【git】分布式版本管理系统工作原理详解
1 本地化版本控制系统

工作原理基本上就是保存并管理文件补丁(patch)。文件补丁是一种特定格式的文本文件,记录着对应文件修订前后的内容变化。所以,根据每次修订后的补丁,rcs 可以通过不断打补丁,计算出各个版本的文件内容。
2 集中化版本控制系统(CVS SVN Perforce)
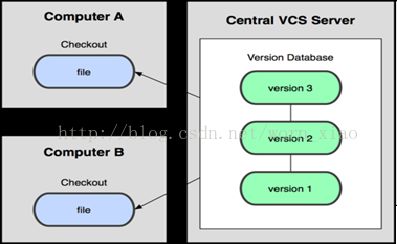
都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新.
3 分布式版本控制系统(GitMercurial BazaarDarcs)

客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。因为每一次的提取操作,实际上都是一次对代码仓库的完整备份
优势
• 直接纪录快照,而非差异比较
• 近乎所有操作都是本地执行
• 时刻保持数据完整性
• 多数操作仅添加数据
保存每次更新时的文件快照
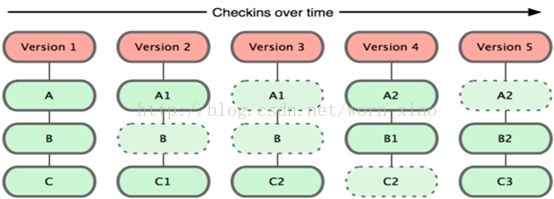
集中式版本管理系统

绝大多数操作都只需要访问本地文件和资源,不用连网如果要浏览项目的历史更新摘要,Git 不用连到外面的服务器上去取数据回来,而直接从本地数据库读取后展示给你看。
时刻保持数据完整性
SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个SHA-1 哈希值,作为指纹字符串,所有保存在Git 数据库中的东西都是用此哈希值来作索引的,而不是靠文件名
计算步骤:1补位 2补长度3消息常量函数4 使用函数5计算摘要。
特点:
常用的 Git 操作大多仅仅是把数据添加到数据库。因为任何一种不可逆的操作,比如删除数据,都会使回退或重现历史版本变得困难重重。
在别的VCS 中,若还未提交更新,就有可能丢失或者混淆一些修改的内容,但在Git 里,一旦提交快照之后就完全不用担心丢失数据.
• 文件的三态:已暂存,已修改,已提交。文件的生命周期
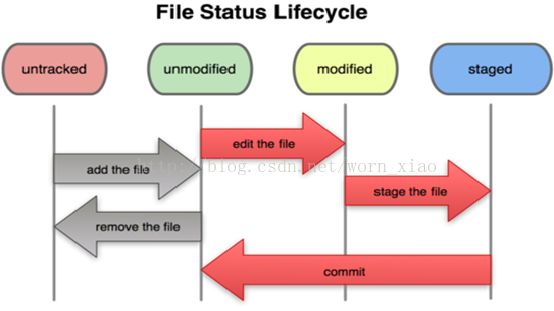
文件流转的区域:

基本的Git工作流程如下:
1 从git仓库中checkout项目到工作目录。
2 在工作目录修改某些文件。
3 对修改后的文件进行快照,然后保存到暂存区域。
4 提交更新,将保存在暂存区域的文件快照永久转储到Git目录中
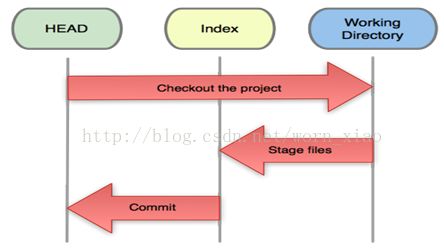
添加文件
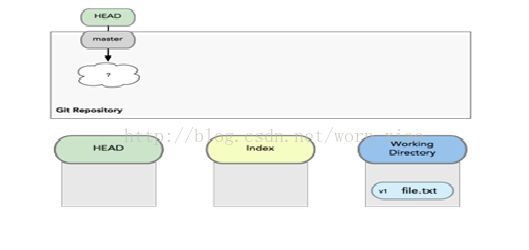



