【sklearn第十讲】支持向量机之回归篇
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
回归
支持向量分类的方法能被推广到解决回归问题,称为支持向量回归。由支持向量分类产生的模型仅依赖训练数据的子集,因为创建模型的代价函数并不考虑超过边界的训练点。类似地,由支持向量回归产生的模型仅依赖训练数据的子集,因为创建模型的代价函数忽略任何接近模型预测的训练数据。支持向量回归有三个不同的执行版本:SVR, NuSVR, LinearSVR. LinearSVR执行速度比SVR要快,但只提供线性核。fit方法取X, y作为输入参数,这里,y取浮点值而不是分类的整数值。
from sklearn import svm
X = [[0, 0], [2, 2]]
y = [0.5, 2.5]
clf = svm.SVR()
clf.fit(X, y)

clf.predict([[1, 1]])

异常检测
One-class SVM可以被用于异常检测(novelty detection), 即,给定一个样本集,检测该集的灵活边界,以便将新的数据点归类是否属于这个集合。类OneClassSVM执行之。这是一个典型的无监督学习,所以fit方法只有一个数组X作为输入,并没有类标签。

核函数
可以使用以下的核函数:
-
linear: < x , x ′ > <x, x'> <x,x′>
-
polynomial: ( γ < x , x ′ > + r ) d (\gamma<x, x'>+r)^d (γ<x,x′>+r)d, d d d 由参数degree, r r r 由coef0指定
-
rbf: exp ( − γ ∥ x − x ′ ∥ 2 ) \exp(-\gamma\|x-x'\|^2) exp(−γ∥x−x′∥2), γ \gamma γ 由参数gamma指定,且必须是正的
-
sigmoid: tanh ( γ < x , x ′ > + r ) \tanh(\gamma<x, x'>+r) tanh(γ<x,x′>+r), r r r 由参数coef0指定
数学原理
数学上,一个支持向量机在一个高维或有限维空间构造了一个或一组超平面,这些超平面被用作分类、回归或其它任务。本质上,由超平面实现的最优分割,即是这个超平面到任何类的最近的训练数据点的距离是最大的。通常来说,边界越大,分类器的泛化误差(generalization error)就越低。
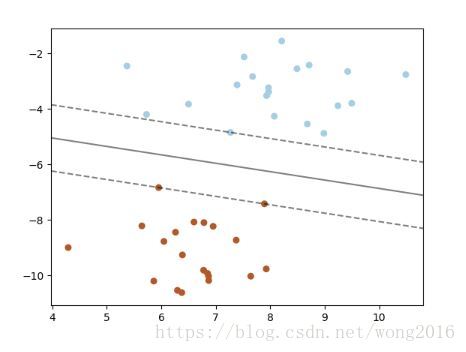
SVC
给定训练向量 x i ∈ R p , i = 1 , 2 , … , n x_i\in\mathbb{R}^p, \, i=1, 2, \dots, n xi∈Rp,i=1,2,…,n. 对于两类,设向量 y ∈ { − 1 , 1 } n y\in \{-1, 1\}^n y∈{−1,1}n. SVC解决了以下的优化问题:
\begin{align*}
& \mathop{\min}_{w, b, \zeta} ,,, \dfrac{1}{2}w\mathrm{T}w+C\sum\limits_{i=1}n zeta_i \
& s. , t. ,, y_i(w^\mathrm{T}\phi(x_i)+b)\ge 1-\zeta_i, \
&\zeta_i \ge 0, , i=1, 2, \dots, n
\end{align*}
其对偶形式为
\begin{align*}
& \mathop{\min}_{\alpha} \ \ \frac{1}{2}\alpha\mathrm{T}Q\alpha-e\mathrm{T}\alpha\
& s. , t. ,, y^\mathrm{T}\alpha=0\
& 0\le\alpha\le C, , i=1, 2, \dots, n
\end{align*}
这里, e e e 是分量全为1的向量, C > 0 C>0 C>0 是上界, Q Q Q 是 n n n 阶正的半正定矩阵。
