
0x00 前言
看到有坛友发微信、QQ的分析文章,我也来凑凑热闹,我分析的是QQ。
本文做法可能不同于其他文章,区别主要在于技术上和目的上。
技术上的不同在于我这里是对将QQ代码逆向工程为C++,协议还原只是一部分。
目的上的不同在于我想打造一款挖掘QQ漏洞的自动化工具。
这文章不好写,原本贴了很多代码,后来都删掉了,这一篇不应当是技术分析文章,而应当是交代上下文,技术分析下一篇再来。
目前是基础功能雏形,只有QQ原生功能,之所以现在就写文章,是因为曾经有太多东西浪费了,不想再次发生。
5年前公司要做手机管理软件,还原了iTunes一些功能(对标xy苹果助手功能),后来老板觉得这种软件不赚钱停了,至今源代码在硬盘的哪个角落吃灰都记不起了.....
2年前公司要做Android安全防御软件,便还原了当时使用率最高的某壳以实现自动脱壳便于服务器自动化分析,半年后公司倒闭,源代码又吃灰去了...
印象里DexHunter也是那个时候发布的,当时考虑到壳早晚会出现抽代码的保护措施,想来想去最终没采用,仍然去搞我的模拟器版“火眼”去了,第一个版本出来后一个月,公司倒闭,吃灰....
一起吃灰的还有.....精力最好的年纪如此度过,真叫一个酸爽。
我主业是开发,安全实力很弱鸡,这文章可能最终就是一篇垃圾,因为有太多老司机在研究和保护,干不过他们啊....
独乐乐不如众乐乐,目的仅为技术交流讨论,还请大家板砖轻拍,谢谢。
0x01 菜刀小试成果
此处为占位。有了结果我便来更新。
工作实在太忙了,加班加的要炸了!!! 漏洞详情一个字没写呢....
如果报的风险被TSRC认同了,那说明QQFuzz多少还有点用。
如果没被认同,那也无关紧要,至多新开一贴总结下知识欠缺之处,然后就结束了。
毕竟我不是安全从业人员,没有太多时间去挖高危。(尽管以我目前对QQ的代码的理解我认为高危一定是能做到的)
0x02 因缘
“浏览器是用户进入互联网的第一道门槛,更是网络攻防对抗的桥头堡!” --- by 仙果
引用仙果兄的这句话是因为我觉得QQ+微信,在国内可能现在比浏览器更当得起攻防的桥头堡。因为论安装数的话QQ/微信几乎覆盖了全部网民终端,但使用率却比浏览器高很多。
而QQ+微信有独特的几个特点是浏览器所无法比拟的。
一、点对点攻击
目标明确,攻击精准。
二、 主动性强
只要在线,随时发起攻击,即时生效。类似xss那种盲打之后只能傻等的痛苦不用体会。
三、多平台
Windows\Android\macOS\ios. 一点发起攻击,有可能多点响应。
四、基数大,进程常驻
加上主动性,极小成本大撒网,那影响范围....
这几点对于攻击来讲,称其为具备天时地利人和的利器应该不为过。
但利用这利器却很困难,甚至听都没听说过,我想原因可能有以下几点:
1、我的错觉
一直不是圈里人,缺少信息来源,也许地下在流通,只是我不知道。
2、挖掘难度高
一个是有太多的安全研究者盯着,同时有专业的团队防御着,找到一个有效的漏洞并不容易。
一个是没工具。cross_fuzz、nmap、metasploit、AFL.... 每个方向都有一大堆,QQ/微信却没有一个.....
一个是完全黑盒。没源码没文档没标准协议:chromiun/openssl这种是开源的、dom/php/js这种就不说了、word/pdf这种文件协议有很多参考代码....
3、漏洞标准
看了下我所能搜索到的QQ公开漏洞,业务漏洞居多。
说句不厚道的哈,当我看到那些漏洞的时候第一反应是:都是程序员,谁还不写个bug啊,程序员何必难为程序员,哈哈。而这里我们所考虑的是拿下权限的漏洞
4、没有沉淀
CVE 辣么多,覆盖了方方面面,QQ呢?
