fasttext算法原理及使用
1. FastText原理
fastText是一种简单高效的文本表征方法,性能与深度学习比肩。fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。主要功能在于:
- 文本分类:有监督学习
- 词向量表征:无监督学习
1.1 模型框架(Model architecture)
fastText的结构与word2vec的CBOW模型架构相似(fastText的开源工具不仅可以文本分类,还可以训练词向量,与word2vec相似)。word2vec有两种模型:skip-gram 模型和CBOW模型。两者的区别概括区别是:skip-gram,用当前词来预测上下文;CBOW,用上下文来预测当前词。
CBOW及fastText的模型框架对比如下:
|
CBOW模型框架
|
fastText模型框架
|
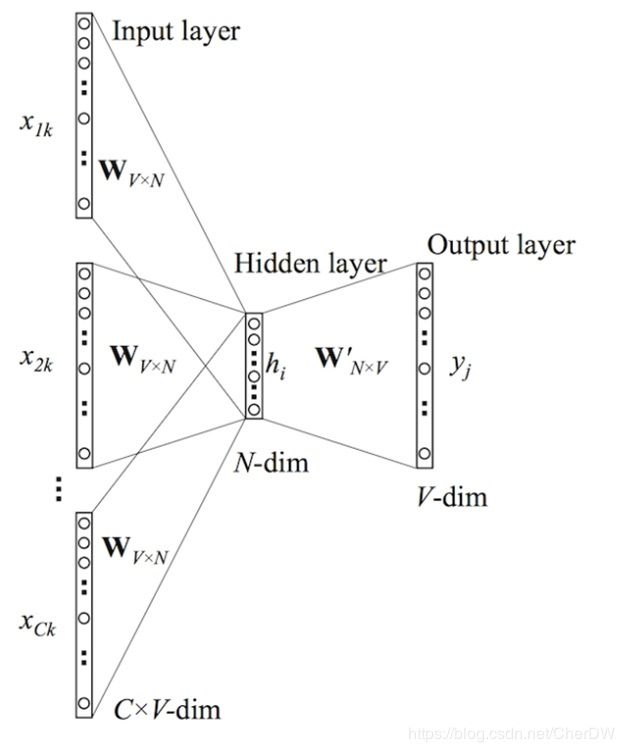
 是被
是被 连接到隐含层;
连接到隐含层;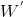 连接到输出层;
连接到输出层;
1.2 层次softmax(Hierarchical softmax)
1.2.1 标准softmax函数
softmax函数又称为归一化指数函数,常在神经网络输出层充当激活函数,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。下图为softma x的计算过程:
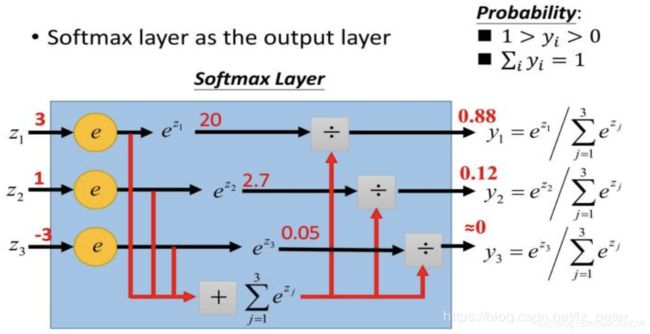
softmax的作用:
- 将预测结果转化为非负数;
- 各种预测结果概率之和等于1;
1.2.2 层次softmax函数
标准的softmax中,计算一个类别的softmax概率时,需要对所有的类别概率做归一化,这在类别数量很大时会很耗时;分层softmax(Hierarchical Softmax)的目的就是提高计算效率,方法是构造霍夫曼树来代替标准softmax,只需计算一条路径上的所有节点的概率值,无需在意其它的节点。通过分层softmax可以将复杂度从N降低到logN。
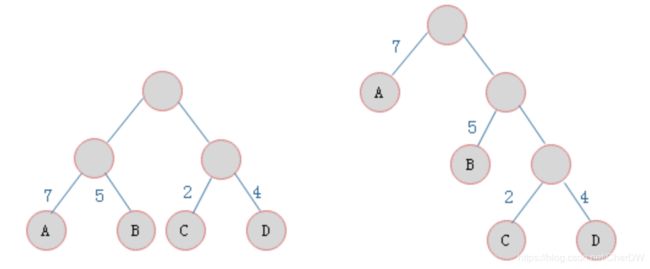
霍夫曼树:
给定n个权值作为n个叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为霍夫曼树(Huffman Tree)。
如左图所示两棵二叉树,叶子结点为A、B、C、D,对应权值分别为7、5、2、4。树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL。
叶子结点为A、B、C、D,对应权值分别为7、5、2、4。
- 左树的WPL = 7 * 2 + 5 * 2 + 2 * 2 + 4 * 2 = 36
- 右树的WPL = 7 * 1 + 5 * 2 + 2 * 3 + 4 * 3 = 35
由ABCD构成叶子结点的二叉树形态有许多种,但是WPL最小的树只有右树所示的形态。则右树为一棵霍夫曼树。
下图是一个层次softmax:

树的结构是根据类别标记的频数构造的霍夫曼树。K个不同的类标组成所有的叶子节点,从根节点到某个叶子节点经过的节点和边形成一条路径,路径长度为![]() 。需要计算目标词
。需要计算目标词 的概率,这个概率的具体含义,是指从根结点开始随机走,走到目标词的概率,非叶子结点处需要分别知道往左走和往右走的概率。例如到达非叶子节点n的时候往左边走和往右边走的概率分别是:
的概率,这个概率的具体含义,是指从根结点开始随机走,走到目标词的概率,非叶子结点处需要分别知道往左走和往右走的概率。例如到达非叶子节点n的时候往左边走和往右边走的概率分别是:
![]()
![]()
图中标记的路径是从根节点到叶子节点 的路径,路径长度
的路径,路径长度![]() ,节点的概率可以表示为:
,节点的概率可以表示为:
从根节点走到叶子节点 ,实际上是在做了3次二分类的逻辑回归;通过分层的softmax,计算复杂度从|K|降低到log|K|。
1.3 N-gram特征(N-gram features)
原始文本是一个单词序列,一般的词袋表示中没有任何序列,它只记录每个单词在文本中出现的次数。因此 fastText 还加入了 N-gram 特征,基本思想是将文本内容按照字节顺序进行大小为N的滑动窗口操作,最终形成长度为N的字节片段序列。n-gram可以是字粒度,也可以是词粒度的。n-gram产生的特征只是作为文本特征的候选集,后面可能会采用信息熵、卡方统计、IDF等文本特征选择方式筛选出比较重要特征。
bigram特征示例:我来到北京旅游
- 字粒度:我来 来到 到北 北京 京旅 旅游
- 词粒度:我/来到 来到/北京 北京/旅游
n-gram有如下优点:
- 保持词序信息:n-gram可以让模型学习到局部单词顺序的部分信息;
- 处理低频词:字符级别的n-gram,即使这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,可以优化生成的单词向量;
