mysql 表锁 行锁
文章目录
- mysql 锁
- 系列文章
- 事务
- 表锁、行锁
- 锁类型
- 共享锁(S)
- 排它锁(X)
- 意向共享锁(IS)
- 意向排它锁(IX)
- 自增锁(AUTO-INC Locks)
- 数据准备
- 临键锁(Next-key Locks)
- 间隙锁(Gap Locks)
- 记录锁(Record Locks)
- 死锁
- 造成死锁
- 如何避免死锁
mysql 锁
系列文章
- mysql 性能优化 | 第一篇 mysql B+Tree
- mysql 性能优化 | 第二篇 MySql Myisam和innodb对比 索引优化建议
- mysql 性能优化 | 第三篇 mysql存储引擎
- mysql 性能优化 | 第四篇 mysql数据库的隔离级别
- mysql 性能优化 | 第五篇 mysql 表锁 行锁
- mysql 性能优化 | 第六篇 mysql MVCC Undo Redo
- mysql 性能优化 | 第七篇 mysql 执行路径 执行计划 慢查询
- mysql 性能优化 | 第八篇 mysql 配置优化
事务
事务是数据库操作的
最小工作单元,是作为单个逻辑工作单元执行的一系列操作;事务是一组不可再分割的操作集合(工作逻辑单元)
开启事务的方式
begin/start transaction;
commit/rollback;
set session autocommit =on/off;
事务的隔离级别:
(本文的重点是锁,这里就不赘述了,不了解的可以看之前写的这篇文章)
mysql数据库的隔离级别
表锁、行锁
锁是用于管理不同事务对共享资源的并发访问
表锁和行锁的区别
| 名称 | 比较 |
|---|---|
| 锁的粒度 | 表锁>行锁 |
| 加锁效率 | 表锁>行锁 |
| 冲突概率 | 表锁>行锁 |
| 并发性能 | 表锁<行锁 |
InnoDB支持行锁和表锁
锁类型
| 锁名称 | 锁类型 | 英文 |
|---|---|---|
| 共享锁 | 行锁 | Shared Locks |
| 排它锁 | 行锁 | Exclusive Locks |
| 意向锁共享锁 | 表锁 | Intention Shared Locks |
| 意向锁排它锁 | 表锁 | Intention Exclusive Locks |
| 自增锁 | 特殊表锁 | AUTO-INC Locks |
| 记录锁 | 行锁的算法 | Record Locks |
| 间隙锁 | 行锁的算法 | Gap Locks |
| 临键锁 | 行锁的算法 | Next-key Locks |
共享锁(S)
共享锁又称为读锁,简称S锁,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改
加锁释放锁的方式
select * from users where id = 1 LOCK IN SHARE MODE;
commit/rollback;
测试
- session窗口一
#关闭自动提交
set session autocommit =off;
select * from eval_leaders where id=100264 LOCK IN SHARE MODE;
#先不提交
commit;
- session窗口二
select * from eval_leaders where id=100264;
- session窗口三
update eval_leaders t set t.leader_name='xwf' where id=100264
执行步骤:
- 执行session窗口一中的sql语句,commit先不执行
- 执行session窗口二种的查询语句,正常执行
- 再执行session窗口三,会发现一直是执行状态,被阻塞了
- 最后执行session窗口一中的commit,session窗口二中的update操作才会执行
如果将id换成100265,执行的话
update eval_leaders t set t.leader_name='tom' where id=100265
分两种情况
- 如果
id为索引,那么可以执行, - 如果不是索引,不能执行
select语句的执行计划,type为const,key为primary,说明id为主键索引
explain select t.* from eval_leaders t where t.id=100264
![]()
InnoDB的行锁是通过给索引上的索引项加锁来实现的。
只有通过索引条件进行数据检索,InnoDB才使用行级锁,否则,InnoDB
将使用表锁(锁住索引的所有记录)
排它锁(X)
排它锁又称为写锁,简称X锁,排它锁不能与其他锁并存,如果一个事务获得了一个数据行的排它锁,其他事务就不能再获取该数据行的锁(共享锁、排它锁),只有该获取了排它锁的事务是可以对数据行进行读取和修改(其他的事务要读取数据可以来自于快照)
加锁释放锁的方式
delete/update/insert 默认加上X锁;
select * from table_name where ... for udpate;
commit/rollback;
先执行以下sql但是不commit或者rollback
#关闭自动提交
set session autocommit =off;
update eval_leaders t set t.leader_name='tom2' where id=100265
commit;
rollback;
对这条记录进行update、select+共享锁和for update三种方式都不能操作,被阻塞,只有上面执行commit或者rollback之后,才能对这条记录进行操作
update eval_leaders t set t.leader_name='tom' where id=100265;
select * from eval_leaders t where id=100265 LOCK IN SHARE MODE;
select * from eval_leaders t where id=100265 for update;
和共享锁一样,锁也需要建立在索引上
意向共享锁(IS)
表示事务准备给数据行加入共享锁,即一个数据行加共享锁前必须先取得该表的IS锁,意向共享锁之间是可以互相兼容的
意向排它锁(IX)
表示事务准备给数据行加入排它锁,即一个数据行加共享锁钱必须先取得该表的IX锁,意向排它锁之间是可以互相兼容的
意向锁(IS/IX)是InnoDB数据操作之前mysql自动加的,不需要用户干预
存在的意义?
当事务进行锁表之前,可以先判断意向锁是否存在,存在就表示该表已经有锁存在,可快速返回该表不能启用表锁
自增锁(AUTO-INC Locks)
针对自增列自增长的一个特殊的表级别锁
show variables like 'innodb_autoinc_lock_mode';
默认取值1,代表连续,事务未提交ID永久丢失
目前表中最大100291

