1.简述人工智能、机器学习和深度学习三者的联系与区别。
| 人工智能 | 机器学习 | 深度学习 | |
| 区别 | 人工智能是目的,是结果 | 机器学习是一种方法、是工具 | 深度学习是一种方法、是工具 |
| 联系 | 1、机器学习是一种实现人工智能的方法 2、深度学习则是一种实现机器学习的技术,适合处理大数据 3、深度学习使得机器学习能够实现众多应用并拓展人工智能的领域范畴。 |
||
2. 全连接神经网络与卷积神经网络的联系与区别。
| 全连接神经网络 | 卷积神经网络 | |
| 区别 | 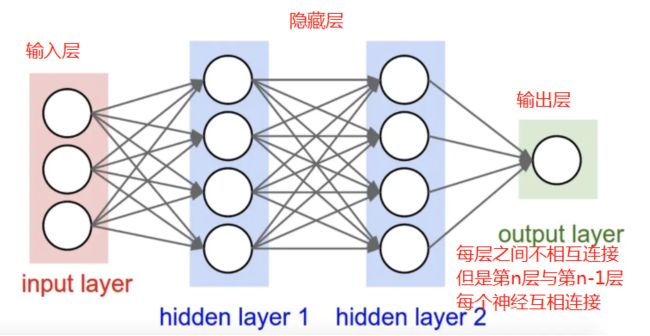 全连接神经网络是通过一层一层的节点组织起来的。在全连接神经网络中,每相邻两层之间的节点都有边相连,于是会将每一层的全连接层中的节点组织成一列,这样方便显示连接结构。 功能上:不好处理识别图片 |
卷积神经网络也是通过一层一层的节点组织起来的。卷积神经网络中的每一个节点就是一个神经元。而对于卷积神经网络,相邻两层之间只有部分节点相连,为了展示每一层神经元的维度,一般会将每一层卷积层的节点组织成一个三维矩阵。 功能上:适合处理图片识别 |
| 联系 | 两种神经网络的结构相似,输入输入以及训练流程也基本一样,全连接神经网络的损失函数以及参数的优化过程也都适用于卷积神经网络。 |
|

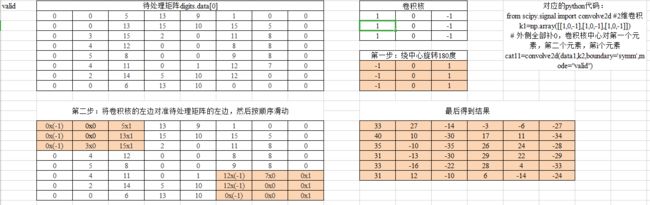
3.理解卷积计算。
以digit0为例,进行手工演算。
from sklearn.datasets import load_digits #小数据集8*8
digits = load_digits()
| 0 | 0 | 5 | 13 | 9 | 1 | 0 | 0 |
| 0 | 0 | 13 | 15 | 10 | 15 | 5 | 0 |
| 0 | 3 | 15 | 2 | 0 | 11 | 8 | 0 |
| 0 | 4 | 12 | 0 | 0 | 8 | 8 | 0 |
| 0 | 5 | 8 | 0 | 0 | 9 | 8 | 0 |
| 0 | 4 | 11 | 0 | 1 | 12 | 7 | 0 |
| 0 | 2 | 14 | 5 | 10 | 12 | 0 | 0 |
| 0 | 0 | 6 | 13 | 10 | 0 | 0 | 0 |
valid类型的卷积计算

