Spark环境搭建与入门实例
1目的及要求
基于Spark平台,使用Spark ML库实现数据聚类分析。使用Synthetic Control Chart Time Series数据synthetic_control.data,数据包括600个数据点(行),每个数据点有60个属性,详细信息见:
http://archive.ics.uci.edu/ml/databases/synthetic_control/
目标:将600个数据点聚为多个类,默认输出为8个类。输入文件为synthetic_control.data,编写Spark分析算法实现600个点的聚类,输出8个聚类质点及包含的点。
2实验环境
本实验基于虚拟机环境,所采用的软件及其版本如下:
虚拟机软件:Oracle VirtualBox 5.2.6
虚拟机操作系统:Ubuntu 16.04.1 LTS - 64 bit
Java环境:JDK-1.8
Maven工具:Maven 3.5.4
Spark平台:spark-2.1.2-bin-hadoop2.7
3实验内容与步骤
3.1实验环境搭建
3.1.1搭建Java开发环境
1)键入如下命令将jdk软件包解压至指定目录:
tar -zxvf jdk-8u181-linux-x64.tar.gz -C your_java_home
2)键入如下命令编辑profile文件:
sudo vim /etc/profile
设置jdk环境变量,在profile文件的末尾添加如下内容:
export JAVA_HOME=your_java_home
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
需要注意的是,设置CLASSPATH环境变量时,等号后面有个点,代表当前目录。
3)键入如下命令,让环境变量立即生效:
source /etc/profile
4)检查jdk是否安装好,键入如下命令:
java -version
结果如下图所示:

3.1.2搭建Spark环境
Spark也有多种运行模式,现简单介绍如下:
Local模式:本地单线程方式运行,主要用于开发调试Spark应用程序;
Standalone模式:利用Spark自带的资源管理与调度器运行Spark集群,采用Master/Slave结构。若想避免单点故障可以采用ZooKeeper实现高可靠性(High Availiabilty);
Mesos模式:基于资源管理框架Apache Mesos,该集群运行模式将资源管理交给Mesos,Spark只负责任务调度与计算;
YARN模式:基于Hadoop资源管理器Yarn,资源管理交给Yarn而Spark只负责任务调度与计算部分。该模式将Spark与Hadoop生态圈结合起来,在实际应用中较为流行。
这里搭建的是Standalone模式,过程如下:
1)键入如下命令将Spark软件包解压至指定目录:
tar -zxvf spark-2.1.2-bin-hadoop2.7.tar.gz -C your_spark_home
2)键入如下命令,给spark添加环境变量:
vim your_spark_home/conf/spark-env.sh
在spark-env.sh文件中添加的环境变量如下图所示:

3)修改spark配置文件
键入如下命令,修改slave配置文件:
vim your_spark_home/conf/slaves
在slaves配置文件中添加一行内容localhost,如下图:

