ImageNet和CNN可以帮助医学图像的识别吗?
从ImageNet和CNN说起
图像的分类和识别一直是计算机视觉的热门研究领域,在医学图像领域,很多方法也都是从计算机视觉领域借鉴过来的,而计算机视觉的许多方法又离不开机器学习和人工智能的基础。
在典型的图像分类和识别问题中,通常有两个重要的步骤,一个是特征提取,常见的有GLCM, HOG, LBP, Haar Wavelet, 一个是分类器, 例如SVM, Random Forest, Neuron Network等。特征提取过程中通常是人工选取某些特征,但是难以确定这些特征是否真正准确地描述了不同类别的差异,怎样才能得到最好的特征呢?
于是卷积神经网络应运而生。其思想是通过一些卷积层的参数来描述特征,这些参数的值不是人工设定,而是通过大量的训练数据通过训练自动得到。再配合传统的Neuron Network可以同时训练特征的参数和分类器的参数。这就是卷积神经网络(Convolution Neuron Network, CNN)。下图简要归纳了它的结构与传统Neuron Network的联系与区别。 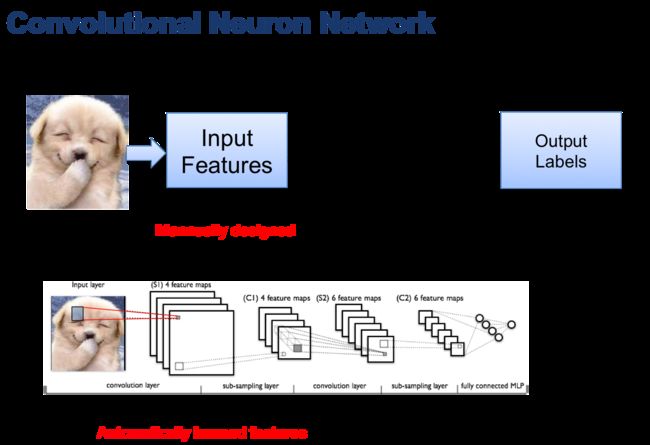
CNN的成功主要起源于它在ImageNet大规模视觉识别挑战赛(ILSVRC)上的成就。ImageNet是一个斯坦福大学Fei-fei Li教授发起的图像数据库,包含120万以上的训练数据和1000种不同的类别,其识别一直比较困难,直到2012年AlexNet的提出,从此以后几乎每年ILSVRC的赢家都使用了CNN,相比以往的方法大幅提高了识别的准确率。 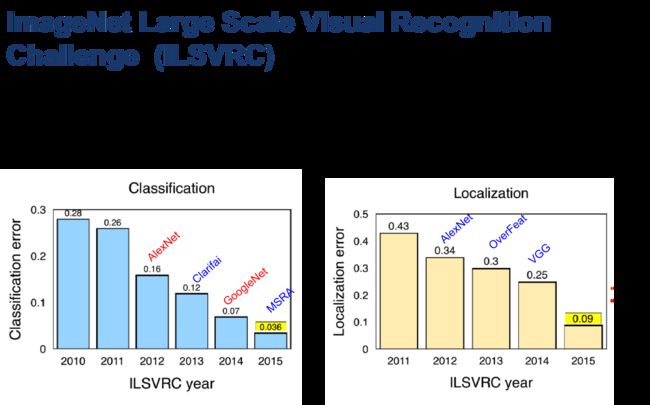
CNN在ImageNet上的成功源于三个主要因素:一是大规模的训练数据。二是更为复杂的模型(CNN)。网络结构更加复杂,更深,参数更多。三是GPU对计算的加速,使以往需要数周的训练过程只需一天甚至数小时以内就可以完成。
医学图像识别的问题
如果将CNN应用于医学图像,首要面对的问题是训练数据的缺乏。因为CNN的训练数据都需要有类别标号,这通常需要专家来手工标记。要是标记像ImageNet这样大规模的上百万张的训练图像,简直是不可想象的。
因为CNN的参数多,必须依靠大规模的训练数据才能防止过度拟合(Over Fitting)。在数据量少的情况下,有两种解决方案:一个叫Data Augmentation。就是依赖现有的图像,通过旋转,平移,变形等变化,产生更多的图像。二是使用转移学习(Transfer Learning)。其思想是通过在另一种大规模的数据集上面训练,得到CNN的参数作为初始值,再在目标数据集上训练对参数进行调优(Fine-tuning)。
转移训练的原理是某些特征在不同的训练数据集上是具有通用性的。对于CNN而言,其第一层是提取局部的特征,在后续层通过下采样扩大感知区域, 再往后的层感知区域更大,得到的特征也更加抽象。在前几层的特征通常并不与某一个具体的分类任务直接相关,而是类似于Gabor Filter, 边缘,与方向有关的特征等。这些特征都是比较通用的,因此可以在一个数据集上训练得到而应用在一个与之类似的数据集上。当然,如果训练出的特征对某个训练数据集或者识别任务具有特异性,用它做转移学习就未必有好的效果。
