图像分割之segnet
一、算法介绍
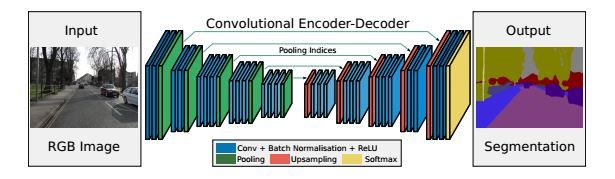
SegNet网络结构如下图所示,Input为输入图片,Output为输出分割的图像,不同颜色代表不同的分类。语义分割的重要性就在于不仅告诉你图片中某个东西是什么,而且告知你他在图片的位置。我们可以看到是一个对称网络,由中间绿色pooling层与红色upsampling层作为分割,左边是卷积提取高维特征,并通过pooling使图片变小,SegNet作者称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与upsampling,通过反卷积使得图像分类后特征得以重现,upsampling使图像变大,SegNet作者称为Decoder,最后通过Softmax,输出不同分类的最大值。
 标题
标题
Convolution
SegNet的Encoder过程中,卷积的作用是提取特征,SegNet使用的卷积为same卷积,即卷积后不改变图片大小;在Decoder过程中,同样使用same卷积,不过卷积的作用是为upsampling变大的图像丰富信息,使得在Pooling过程丢失的信息可以通过学习在Decoder得到。SegNet中的卷积与传统CNN的卷积并没有区别。
Batch Normalisation
批标准化的主要作用在于加快学习速度,用于激活函数前,在SegNet中每个卷积层都会加上一个bn层,bn层后面为ReLU激活层,bn层的作用过程可以归纳为:
(1)训练时:
1.向前传播,bn层对卷积后的特征值(权值)进行标准化,但是输出不变,即bn层只保存输入权值的均值与方差,权值输出回到卷积层时仍然是当初卷积后的权值。
2.向后传播,根据bn层中的均值与方差,结合每个卷积层与ReLU层进行链式求导,求得梯度从而计算出当前的学习速率。
(2)测试时:每个bn层对训练集中的所有数据,求取总体的均值与方差,假设有一测试图像进入bn层,需要统计输入权值的均值与方差,然后根据训练集中整体的无偏估计计算bn层的输出。注意,测试时,bn层已经改变卷积的权值,所以激活层ReLU的输入也被改变。
二、算法实现
2.1 数据准备
数据包括image和label两部分,图像分割是基于像素点的分类,我这里用的label标记工具是labelme,不清楚的可以了解一下其用法,这里就不详细描述了。
 标题
标题
 标题
标题
以上就是图像和标签的文件夹。数据准备的代码如下:
import os
import sys
import numpy as np
from scipy.misc import imsave
import scipy.ndimage
import pydicom
training_dicom_dir = "test\\a"
training_labels_dir = "test\\b"
training_png_dir = "Data\\Training\\Images\\Sunnybrook_Part2"
training_png_labels_dir = "Data\\Training\\Labels\\Sunnybrook_Part2"
for root, dirs, files in os.walk(training_labels_dir):
for file in files:
if file.endswith("-icontour-manual.txt"):
try:
prefix, _ = os.path.split(root)
prefix, _ = os.path.split(prefix)
_, patient = os.path.split(prefix)
file_fn = file.strip("-icontour-manual.txt") + ".dcm"
print(file_fn)
print(patient)
dcm = pydicom.read_file(os.path.join(training_dicom_dir, patient, file_fn))
print(dcm.pixel_array.shape)
img = np.concatenate((dcm.pixel_array[...,None], dcm.pixel_array[...,None], dcm.pixel_array[...,None]), axis=2)
labels = np.zeros_like(dcm.pixel_array)
print(img.shape)
print(labels.shape)
with open(os.path.join(root, file)) as labels_f:
for line in labels_f:
x, y = line.split(" ")
labels[int(float(y)), int(float(x))] = 128
labels = scipy.ndimage.binary_fill_holes(labels)
img_labels = np.concatenate((labels[..., None], labels[..., None], labels[..., None]), axis=2)
imsave(os.path.join(training_png_dir, patient + "-" + file_fn + ".png"), img)
imsave(os.path.join(training_png_labels_dir, patient + "-" + file_fn + ".png"), img_labels)
except Exception as e:
print(e)
2.2 训练
数据训练的代码如下:
import tensorflow as tf
import tensorflow.contrib.slim as slim
from tensorflow.python.ops import gen_nn_ops
from tensorflow.python.framework import ops
import numpy as np
import os
import scipy.misc
import random
WORKING_DIR = os.getcwd()
TRAINING_DIR = os.path.join(WORKING_DIR, 'Data', 'Training')
TEST_DIR = os.path.join(WORKING_DIR, 'Data', 'Test')
ROOT_LOG_DIR = os.path.join(WORKING_DIR, 'Output')
RUN_NAME = "SEGNET"
LOG_DIR = os.path.join(ROOT_LOG_DIR, RUN_NAME)
TRAIN_WRITER_DIR = os.path.join(LOG_DIR, 'Train')
TEST_WRITER_DIR = os.path.join(LOG_DIR, 'Test')
CHECKPOINT_FN = 'model.ckpt'
CHECKPOINT_FL = os.path.join(LOG_DIR, CHECKPOINT_FN)
BATCH_NORM_DECAY = 0.95 #Start off at 0.9, then increase.