补0后——same类型的卷积计算
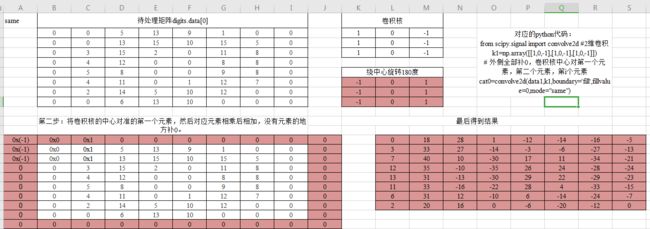

补充一点:http://imgtec.eetrend.com/d6-imgtec/blog/2018-11/19122.html
相关运算是将卷积核在图像上滑动,对应位置相乘求和;卷积运算则先将卷积核旋转180度(行列均对称翻转),然后使用旋转后的滤波器进行相关运算。两者在计算方式上可以等价,有时为了简化,虽然名义上说是“卷积”,但实际实现时是相关运算。
所以有时候直接用卷积核在图像上进行滑动计算,得到的结果会与python代码运行的结果正负相反。
4.理解卷积如何提取图像特征。
读取一个图像;
以下矩阵为卷积核进行卷积操作;
显示卷积之后的图像,观察提取到什么特征。
| 1 | 0 | -1 |
| 1 | 0 | -1 |
| 1 | 0 | -1 |
| 1 | 1 | 1 |
| 0 | 0 | 0 |
| -1 | -1 | -1 |
| -1 | -1 | -1 |
| -1 | 8 | -1 |
| -1 | -1 | -1 |
卷积API
scipy.signal.convolve2d
tf.keras.layers.Conv2D
一个卷积核是提取一个特征,多个卷积核提取多个特征
卷积模式有三种:
①full
②same(用得最多)--------填充0或者边缘数据,做完卷积后和原矩阵规模一样
③valid------不填充,做完卷积后会比原矩阵的规模小
1 from PIL import Image
2 import matplotlib.pyplot as plt
3 import numpy as np
4 from scipy.signal import convolve2d #2维卷积
5 I=Image.open("./机器学习/William.jpg")
6 L=I.convert('L')#彩色图形转为灰度图
7 plt.imshow(L,cmap='gray')#灰度图展示
8 plt.show()
9 william=np.array(I)#转为数组
10 williamg=np.array(L)#转为数组,包括像素等等
11 k1=np.array([[1,0,-1],[1,0,-1],[1,0,-1]]) #垂直边缘检测
12 k2=np.array([[1,1,1],[0,0,0],[-1,-1,-1]]) #水平边缘
13 k3=np.array([[-1,-1,-1],[-1,8,-1],[-1,-1,-1]])
14 william1=convolve2d(williamg,k1,boundary='symm',mode="same")
15 william2=convolve2d(williamg,k2,boundary='symm',mode="same")
16 william3=convolve2d(williamg,k3,boundary='symm',mode="same")
17 plt.figure(figsize=(8,8)) #自定义一个画布
18 plt.subplot(221) #是2x2的格子上第一块图形原图
19 plt.imshow(I)
20 plt.subplot(222) #是2x2的格子上第2块图形垂直边缘
21 plt.imshow(william1)
22 plt.subplot(223) #是2x2的格子上第3块图形水平边缘
23 plt.imshow(william2)
24 plt.subplot(224) #是2x2的格子上第4块图形
25 plt.imshow(william3)
运行结果图:
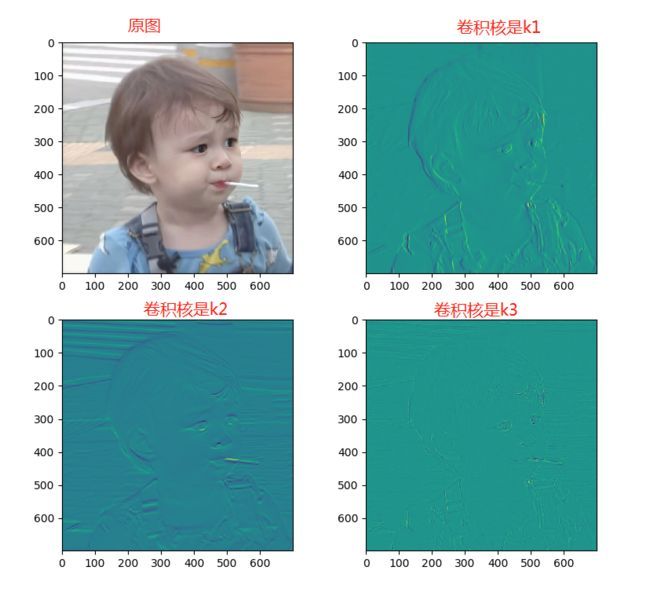
当卷积核为k1=np.array([[1,0,-1],[1,0,-1],[1,0,-1]])时,可以发现垂直部分更加明显,特征更加明显清楚;
当卷积核为k2=np.array([[1,1,1],[0,0,0],[-1,-1,-1]])时,可以发现水平边缘部分更加明显,特征更加明显清楚;
当卷积核为k3=np.array([[-1,-1,-1],[-1,8,-1],[-1,-1,-1]])是时,中间部分的边缘特征更加明显。
5. 安装Tensorflow,keras
参考:https://blog.csdn.net/u011119817/article/details/88309256
如果想在pycharm里面使用:安装好TensorFlow后,新建一个项目,将其interpreter改成anaconda的。