4)键入如下命令,启动spark:
your_spark_home/sbin/start-all.sh
启动完毕后,使用jps命令可以查看当前运行的Java进程,如下图所示:
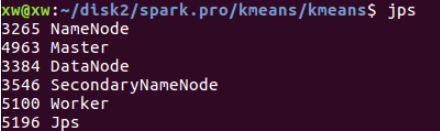
可看到多了Master和Worker两个进程,剩余的进程是Hadoop进程,由于使用了HDFS,故预先启动了Hadoop。
Spark启动后,在浏览器中输入如下地址,可以进入spark的管理界面:
http://localhost:8080/
如下图所示:
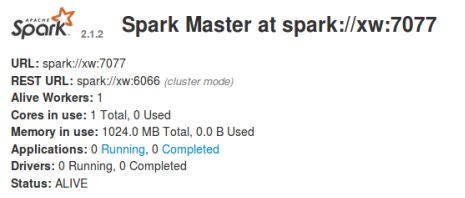
3.2实验步骤
1)准备可执行jar文件
根据实验要求,使用Java语言编写程序,这里使用了Java平台上流行的项目管理工具Maven来构建Spark程序。
首先使用如下命令生成一个项目框架:
mvn archetype:generate -DgroupID=kmeans -DartifactID=kmeans
然后在生成的kmeans/kmeans/src/main/java/kmeans文件夹下编写Java程序源文件kmeans.java。
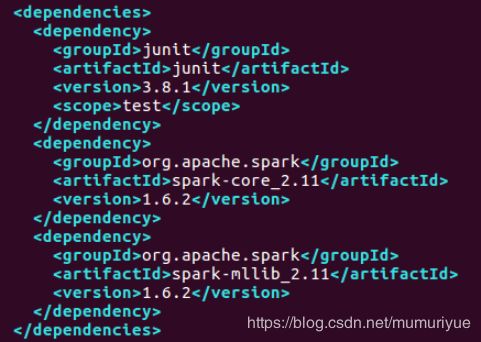
由于使用了Spark的类库,在pom.xml文件中添加项目依赖,如下图所示:
程序编写完成后,使用如下命令编译项目:
mvn compile
编译完成后,使用如下命令将程序进行打包:
mvn package
将在target目录生成kmeans-1.0-SNAPSHOT.jar文件。
2)上传输入文件到HDFS
在hdfs启动后,首先在hdfs中创建目录:
your_hadoop_path/bin/hdfs dfs -mkdir -p /kmeans/input
然后使用如下命令将欲处理的文件上传到hdfs:
your_hadoop_path/bin/hdfs dfs -put synthetic_control.txt /kmeans/input
3)执行程序
在准备好可执行jar文件和待处理的输入文件后,首先程序至spark平台运行:
your_spark_path/bin/spark-submit --class kmeans.kmeans --master local target/kmens-1.0-SNAPSHOT.jar
4实验结果与数据处理
4.1 Spark ML库
本实验的目的是使用Spark ML库实现600个数据点的聚类分析,首先对Spark ML库进行介绍。
Spark ML库提供了常用机器学习算法的实现,包括聚类,分类,回归,协同过滤,维度缩减等。通过使用ML库,可以让基于海量数据的机器学习变得更加简单,开发者无需自己实现常用的机器学习算法,只需有Spark基础并且了解机器学习算法的原理,通过选取相关参数并调用相应的 API 就可以实现基于海量数据的机器学习过程。
因为通常情况下机器学习算法参数学习的过程都是迭代计算的,即本次计算的结果要作为下一次迭代的输入,这个过程中,如果使用MapReduce,我们只能把中间结果存储到磁盘,然后在下一次计算的时候重新读取,显而易见这会影响迭代算法的效率。由于Spark基于内存进行计算,故天然地适应于迭代式计算。
4.2 K-means 聚类算法
聚类分析是一个无监督学习过程, 一般是用来对数据对象按照其特征属性进行分组,经常被应用在客户分群,欺诈检测,图像分析等领域。
K-means 算法也是一个迭代式的算法,其主要步骤如下:
第一步,选择 K 个点作为初始聚类中心。
第二步,计算其余所有点到聚类中心的距离,并把每个点划分到离它最近的聚类中心所在的聚类中去。在这里,衡量距离一般有多个函数可以选择,最常用的是欧几里得距离 (Euclidean Distance), 也叫欧式距离。
第三步,重新计算每个聚类中所有点的平均值,并将其作为新的聚类中心点。
最后,重复 (二),(三) 步的过程,直至聚类中心不再发生改变,或者算法达到预定的迭代次数,又或聚类中心的改变小于预先设定的阀值。
在实际应用中,K-means算法中聚类个数K的选择往往要依赖于对待处理数据集背景知识的了解,本实验中预先指定了聚类个数为8,因此不需再对数据集进行提前处理。
4.3实验结果
程序提交至Spark平台运行后,会在终端中打印出很多程序运行信息,提交的用户程序的输出也夹杂在其中,输出的聚类质点如下图所示:
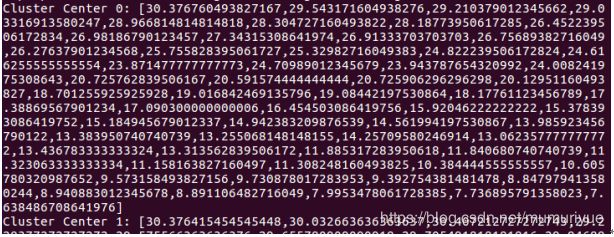
聚类质点共8个,图中的是其中一个聚类质点的信息。