《PostgreSQL 开发指南》第 08 篇 备份与恢复
文章目录
- 基本概念
- 备份类型
- 备份恢复工具
- 备份与恢复
- 逻辑备份与还原
- 备份单个数据库
- 备份整个集群
- 导出表数据
- 备份大型数据库
- 物理备份与恢复
- 离线备份
- 在线备份
- 时间点恢复
基本概念
服务器系统错误、硬件故障或者人为失误都可能导致数据的丢失或损坏。因此,备份和恢复对于数据库的高可用性至关重要。数据库管理员应该根据业务的需求制定合适的备份策略,并提前演练各种故障情况下的恢复过程,做到有备无患。
在升级 PostreSQL 版本之前,通常也需要先进行数据库的备份。另外,备份也可以用于主从复制结构中的从节点初始化。
备份(backup),通过某种方式(物理复制或者逻辑导出)将数据库的文件或结构和数据拷贝到其他位置进行存储。
还原(restore),一种不完全的恢复,使用备份的文件将数据库恢复到执行备份时的状态。备份时间点之后的数据变更无法通过还原进行恢复。
恢复(recovery),执行恢复时,通常是先使用物理备份文件进行还原,然后再应用备份时间点到故障点之间的日志文件(WAL),将数据库恢复到最新状态。
备份类型
根据备份的方式和内容的不同,可以进行以下分类。
物理备份与逻辑备份
物理备份(Physical Backup) 就是直接复制数据库相关的文件。通常来说,物理备份比逻辑备份更快,但是占用的空间也更大。PostgreSQL 支持在线和离线的物理备份。实际环境中应该以物理备份为主。
逻辑备份(Logical Backup) 就是将数据库的结构和数据导出为 SQL 文件,还原时通过文件中的 SQL 语句和命令重建数据库并恢复数据。逻辑备份通常需要更多的备份和还原时间。逻辑备份可以作为物理备份的补充,或者用于测试目的的数据导入导出。
在线备份与离线备份
在线备份(Online Backup) 是指 PostgreSQL 服务器处于启动状态时的备份,也称为热备份(Hot Backup)。由于逻辑备份需要连接到数据库进行操作,因此逻辑备份只能是在线备份。
离线备份(Offline Backup) 是指 PostgreSQL 服务器处于关闭状态时的备份,也称为冷备份(Cold Backup)。离线状态只能执行数据库的物理备份,即复制数据库文件。
全量备份与增量备份
全量备份(Full Backup) 就是备份所有的数据库文件,执行一次完整的 PostgreSQL 数据库集群备份。这种方式需要备份的内容较多,备份时较慢,但是恢复速度更快。
增量备份(Incremental Backup) 就是备份上一次备份(任何类型)之后改变的文件。另外,差异备份(Differential Backup) 是针对上一次完全备份后发生变化的所有文件进行备份。增量备份每次备份的数据量较小,但是恢复时需要基于全量备份,并依次恢复增量部分,时间较长。差异备份位于两者之间。
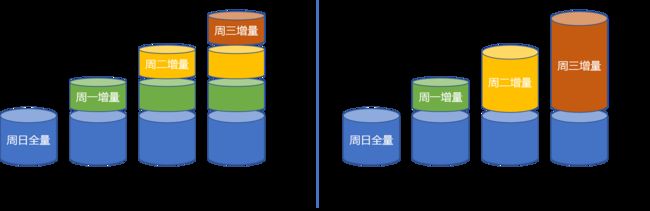
在 PostgreSQL 中是通过一个基准备份(Base Backup),加上不断备份的事务日志文件(WAL)来达到增量备份的效果。
在实际环境中可以结合全量备份和增量/差异备份,以平衡备份和恢复所需的存储空间和时间。
备份恢复工具
PostgreSQL 为不同的备份和恢复类型提供了相应的工具和方法。

- pg_dump,逻辑备份工具,支持单个数据库(可以指定模式、表)的导出,可以选择导出的格式。
- pg_dumpall,逻辑备份工具,用于导出整个数据库集群,包括公用的全局对象。
- pg_basebackup,物理备份工具,为数据库集群创建一个基准备份。它也可以用于时间点恢复(point-in-time recovery)的基准备份,或者设置基于日志传输或流复制的从节点的初始化。
- psql,PostgreSQL 交互式命令行工具,也可以用于导入逻辑备份产生的 SQL 文件。
- pg_restore,逻辑还原工具,用于还原 pg_dump 导出的归档格式的备份文件。
- COPY,PostgreSQL 专有的 SQL 语句,将表中的数据复制到文件,或者将文件中的数据复制到表中。
此外,还可以通过第三方工具执行备份与恢复操作。
- pgAdmin(开源)
- Barman(开源)
- pg_probackup(开源)
- pgBackRest(开源)
- BART(商业)
接下来,我们介绍如何利用 PostgreSQL 自带的工具和命令执行备份与恢复操作。
备份与恢复
逻辑备份与还原
