oracle体系结构理解
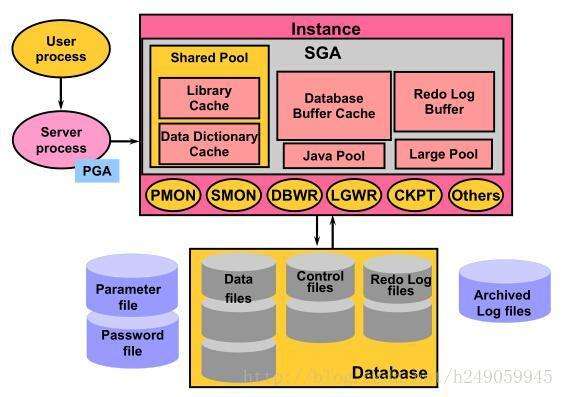
oracle体系结构:带着四个问题来学习这门课
1、告诉你数据后台都有什么
2、数据库中有哪些主键
3、每个主键都有哪些作用
4、将来怎么管理这些主键
======================================================
首先,数据库在操作系统下有一个软件,这个软件我们管理不了,软件引擎是花钱买的, Oracle数据库不是开源的,
所以核心代码都是封装好的,我们拿过来用就是了,没有机会对它更改。
我们能管理的是由该软件创建出来的数据库。
那么我们在做添删改查的时候到底都由哪些主键参与工作:
一、:外围主键
1、当你从终端启动的,一个能写sql语句的,与oracle服务器进行交互的小程序,我们叫它用户进程,
即sqlplus、sqldevloper,无论哪一个都属于user process。也就是接口程序的意思。通常在client端。
2、一个用户进程怎么去访问磁盘上的海量数据呢?
一个用户进程如果想工作,所发出的命令都要传给服务端的一个进程,叫做server process,
即必须用服务进程来解析发出的这条语句后,才能工作。
也就是说服务进程是帮我们处理sql命令、解析sql,帮助我们做提交和回退,帮助我们到硬盘中读取所需要的数据块。
3、那么服务进程是如何从硬盘中找到我们所需要的数据呢?
我们最终的数据是放在二进制文件中,这是物理库在磁盘中存在的我们能看的见的文件,我们叫它database
但是硬盘中的数据我们常常无法直接对他操作,需要把它先加载到内存中,如果直接到硬盘中读数据,硬盘慢cpu快,
就会出现cpu一直空闲,硬盘在不断工作,效率太低。
为了缓冲IO瓶颈,Oracle在操作数据库的时候把经常访问的数据都加在到内存当中。Oracle为了便于我们学习,
把自己这套软件在内存当中所加载的所有模块统称为实例instance。
Oracle给实例下的定义是:实例是访问数据库的手段,必须通过实例才能访问物理库。
===========================================================================
实例由两部分部分组成
即由一块内存加一组后台进程组成的实例这个主键。实例这个主键将来能操作物理库。
Oracle有150多个后台进程,但是默认启动也就20多个,这么多后台进程中只有五个叫核心后台进程,
非主要核心进程即使崩溃了,Oracle也有能力去重新启动。
介绍实例:
由服务进程来直接和实例交互
实例的这块内存,Oracle称为sga(系统全局区或共享全局区)
sga这块内存主键,Oracle把它隔离成若干个内存池。虽然叫sga,但是里边由很多小的模块组成。
具体如下:
1、共享池 share pool
共享池中Oracle又把它分为两个小模块
1)、liberay cache库高速缓存
2)、data dictionary cache 数据字典缓冲区高速缓存
2、database buffer cache 数据库缓冲区高速缓存
3、large pool大池
4、java pool java池
5、streams pool流池
6、redo log buffer重做日志缓冲区
user process写sql语句------>server process处理sql语句----->对数据库的操作通过实例
|
|
(六个模块)内存<----------->进程
--------------------------------------------------------------------------------------------------------------
各个内存模块的作用:
share poor共享池
共享池的作用实际就是liberay cache和data dictionary cache的作用。
liberay cache库高速缓存
里边存的sql语句和PL/SQL块,你所运行的SQL语句,你所调用的PL/SQL块都会缓存到这块内存中,目的是减少SQL语句的重解析。
目的:oracle数据库在工作时如果每时每刻运行的SQL都是不相同的,我们就无法优化了。所以系统下将来所接受的SQL语句大多情况下是相同或相似的。
oracle为了加速SQL语句的运行,就会把运行过的SQL语句在内存中缓存一份,以便于以后这条语句再次执行的时候起到加速效果。一条SQL语句发出后到结果集返回数据库都做了什么:
大体分为三个阶段:
1、解析:(解析的过程就是拿到最佳的执行计划或者访问路径)
2、执行:(按照执行计划访问后台对象,执行计划是指访问数据的最佳路径,如全表扫描批量读取,索引访问单块读取等)
