(图文详细)云计算与大数据实训作业答案(之篇三HDFS和MapReduce实训 )
-
- HDFS和MapReduce实训
-
- 第1关:WordCount词频统计
- 第2关:HDFS文件读写
- 第3关:倒排索引
- 第4关: 网页排序——PageRank算法
-
- HDFS和MapReduce实训
HDFS和MapReduce实训
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,可以在不了解分布式底层细节的情况下,开发分布式程序,以满足在低性能的集群上实现对高容错,高并发的大数据集的高速运算和存储的需要。Hadoop支持超大文件(可达PB级),能够检测和快速应对硬件故障、支持流式数据访问、同时在简化的一致性模型的基础上保证了高容错性。因而被大规模部署在分布式系统中,应用十分广泛。
本实训的主要目标是让大家学习Hadoop的基本概念如MapReduce、HDFS等,并掌握Hadoop的基本操作,主要包括MapReduce编程(词频统计)、HDFS文件流读取操作、MapReduce迭代等。通过本次实训,建立起对Hadoop云计算的初步了解,后续大家可以通过进阶学习来深入学习Hadoop内部实现机制进行高级的应用开发。
第1关:WordCount词频统计
本关任务
词频统计是最能体现MapReduce思想的程序,结构简单,上手容易。
词频统计的大致功能是:统计单个或者多个文本文件中每个单词出现的次数,并将每个单词及其出现频率按照
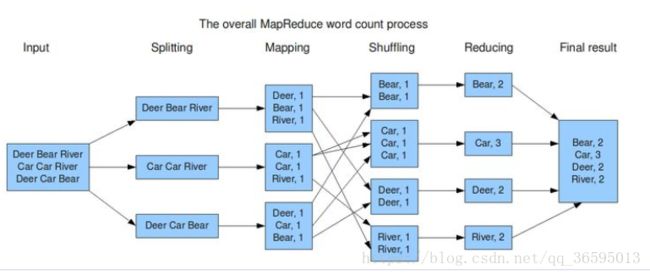
由图可知:
- 输入文本(可以不只一个),按行提取文本文档的单词,形成行 ⟨k1,v1⟩ ⟨ k 1 , v 1 ⟩ 键值 对具体形式很多,例如 ⟨行数,字符偏移⟩ ⟨ 行 数 , 字 符 偏 移 ⟩ 等;
- 通过Spliting将 ⟨k1,v1⟩ ⟨ k 1 , v 1 ⟩ 细化为单词键值对 ⟨k2,v2⟩ ⟨ k 2 , v 2 ⟩ ;
- Map分发到各个节点,同时将 ⟨k2,v2⟩ ⟨ k 2 , v 2 ⟩ 归结为list( ⟨k2,v2⟩ ⟨ k 2 , v 2 ⟩ );
- 在进行计算统计前,先用Shuffing将相同主键k2归结在一起形成 ⟨k2,list(v2)⟩ ⟨ k 2 , l i s t ( v 2 ) ⟩ ;
- Reduce阶段直接对 ⟨k2,list(v2)⟩ ⟨ k 2 , l i s t ( v 2 ) ⟩ 进行合计得到list ⟨(k3,v3)⟩ ⟨ ( k 3 , v 3 ) ⟩ 并将结果返回主节点。
主节点对预设文本文档进行词频统计,并将最终结果输出。
- 注:输入和输出事先已经预定,只要比较输出是否达到预期即可判断是否达到要求。
- 注:MapReduce处理的数据集必须可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。不是关系型数据库,而是结构化的。
- 通过Text对象,获取文本文档的内容。
- 逐行处理文档,将单词提取出来。
- 每个单词为key,对应的value设为1,将 ⟨k2,v2⟩ ⟨ k 2 , v 2 ⟩ 对输出。
-
- **关键性说明:**
- map阶段的处理,主要是如何对文本进行逐行的单词分割,从而获取单词,以及将键值对分发到各个节点(此处由hadoop隐性提供,用户先不必关心hdfs存储过程)。
- 可以参考的单词分割提取代码模板如下:
- **关键性说明:**
public void map(Object key,Text value,Context context)throws IOException,InterruptedException
{
//对文本内容对象value进行分割
StringTokenizer itr=new StringTokenizer(valu e.toString());
while(itr.hasMoreTokens()) {
String word=itr.nextToken();/*获取分割好的单词*/
/*
可以在该循环体中,使用获取好的单词word变量进行key和value的设定。
*/
}
}- 在各个节点并行循环统计每个单词出现的次数。
- 将各个节点的结果汇总以list( ⟨k3,v3⟩ ⟨ k 3 , v 3 ⟩ )的形式输出。
public void reduce(Object key,Iterable values,Context context)throws IOException, InterruptedException
{
int count=0;
for(IntWritable itr:vlaues)
{
count+=itr.get(); /*循环统计*/
}
/*统计完成后,将结果输出.....*/
}
编程要求
本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
- 在主函数main中已初始化 hadoop 的系统设置,包括hadoop运行环境的连接。
- 在main函数中,已经设置好了待处理文档路径(即input),以及结果输出路径(即output)。
- 在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
- 本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
测试说明
以下是测试样例:
测试输入样例数据集:文本文档 test1.txt 和 test2.txt
文档test1.txt中的内容为:
tale as old as time
true as it can be
beauty and the beast
文档test2.txt中的内容为:
ever just the same
ever as before
beauty and the beast
预期输出result.txt文档中的内容为:
and 2
as 4
beast 2
beauty 2
before 1
can 1
ever 2
it 1
just 1
old 1
same 1
tale 1
the 3
time 1
true 1
注:由于启动服务、编译等耗时,以及MapReduce过程资源消耗较大,评测时间较长(30s左右)!
