3.8 多层感知机 动手学深度学习——pytorch1.10
学了本文你能学到什么?仅供学习,如有疑问,请留言。。。
注:红色是小结, 紫色是重点,能像被课文一样背诵感知机
目录
3.8 多层感知机
3.8.1 隐藏层
3.8.2 激活函数
3.8.2.1 ReLU函数
3.8.2.2 sigmoid函数
3.8.2.3 tanh函数
3.8.3 多层感知机
小结
多层感知机在输出层与输入层之间加入了一个或多个全连接隐藏层,并通过激活函数对隐藏层输出进行变换。
常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。
# 3.8.1 隐藏层
多层感知机在单层神经网络的基础上引入了一到多个隐藏层(hidden layer)。
"多层感知机中的隐藏层和输出层都是全连接层。"
隐藏层位于输入层和输出层之间。
图3.3展示了一个多层感知机的神经网络图,它含有一个隐藏层,该层中有5个隐藏单元。

# 3.8.2 激活函数
不难发现,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。
上述问题的根源在于全连接层只是对数据做仿射变换(affine transformation),而多个仿射变换的叠加仍然是一个仿射变换。
解决问题的一个方法是引入非线性变换,例如对隐藏变量使用按元素运算的非线性函数进行变换,然后再作为下一个全连接层的输入。这个非线性函数被称为激活函数(activation function)。
# 3.8.2.1 ReLU函数

"ReLU函数只保留正数元素,并将负数元素清零。"
import torch
import numpy as np
import matplotlib.pyplot as plt
import sys
sys.path.append("..") # 为了导入上层目录的d2lzh_pytorch
import d2lzh_pytorch as d21
#
# def xyplot(x_vals, y_vals, name):
# d21.set_figsize(figsize = (5, 2.5))
# d21.ple.plot(x_vals.detach().numpy(), y_vals.detach().numpy())
# d21.plt.xlabel("x")
# d21.plt.ylabel(name +"(x)")
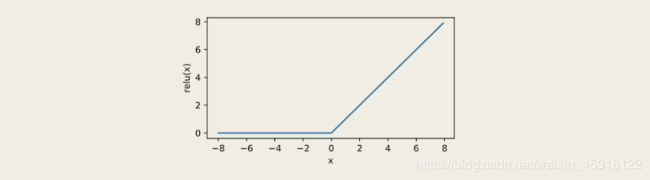
# #我们接下来通过Tensor提供的relu函数来绘制ReLU函数。可以看到,该激活函数是一个两段线性函数。
# x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
# y = x.relu()
# xyplot(x, y, 'relu')
"""
当输入为负数时,ReLU函数的导数为0;当输入为正数时,ReLU函数的导数为1。尽管输入为0时ReLU函数不可导,但是我们可以取此处的导数为0。
y.sum().backward()
xyplot(x, x.grad, 'grad of relu')
"""

# 3.8.2.2 sigmoid函数
"sigmoid函数可以将元素的值变换到0和1之间:"

下面绘制了sigmoid函数。当输入接近0时,sigmoid函数接近线性变换。
y = x.sigmoid()
xyplot(x, y, 'sigmoid')

"当输入为0时,sigmoid函数的导数达到最大值0.25;当输入越偏离0时,sigmoid函数的导数越接近0。"

# 3.8.2.3 tanh函数
"tanh(双曲正切)函数可以将元素的值变换到-1和1之间:"
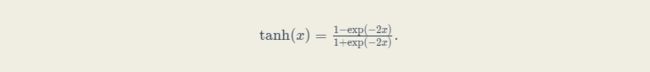
"当输入接近0时,tanh函数接近线性变换。虽然该函数的形状和sigmoid函数的形状很像,但tanh函数在坐标系的原点上对称。"
y = x.tanh()
xyplot(x, y, 'tanh')

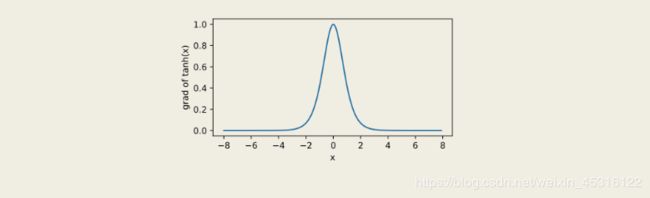
"当输入为0时,tanh函数的导数达到最大值1;当输入越偏离0时,tanh函数的导数越接近0。"
x.grad.zero_()
y.sum().backward()
xyplot(x, x.grad, 'grad of tanh')
# 3.8.3 多层感知机
"多层感知机就是含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过激活函数进行变换。"
"多层感知机的层数和各隐藏层中隐藏单元个数都是超参数"

"在分类问题中,我们可以对输出OO做softmax运算,并使用softmax回归中的交叉熵损失函数。"
"在回归问题中,我们将输出层的输出个数设为1,并将输出OO直接提供给线性回归中使用的平方损失函数。"
参考链接:http://tangshusen.me/Dive-into-DL-PyTorch/#/chapter03_DL-basics/3.8_mlp?id=_38-%E5%A4%9A%E5%B1%82%E6%84%9F%E7%9F%A5%E6%9C%BA