5、不可抗拒因素
珊瑚虫,大家都懂的。能分析的人肯定不少,敢用来赚钱的都不敢露面吧。
1和5是技术解决不了的,但234可以用技术解决。
解决的方式就是没有工具就把工具写出来,没有协议就把协议逆出来,虽然这个活不好干,但这是第一步,总要有人干才行。
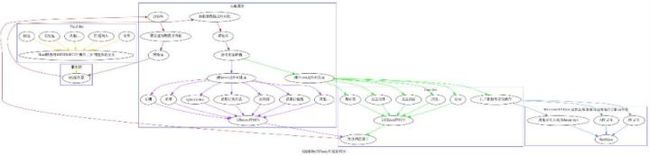
QQFuzzy 就是这个思路。
目标及方式
首先,要明确目标,要不然就像产品提需求,有多少PM自己都不知道自己在想啥瞎提需求?
目标:在用户环境无污染的情况下,通过QQFuzz发现攻击成功的漏洞。
即已将恶意软件安装到机器上的不算,网络劫持不算。类似这种都属于组合技,是在实施攻击时的技巧,不属于漏洞挖掘,这是我的理解,不知道对不对。
按我的理解,QQ漏洞挖掘可分为三部分:
一、浏览器部分,即X5Core
这个首先pass,尽管这个可能会更自由。但我没怎么分析,不了解。
而且这跟浏览器攻防有很大一部分是重合的。
二、应用程序部分,即exe\apk\app
二进制漏洞挖掘
三、业务漏洞
太简单,pass
QQ客户端分为Windows、Android、MacOs、IOS、Linux、WebQQ 6个平台,各个平台又有不同版本。那么怎样Fuzzing呢?
常规做法比如afl、Peach、Honggfuzz之类,不管是基于变异的还是基于生成的fuzzer,对于QQ都不太适合,因为折腾半天终于发现个可疑的地方,然后就会发现没有办法触发!!!
即便可以触发,也效率太低了,Windows的只能Windows用,Android的只能Android用,定位方式完全无法复用,太累了。
于是我就在想,怎样才可以方便的验证漏洞是否存在并验证?是什么阻碍了触发和测试?
答案就是:输入数据和输出数据被QQ拦腰截断了。
输入:完全不能像js一样写啥是啥,能不能到达用户面前都是问题,很多时候到达时已经是另一个样子。也不能像pdf、word一样靠文件输入。
输出:到了用户那里的封包你给改了就会直接丢弃,不丢弃的你不能直接改...
QQ 阻断的方式就2种,一种是客户端的对输入/输出数据过滤检查,一种是server的对传输数据过滤检查。
这就决定了无法用通用工具进行Mock,解决办法也只有2个,一个是Hook,一个是逆向工程。
Hook太累,要处理发送端和接收端,要按功能Hook,各个平台也不同,测试各种消息体得定位,每次发布得从头来一遍,这活又不是搞外挂,能把人搞死。
测试验证也不方便server 的过滤完全无能为力
放弃
逆向工程
协议总不会三天两头儿的改吧?改也不会大换血吧?
测试挖掘那就更简单了,直接写代码就行了,写代码能搞定的事都不叫事儿嘛~~
就是还原的过程比较痛苦,准确的说,还原不痛苦,痛苦的是确保你的代码就是QQ的代码,要不然啥时候有坑你都不知道。
QQ架构总结、QQFuzzy架构
QQ架构流程图
图比较丑陋,凑合看,用Graphviz写的,便于以后迭代,如果有机会的话。
我把QQ的功能分为三个层次:基础层、接口层、业务层。
基础层完全与业务无关,提供基础功能库,比如序列化、网络库、加解密库、通讯协议、WebView等。
接口层是连接业务层与基础层的桥梁,比如消息体、消息路由、与webview的交互规则等。
业务层就是一些基本的功能,比如发送聊天消息。
很棒的设计
从基础部分代码来看,按我的理解,在设计之初制订了一套规则,目的是将业务模块化,并满足业务方无论添加什么新功能都无缝兼容,使业务方专注于业务逻辑开发,基础也不用被业务方拖着走。
这个规则就是业务消息路由,该路由通过业务名字进行分发。
这个设计天生就具备了强解耦属性,至多在某些极端场景需要一点轻耦合。
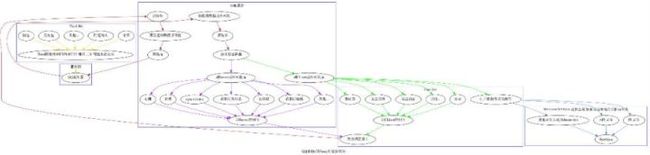
QQFuzzy架构
懒得画图了,但总体与QQ的架构方向一致,略有改变。
实现了一套C++版消息机制,参考了IOS的NotificationCenter,并依赖此消息机制模拟实现QQ消息路由、 异步、业务功能独立、Fuzzy接口实现等。
Fuzzy与QQ自身功能是平行的,目的都是触发代码执行,并分类
比如按平台分类,Android 着重触发反序列化、反射、so crash、Scheme....Windows 着重触发崩溃、X5跳转、XSS...