#自增锁
set session autocommit =off;
insert into eval_leaders(leader_code,leader_name,leadergroup_id)values(1,1,1)
commit;
rollback;
insert之后执行rollback操作;连续执行两次
如果存在自增锁,两个自增id丢失,那么下一条数据的id应该为100294
第三次执行insert后 commit,如果如下

数据准备
注:下面的三种锁可以当成是
行锁的算法
为下面三种锁的测试做准备
user表,插入四条记录
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES ('1', '谢**');
INSERT INTO `user` VALUES ('4', '李**');
INSERT INTO `user` VALUES ('7', '张**');
INSERT INTO `user` VALUES ('10', '王**');
临键锁(Next-key Locks)
锁住记录+区间(左开右闭)
当sql执行按照索引进行数据的检索时,查询条件为范围查找(between and、<、>等),并有数据命中,这时sql语句加上锁即为Next-key Locks,锁住索引的记录+区间
-
Next-key Locks是InnoDB默认的行锁算法 -
锁住的区间为
当前区间+下一个区间 -
Next-key Locks = Gap Lock + Record Lock
为什么这么设计?
可以解决幻读的问题
select * from user where id > 5 and id < 9 for update
第一次读取的记录为7,这个区间被锁住之后,无法在插入数据,保证事务第二读取的值依然是7

测试
窗口执行事务一
begin;
select * from user where id >5 and id <9 for update;
#先不执行
rollback;
新开窗口执行事务二
#无法插入被阻塞
insert into user(id,name) value (5,5);
insert into user(id,name) value (6,6);
insert into user(id,name) value (10,10);
#可以插入
insert into user(id,name) value (11,11);
插入5,6,10事务被阻塞,插入11时正常执行
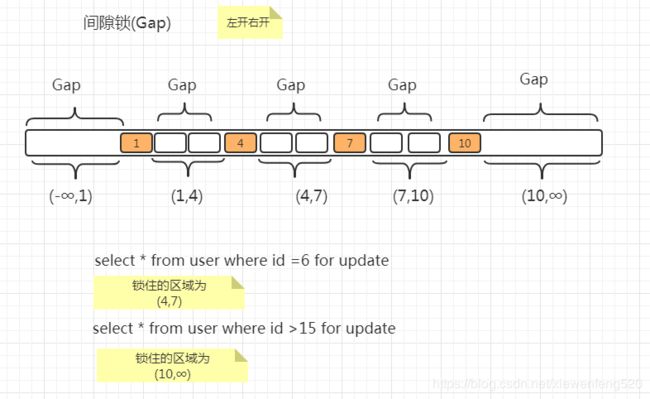
间隙锁(Gap Locks)
锁住数据不存在的区间(左开右开)
当sql执行按照索引进行数据的检索时,查询条件的数据不存在,这时sql语句加上锁即为Gap Locks,锁住索引不存在的区间
-
在RR(可重复读Repeatable Read)的隔离级别中存在,所以在InnoDB中,间隙锁可以解决幻读的问题
-
当记录不存在,临键锁退化成Gap锁
测试
窗口执行事务一
begin;
select * from user where id = 6 for update;
select * from user where id > 15 for update;
#先不执行
rollback;
新开窗口执行事务二
#无法插入被阻塞
insert into user(id,name) value (5,5);
insert into user(id,name) value (6,6);
insert into user(id,name) value (20,20);
#可以插入
insert into user(id,name) value (8,8);
- 执行
id = 6的sql语句;并执行插入5,6事务被阻塞,插入8时正常执行 - 执行
id > 15的sql语句;并执行插入20事务被阻塞,插入8时正常执行(前提是要删除之前的8,避免主键冲突)
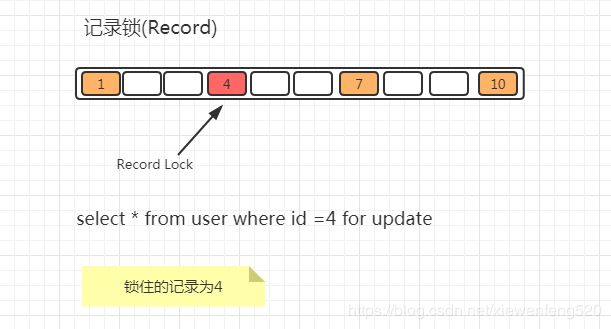
记录锁(Record Locks)
锁住具体的索引项
当sql执行按照唯一性(Primary key、Unique key)索引进行数据的检索时,查询条件等值匹配且查询的数据是存在,这时SQL语句加上的锁即为记录锁Record locks,锁住具体的索引项
条件为精准匹配,唯一性(Primary key、Unique key)索引,退化为记录锁
测试
窗口执行事务一
begin;
select * from user where id = 4 for update;
#先不执行
rollback;
新开窗口执行事务二
#无法执行
update user set name = '我**' where id = 4;
#正常执行
update user set name = '我**' where id = 5;
执行update id =4 操作被阻塞,执行update id =5时正常执行
死锁
造成死锁
-
多个并发事务(2个或以上)
-
每个事务都持有锁(或者是已经在等待锁)
-
每个事务都需要再继续持有锁
-
事务之间产生加锁的循环等待,形成死锁
如何避免死锁
- 类似的业务逻辑以固定的顺序访问表和行
- 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁的概率
- 降低隔离级别,如果业务允许,将隔离级别调低也是较好的选择
- 加表添加合理的索引。可以看到如果不走索引将会为表的每一行记录加上锁(或者说是表锁)