3、获取:(把从数据库中找到的符合条件的结果集回传给client端)
在1阶段之前会有一个步骤:共享池扫描:发出一条SQL语句后,oracle会先去共享池liberay cache中查看这条命令是否存在。假如找到即命中,则视为一次软解析成功。
所以一条SQL语句的快慢取决于解析阶段,获取最佳的执行计划。
解析过程分为两种操作:
1、硬解析:一次硬解析的过程如下
1)、语法分析:如果是一条新SQL,数据库会先对其做语法分析,是否满足oracle的SQL语法规则。
2)、语意分析:校验SQL语句中所涉及的对象、用户、列名等属性信息的存在否及有效性等。3)、安全审核:对SQL语句进行安全审核,校验发出的SQL语句有没有权限访问数据。
4)、优化:oracle要对SQL语句进行优化,即筛选执行计划。oracle有一个最核心的主键叫做优化器。它会找出这条SQL所有可能的执行计划,然后针对消耗的成本(cost)进行对比,找出成本最低的执行计划。
5、行资源生成:把资源写入,即把找到文本以及计划写入到共享池liberay cache。这里既有SQL语句的文本,还有SQL语句的执行计划。
2、软解析:就是在解析阶段之前的命中就是软解析。
------------------------------------------------------------------------------------------------------------------
data dictionary cache数据字典缓冲区高速缓存
这个模块中保存了以行为单位,最近所访问的数据字典里的数据(如表名table_name,用户user_name,列名col_name都在数据字典中校验是否存在及有效性等信息),
数据字典是在系统表空间里即在硬盘中。所以使用该模块目的是加速SQL语句的解析,因为SQL语句经常要与数据字典打交道,所有用户的信息,属性的信息都存于数据字典。
因此share poor这块内存池的作用就是减少SQL语句的重解析和加速SQL语句的解析,都与SQL相关。
---------------------------------------------------------------------------------------------------------------
数据库缓冲区高速缓存database buffer cache
作用:减少IO瓶颈即减少与硬盘的交互。所有对数据的访问,我们都不在硬盘上去做,而是在内存里把硬盘块做一个镜像。
所有的添删改查都是在对这个镜像做处理即在实例中(database buffer cache)完成,永远都不是在直接操作存储。目的就是为了加速数据读取和修改的效率。
--------------------------------------------------------------------------------------------------
内存小硬盘大怎样用少量内存操作大量数据:(有一种清理内存的机制)
oracle对于内存的管理有一种LRU算法,即最近最少使用原则。
oracle会把每一个进入内存的块所进入内存的时间和频率记录下来,然后把这些块逻辑上维护在一个列表下。这个列表有热端,有冷端末尾,有冷端头。如果现在内存空间不足了,所有内存的堆栈模块都被缓存了数据,现在还有一张表需要查询,即需要进入内存。oracle会从LRU列表的冷端末尾把这些块清掉,释放出来一些内存模块出来,再把硬盘中的一些数据加载进去。这样不断把冷端末尾的块清掉,把数据加载到内存。
用LRU算法管理内存中的有限空间,以DB BLOCK块为单位去进行读和回写,而在创建数据库的时候就决定了它default值是8K。换句话说,即使查询数据只有一行(几个字节),oracle也会把它所在的8K块都加载入内存,这样虽然浪费了内存空间,
但是减少了物理IO次数,以后再读取该数据就不用再与硬盘交互了。
===========================================================================large poor大池
存放与SQL操作和PL/SQL操作不相关的块,如备份还原恢复时涉及到的块。这个池对数据库性能影响不大,如果临时需要增加备份还原的效率可以加大该池的分配空间。
------------------------------------------------------------------------------------------------------------------------------
java poor
