ElasticSearch5.X按时间统计-聚合(五)
按时间统计编辑
(测试数据:http://blog.csdn.net/wwd0501/article/details/78501842)如果搜索是在 Elasticsearch 中使用频率最高的,那么构建按时间统计的 date_histogram 紧随其后。 为什么你会想用 date_histogram 呢?
假设你的数据带时间戳。 无论是什么数据(Apache 事件日志、股票买卖交易时间、棒球运动时间)只要带有时间戳都可以进行 date_histogram 分析。当你的数据有时间戳,你总是想在 时间 维度上构建指标分析:
- 今年每月销售多少台汽车?
- 这只股票最近 12 小时的价格是多少?
- 我们网站上周每小时的平均响应延迟时间是多少?
虽然通常的 histogram 都是条形图,但 date_histogram 倾向于转换成线状图以展示时间序列。 许多公司用 Elasticsearch _仅仅_ 只是为了分析时间序列数据。 date_histogram 分析是它们最基本的需要。
date_histogram 与 通常的 histogram 类似。 但不是在代表数值范围的数值字段上构建 buckets,而是在时间范围上构建 buckets。 因此每一个 bucket 都被定义成一个特定的日期大小 (比如, 1个月 或 2.5 天)。
我们的第一个例子将构建一个简单的折线图来回答如下问题: 每月销售多少台汽车?
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "month",
"format": "yyyy-MM-dd"
}
}
}
}
|
|
时间间隔要求是日历术语 (如每个 bucket 1 个月)。 |
|
|
我们提供日期格式以便 buckets 的键值便于阅读。 |
我们的查询只有一个聚合,每月构建一个 bucket。这样我们可以得到每个月销售的汽车数量。 另外还提供了一个额外的 format 参数以便 buckets 有 "好看的" 键值。 然而在内部,日期仍然是被简单表示成数值。这可能会使得 UI 设计者抱怨,因此可以提供常用的日期格式进行格式化以更方便阅读。
结果既符合预期又有一点出人意料(看看你是否能找到意外之处):
{
...
"aggregations": {
"sales": {
"buckets": [
{
"key_as_string": "2014-01-01",
"key": 1388534400000,
"doc_count": 1
},
{
"key_as_string": "2014-02-01",
"key": 1391212800000,
"doc_count": 1
},
{
"key_as_string": "2014-05-01",
"key": 1398902400000,
"doc_count": 1
},
{
"key_as_string": "2014-07-01",
"key": 1404172800000,
"doc_count": 1
},
{
"key_as_string": "2014-08-01",
"key": 1406851200000,
"doc_count": 1
},
{
"key_as_string": "2014-10-01",
"key": 1412121600000,
"doc_count": 1
},
{
"key_as_string": "2014-11-01",
"key": 1414800000000,
"doc_count": 2
}
]
...
}
聚合结果已经完全展示了。正如你所见,我们有代表月份的 buckets,每个月的文档数目,以及美化后的 key_as_string 。
返回空 Buckets编辑
注意到结果末尾处的奇怪之处了吗?
是的,结果没错。 我们的结果少了一些月份! date_histogram (和 histogram 一样)默认只会返回文档数目非零的 buckets。
这意味着你的 histogram 总是返回最少结果。通常,你并不想要这样。对于很多应用,你可能想直接把结果导入到图形库中,而不想做任何后期加工。
事实上,即使 buckets 中没有文档我们也想返回。可以通过设置两个额外参数来实现这种效果:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
}
}
}
}
|
|
这个参数强制返回空 buckets。 |
|
|
这个参数强制返回整年。 |
这两个参数会强制返回一年中所有月份的结果,而不考虑结果中的文档数目。 min_doc_count 非常容易理解:它强制返回所有 buckets,即使 buckets 可能为空。
extended_bounds 参数需要一点解释。 min_doc_count 参数强制返回空 buckets,但是 Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets。
因此如果你的数据只落在了 4 月和 7 月之间,那么你只能得到这些月份的 buckets(可能为空也可能不为空)。因此为了得到全年数据,我们需要告诉 Elasticsearch 我们想要全部 buckets, 即便那些 buckets 可能落在最小日期 之前 或 最大日期 之后 。
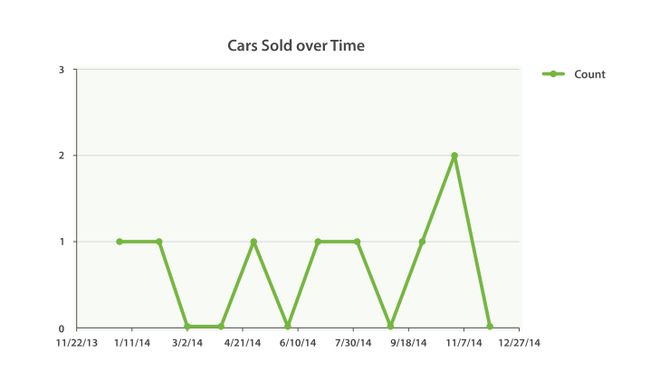
extended_bounds 参数正是如此。一旦你加上了这两个设置,你可以把得到的结果轻易地直接插入到你的图形库中,从而得到类似 图 37 “汽车销售时间图” 的图表。
图 37. 汽车销售时间图
/**
* Description:按时间统计聚合,用于各种图表数据的聚合
* 按时间统计:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_looking_at_time.html
* 例: 每月销售多少台汽车
*
* @author wangweidong
* CreateTime: 2017年11月10日 上午10:17:54
*
* 返回空buckets处理:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_returning_empty_buckets.html
*
* extended_bounds 参数需要一点解释。 min_doc_count 参数强制返回空 buckets,但是 Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets。
因此如果你的数据只落在了 4 月和 7 月之间,那么你只能得到这些月份的 buckets(可能为空也可能不为空)。
因此为了得到全年数据,我们需要告诉 Elasticsearch 我们想要全部 buckets, 即便那些 buckets 可能落在最小日期 之前 或 最大日期 之后 。
*/
@Test
public void dataHistogramAggregation() {
try {
String index = "cars";
String type = "transactions";
SearchRequestBuilder searchRequestBuilder = client.prepareSearch(index).setTypes(type);
DateHistogramAggregationBuilder field = AggregationBuilders.dateHistogram("sales").field("sold");
field.dateHistogramInterval(DateHistogramInterval.MONTH);
// field.dateHistogramInterval(DateHistogramInterval.days(10))
field.format("yyyy-MM");
field.minDocCount(0);//强制返回空 buckets,既空的月份也返回
field.extendedBounds(new ExtendedBounds("2014-01", "2014-12"));// Elasticsearch 默认只返回你的数据中最小值和最大值之间的 buckets
searchRequestBuilder.addAggregation(field);
searchRequestBuilder.setSize(0);
SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
System.out.println(searchResponse.toString());
Histogram histogram = searchResponse.getAggregations().get("sales");
for (Histogram.Bucket entry : histogram.getBuckets()) {
// DateTime key = (DateTime) entry.getKey();
String keyAsString = entry.getKeyAsString();
Long count = entry.getDocCount(); // Doc count
System.out.println(keyAsString + ",销售" + count + "辆");
}
} catch (Exception e) {
e.printStackTrace();
}
} https://www.elastic.co/guide/cn/elasticsearch/guide/current/_returning_empty_buckets.html