第二次添加文件生成版本库。

初次运行Git 前的配置.
$ git config --global user.name lvl
$ git config --global user.email [email protected]
$ git help config 获取帮助。
1 在工作目录中初始化新仓库
$ git init.
2 从现有仓库克隆
git clone [url]
Git目录
|-- HEAD # 这个git项目当前处在哪个分支里
|-- config # 项目的配置信息,git config命令会改动它
|-- description # 项目的描述信息
|-- hooks/ # 系统默认钩子脚本目录
|-- index # 索引文件
|-- logs/ # 各个refs的历史信息
|-- objects/ # Git本地仓库的所有对象 (commits,trees, blobs, tags)
`-- refs/ # 标识你项目里的每个分支指向了哪个提交(commit)。
检查当前文件状态
$ vim README
$ git status
# On branch master
# Untracked files:
# (use "git add
# README
nothing added to commit but untracked filespresent (use "git add" to track)
忽略某些文件
$ cat .gitignore #作用于.gitignore所存放的目录
# 此为注释 – 将被 Git 忽略
*.a # 忽略所有.a 结尾的文件
!lib.a # 但lib.a 除外
/TODO # 仅仅忽略项目根目录下的TODO 文件,不包括subdir/TODO
build/ # 忽略build/ 目录下的所有文件
doc/*.txt # 会忽略 doc/notes.txt 但不包括 doc/server/arch.txt
*.[oa] # 忽略所有以 .o 或 .a 结尾的文件
查看已暂存和未暂存的更新---Git diff
$ git diff # 工作区和暂存区比较
$ git diff --cached # HEAD和暂存区比较
$ git diff HEAD # HEAD和工作区比较
$ git diff HEAD HEAD^ # HEAD和HEAD的父版本比较
$ git diff HEAD~2 HEAD^ # HEAD父父版本和HEAD的父版本比较
rm filename #仅工作目录删除
git rm filename #删除并存入暂存区
git rm --cached filename #删除暂存区内的文件
$ gitk #使用图形化工具查阅提交历史
$ git reset HEAD filename取消已经暂存的文件
$ git checkout – filename取消对文件的修改
远程仓库的使用
$ git clone [email protected]:repos/share.git克隆
$ git remote add temp [email protected]:repos/share.git添加远程仓库
$ git pull
$ git push
实战团队开发工作流
1集中式工作流
通常,集中式工作流程使用的都是单点协作模型。一个存放代码仓库的中心服务器,可以接受所有开发者提交的代码。所有的开发者都是普通的节点,作为中心集线器的消费者,平时的工作就是和中心仓库同步数据

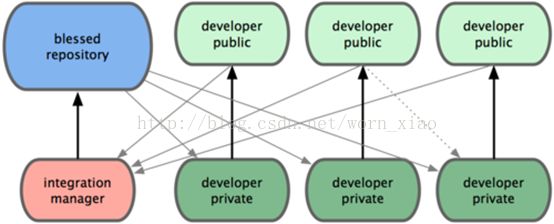
集成管理员工作流
1.项目维护者可以推送数据到公共仓库 blessedrepository。
2.贡献者克隆此仓库,修订或编写新代码。
3.贡献者推送数据到自己的公共仓库 developerpublic。
4.贡献者通知维护者,请求拉取自己的最新修订。
5.维护者在自己本地的 integrationmanger 仓库中,将贡献者的仓库加为远程仓库,合并更新并做测试。
6.维护者将合并后的更新推送到主仓库 blessedrepository。
1.SVN优缺点
优点:
1、 管理方便,逻辑明确,符合一般人思维习惯。
2、 易于管理,集中式服务器更能保证安全性。
3、 代码一致性非常高。
4、 适合开发人数不多的项目开发。
缺点:
1、 服务器压力太大,数据库容量暴增。
2、 如果不能连接到服务器上,基本上不可以工作,看上面第二步,如果服务器不能连接上,就不能提交,还原,对比等等。
3、 不适合开源开发(开发人数非常非常多,但是Google app engine就是用svn的)。但是一般集中式管理的有非常明确的权限管理机制(例如分支访问限制),可以实现分层管理,从而很好的解决开发人数众多的问题。
2.Git优缺点
优点:
1、适合分布式开发,强调个体。
2、公共服务器压力和数据量都不会太大。
3、速度快、灵活。
4、任意两个开发者之间可以很容易的解决冲突。
5、离线工作。
缺点:
1、学习周期相对而言比较长。
2、不符合常规思维。
3、代码保密性差,一旦开发者把整个库克隆下来就可以完全公开所有代码和版本信息。
课程分享
https://edu.csdn.net/course/detail/9287