如果前端有一些java代码的编译需求需要加载到内存中去做,就需要开这个池------------------------------------------------------------------------------------------------------------------------------
流池streams pool
到oracle11G,流复制技术已经停止开发使用。------------------------------------------------------------------------------------------------------------------------
redo log buffer重做日志缓冲区
记录的是所有数据块的变化即redo条目。数据块的修改将来是要写盘的,但是不能一有日志就写盘或者说一有变化就写盘,这样IO太频繁。所以为了减少日志写盘的频繁程度,缓冲IO的瓶颈,才引入了log buffer。
===========================================================================
实例的另外一部分是后台进程:
一、PMON---进程监视器(启动数据库时候第一个加载的进程)
作用: 1、监控其它的非主要核心进程,如果非主要核心进程意外终止,由PMON负责重启。
2、清理由意外终止的连接在服务器端遗留的垃圾资源。例如:有的时候一些会话可能在服务器上加了一些锁,做了一些数据修改,把一些数据在内存中给冻结了。即insert、update、delete,还没有提交,也没有回退,这时候突然网络断了,或者突然死机了,这些都属于user process意外终止,那你刚才做了修改,肯定破坏了数据,而你有没有机会提交和回退,这时候就由PMON把这些数据做rollback。把遗留的资源释放。
3、在网络环境中,将实例的信息注册到监听程序,注册周期60秒即60秒做一次。4、在集群环境,以60秒为单位,收集当前节点的CPU压力。将来会以cpu压力信息来做负载均衡。
二、DBWN---数据写进程,把脏块写到数据文件。这个N是取值范围(0-9、A-J)
作用:把内存(database buffer cache)中的脏数据回写到硬盘,即做数据同步。什么时候会触发该进程去写盘:(9种情况触发数据写)
1、检查点checkpoint,如果产生检查点,后台就会触发日志写。2、脏数据达到预值,default值是10%,会触发。
3、扫描整个database buffer cache没有空闲空间可用。4、timeout,default值是3秒,老版本有,oracle10之后去掉了。
5、集群环境下的ping请求---RAC request触发数据写。集群环境如果想协同工作,多个实例的数据要一致,即一号机修改二号 要可见,二号机修改一号也得可见。实现原理:oracle在后台发出一个ping事件,触发多实例的数据同步,即把数据修改都写到磁盘阵列,然后在数据库里边重新分发,这样来实现双节点的数据同步。
6、表级别的drop、truncate----drop table、truncate table。7、tablespace readonly,即表空间只读触发。
8、tablespace offline,即表空间离线触发。9、热备份命令触发,即begin backup。
三、SMON---系统监控程序作用:1、空间管理
体现在两方面:1)定期合并空闲。
2)回收临时段。
2、实例恢复:包含三个操作
1、前滚
2、回滚3、释放资源
当系统掉电,实例意外终止。因为数据修改是在实例当中去做的,而数据修改的写盘动作不是时时刻刻在做的,因此可能存在已经提交还没写盘的数据就需要前滚。也可能出现未提交但是数据修改已经写盘,那么重启时就需要还原,既然没提交就会有老镜像,那么由SMON把老镜像拿回来做回滚恢复,最后把所有的锁资源释放。这就是实例恢复的三个动作。
四、CKPT---检查点进程要做三件事:
1、调度数据写
2、把已经完成的检查点写入到数据文件头3、将完成的检查点写入到控制文件
五、LGWR---日志写进程把redo条目写到联机日志
redo的作用是将来做recovery的,所以redo放在内存中是没有用的,掉电就全没了,所以有用的日志必须写入硬盘,那么日志是怎么从log buffer到硬盘的呢,就是由LGWR写进来的。
写入硬盘的redo才可以参与recovery,如果日志不写盘,数据一定不会写盘。
那么什么时候会触发日志写:
1、提交commit
2、log buffer达到三分之一满。
3、timeout
4、任何一次数据写之前。 即日志写发生在数据写之前,因此日志写要比数据写频繁。只要日志写入硬盘,理论上就可以认为数据已经写盘了,因为即使系统掉电,将来也可以recovery。