6. 设计手写数字识别模型结构,注意数据维度的变化。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2D
model = tf.keras.Sequential()
model.add(Conv2D(…))
model.add(MaxPool2D(…))
...
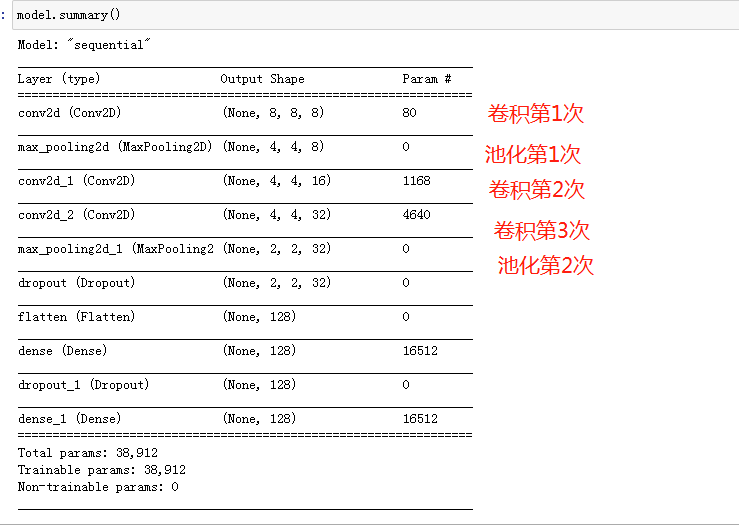
#可以上传手动演算的每层数据结构的变化过程。model.summary()
5个组成部分:
输入层(原数据)
卷积层(提取特征映射,对应一个特定的图案,即卷积层需要的数据只是对应上一层的部分数据)
激活函数层(引入非线性)
池化层(把维度变小)
全连接层(所有特征拉成一条,做分类)
第一步:手写数字的图片大小(8,8)
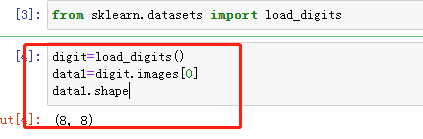
第二步:可以做x个3*3的卷积核,提取出x个特征,得到x个8*8的卷积层
提取多少个特征是可以自己定的,卷积核大小也可以自己定,3*3也可以,5*5也可以,三种模式(full,same,valid)也是可以自己选择,然后能够得到结果就是x个y*y的卷积层
第三步:可以做池化,这样原来是8*8的卷积层会变成4*4的卷积层,规格缩小一半,得到x个4*4的卷积层
第四步:可以继续做卷积,或者做池化,自己设计

参考:
https://www.jianshu.com/p/afe485aa08ce
https://blog.csdn.net/junjun150013652/article/details/82217571