比如按诱导分,那就着重各种消息、红包、通知、分享....
总结
总结下我在逆向的过程中的拙劣经验,供大家参考。
1、不纠结于点,快速推进
这点我浪费了很多时间,而且时间线太长容易遗忘。
还原过程不必参考网络上的代码或总结,包括我这篇
主观原因是我没找到可参考的,要么是webQQ的,要么是抓包特征码的,要么易语言的(看截图就是特征码)...
客观原因是:纸上得来终觉浅。不亲自上手分析很难理解到底怎么一回事,有问题的话自己还是解决不了。甚至分析的不够彻底都有可能找不到问题原因。
2、、一开始就做好写插件或工具辅助分析的准备
脑子好使的童鞋这个就不用啦,我记忆力越来越差了,也越来越懒了,所以写了一堆的插件来辅助。
我的IDA插件主要功能
注释、Patch
我的注释和补丁都是写在插件中的。当感觉idb有妖的时候,直接删掉,重新跑一下插件接着分析
结构体定义
结构体定义也是用插件自动生成的,同时生成头文件,便于同步更新idb和源码。
偏移计算工具
便于基址变化或版本升级时降低工作量以及其他插件功能使用
流程及架构分析
比如双向调用链
3、类/结构体尽可能搞好
这样可以便于分析,更好地理解完整流程和保证相似度。
否则,那代码会惨不忍睹(想象下没有结构体的1200行的函数是什么样子),说起来全是泪。
4、尽早从架构角度熟悉代码
架构越早熟悉还原越容易,哪里风险值高也越清楚。
我的插件里有个功能就是用来分析架构,分析的结果我存在sqlite数据库里,340M。
为了方便阅读,我还写过自动生成MarkDown,还写过自动用graphviz生成流程图,但都不大好用...
5、组合技一般都挺好用
开发方面掌握Android、IOS开发,逆向方面掌握ARM、smali,会有惊喜哦。
我花费的时间供大家参考:
我总共2次实施完整的还原,协议版本不同,全部为业余时间。
第一次是2年前,总共花费3个多月。
当时没经验,如上面所说代码惨不忍睹,主要是架构乱,一堆的指针问题,自己都不想看。
第二次是不久前,不到3个月。
时间主要花在架构升级和逆向规范化上,协议本身花的时间很少,最多一个月,现在要测试个什么很爽。
不负责任YY一则:
假如QQ全网配置清单:
虚拟主机:20w台
这里指完全用于QQ自身功能的服务器台数,即不包括DB、中间件之类。
带宽:不限
内存:32G.
CPU:E5
全部宕机攻击成本:7w 肉鸡
大家不要认真哈,这里纯属YY,纯属YY,纯属YY,重要的事情说三遍。
只是从代码和观测到的数据来看,我想不出来十分有效的防护办法,因为这里是以小博大,和CC、DDOS不是一码事。
原理我会提交TSRC,可能这压根就不是问题,贫穷和无知限制了我的想象力。
最终总结
整体难度不高,高相似度还原工作量较大,很容易进坑。
客观的说,QQ的整个分析过程学习到很多。
现在最欣赏的就是他的基础架构,这才是实战出来的好架构,推荐大家都去看看。
同时也看到了该架构的推行阻力或使用不到位,如果有当年负责基础这一块的腾讯的兄弟看到这里,不知我说的对不对?
分析过很多大公司的客户端,QQ的代码质量是我觉得最好的之一。
源码在手,不论是盲测还是定向分析,都很自由
分析难度: Android < IOS < Windows
还原难度:Windows < Android < IOS
这次没有可直接用的干货,对不起大家,如果后面有机会,我抛些代码出来。
如何使QQFuzzy有意义我还没想好,我不敢直接放源码,大家有什么建议?
不太会写文章,谢谢观看
引用文档
浏览器漏洞攻防对抗的艺术 https://bbs.pediy.com/thread-211277.htm
本文由看雪论坛 eightmg 原创 转载请注明来自看雪社区
更多干货文章,关注看雪学院公众号 ikanxue~