- 处理未出现过的词:字符级n-gram,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量;
2.fastText文本分类实践
fasttext官网:https://fasttext.cc/
中文社区:http://fasttext.apachecn.org/#/doc/zh/support
fastText 支持的不同用例:
The commands supported by fasttext are:
supervised 训练一个监督分类器
quantize 量化模型以减少内存使用量
test 评估一个监督分类器
predict 预测最有可能的标签
predict-prob 用概率预测最可能的标签
skipgram 训练一个 skipgram 模型
cbow 训练一个 cbow 模型
print-word-vectors 给定一个训练好的模型,打印出所有的单词向量
print-sentence-vectors 给定一个训练好的模型,打印出所有的句子向量
nn 查询最近邻居
analogies 查找所有同类词fasttext.supervised 参数如下
input_file 训练文件路径(必须)
output 输出文件路径(必须)
label_prefix 标签前缀 default __label__
lr 学习率 default 0.1
lr_update_rate 学习率更新速率 default 100
dim 词向量维度 default 100
ws 上下文窗口大小 default 5
epoch epochs 数量 default 5
min_count 最低词频 default 5
word_ngrams n-gram 设置 default 1
loss 损失函数 {ns,hs,softmax} default softmax
minn 最小字符长度 default 0
maxn 最大字符长度 default 0
thread 线程数量 default 12
t 采样阈值 default 0.0001
silent 禁用 c++ 扩展日志输出 default 1
encoding 指定 input_file 编码 default utf-8
pretrained_vectors 指定使用已有的词向量 .vec 文件 default None先贴出其他博客不错的代码,后面给出实例:
# -*- coding:utf-8 -*-
import pandas as pd
import random
import fasttext
import jieba
from sklearn.model_selection import train_test_split
cate_dic = {'technology': 1, 'car': 2, 'entertainment': 3, 'military': 4, 'sports': 5}
"""
函数说明:加载数据
"""
def loadData():
#利用pandas把数据读进来
df_technology = pd.read_csv("./data/technology_news.csv",encoding ="utf-8")
df_technology=df_technology.dropna() #去空行处理
df_car = pd.read_csv("./data/car_news.csv",encoding ="utf-8")
df_car=df_car.dropna()
df_entertainment = pd.read_csv("./data/entertainment_news.csv",encoding ="utf-8")
df_entertainment=df_entertainment.dropna()
df_military = pd.read_csv("./data/military_news.csv",encoding ="utf-8")
df_military=df_military.dropna()
df_sports = pd.read_csv("./data/sports_news.csv",encoding ="utf-8")
df_sports=df_sports.dropna()
technology=df_technology.content.values.tolist()[1000:21000]
car=df_car.content.values.tolist()[1000:21000]
entertainment=df_entertainment.content.values.tolist()[:20000]
military=df_military.content.values.tolist()[:20000]
sports=df_sports.content.values.tolist()[:20000]
return technology,car,entertainment,military,sports
"""
函数说明:停用词
参数说明:
datapath:停用词路径
返回值:
stopwords:停用词
"""
def getStopWords(datapath):