MAX_STEPS = 500 #原先是20000步,这里我为了节省时间,先改成500
BATCH_SIZE = 6
SAVE_INTERVAL = 50
class GetData():
def __init__(self, data_dir):
images_list =[]
labels_list = []
self.source_list = []
examples = 0
print("loading images")
label_dir = os.path.join(data_dir, "Labels")
image_dir = os.path.join(data_dir, "Images")
for label_root, dir, files in os.walk(label_dir):
for file in files:
if not file.endswith((".png", ".jpg", ".gif")):
continue
try:
folder = os.path.relpath(label_root, label_dir)
image_root = os.path.join(image_dir, folder)
image = scipy.misc.imread(os.path.join(image_root, file))
label = scipy.misc.imread(os.path.join(label_root, file))
images_list.append(image[...,0][...,None]/255)
labels_list.append((label[...,0]>1).astype(np.int64))
examples = examples + 1
except Exception as e:
print(e)
print("finished loading images")
self.examples = examples
print("Number of examples found: ", examples)
self.images = np.array(images_list)
self.labels = np.array(labels_list)
def next_batch(self, batch_size):
if len(self.source_list) < batch_size:
new_source = list(range(self.examples))
random.shuffle(new_source)
self.source_list.extend(new_source)
examples_idx = self.source_list[:batch_size]
del self.source_list[:batch_size]
return self.images[examples_idx,...], self.labels[examples_idx,...]
def placeholder_inputs(batch_size):
images = tf.placeholder(tf.float32, [batch_size, 256, 256, 1])
labels = tf.placeholder(tf.int64, [batch_size, 256, 256])
is_training = tf.placeholder(tf.bool)
return images, labels, is_training
def unpool_with_argmax(pool, ind, name = None, ksize=[1, 2, 2, 1]):
"""
Unpooling layer after max_pool_with_argmax.
Args:
pool: max pooled output tensor
ind: argmax indices
ksize: ksize is the same as for the pool
Return:
unpool: unpooling tensor
"""
with tf.variable_scope(name):
input_shape = pool.get_shape().as_list()
output_shape = (input_shape[0], input_shape[1] * ksize[1], input_shape[2] * ksize[2], input_shape[3])
#计算所有元素的乘积
flat_input_size = np.prod(input_shape)
flat_output_shape = [output_shape[0], output_shape[1] * output_shape[2] * output_shape[3]]
pool_ = tf.reshape(pool, [flat_input_size])
batch_range = tf.reshape(tf.range(output_shape[0], dtype=ind.dtype), shape=[input_shape[0], 1, 1, 1])
b = tf.ones_like(ind) * batch_range
b = tf.reshape(b, [flat_input_size, 1])
ind_ = tf.reshape(ind, [flat_input_size, 1])
ind_ = tf.concat([b, ind_],1)#交换了两个参数
ret = tf.scatter_nd(ind_, pool_, shape=flat_output_shape)
ret = tf.reshape(ret, output_shape)
return ret
# @ops.RegisterGradient("MaxPoolWithArgmax")
# def _MaxPoolGradWithArgmax(op, grad, unused_argmax_grad):
# return gen_nn_ops._max_pool_grad_with_argmax(op.inputs[0],
# grad,
# op.outputs[1],
# op.get_attr("ksize"),
# op.get_attr("strides"),
# padding=op.get_attr("padding"))
def inference_scope(is_training, batch_norm_decay=0.9):
with slim.arg_scope([slim.conv2d],
activation_fn=tf.nn.relu,
weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
normalizer_fn=slim.batch_norm,
stride=1,
padding='SAME'):
with slim.arg_scope([slim.batch_norm],
is_training=is_training,
decay=batch_norm_decay) as sc:
return sc
def inference(images, class_inc_bg = None):
tf.summary.image('input', images, max_outputs=3)
with tf.variable_scope('pool1'):
net = slim.conv2d(images, 64, [3, 3], scope='conv1_1')