执行逻辑备份时,PostgreSQL 服务器必须已经启动,备份工具(例如 pg_dump)通过建立数据库连接,从数据库中查询出相应的结构信息和数据,并生成备份文件。针对不同的备份格式,PostgreSQL 提供了配套的还原工具。
备份单个数据库
PostgreSQL 提供了备份单个数据库的工具 pg_dump。它支持三种文件格式:
- plain,文本格式,输出一个纯文本形式的 SQL 脚本,默认值。还原时直接使用 psql 导入。
- custom,自定义格式,输出一个自定义格式的归档文件,还原时使用 pg_restore 工具。与目录导出格式结合使用时,提供了最灵活的输出格式,它允许在恢复时手动选择和排序已归档的项。这种格式在默认情况还会进行文件的压缩。
- directory,目录格式,输出一个目录格式的归档,还原时使用 pg_restore 工具。这种格式将会创建一个目录,为每个导出的表和大对象都创建一个文件,另外再创建一个内容目录文件,该文件使用自定义格式存储关于导出对象的描述。这种格式在默认情况还会进行文件的压缩,并且支持并行导出。
- tar,打包格式,输出一个 tar 格式的归档,还原时使用 pg_restore 工具。这种格式与目录格式兼容,解压一个 tar 格式的归档将会产生一个目录格式的归档。但是,tar 格式不支持压缩。另外,在使用 tar 格式归档进行还原时,表数据项的相对顺序不能进行改动。
接下来我们看一些示例。首先,使用 pg_dump 文本格式导出数据库 testdb:
-bash-4.2$ whoami
postgres
-bash-4.2$ pg_dump testdb > testdb.sql
以上命名将会创建一个 sql 文件 testdb.sql,其中包含了重建数据库 testdb 中对象所需的脚本,包括表中的数据。
关于 pg_dump 工具的各种选项,可以参考官方文档。
对于 sql 文件格式的备份,还原时直接使用 psql 导入相关文件即可:
-bash-4.2$ psql newdb -f testdb.sql
SET
SET
SET
...
以上命令将 testdb.sql 中的内容还原到数据库 newdb 中。
关于 psql 工具的使用可以参考官方文档。
pg_dump 和 psql 支持的读写管道功能使得我们可以直接将数据库从一个服务器导出到另一个服务器,例如:
pg_dump -h host1 dbname | psql -h host2 dbname
接下来,使用自定义格式导出数据库 testdb:
-bash-4.2$ pg_dump -Fc testdb -f testdb.dmp
其中,-Fc 指定自定义格式,-f 指定导出的文件名。这种格式的备份,还原时需要使用 PostgreSQL 提供的 pg_restore 工具。
-bash-4.2$ pg_restore -d newdb testdb.dmp
其中,-d 表示还原到数据库 newdb 中。
关于 pg_restore 工具的使用和选项,可以参考官方文档。
继续,使用目录格式导出数据库 testdb:
-bash-4.2$ pg_dump -Fd testdb -f testdb_dir
其中,-Fd 指定目录格式,-f 指定导出的文件目录。这种格式的备份,还原时需要使用 PostgreSQL 提供的 pg_restore 工具。
-bash-4.2$ pg_restore -d newdb testdb_dir
使用 tar 格式导出数据库 testdb:
-bash-4.2$ pg_dump -Ft testdb -f testdb.tar
其中,-Ft 指定 tar 格式,-f 指定导出的文件名。这种格式的备份,还原时需要使用 PostgreSQL 提供的 pg_restore 工具。
-bash-4.2$ pg_restore -d newdb testdb.tar
备份整个集群
pg_dump 每次只导出一个数据库,而且它不会导出角色或表空间(属于集群范围)相关的信息。为此,PostgreSQL 还提供了导出数据库集群的 pg_dumpall 工具。它会针对集群中的每个数据库调用 pg_dump 来完成导出工作,同时还导出所有数据库公用的全局对象(pg_dump不保存这些对象),包括数据库用户和组、表空间以及所有数据库的访问权限等属性。
我们使用 pg_dumpall 导出整个数据库集群:
-bash-4.2$ pg_dumpall -f cluster.sql
关于 pg_dumpall 工具的各种选项和使用方法,可以参考官方文档。
