yolo模型(一)ubuntu16.04下 yolo使用自己的数据集训练模型
如果没有安装好Ubuntu和cuda环境,请移步到我的博客https://blog.csdn.net/xue_csdn/article/details/90898400,有详细的安装过程
1、下载darknet框架
参考官网https://pjreddie.com/darknet/yolo/
git clone https://github.com/pjreddie/darknet
cd darknet
make
2、官网下载预训练权重
wget https://pjreddie.com/media/files/yolo3.weights
该权重只是作为当前测试用
3、测试
(1)修改darknet目录下Makefile文件,将GPU、CUDNN、OPENCV的值都改为1(需提前安装显卡驱动、cuda、cudnn、opencv)
(2)修改要使用的cfg文件,以yolov3.cfg为例,将testing下的batch和subdivision取消注释,将training下的batch和subdivision加注释
用图片测试:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
用视频测试:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights 用相机测试:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
一般情况下不需要加sudo就可以执行,但如果出现权限问题,加sudo有效,说明你的cuda安装有问题,但是不会对结果产生影响。
4、将自己的数据集放在指定文件夹下
部分文件夹需要自己新建
图片统一编号,放在文件夹JPEGImages文件夹中,(我是用ACDSee软件实现统一编码)
5、图片制作xml文件
用labelImg,下载地址https://github.com/tzutalin/labelImg
我用的是python2
Python2安装labelImg步骤:
sudo apt-get install pyqt4-dev-tools
sudo pip install lxml
make qt4py2
python labelImg.py
这里顺便附上python3的步骤:
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3
python3 labelImg.py
打开之后,改变xml文件存储地址为上图中的Annotations文件夹中。
6、Imagesets文件夹下新建Main文件夹,用来存放训练图片的名字的文档train.txt及测试图片的名字的文档test.txt。这部分我是用matlab代码实现的,网上应该可以找到python代码。(python代码和matlab代码参考我的博客PASCAL VOC数据集 生成train.txt、test.txt、tainval.txt、val.txt)
7、将xml文件转换为txt文件
在darknet/scripts目录下找到voc_label.py文件,
将sets中的2012相关的去掉,classes改为自己数据集的类别,os.system去掉2012相关,把相应的文件路径改成自己的
运行python voc_label.py,可以看到txt文件出现在labels文件夹下
同时在scripts文件夹下边生成三个txt文件,分别是2007_train.txt、2007_test.txt(一般不会用到)、2007_val.txt
8、修改voc.nama
位于darknet/data文件夹下,这是目标的标签,清空,添加自己的标签
9、修改voc.data
位于darknet/cfg文件夹下,分别将train、val的路径改为scripts文件夹下边的2007_train.txt、2007_val.txt的路径
10、修改模型(cfg)中的参数
(1)如果使用yolov2-voc.cfg,将Training后边的注释去掉,batch=64,修改subdivsion=64(如果该值太小容易使内存溢出),
(2)修改[region]层,将classes的值改为自己标签的个数,
(3)[region]层上边最后一个[convolutional]层中,修改filters的数值,计算公式:
filters=num*(classes+coords+1),classes和coords的值都是[region]层中的值
11、训练模型
下载预训练模型
wget https://pjreddie.com/media/files/darknet19_448.conv.23
(yolov3需要下载darknet53.conv.74)
然后执行
./darknet detector train cfg/voc.data cfg/yolov2-voc.cfg darknet19_448.conv.23
就可以在darknet/backup文件夹下看到有不同精度的模型(权重)出现。按照每100步、每1000步、每10000步产生。
如果训练中断,但是后面想要接着前边的模型继续训练,(如训练到5100步时中断)只需要把“darknet19_448.conv.23”换成“yolov2-voc_5000.weights”,即可继续训练。
根据需要选择模型测试图片或视频。
12、测试
测试方法与步骤3类似,需将cfg文件名改为yolov2-voc.cfg,yolov2-voc.cfg中的training下的两个值加注释,testing下的两个值取消注释。如:用摄像头测试:
./darknet detector demo cfg/voc.data cfg/yolov2-voc.cfg yolov2-voc_50000.weights
50000是训练的步数。
如果想在bbox上显示准确率(准确来说是置信度),执行:
- 打开derknet/src文件中找到image.c文件
- 找到draw_detections函数,加入红色框中的内容,
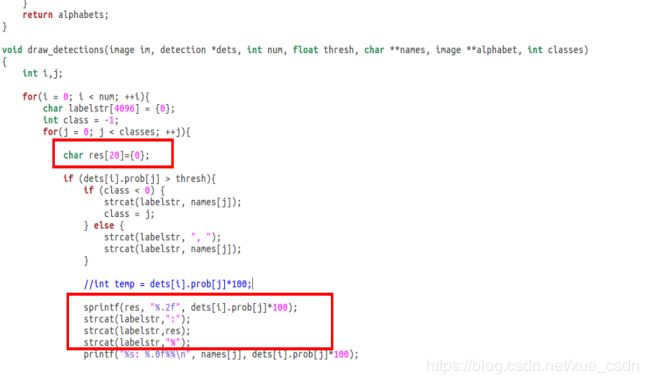
- 最后重新编译darknet:
make clean
make