ElasticSearch之高亮显示
一 什么是highlight
Highlight就是我们所谓的高亮,即允许对一个或者对个字段在搜索结果中高亮显示。比如字体加粗或者字体呈现和其他文本普通颜色等。
为了执行高亮显示,该字段必须有实际的内容,并且这个字段必须存储,即在mapping中store设为true,不能只存在于内存中,否则系统会自动加载_source字段并匹配相关的列。
二 三种高亮类型
ES提供了三种高亮类型,Lucene的plain highlighter,以及fast vector highlighter(fvh)以及posting highlighter.
2.1 Plain Highlighter
Plain Hightlighter是默认的高亮选择,由使用Lucene Hightlighter实现的。它主要是试图反应查询匹配逻辑。
如果你想高亮很多字段,而且带有复杂的查询,那么这个highlight不是很快的。为了准确地反映查询逻辑,它创建了一个很小的内存索引。
并通过Lucene的查询执行计划来重新运行原始的查询条件,从而获得对当前文档的低级匹配信息,每个字段和每个需要高亮显示的文档都会重复这个过程,所以是有性能隐患的。所以需要你换一个hightlight类型
POST /ecommerce/music/_search
{
"query":{
"match":{"desc":"雅马哈 "}
},
"highlight": {
"fields": {
"desc":{}
}
}
}
2.2 Fast Vector Highlighter
如果我们在mapping中对字段指定了term_vector参数,且参数值是with_positions_offsets,那么fast vector highlighter 将会替代plain highlighter成为默认的highlight类型。
它的主要特点:
# 快,特别是对于大字段来说比较快(>1M)
# 要求在mapping中设置term_vector=with_positions_offsets
# 可以分配不同的权重来匹配不同的位置
# 我们可以设定一些属性,boundary_chars,boundary_max_scan
fragment_offset
boundary_chars:分割字符,比如有些字符包含.,!?等特殊符号,我们可以指定是否遇到他们进行分割
boundary_max_scan:表示最多扫描多少个字符
fragment_offset:从什么地方开始进行fragment
phrase_limit: 可以阻止对很多短语进行分词从而吃掉很多内存,默认是256. 只有前256个phrase才会被考虑
PUT /blogs
{
"mappings": {
"news": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"term_vector" : "with_positions_offsets"
}
}
}
}
}
2.3 Posting Highlighter
如果我们在mapping里index_options设置成offsets,这个posting hightlighter将会代替plain highlighter
它有哪些特点呢?
# 比起plain highlight性能更快一点,因为它不需要重新分析文档:尤其是对大文件对性能的提高更为明显
# 占用更少的磁盘空间
# 把高亮显示和句子分开,方便阅读
# 使用BM25算法,使搜索的时候像是整篇文档
首先你在mapping需要预先定义:
PUT /website
{
"mappings": {
"article":{
"properties": {
"title":{
"type":"text"
},
"content":{
"type":"text",
"index_options": "offsets"
}
}
}
}
}
然后添加一条数据:
PUT /website/article/1
{
"title":"Posting Highlighter",
"content":"Note that the postings highlighter is meant toperform simple query terms highlighting, regardless of their positions."
}
高亮查询
POST /website/article/_search
{
"query":{
"match":{"content":"Highlighter"}
},
"highlight": {
"fields": {
"content":{}
}
}
}
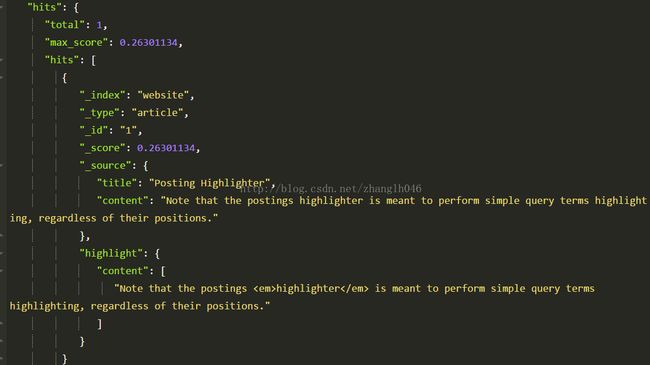
请注意:postinghighlighter只是做一个简单的查询,而不会管它的位置,这也就是说也短语查询结合的时候,它会高亮显示所有term,而不管它是否查询匹配的一部分
POST /website/article/_search
{
"query": {
"match_phrase": {
"content": {
"query": "perform terms",
"slop":3
}
}
},
"highlight": {
"fields": {
"content":{}
}
}
}
还有,postinghighlighter不支持很复杂的查询,比如match_phrase_prefix,返回结果不会高亮
所以我们需要从实际情况去考虑,一般情况下,用plain highlight也就足够了,不需要做其他额外的设置;如果对高亮的性能要求很高,可以尝试启用posting highlight;如果field的值特别大,超过了1M,那么可以用fastvector highlight
三 控制参数
3.1设置高亮html标签,默认是标签
我们可以使用pre_tags属性和post_tags属性自定义高亮显示html标签,去替代默认的em标签
PUT /blogs
{
"mappings": {
"news": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"term_vector" : "with_positions_offsets"
}
}
}
}
}
PUT /blogs/news/1
{
"title":"资本催熟的!流行!,或是共享经济大潮里的#流星#",
"content":"迷你.KTV一开始就绑着/共享娱乐/的名号,和自助健身屋、自助咖啡厅、共享单车"
}
POST /blogs/news/_search
{
"query": {
"match":{"content":"迷你"}
},
"highlight": {
"pre_tags": [""],
"post_tags": [""],
"fields": {
"content":{}
}
}
}
3.2 强制使用某种highlight
当前你可能已经在mapping中设置了index_options选项为offsets或者设置了term_vector为with_positions_offsets,那么他们默认的高亮就不是plain highlight,如果我们就希望使用plain highlight,那么我们可以使用type参数来指定。他有三种可以选择的类型:plain,posting,fvh.
POST /blogs/news/_search
{
"query": {
"match":{"content":"迷你"}
},
"highlight": {
"fields": {
"content":{
"type":"plain"
}
}
}
}
3.3高亮片段fragment的设置
fragment_size: 某字段的值,长度是1万,但是我们一般不会在页面展示这么长,可能只是展示一部分。设置要显示出来的fragment文本判断的长度,默认是100
number_of_fragments:高亮的文本片段有多个,你希望展示几个
no_match_size: 可能没有高亮的文本片段,这个参数可以设置从该字段的开始制定长度为多少,然后作为默认的显示
POST /blogs/news/_search
{
"query": {
"match":{"content":"自助"}
},
"highlight": {
"fields": {
"content":{
"fragment_size" : 2,
"number_of_fragments" : 1,
"no_match_size": 2
}
}
}
}
四 全局设置
我们可以进行全局的设置高亮属性,然后fields字段可以重写这些全局设置
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"number_of_fragments" : 3,
"fragment_size" : 150,
"fields" : {
"_all" : { "pre_tags" : [""],"post_tags" : [""] },
"bio.title" : { "number_of_fragments" : 0 },
"bio.author" : { "number_of_fragments" : 0 },
"bio.content" : { "number_of_fragments" : 5,"order" : "score" }
}
}
}