因为 pg_dumpall 从所有数据库中读取表,所以需要以一个超级用户的身份连接以便生成完整的导出操作。同样,还原时也需要超级用户特权执行备份的脚本,这样才能增加用户和组以及创建数据库。
pg_dumpall 导出 sql 文件格式的备份,还原时直接使用 psql 导入相关文件即可。
-bash-4.2$ psql -f cluster.sql postgres
以上命令通过 psql 工具连接到数据库 postgres,然后运行 cluster.sql 文件还原之前的备份。
导出表数据
如果只需要导出指定表中的数据(例如为了测试而迁移数据),PostgreSQL 至少提供了以下两种方法:
- 使用 pg_dump 中导出表的选项 -t 和 -T;
- 使用
COPY命令复制数据
首先使用 pg_dump 导出数据库 testdb 中以 emp 开头的表(排除表 employees)中的数据:
-bash-4.2$ pg_dump -a -t 'emp*' -T employees testdb > testdb_table.sql
其中,-a 表示只导出数据(不包含结构),-t 指定要导出的表,-T 表示排除的表。导出时也可以指定其他的导出格式,并且采用相应的方式进行数据导入,参考上文。
另外,使用COPY命令可以导出单个表中的数据或查询结果集:
postgres=# \c testdb;
You are now connected to database "testdb" as user "postgres".
testdb=# COPY products to '/var/lib/pgsql/products.dat';
COPY 1
COPY支持不同的写入/读取文件格式:text、 csv 或者 binary。默认是 text。
对于COPY导出的文件,同样使用COPY命令进行导入。
testdb=# COPY products FROM '/var/lib/pgsql/products.dat';
以上语句将指定文件中的数据导入(追加)表 products 中。
关于
COPY命令的使用,可以参考官方文档。
备份大型数据库
对于大型数据库,在执行备份和恢复操作时,可能会面临两个问题:备份文件过大,或者操作时间过长。
对于文件过大的问题,pg_dump 和 pg_dumpall 支持将内容写到标准输出,结合操作系统提供的一些工具,可以进行以下处理:
导出压缩格式的文件,以下命令利用 gzip 工具对导出文件进行压缩。
-bash-4.2$ time pg_dumpall > cluster.sql
real 2m18.435s
user 0m32.315s
sys 0m49.526s
-bash-4.2$ time pg_dumpall | gzip > cluster.sql.gz
real 6m20.461s
user 6m38.507s
sys 0m47.674s
-bash-4.2$ ls -lh
total 23G
drwx------ 6 postgres postgres 81 Dec 5 11:18 11
drwx------. 2 postgres postgres 6 Dec 8 2017 backups
-rw-r--r-- 1 postgres postgres 22G Mar 6 04:00 cluster.sql
-rw-r--r-- 1 postgres postgres 1.8G Mar 6 04:33 cluster.sql.gz
drwx------. 2 postgres postgres 6 Dec 8 2017 data
可以看出,压缩需要占用更多的时间,但是导出的备份文件更小。
还原时先使用 gunzip 解压再导入:
-bash-4.2$ gunzip -c cluster.sql.gz | psql newdb
分割导出的文件,利用操作系统提供的工具,例如 split,将导出的文件分割成多个小的文件:
-bash-4.2$ pg_dumpall | split -b 1G - cluster
以上命令使用 pg_dumpall 导出整个数据库集群,并且利用 split 将备份文件分割为多个 1 GB 的文件(clusteraa、clusterab 等)。还原时导入所有的备份文件即可:
-bash-4.2$ cat cluster* | psql newdb
COPY 命令也提供了类似的压缩功能:
COPY products to PROGRAM 'gzip > /var/lib/pgsql/products.dat.gz';
