lhy机器学习(一):ML Lecture 4 Classification 概率生成模型(Probabilistic Generative Model)
生成模型(Generative Model)
为了求给的x是C1类的概率,先看如下公式

以Class1(简称C1)为water水系宝可梦,Class2(简称C2)为Normal一般系宝可梦为例,我们现在要求取出一个x海龟宝可梦,他是水系宝可梦的概率是多少
红框的项很好算,就是如下

此时P(C1)和P(C2)已经很easy算出来,根据上面的P(C1|x)公式,为了求x(海龟)属于C1(water)的概率,那就必须求从C1(water)中取出x是海龟的概率,也就是P(x|C1)(注意红色标注的两个是不一样的哦!)
而x(海龟)并不在我们的C1(Water)数据中,那要怎么求从C1(water)中取出x是海龟的概率呢?
没错,如下图所示,就是根据整体的water系宝可梦分布建立密度函数(红圈),有了这个红圈密度函数,我们就可以将海龟的两个特征代入求得从water取出海龟的概率P(x|C1),即P(海龟|water),因此我们需要假设一个water系宝可梦服从什么样的分布,这里我们就假设water系宝可梦服从多元高斯分布(因为有多个特征)
然后利用最大似然估计求解使得L(μ,∑)最大的μ和∑,也就是说,我们在空间上有无限多个概率密度函数fμ,∑(x),穷举所有μ,∑,存在一对μ和∑,使得我们这部分water系样本的每个点在某个概率密度函数![]() 中同时出现的概率最大,这就是极大似然估计,就是为了最拟合训练样本的概率密度函数(这里用的是多元高斯)
中同时出现的概率最大,这就是极大似然估计,就是为了最拟合训练样本的概率密度函数(这里用的是多元高斯)
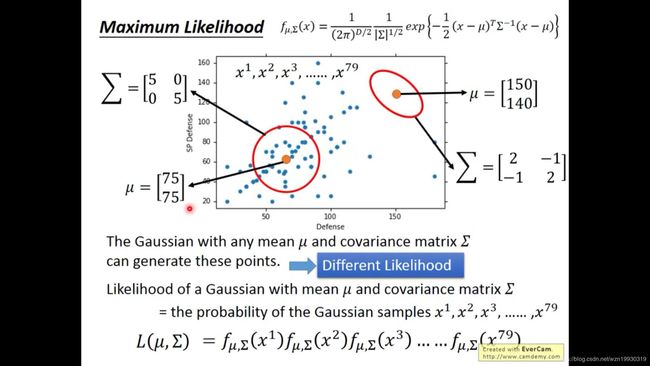
那么根据经验和瞎几把猜(其实是可以数学推导求出来的),使L(μ,∑)最大的μ*就是训练样本的均值,μ1就是water系的宝可梦样本在特征1(就是上图的Defense)的均值,μ1就是water系样本在特征2(就是上图的SP Defense)的均值。
![]()
而把μ代进去就求出来∑*

对于水系Water宝可梦和一般系宝可梦,他们利用似然估计解除的多元高斯分布的μ和∑就是下面两个
然后同理,利用一般系Noemal的宝可梦,即C2的样本分布建立概率密度函数求P(x|C2)
这样一来P(x|C1)、P(x|C2)、P(C1)、P(C2)都算出来了,那根据公式,P(C1|x)是不是也就算出来了呢?
对于水系宝可梦和一般系宝可梦,他们利用似然估计解除的多元高斯分布的μ和∑就是下面两个
于是知道water水系宝可梦的多元高斯分布以后,就可以求出来x的概率,那设置一个阈值,>0.5就是水系宝可梦。

于是知道water水系宝可梦的多元高斯分布以后,就可以求出来x的概率,那设置一个阈值,>0.5就是水系宝可梦。

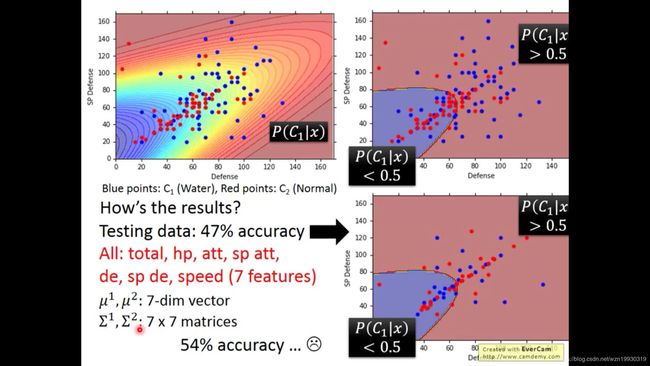
这里我们求出来μ1,∑1,μ2,∑2,P(C1|x)就是关于这四个参数的一个式子,但是我们知道,如果参数过多的话,有可能发生过拟合现象哦~,我们这里只有两个特征,特别是特征非常多的时候,我们就有非常多的μ1,∑1,μ2,∑2,μ3,∑3......因此其实通常我们都让他们共用同一个∑

之前我们的最大似然估计是通过两个式子分别求water和normal系的宝可梦的μ1,∑1,μ2,∑2,于是现在我们的最大似然估计求概率密度就变了成了先求μ1,μ2,这两个很好求,上文也说了解出来这两个值就是样本均值,然后求共用的∑就变成了如下一个式子

共用∑之前的决策边界是左边的图,共用∑之后的决策边界是右边的图,那么我们发现在共用同一个∑后,决策边界变成了一条线性的,并且其准确率提升到了73%


如果某个特征是1或0,而不是连续分布的值,是离散分布,那我们如果假设他是高斯分布就有点自欺欺人了哦~毕竟他只有两个值0和1,离散的变量我们就可以假设他服从伯努利分布,如果所有的特征都是独立分布的,那就可以用朴素贝叶斯:

我们可以看到贝叶斯公式可以化简为如下形式,这个是不是很眼熟?对,就是sigmod函数!


一大波数学推导来袭!数学公式警告!!!!
这里我们就发现一个有趣的现象,当共用∑以后,我们试着把z推导出来




你没有看错!P(C1|x)的最终结果就是逻辑回归LR公式!
小知识:为什么叫生成模型(Generative Model)呢?
下面是我根据李宏毅老师的描述总结的我的理解:
因为x,也就是海龟,本来是不存在于样本中的,而我们利用样本建立概率密度函数(红圈的地方),进而估计海龟在water中的位置和概率,其实就等于假设海龟是服从我们假设的概率密度分布的,这种有假设分布前提的模型就叫生成模型(Generative Model)。