stopwords=pd.read_csv(datapath,index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')
stopwords=stopwords["stopword"].values
return stopwords
"""
函数说明:去停用词
参数:
content_line:文本数据
sentences:存储的数据
category:文本类别
"""
def preprocess_text(content_line,sentences,category,stopwords):
for line in content_line:
try:
segs=jieba.lcut(line) #利用结巴分词进行中文分词
segs=filter(lambda x:len(x)>1,segs) #去掉长度小于1的词
segs=filter(lambda x:x not in stopwords,segs) #去掉停用词
sentences.append("__lable__"+str(category)+" , "+" ".join(segs)) #把当前的文本和对应的类别拼接起来,组合成fasttext的文本格式
except Exception as e:
print (line)
continue
"""
函数说明:把处理好的写入到文件中,备用
参数说明:
"""
def writeData(sentences,fileName):
print("writing data to fasttext format...")
out=open(fileName,'w')
for sentence in sentences:
out.write(sentence.encode('utf8')+"\n")
print("done!")
"""
函数说明:数据处理
"""
def preprocessData(stopwords,saveDataFile):
technology,car,entertainment,military,sports=loadData()
#去停用词,生成数据集
sentences=[]
preprocess_text(technology,sentences,cate_dic["technology"],stopwords)
preprocess_text(car,sentences,cate_dic["car"],stopwords)
preprocess_text(entertainment,sentences,cate_dic["entertainment"],stopwords)
preprocess_text(military,sentences,cate_dic["military"],stopwords)
preprocess_text(sports,sentences,cate_dic["sports"],stopwords)
random.shuffle(sentences) #做乱序处理,使得同类别的样本不至于扎堆
writeData(sentences,saveDataFile)
if __name__=="__main__":
stopwordsFile=r"./data/stopwords.txt"
stopwords=getStopWords(stopwordsFile)
saveDataFile=r'train_data.txt'
preprocessData(stopwords,saveDataFile)
#fasttext.supervised():有监督的学习
classifier=fasttext.supervised(saveDataFile,'classifier.model',lable_prefix='__lable__')
result = classifier.test(saveDataFile)
print("P@1:",result.precision) #准确率
print("R@2:",result.recall) #召回率
print("Number of examples:",result.nexamples) #预测错的例子
#实际预测
lable_to_cate={1:'technology'.1:'car',3:'entertainment',4:'military',5:'sports'}
texts=['中新网 日电 2018 预赛 亚洲区 强赛 中国队 韩国队 较量 比赛 上半场 分钟 主场 作战 中国队 率先 打破 场上 僵局 利用 角球 机会 大宝 前点 攻门 得手 中国队 领先']
lables=classifier.predict(texts)
print(lables)
print(lable_to_cate[int(lables[0][0])])
#还可以得到类别+概率
lables=classifier.predict_proba(texts)
print(lables)
#还可以得到前k个类别
lables=classifier.predict(texts,k=3)
print(lables)
#还可以得到前k个类别+概率
lables=classifier.predict_proba(texts,k=3)
print(lables)