net = slim.conv2d(net, 64, [3, 3], scope='conv1_2')
net, arg1 = tf.nn.max_pool_with_argmax(net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='maxpool1')
with tf.variable_scope('pool2'):
net = slim.conv2d(net, 128, [3, 3], scope='conv2_1')
net = slim.conv2d(net, 128, [3, 3], scope='conv2_2')
net, arg2 = tf.nn.max_pool_with_argmax(net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='maxpool2')
with tf.variable_scope('pool3'):
net = slim.conv2d(net, 256, [3, 3], scope='conv3_1')
net = slim.conv2d(net, 256, [3, 3], scope='conv3_2')
net = slim.conv2d(net, 256, [3, 3], scope='conv3_3')
net, arg3 = tf.nn.max_pool_with_argmax(net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='maxpool3')
with tf.variable_scope('pool4'):
net = slim.conv2d(net, 512, [3, 3], scope='conv4_1')
net = slim.conv2d(net, 512, [3, 3], scope='conv4_2')
net = slim.conv2d(net, 512, [3, 3], scope='conv4_3')
net, arg4 = tf.nn.max_pool_with_argmax(net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='maxpool4')
with tf.variable_scope('pool5'):
net = slim.conv2d(net, 512, [3, 3], scope='conv5_1')
net = slim.conv2d(net, 512, [3, 3], scope='conv5_2')
net = slim.conv2d(net, 512, [3, 3], scope='conv5_3')
net, arg5 = tf.nn.max_pool_with_argmax(net, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='maxpool5')
with tf.variable_scope('unpool5'):
net = unpool_with_argmax(net, arg5, name='maxunpool5')
net = slim.conv2d(net, 512, [3, 3], scope='uconv5_3')
net = slim.conv2d(net, 512, [3, 3], scope='uconv5_2')
net = slim.conv2d(net, 512, [3, 3], scope='uconv5_1')
with tf.variable_scope('unpool4'):
net = unpool_with_argmax(net, arg4, name='maxunpool4')
net = slim.conv2d(net, 512, [3, 3], scope='uconv4_3')
net = slim.conv2d(net, 512, [3, 3], scope='uconv4_2')
net = slim.conv2d(net, 256, [3, 3], scope='uconv4_1')
with tf.variable_scope('unpool3'):
net = unpool_with_argmax(net, arg3, name='maxunpool3')
net = slim.conv2d(net, 256, [3, 3], scope='uconv3_3')
net = slim.conv2d(net, 256, [3, 3], scope='uconv3_2')
net = slim.conv2d(net, 128, [3, 3], scope='uconv3_1')
with tf.variable_scope('unpool2'):
net = unpool_with_argmax(net, arg2, name='maxunpool2')
net = slim.conv2d(net, 128, [3, 3], scope='uconv2_2')
net = slim.conv2d(net, 64, [3, 3], scope='uconv2_1')
with tf.variable_scope('unpool1'):
net = unpool_with_argmax(net, arg1, name='maxunpool1')
net = slim.conv2d(net, 64, [3, 3], scope='uconv1_2')
logits = slim.conv2d(net, class_inc_bg, [3, 3], scope='uconv1_1')
return logits
def loss_calc(logits, labels):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels)
loss = tf.reduce_mean(cross_entropy)
tf.summary.scalar('loss', loss)
return loss
def evaluation(logits, labels):
correct_prediction = tf.equal(tf.argmax(logits, 3), labels)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
return accuracy
def training(loss, learning_rate):
global_step = tf.Variable(0, name='global_step', trainable=False)
#This motif is needed to hook up the batch_norm updates to the training
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss=loss, global_step=global_step)
return train_op, global_step
def add_output_images(images, logits, labels):
cast_labels = tf.cast(labels, tf.uint8) * 128
cast_labels = cast_labels[...,None]
tf.summary.image('input_labels', cast_labels, max_outputs=3)