还原时也一样:
COPY products FROM PROGRAM 'gunzip < /var/lib/pgsql/products.dat.gz';
pg_dump 自定义格式导出,如果 PostgreSQL 所在的系统上安装了 zlib 压缩库,导出自定义格式时将会对输出文件进行压缩。这种方式和使用 gzip 压缩的效果类似,但是它还有一个优点就是还原时可以选择指定的表。
对于超大型的数据库,可以将 split 与其他两种方法配合使用。
pg_dump 并行导出,并行导出可以同时备份多个表。使用 -j 参数控制并发数,并行导出只支持“目录”导出格式。
-bash-4.2$ time pg_dump -F d -f out.dir testdb
real 10m22.901s
user 10m13.333s
sys 0m8.830s
-bash-4.2$ time pg_dump -j 8 -F d -f out.dir testdb
real 2m31.607s
user 2m27.522s
sys 0m4.010s
还原时也可以使用 pg_restore -j 指定并发导入。它只能用于自定义或目录格式的导出文件,无论这些归档是否由 pg_dump -j 创建。
物理备份与恢复
离线备份
离线备份,也称为冷备份,通过文件系统级别的复制备份数据库(/data 目录)。这种备份方式要求关闭 PostgreSQL 实例服务,以便创建一个一致的数据备份。PostgreSQL 可以通过软链接的方式将 pg_wal(pg_xlog)和 pg_tblspce 存储到其他的挂载设备。
执行以下步骤创建一个 PostgreSQL 冷备份,备份数据中包含了软链接指向的数据内容:
-
关闭 PostgreSQL 服务;
-bash-4.2$ pg_ctl stop -D /var/lib/pgsql/11/data/ -
执行操作系统命令,拷贝数据目录;
-bash-4.2$ tar czf backup.tar.gz /var/lib/pgsql/11/data也可以使用
cp或者rsync等命令复制数据目录。 -
完成备份之后,重新启动 PostgreSQL 服务。
-bash-4.2$ pg_ctl start -D /var/lib/pgsql/11/data/
离线备份只能备份整个数据库集群,还原时也一样。执行还原时可以直接使用备份文件启动 PostgreSQL 服务:
-
关闭 PostgreSQL 服务(也可以启动另一个实例服务管理备份的数据目录);
-bash-4.2$ pg_ctl stop -D /var/lib/pgsql/11/data/ -
使用备份的数据目录启动实例服务;
-bash-4.2$ pwd /var/lib/pgsql -bash-4.2$ tar xzf backup.tar.gz -bash-4.2$ /usr/pgsql-11/bin/pg_ctl start -D ./var/lib/pgsql/11/data/
使用冷备份执行的还原只能恢复到备份点时的状态,备份点到故障点之间的任何修改都不会恢复。另外,还原时不会重新创建软链接,而是直接使用备份时的生成数据目录。
在线备份
对于前面介绍的逻辑备份和物理冷备份,都是基于一个时间点的备份,还原时只能恢复到该时间点。这些备份的一个主要缺点就是无法恢复备份点之后的数据变更。为了实现完全的数据恢复,确保不丢失任何变更和数据,PostgreSQL 提供了在线增量备份的功能。
PostgreSQL 对于数据的修改,都会写入一个称为预写式日志(WAL)的文件中,该文件位于数据目录的 pg_wal(pg_xlog)子目录中。当系统出现故障需要恢复时,可以通过重做最后一次检查点(checkpoint)以来的 WAL 日志执行数据库的恢复。基于这个机制,我们可以先创建一个文件级别的完全备份,然后不断备份生成的 WAL 文件,达到增量备份的效果。这些备份操作都可以在线执行,因此对于无法接受停机的业务系统至关重要。
预写式日志(Write-Ahead Logging)是实现可靠性和数据完整性的标准方法,同时还能减少磁盘 IO 的操作,提高数据库的性能。可以参考官方文档。
归档日志模式
对于在线备份而言,数据库集群处于运行状态,而且必须使用归档日志模式(Archive Log)运行,这样才能不断备份(归档)生成的 WAL 日志文件。因此,我们首先来设置 WAL 归档。
启用 PostgreSQL 的 WAL 归档需要在 postgresql.conf 文件中配置三个参数:
