电商行业场景化项目分析(下)——数据分析
根据 电商行业场景化项目分析(上)——数据清洗,我们已经将数据清理完成,接下来我们使用Python进行可视化分析。
总体概览
# 1、 销售GMV
gmv = round(data['orderAmount'].sum()/10000, 2)
# 2、 成交总和
pay_sum = round(data['payment'].sum()/10000, 2)
# 3、 实际成交额
real_paysum = round(data[data['chargeback']=='否']['payment'].sum()/10000, 2)
# 4、 订单数量
order_count = data['orderID'].unique().size
# 5、 退货订单数
orderback_count = data[data['chargeback']=='是']['orderID'].size
# 6、 退货率
rate = round(orderback_count/order_count*100, 2)
# 7、 用户数
user_count = data['userID'].unique().size
2019年销售额、成交总和、实际成交额趋势
data['month'] = data['orderTime'].dt.month
gmv_month = round(data.groupby('month')['orderAmount'].sum()/10000, 2)
pay_sum_month = round(data.groupby('month')['payment'].sum()/10000, 2)
real_paysum_month = round(data[data['chargeback']=='否'].groupby('month')['payment'].sum()/10000, 2)
x = data['month'].unique()
plt.figure(figsize=(12,7))
plt.grid(alpha=0.4, c='grey')
x_title_label = ['{}月份'.format(i) for i in x] #x轴名称
plt.xticks(x,x_title_label)
plt.xlabel('月份')
plt.ylabel('金额(万)元')
plt.title('2019年销售额走势图', fontsize=15)
for a, b in zip(x, gmv_month):
plt.text(a, b, b, va='bottom', ha='center')
plt.plot(x, gmv_month, label='销售GMV')
plt.plot(x, pay_sum_month, label='成交总和')
plt.plot(x, real_paysum_month, label='实际成交额')
plt.legend(fontsize=15)
plt.show()
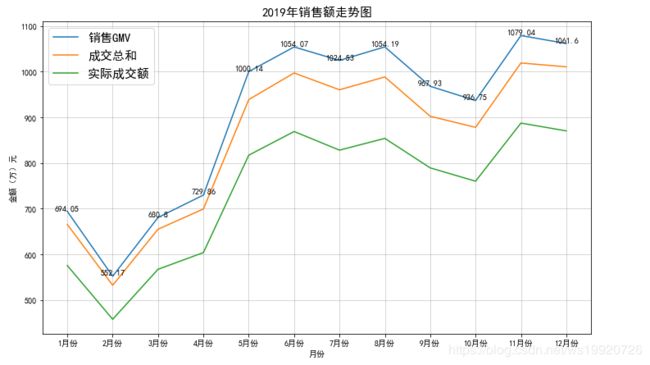
通过走势图可以看到,2月份销量最低,可能是因为2月份正好出于中国春节,各快递公司都休假,而且假期中用户的在线购买欲望不高;6月份、11月份是各大电商的购物节,故销量高也属于正常情况;4月到5月销量增长迅猛,我们可以猜测是否这段时间平台的销售策略比较成功,是否有值得借鉴的部分。
流量渠道来源分析,各渠道用户占比
user_per = data.groupby('chanelID')['userID'].count()
chanel = data['chanelID'].unique()
plt.figure(figsize=(12,10))
plt.pie(user_per, labels=chanel, autopct='%1.1f%%', startangle=90)
plt.title('各渠道用户比例', fontsize=18)
plt.show()