对于医学图像而言,得到大规模的训练数据是比较不容易的,那么可否使用Transfer Learning利用现成的ImageNet的图像来帮助医学图像的识别呢?ImageNet里面的图像(二维,彩色)没有医学图像,包含一些诸如鸟类、猫、狗、直升机等物体的识别,与医学图像(二维或三维,非彩色)相差很大。如果回答是肯定的话,是一件令人非常振奋的事情。
使用ImageNet做转移学习的效果
在NIH的Hoo-Chang Shin ; Holger R. Roth等人最近的一篇文章中研究了这个问题(下载链接)。其全名为:Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning。
该文章除了研究上述问题,还比较了CifarNet (2009年), AlexNet(2012年)和GoogleNet(2014年)这三个一个比一个复杂的网络结构在不同的训练数据量的情况下的性能。这三个网络的结构简图如下: 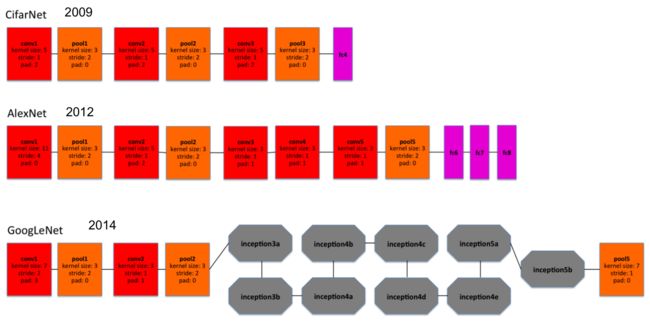
该文章研究的医学图像应用为CT图像中胸腹部淋巴结(三维)的检测和肺部疾病的分类(二维)。如何让彩色二维图像与医学图像相结合呢?该文采用了两个小技巧: 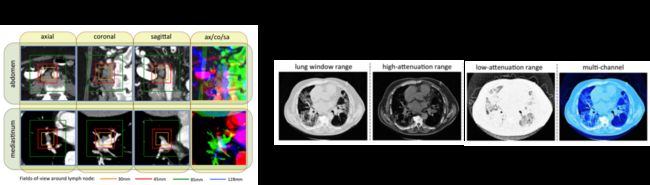
对于三维CT图像,将通过某一点的冠状面、矢状面和横断面的三个二维图像组合在一起,作为RGB的三个通道,使之与彩色图像兼容。对二维CT图像,分别采用三种不同的CT灰度窗口,得到三张图像,组合成彩色图像。 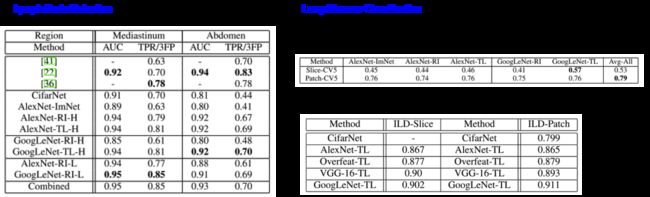
实验的结果如上图。可以看出,在不使用Transfer Learning的情况下(Random Initialization, RI),AlexNet虽然比GoogleNet简单,但是效果比GoogleNet好,这是因为GoogleNet参数太多,训练数据不够导致过度拟合,使其泛化能力下降,从而分类精度降低。使用了Transfer Learning (TL)后,GoogleNet的性能提高很多,效果比AlexNet要好。
Random Initialization和Transfer Learning 在训练过程中的性能比较如下图: 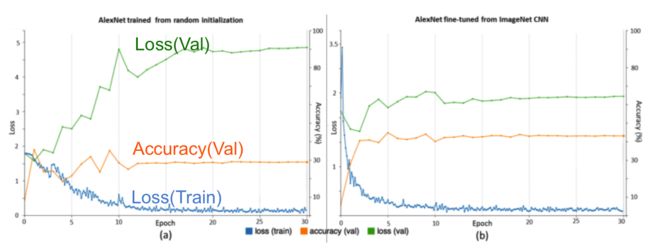
可见Transfer Learning减少了测试数据上的误差,提高了分类的准确率。
再来看看Transfer Learning学到了那些特征: 
上图显示了在CNN的第一层中学习到的特征。可以看出在不使用Transfer Learning的情况下,单从CT图像上学习到的特征都表现出比较模糊的样子,而使用Transfer Learning的CNN相应的特征中包含一些和边缘有关的特征,这些实际上是从ImageNet中学习过来的,但有助于CT图像的分类和识别。