[y==0]))# x取y=0的点, y取0,有多少个x,就有多少个y
plt.scatter(x[y==1],[0]*len(x[y==1]))
plt.show()
测试数据显示如下:
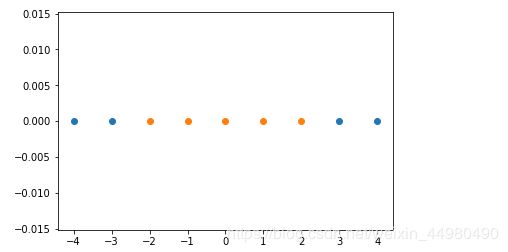
4、数据集升维处理
# 高斯核函数
def gaussian(x,l):
gamma = 1.0
return np.exp(-gamma * (x -l)**2)
l1,l2 = -1,1
X_new = np.empty((len(x),2)) #len(x) ,2
for i,data in enumerate(x):
X_new[i,0] = gaussian(data,l1)
X_new[i,1] = gaussian(data,l2)
plt.scatter(X_new[y==0,0],X_new[y==0,1])
plt.scatter(X_new[y==1,0],X_new[y==1,1])
plt.show()
处理后数据集显示如下:
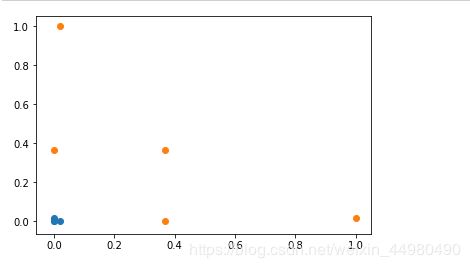
由数据集显示可知,升维后很容易对数据集进行分类
四、超参数
1、超参数定义
超参数:
- 定义关于模型的更高层次的概念,如复杂性或学习能力。
- 不能直接从标准模型培训过程中的数据中学习,需要预先定义。
- 可以通过设置不同的值,训练不同的模型和选择更好的测试值来决定
高斯函数
g ( x ) = 1 σ 2 π e − 1 2 ( x − μ σ ) 2 g(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2} g(x)=σ2π1e−21(σx−μ)2
在高斯函数中, σ \sigma σ 越大,分布就越宽
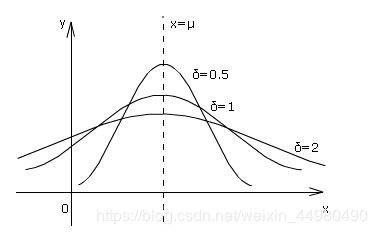
核函数中的 γ \gamma γ类似于 1 2 σ 2 2 σ 21 \frac{1}{2\sigma^2} 2 σ 2 1 2σ212σ21。
所以, γ \gamma γ越大,高斯分布越窄; γ \gamma γ 越小,高斯分布越宽。
接下来用代码来演示下 γ \gamma γ的取值对结果的影响。
2、生成数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X,y = datasets.make_moons(noise=0.15,random_state=777)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
生成如下数据集:
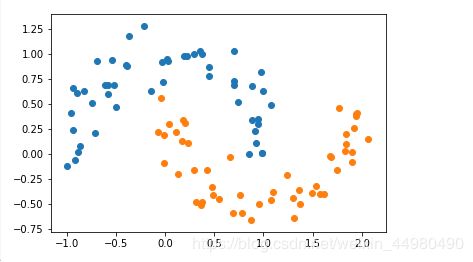
3、定义一个RBF核的SVM
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
显示结果如下:
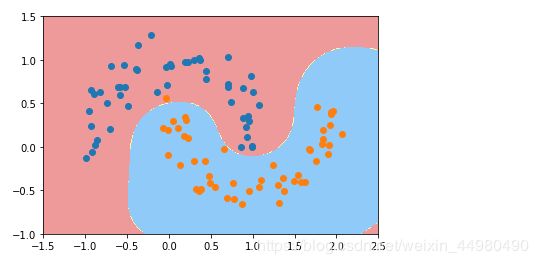
该图片显示下: γ \gamma γ=1.0
4、修改 γ \gamma γ值
(1) γ \gamma γ=100
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc = RBFKernelSVC(100)
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
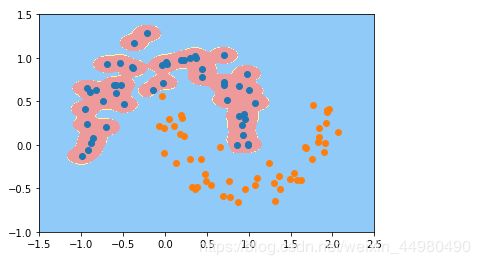
该图片显示中: γ \gamma γ=100
由两个图片比较可知: γ \gamma γ=100时,数据集分类更准确。
(2) γ \gamma γ=10
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc = RBFKernelSVC(10)
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
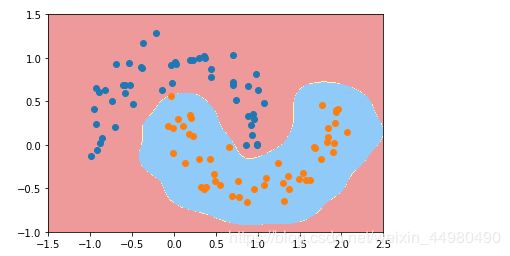
(3) γ \gamma γ=0.1
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc = RBFKernelSVC(0.1)
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
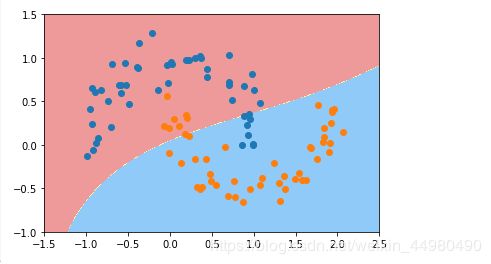
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=777) # 把数据集拆分成训练数据和测试数据
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
def StandardLinearSVR(epsilon=0.1):
return Pipeline([
('std_scaler',StandardScaler()),
('linearSVR',LinearSVR(epsilon=epsilon))
])
svr = StandardLinearSVR()
svr.fit(X_train,y_train)
svr.score(X_test,y_test) #0.6989278257702748
程序运行结果如下:
![]()