用户行为,按周一到周日统计订单量情况,研究订单量和星期的关系
data['weekday'] = data['orderTime'].dt.dayofweek
dayofweek = data['weekday'].unique()
order_week = data.groupby('weekday')['orderID'].count()
x_label = ['周一','周二','周三','周四','周五','周六','周日']
plt.figure(figsize=(12,8))
plt.xticks(range(len(x_label)), x_label)
plt.xlabel('星期')
plt.ylabel('订单量')
plt.title('订单量统计', fontsize=18)
for a, b in zip(range(len(x_label)), order_week):
plt.text(a, b, b, va='bottom', ha='center', fontsize=12)
plt.bar(range(len(x_label)), order_week.values, color=['r','b','pink','g'])
plt.show()
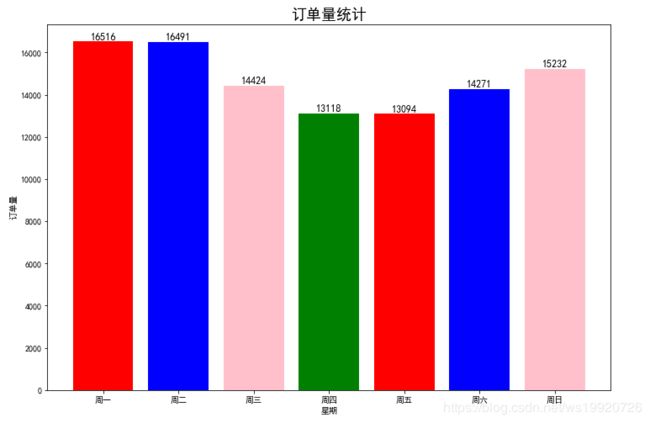
通过条形图可以看出,每周一、周二,销售额明显高于其他日期,所以我们是否可以在周一、周二更多的发布购物相关活动,以此吸引更多用户下单,另外周四、周五属于销售疲软期,如果安排休假等,我们可以尽量安排在这两天。
不同时间段用户下单情况统计
import seaborn as sns
s = data['orderTime'].dt.floor('30T')
#将下单时间按照时间段分类
data['orderTime_new'] = s.dt.strftime('%H:%M') + '-' + (s + pd.Timedelta(minutes=29)).dt.strftime('%H:%M')
time_quan = data.groupby('orderTime_new')['orderID'].count()
plt.figure(figsize=(16,8))
plt.xticks(rotation=90)
plt.ylabel('订单量')
plt.title('不同时间段订单量统计', fontsize=18)
sns.barplot(time_quan.index, time_quan.values)
plt.show()
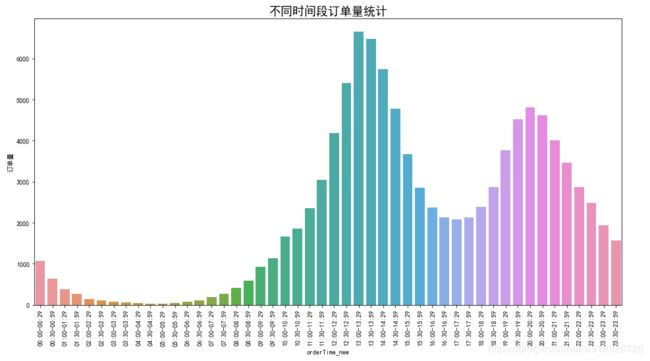
可以看到,每天的下单高峰期处于12:30-14:30、19:30-22:00期间,如有秒杀、团购等活动,可以尽量考虑安排在这两个时间段;每天凌晨用户的下单量最低,可以考虑在这个时间段进行更新、迭代版本等工作。
用户行为:复购率情况
pivoted = data.pivot_table(index='userID', columns='month', values='orderTime', aggfunc='count', fill_value=0)
# pivoted.sample(5)
#数据转换,消费两次以上记为1,消费1次记为0,没有消费记为NaN
pivoted_buy = pivoted.applymap(lambda x : 1 if x>1 else 0 if x==1 else np.NAN)
# pivoted_buy.sample(5)
plt.figure(figsize=(12,8))
plt.grid(alpha=0.4)
plt.ylabel('复购率(%)')
plt.title('用户复购率', fontsize=18)
sns.lineplot(pivoted.columns, pivoted_buy.sum()/pivoted_buy.count()*100)

根据走势图,我们可以看到用户的复购率低于3%,所以下一段的重点目标可以考虑如何提升用户的复购率。
用户RFM模型
data2 = data.copy()
#删除退单
data2.drop(data2[data2['chargeback']=='是'].index, inplace=True)
#时间格式转化
data2['orderTime'] = pd.to_datetime(data2['orderTime'], format='%Y-%m-%d')
#将用户ID设置为索引
data2.set_index('userID', inplace=True) #drop默认为True,即不保留原列
#新建订单量字段,并设置为1
data2['orders'] = 1
# data2.sample(5)
#数据透视表
rfmdf = data2.pivot_table(index='userID', values=['orderAmount','orderTime','orders'],
aggfunc={'orderAmount':'sum','orderTime':'max','orders':'sum'})
#处理数据透视表中的R
rfmdf['R'] = (rfmdf['orderTime'].max() - rfmdf['orderTime']).dt.days
#处理数据透视表中的F与M
rfmdf.rename(columns={'orderAmount':'M', 'orders':'F'}, inplace=True)
rfmdf.sample(5)

设置标签,并进行分组聚合
def rfm_func(x):
level = x.apply(lambda x : '1' if x >=0 else '0')
label = level['R']+level['F']+level['M']
d = {
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户'
}
result = d[label]
return result
#根据模型打标签
rfmdf['label'] = rfmdf[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func, axis=1)
# rfmdf.sample(5)
#分组聚合
rfmdf_label = rfmdf.groupby('label').count()
rfmdf_label

绘制相关条形图
plt.figure(figsize=(15,10))
plt.title('用户分类标签', fontsize=18)
plt.bar(rfmdf['label'].value_counts().index, rfmdf['label'].value_counts().values)
plt.show()
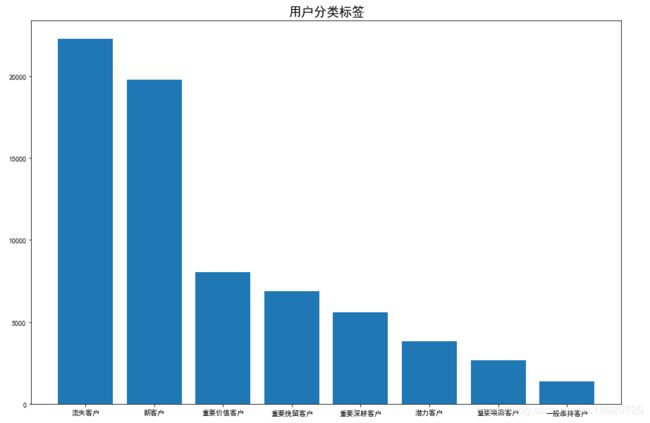
由上图可以看出,流失客户量过大,并且重要客户、比例过小,说明目前平台情况并不太乐观,下一阶段,重点目标为如何维持现有客户,降低客户流失。