- wal_level,决定写入 WAL 的信息量。可选值为 minimal、replica 以及 logical,默认值为 replica。启用 WAL 归档需要设置为 replica 或更高配置。在 PostgreSQL 9.6 之前的版本中,还允许设置为 archive 和 hot_standby。仍然可以设置这两个值, 但它们直接映射到 replica。
- archive_mode,是否启动日志归档。默认值为 off。如果设置为 on 或者 always,可以通过设置下面的归档命令参数 archive_command 执行已完成的 WAL 段文件的归档操作。
- archive_command,执行日志归档操作的脚本命令。例如操作系统的 cp 命令。
修改 postgresql.conf 文件,添加以下内容:
wal_level = replica
archive_mode = on
archive_command = 'test ! -f /var/lib/pgsql/wal_archive/%f && cp %p /var/lib/pgsql/wal_archive/%f'
archive_timeout = 300
在 archive_command 中使用了两个占位符, %p 代表要归档的日志文件路径名称(相对于当前工作目录,即数据目录的文件名),%f 代表要归档的日志文件名(不包含路径)。如果需要在命令中使用 % 符号,可以使用两个连写的 %% 表示。以上命令会在执行时生成许多类似下面的实际操作:
test ! -f /var/lib/pgsql/wal_archive/000000010000000000000001 && cp pg_wal/000000010000000000000001 /var/lib/pgsql/wal_archive/000000010000000000000001
我们还需要提前创建好 /var/lib/pgsql/wal_archive 目录,并且确保 PosgtreSQL 实例的管理用户(默认为 postgres)具有该目录的读写权限。
PosgtreSQL 只会针对已经完成的 WAL 段进行归档操作,而 archive_timeout 确保了即使某个 WAL 日志长时间没有填满(业务不繁忙),最多 5 分钟之后,它也会被归档。需要注意的是,未完成的 WAL 大小也是一样大;因此,过小的 archive_timeout 可能会导致生成大量的 WAL 文件。
以上参数的修改需要重新启动 PostgreSQL 实例服务:
-bash-4.2$ pg_ctl restart
每过 5 分钟(archive_timeout),就会产生一次 WAL 段文件的切换,同时对该文件进行归档。也可以使用pg_switch_wal函数执行手动切换。
postgres=# select * from pg_switch_wal();
pg_switch_wal
---------------
0/40001C8
(1 row)
PosgtreSQL 提供了一个视图pg_stat_archiver,用于查看 WAL 归档状态:
postgres=# select * from pg_stat_archiver;
archived_count | last_archived_wal | last_archived_time | failed_count | last_failed_wal | last_failed_time | stats_rese
t
----------------+--------------------------+-------------------------------+--------------+--------------------------+-------------------------------+--------------------
-----------
4 | 000000010000000000000004 | 2019-03-25 22:36:16.462352-04 | 0 | | | 2019-01-04 16:57:12.471428-05
(1 row)
至此,我们完成的 WAL 归档的设置和验证。
下一步就是执行基准备份了,基准备份是一个全量备份。执行基准备份最简单的方法就是使用pg_basebackup工具,它也可以用于流复制结构中的从节点初始化,我们在下一章进行介绍。这里我们使用另外一种创建备份的方式,即调用两个系统函数:pg_start_backup()和pg_stop_backup()。
