仔仔细细做面试题---google2013校园招聘笔试题
1.单项选择题
1.1 使用C语言将一个1G字节的字符数组从头到尾全部设置为字符'A',在一台典型的当代PC上,需要花费的CPU时间的数量级最接近:
A. 0.001秒 B. 1秒 C. 100秒 D. 2小时
解答:现在机器cpu都是GHz,每次需要若干个指令,大约在1秒。
1.2 在某些极端要求性能的场合,我们需要对程序进行优化,关于优化,以下说明正确的是:
A. 将程序整个用汇编语言改写会大大提高程序性能。
B. 在优化前,可以先确定哪部分代码最为耗时,然后对这部分代码使用汇编语言改写,使用的汇编语句数目越少,程序就运行越快。
C. 使用汇编语言虽然可能提高程序性能,但是降低了程序的可移植性和可维护性,所以应该绝对避免。
D. 适当调整汇编指令的顺序,可以缩短程序运行的时间。
解答:A中,不应该将程序整个改写,应该只改写关键部分,整个改写降低了程序的可移植性和可维护性,B,汇编语句不是数目越少越快,循环等
C。不应该绝对避免
1.3 对如下c语言程序在普通的x86 pc上面运行时候的输出叙述正确的是:
char *f()
{
char X[512];
sprintf(X, "hello world");
return X+6;
}
void main()
{
printf("%s",f());
}
A.程序可能崩溃,也可能输出hello world
B.程序可能崩溃,也可能输出world
C.程序可能崩溃,也可能输出hello
D.程序一定会崩溃
解答:
这个程序是想返回一个数组的值,X是一个数组,是函数f()中的一个局部变量,在这个函数结束的时候,将会释放掉这个数组,
而X+6只是一个指向world的一个地址,f()返回的就是这个地址,但是地址中的内容没有了。
这里主要是讨论的数组返回的问题参考地址: http://www.cnblogs.com/yangxi/archive/2011/09/18/2180759.html
1.4 方程x1+x2+x3+x4 =30有多少满足x1>=2,x2>=0,x3>=-5, x4>=8的整数解?
A.3276
B. 3654
C.2925
D.17550
解答:整数划分问题;y1 = x1 - 2 >= 0,y2 = x2 >= 0,y3 = x3 + 5 >= 0,y4 = x4 - 8 >= 0;故y1 + y2 + y3 + y4 = 25,Num = 28 * 27 * 26/6 = 3276
1.5 一个袋子里装了100个苹果,100个香蕉,100个桔子,100个梨,如果每分钟从里面随机抽取一个水果,那么最多过多少分钟时间能肯定至少拿到一打相同种类的水果?(1打=12个)
A. 40
B. 12
C.24
D.45
解答:4中水果都取了11个,用时间4*11=44分钟,再取一个。45分钟
1.6 双败淘汰赛与淘汰赛相仿,也是负者出局,但负一场后并未被淘汰,只是跌入负者组,在负者组再负者(即总共已负两场)才被淘汰。现在有10个人参加双败淘汰赛,假设我们取消最后的胜者组冠军VS负者组冠军的比赛,那么一个需要举行多少场比赛?
A. 16
B.17
C.18
D.19
E.20
解答:10个人需要进行9场产生9个第一次失败的人,在失败者的9个人需要8场比赛,淘汰8个人,所以需要9+8=17
1.7 n个节点的二叉树,最多可以有多少层?
A. n/2
B. log(n)
C. n-1
D.n
解答:每层一个节点的二叉树
1.8
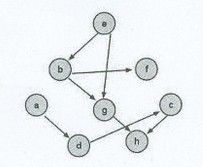 .
.
.
下
面哪
个序列不是上图的拓扑排序?
A. ebfgadch
B.adbdgfch
C.adchebfg
D.aedbfgch
解答:
拓扑排序方法如下:
(1)从有向图中选择一个没有前驱(即入度为0)的顶点并且输出它.
(2)从网中删去该顶点,并且删去从该顶点发出的全部有向边.
(3)重复上述两步,直到剩余的网中不再存在没有前趋的顶点为止.
在C中h应是的g后面的。
1.9假设某主机安装了2G内存,在其上运行的某支持MMU的32位Linux发行版中,一共运行了X,Y,Z三个进程,下面关于三个程序使用内存的方式,哪个是可行的?
A.X,Y, Z 的虚拟地址空间都映射到0~4G的虚拟地址上
B.X在堆上分配总大小为1GB的空间,Y在堆上分配200MB,Z在堆上分配500MB,并且内存映射访问一共1GB的磁盘文件。
C. X 在堆上分配1GB,Y在堆上分配800MB,Z在堆上分配400MB
D.以上访问方式都是可行的
解答:MMU是内存管理单位,A是对的。其它未知,欢迎补充。
1.10
当使用TCP协议编程是,下列问题哪个是必须由程序员考虑和处理的?