classification1 = tf.nn.softmax(logits = logits, dim=-1)[...,1]
output_image_gb = images[...,0]
output_image_r = classification1 + tf.multiply(images[...,0], (1-classification1))
output_image = tf.stack([output_image_r, output_image_gb, output_image_gb], axis=3)
tf.summary.image('output_mixed', output_image, max_outputs=3)
output_image_binary = tf.argmax(logits, 3)
output_image_binary = tf.cast(output_image_binary[...,None], tf.float32) * 128/255
tf.summary.image('output_labels', output_image_binary, max_outputs=3)
output_labels_mixed_r = output_image_binary[...,0] + tf.multiply(images[...,0], (1-output_image_binary[...,0]))
output_labels_mixed = tf.stack([output_labels_mixed_r, output_image_gb, output_image_gb], axis=3)
tf.summary.image('output_labels_mixed', output_labels_mixed, max_outputs=3)
return
def main():
training_data = GetData(TRAINING_DIR)
test_data = GetData(TEST_DIR)
g = tf.Graph()
with g.as_default():
images, labels, is_training = placeholder_inputs(batch_size=BATCH_SIZE)
arg_scope = inference_scope(is_training=True, batch_norm_decay=BATCH_NORM_DECAY)
with slim.arg_scope(arg_scope):
logits = inference(images, class_inc_bg=2)
add_output_images(images=images, logits=logits, labels=labels)
loss = loss_calc(logits=logits, labels=labels)
train_op, global_step = training(loss=loss, learning_rate=1e-04)
accuracy = evaluation(logits=logits, labels=labels)
summary = tf.summary.merge_all()
init = tf.global_variables_initializer()
saver = tf.train.Saver()
sm = tf.train.SessionManager()
ckpt=tf.train.get_checkpoint_state(LOG_DIR)
with sm.prepare_session("", init_op=init, saver=saver, checkpoint_dir=LOG_DIR) as sess:
sess.run(init)
if ckpt!=None:
print("restore model!")
saver.restore(sess,ckpt.model_checkpoint_path)
else:
print("no model!")
train_writer = tf.summary.FileWriter(TRAIN_WRITER_DIR, sess.graph)
test_writer = tf.summary.FileWriter(TEST_WRITER_DIR)
global_step_value, = sess.run([global_step])
print("Last trained iteration was: ", global_step_value)
for step in range(global_step_value+1, global_step_value+MAX_STEPS+1):
print("Iteration: ", step)
images_batch, labels_batch = training_data.next_batch(BATCH_SIZE)
train_feed_dict = {images: images_batch,
labels: labels_batch,
is_training: True}
_, train_loss_value, train_accuracy_value, train_summary_str = sess.run([train_op, loss, accuracy, summary], feed_dict=train_feed_dict)
if step % SAVE_INTERVAL == 0:
print("Train Loss: ", train_loss_value)
print("Train accuracy: ", train_accuracy_value)
train_writer.add_summary(train_summary_str, step)
train_writer.flush()
images_batch, labels_batch = test_data.next_batch(BATCH_SIZE)
test_feed_dict = {images: images_batch,
labels: labels_batch,
is_training: False}
test_loss_value, test_accuracy_value, test_summary_str = sess.run([loss, accuracy, summary], feed_dict=test_feed_dict)
print("Test Loss: ", test_loss_value)
print("Test accuracy: ", test_accuracy_value)
test_writer.add_summary(test_summary_str, step)
test_writer.flush()
saver.save(sess, CHECKPOINT_FL, global_step=step)
print("Session Saved")
print("================")
if __name__ == '__main__':
main()2.3 训练结果
 标题
标题
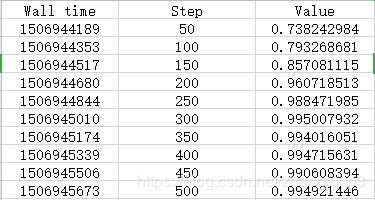
中间栏代表的是迭代次数,右边一栏代表准确率。由结果表示训练效果还是比较不错的。不过请注意,以上的编码和解码的过程很费现存,显存较小的可以适当减少对应的卷积于反卷积的过程,例如四层卷积和四层反卷积。以上就是全部过程,希望对大家有所帮助。