首先,调用 pg_start_backup() 函数开始一个备份:
postgres=# SELECT pg_start_backup('basebackup20190328');
pg_start_backup
-----------------
0/2E000060
(1 row)
其中的参数‘basebackup20190328’是本次备份的标识。该函数会在集群的数据目录中创建一个名称为 backup_label 的备份标签文件,记录本次备份的相关信息,包括起始时间和备份标识。另外,如果存在自定义的表空间,还会创建一个表空间映射文件,名称为 tablespace_map,记录 pg_tblspc/ 中的表空间符号链接的信息。这两个文件对于备份的完整性至关重要。
这种备份方式是排他性的备份,当前备份执行的过程中不允许运行其他备份。在 PostgreSQL 9.6 之后,支持非排他性的备份方式,参考官方文档。
执行完以上命令之后,PostgreSQL 会进入备份模式,然后就可以使用操作系统命令(cp、tar、rsync 等)复制数据目录:
-bash-4.2$ cp -r /var/lib/pgsql/11/data/ /var/lib/pgsql/11/backups/basebackup20190328/
-bash-4.2$ ls /var/lib/pgsql/11/backups/basebackup20190328/
backup_label global pg_dynshmem pg_logical pg_replslot pg_stat pg_tblspc pg_wal postgresql.conf tablespace_map
base log pg_hba.conf pg_multixact pg_serial pg_stat_tmp pg_twophase pg_xact postmaster.opts
current_logfiles pg_commit_ts pg_ident.conf pg_notify pg_snapshots pg_subtrans PG_VERSION postgresql.auto.conf postmaster.pid
此时的文件备份可能不是一致性备份,因为备份的同时某些文件可能会被修改。但是这些不一致性可以通过 WAL 日志重放进行恢复,就像发生系统故障时的恢复一样。
最后,调用 pg_stop_backup() 函数结束备份:
postgres=# SELECT pg_stop_backup();
NOTICE: pg_stop_backup complete, all required WAL segments have been archived
pg_stop_backup
----------------
0/2E000168
(1 row)
该函数将会终止备份模式,并且执行一次 WAL 段文件切换。切换文件是为了准备归档备份过程中写入过的最后一个 WAL 段。该函数返回了一些关于此次备份的信息。另外,PostgreSQL 还会在 pg_wal(pg_xlog)目录中生成一个 ‘wal-segement-number.backup’ 文件(00000001000000000000002E.00000060.backup),其中存储了本次备份的历史信息。
一旦完成最后的 WAL 段文件归档,备份过程就结束了。pg_stop_backup 返回的结果就是组成一个完整备份所需的最后一个段文件。如果启用了 archive_mode,pg_stop_backup 将会等待最后一个 WAL 段文件归档后才返回。
PostgreSQL 没有提供备份目录(backup catalog)的功能,用于记录这些备份历史信息。但是某些第三方工具(例如 Barman)提供了这些高级功能。
时间点恢复
有了基准备份和连续的 WAL 归档,再加上当前使用的 WAL 段文件,PostgreSQL 可以恢复到最新的状态。不仅如此,我们还可以通过 WAL 回放到上次备份以来的任意时间点,也就是时间点恢复(Point-in-Time Recovery)。
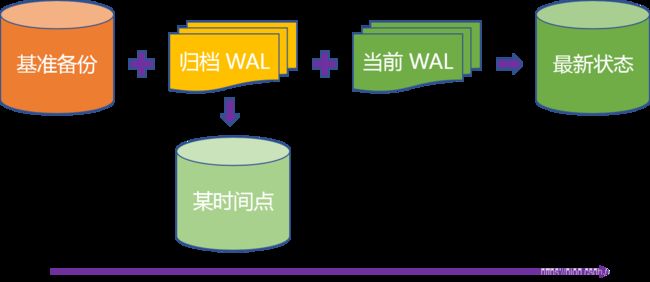
接下来我们基于上面的备份执行一次恢复操作。开始之前创建一个测试表:
postgres=# \c testdb
You are now connected to database "testdb" as user "postgres".