A. 乱序数据包的重传
B.数据传输过程中的纠错
C.网络拥塞处理
D.发生数据的格式和应用层协议
解答:TCP协议功能---
主要功能是完成对数据报的确认、流量控制和网络拥塞;自动检测数据报,并提供错误重发的功能;将多条路径传送的数据报按照原来的顺序进行排列,并对重复数据进行择取;控制超时重发,自动调整超时值;提供自动恢复丢失数据的功能。
2.程序设计和算法
(2.1,2.2为编程题,需要写出程序实现;2.3为算法设计题,只需要写出算法设计思路及关键步骤的伪代码即可。)
2.1
给定三个整数a,b,c,实现函数int median(int a, int b, int c),返回三个数的中位数。不可以使用sort,要求整数操作(比较,位运行,加减乘除等)次数尽量少。 并分析说明程序最坏和平均情况下使用的次数。
解答:用了三次比较,一次运算。
代码实现:
- #include
- using namespace std;
- int median(int a,int b,int c)
- {
- int min=a;
- int max=b;
- if (b
- {
- min=b;
- }
- else
- {
- max=b;
- }
- if (c
- {
- min=c;
- }
- else if (c>max)
- {
- max=c;
- }
- return a+b+c-min-max;
- }
- int main()
- {
- cout<
- }
2.2
给定一个key(只含有ASCII编码的小写英文字母),例如kof,然后对input的string(只含有ASCII编码的小写英文字符)利用这个key排序。顺序是:先按照key中的字符排序,然后对key中不包含的字符,按a-z排序;
解答:
思路:(1)用hash表的思想,先对key字和a~z重新排序,可以定义一个26个字符的数组,char hash[26]; 对不同的字母对应的给与排序的值,
例如key中为kof,得到的hash['k'-97]=0; hash['o'-97]=1;hash['f'-97]=2;hash['a'-97]=3;..................
(2)用快速排序(已可以是其他算法)算法进行排序
代码实现:
- #include
- #include
- using namespace std;
- void swap(char* a,char* b)
- {
- char temp=*a;
- *a=*b;
- *b=temp;
- }
- void create_hash(char* hashtable,char* key)
- {
- int iKeyLength=strlen(key);
- int iValue=0;
- for (int i=0;i<26;i++)
- {
- hashtable[i]='#';
- }
- //先对关键字符排在前面
- for (int i=0;i
- {
- hashtable[*(key+i)-97]=iValue;
- iValue++;
- }
- //对剩余的字符进行排列
- for (int i=0;i<26;i++)
- {
- if (hashtable[i]=='#') //其中的hashtable[i]==hashtable['a'+i-97]
- {
- hashtable[i]=iValue;
- iValue++;
- }
- }
- }
- //快速排序
- void quick_sort(char* str,int iStart,int iEnd,char* hashtable)
- {
- if (iStart>=iEnd)
- {
- return ;
- }
- char* pSign=str+iStart; //将第一个作为划分标志
- char* pMove=str+iEnd; //需要比较移动的点
- char* pTemp;
- while(pSign!=pMove)
- {
- if (pMove>pSign)
- {
- if (hashtable[*pSign-97]>hashtable[*pMove-97])
- {
- swap(pSign,pMove); //交换值
- pTemp=pMove; //交换指针
- pMove=pSign;
- pSign=pTemp;
- pMove++;
- }
- else
- {
- pMove--;
- }
- }
- else
- {
- if (hashtable[*pSign-97]
- {
- swap(pSign,pMove); //交换值
- pTemp=pMove; //交换指针
- pMove=pSign;
- pSign=pTemp;
- pMove--;
- }
- else
- {
- pMove++;
- }
- }
- }
- quick_sort(str,iStart,pSign-1-str,hashtable);
- quick_sort(str,pSign+1-str,iEnd,hashtable);
- }
- void sort(char* str,char* key)
- {
- char hashTable[26];
- create_hash(hashTable,key);
- quick_sort(str,0,strlen(str)-1,hashTable);
- }
- int main()
- {
- char str[]="helloworld";
- char key[]="kol";
- sort(str,key);
- cout<
- }
2.3 一个平行于坐标轴的n*n的网格,左下角(0,0)右上角(n,n),n为非负整数,有n个平行于坐标轴的矩形,每个矩形用左下角(x1,y1)右上角(x2,y2)来表示,x1,y1,x2,y2都是非负整数,现在有非常多个query,每个query会询问一个网格(x,y)(x+1,y+1)一个被几个矩形覆盖。现在要求设计一个算法,使得出来每个query的时间复杂度尽可能低,在这个前提下,预处理的时间复杂度尽可能低。
(1<=n<=1000)