Q i j = y i y j K ( x i , x j ) Q_{ij}=y_i y_j K(x_i, x_j) Qij=yiyjK(xi,xj), K ( x i , x j ) = ϕ ( x i ) T ϕ ( x j ) K(x_i, x_j)=\phi(x_i)^\mathrm{T}\phi(x_j) K(xi,xj)=ϕ(xi)Tϕ(xj) 是核。 函数 ϕ \phi ϕ 的作用是将输入向量映射到高维空间。
决策函数是:
s g n ( ∑ i = 1 n y i α i K ( x i , x ) + ρ ) sgn(\sum\limits_{i=1}^n y_i \alpha_i K(x_i, x)+\rho) sgn(i=1∑nyiαiK(xi,x)+ρ)
注意:虽然大多数估计量使用 α \alpha α 作为正则参数,而来自libsvm, liblinear的SVM使用C. 两个模型的正则量的精确等价性依赖优化模型的目标函数形式。例如,当使用的估计量是sklearn.linear_model.Ridge回归时, C = α − 1 C=\alpha^{-1} C=α−1.
可以通过保存 y i α i y_i\alpha_i yiαi 的成员函数 dual_coef_, 保存支持向量的成员函数support_vectors_, 保存独立项 ρ \rho ρ 的intercept_访问参数。
NuSVC
我们介绍一个新参数 ν \nu ν, 它控制支持向量的数量和训练误差。参数 ν ∈ ( 0 , 1 ] \nu\in(0, 1] ν∈(0,1], 是训练误差比例的上界,同时也是支持向量比例的下界。
SVR
给定训练向量 x i ∈ R p , i = 1 , 2 , … , n x_i\in\mathbb{R}^p, \, i=1, 2, \dots, n xi∈Rp,i=1,2,…,n. ϵ \epsilon ϵ-SVR解决下面的优化问题:
\begin{align*}
& \mathop{\min}_{w, b, \zeta, \zeta^} \ \ \frac{1}{2}w\mathrm{T}w+C\sum\limits_{i=1}n (\zeta_i+\zeta_i^) \
& s. , t. ,, y_i-w^\mathrm{T}\phi(x_i)-b\le\epsilon+\zeta_i, \
& w\mathrm{T}\phi(x_i)+b-y_i\le\epsilon+\zeta_i, \
& \zeta_i, \zeta_i^ \ge 0, , i=1, 2, \dots, n
\end{align*}
对偶形式
\begin{align*}
& \mathop{\min}_{\alpha, \alpha^} \ \ \frac{1}{2}(\alpha-\alpha*)\mathrm{T}Q(\alpha-\alpha^)+\epsilon e\mathrm{T}(\alpha+\alpha)-y\mathrm{T}(\alpha-\alpha) \
& s. , t. ,, e\mathrm{T}(\alpha-\alpha)=0 \
& 0\le \alpha, \alpha^\le C , , i=1, 2, \dots, n
\end{align*}
这里, e e e 是全为1的向量, C > 0 C>0 C>0 是上界, Q Q Q 是 n n n 阶正的半正定矩阵。
Q i j = K ( x i , x j ) = = ϕ ( x i ) T ϕ ( x j ) Q_{ij}=K(x_i, x_j)==\phi(x_i)^\mathrm{T}\phi(x_j) Qij=K(xi,xj)==ϕ(xi)Tϕ(xj) 是核。训练数据由 ϕ \phi ϕ 映射到高维空间。
决策函数是:
∑ i = 1 n ( α − α ∗ ) K ( x i , x ) + ρ \sum\limits_{i=1}^n (\alpha-\alpha^*)K(x_i, x)+\rho i=1∑n(α−α∗)K(xi,x)+ρ
这些参数由保存 α − α ∗ \alpha-\alpha^* α−α∗ 的成员函数dual_coef_, 保存支持向量的support_vectors_, 保存 ρ \rho ρ 的intercept_访问。
阅读更多精彩内容,请关注微信公众号:统计学习与大数据