testdb=# create table t1(id int,v varchar(10));
CREATE TABLE
testdb=# insert into t1(id, v) values(1, 'pg');
INSERT 0 1
这个表是在备份之后创建的,只有恢复到最新状态才能看到。
首先,我们模仿系统故障,直接关闭服务器进程,并且删除数据目录中的文件(需要保留 pg_wal 子目录,因为完全恢复需要使用当前还未归档的 WAL 文件)。
-bash-4.2$ ps -ef|grep /usr/pgsql-11/bin/postgres
postgres 6471 32086 0 02:46 pts/1 00:00:00 grep --color=auto /usr/pgsql-11/bin/postgres
postgres 32313 1 0 Mar25 pts/1 00:00:16 /usr/pgsql-11/bin/postgres -D /var/lib/pgsql/11/data/
-bash-4.2$ kill -9 32313
-bash-4.2$ ps -ef|grep postgres
postgres 7058 32086 0 02:48 pts/1 00:00:00 ps -ef
postgres 7059 32086 0 02:48 pts/1 00:00:00 grep --color=auto postgres
root 32083 7880 0 Mar25 pts/1 00:00:00 su - postgres
postgres 32086 32083 0 Mar25 pts/1 00:00:01 -bash
-bash-4.2$ mkdir /var/lib/pgsql/11/data_old
-bash-4.2$ mv /var/lib/pgsql/11/data/* /var/lib/pgsql/11/data_old
如果此时尝试重启 PostgreSQL 服务进程,提示目录不是数据库集群目录:
-bash-4.2$ pg_ctl start
pg_ctl: directory "/var/lib/pgsql/11/data" is not a database cluster directory
还原前面执行的基准备份,需要注意的是使用数据库的拥有者(postgres)执行操作。如果使用了自定义的表空间,确认 pg_tblspc 子目录中的符号链接正确还原:
-bash-4.2$ cp -R /var/lib/pgsql/11/backups/basebackup20190328/* /var/lib/pgsql/11/data/
-bash-4.2$ ls /var/lib/pgsql/11/data/pg_tblspc/ -l
total 0
lrwxrwxrwx. 1 postgres postgres 23 Mar 28 03:21 16558 -> /var/lib/pgsql/tony_tbs
删除还原的 pg_wal 子目录中的文件,这些文件是在执行基准备份时复制生成的,对于恢复没有作用。
-bash-4.2$ rm -rf /var/lib/pgsql/11/data/pg_wal/*
将前面保留的未归档的 WAL 段文件复制到 pg_wal 子目录(最好使用复制,而不是移动文件,这样的话在恢复失败后还可以重新尝试)。
-bash-4.2$ cp -R /var/lib/pgsql/11/data_old/pg_wal/* /var/lib/pgsql/11/data/pg_wal/
在数据目录中创建一个恢复命令文件 recovery.conf,配置以下参数:
restore_command = 'cp /var/lib/pgsql/wal_archive/%f %p'
#recovery_target_time = "2019-3-28 12:05 GMT"
restore_command 用于指定还原归档 WAL 文件的命令,基本上与 archive_command 的设置相反。recovery_target_time 用于设置恢复目标,即恢复到哪个时间点。PostgreSQL 支持多种恢复目标的设置,默认为恢复到最新的状态。详细的参数介绍可以参考官方文档。
为了防止恢复期间的用户连接,可以临时修改 pg_hba.conf 文件,拒绝远程客户端的连接请求,等到恢复成功时再修改回来。
最后,重启 PostgreSQL 服务器进程:
-bash-4.2$ pg_ctl start
waiting for server to start....2019-03-28 22:21:26.231 EDT [31505] LOG: listening on IPv4 address "192.168.56.103", port 5432
2019-03-28 22:21:26.234 EDT [31505] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-03-28 22:21:26.238 EDT [31505] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-03-28 22:21:26.252 EDT [31505] LOG: redirecting log output to logging collector process
2019-03-28 22:21:26.252 EDT [31505] HINT: Future log output will appear in directory "log".
done
server started
启动服务器时,会使用恢复模式,并且读取归档的 WAL 文件以及未归当的 WAL 文件。恢复完成后,服务器会将 recovery.conf 文件重命名为 recovery.done,将 backup_label 文件重命名为 backup_label.old。这样可以防止再次启动时进入恢复模式。最后,数据库将会进入正常操作模式。
我们验证一下数据库中的表 t1 是否成功恢复:
testdb=# select * from t1;
id | v
----+-----
1 | pg
(1 rows)
如果在恢复之前限制了客户端的连接,现在可以还原 pg_hba.conf 文件中的配置。
除此之外,PostgreSQL 还支持时间线(Timelines)恢复,具体内容可以参考官方文档。
前面提到,基于连续的 WAL 归档技术,如果在另外一台服务器上使用相同的基准备份启动数据库集群,并且不断应用这些归档日志,可以构建一个主从复制的体系结构。这种结构可以提供数据库集群级别的高可用性(HA),PostgreSQL 9.0 引入的流复制支持从节点上的只读操作(read-only),可以承担部分查询的负载。我们将在第 IV 部分介绍相关内容。
下一篇,我们开始学习 SQL(结构化查询语言),它是关系数据库的通用语言。
人生本来短暂,你又何必匆匆!点个赞再走吧!