请耐心等待!相信自己!通往成功的路上不会太久!
建议完成本关后尝试在本机上根据相关指导搭建环境运行程序,这样理解更深刻!
合抱之木,生于毫末;九层之台,起于累土!复杂源于简单,要想铸就高楼大厦必须打牢基础!
开始你的任务吧,祝你成功!
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/*
* MapReduceBase类:实现Mapper和Reducer接口的基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类要实现此接口。
*/
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/*
*LongWritable,IntWritable,Text是Hadoop中实现的用于封装Java数据类型的类,这些类实现了WritableComparable接口,
*都能够被串行化,便于在分布式环境中进行数据交换,可以视为long,int,String数据类型的替代。
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();//Text实现了BinaryComparable类,可以作为key值
/*
* Mapper接口中的map方法:
* void map(K1 key, V1 value, OutputCollector output, Reporter reporter)
* 映射一个单个的输入对到一个中间输出对
* 中间输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* OutputCollector接口:收集Mapper和Reducer输出的对。
* OutputCollector接口的collect(k, v)方法:增加一个(k,v)对到output
* Reporter 用于报告整个应用的运行进度
*/
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
/*
* 原始数据(以test1.txt为例):
* tale as old as time
true as it can be
beauty and the beast
map阶段,数据如下形式作为map的输入值:key为偏移量
<0 tale as old as time>
<21 world java hello>
<39 you me too>
*/
/**
* 解析(Spliting)后以得到键值对(仅以test1.txt为例)
* 格式如下:前者是键值,后者数字是值
* tale 1
* as 1
* old 1
* as 1
* time 1
* true 1
* as 1
* it 1
* can 1
* be 1
* beauty 1
* and 1
* the 1
* beast 1
* 这些键值对作为map的输出数据
*/
//****请补全map函数内容****//
/*********begin*********/
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
/*********end**********/
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
/*
* reduce过程是对输入键值对洗牌(Shuffing)形成格式数据(仅以test1.txt为例):
* (tablie [1])
* (as [1,1,1])
* (old [1])
* (time [1])
* (true [1])
* (it [1])
* (can [1])
* (be [1])
* (beauty [1])
* (and [1])
* (the [1])
* (beast [1])
* 作为reduce的输入
*
*/
public void reduce(Text key, Iterable values,
Context context
) throws IOException, InterruptedException {
//****请补全reduce对 进行合计得到list()过程****//
/*********begin*********/
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
/*********end**********/
//****请将list()统计输出****//
/*********begin*********/
result.set(sum);
context.write(key, result);
/*********end**********/
}
}
public static void main(String[] args) throws Exception {
/**
* JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作
* 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等
*/
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
/*
* 需要配置输入和输出的HDFS的文件路径参数
* 可以使用"Usage: wordcount "实现程序运行时动态指定输入输出
*/
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount " );
System.exit(2);
}
Job job = new Job(conf, "word count");//Job(Configuration conf,String jobName)设置job名称
job.setJarByClass(WordCount.class);//为job设置Mapper类
/*********begin*********/
//****请为job设置Mapper类****//
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);//为job设置Combiner类
//****请为job设置Reduce类****//
job.setReducerClass(IntSumReducer.class);
//****请设置输出key的参数类型****//
job.setOutputKeyClass(Text.class);
//****请设置输出value的类型****//
job.setOutputValueClass(IntWritable.class);
/*********end**********/
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));//为map-reduce任务设置InputFormat实现类,设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为map-reduce任务设置OutputFormat实现类,设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
第2关:HDFS文件读写
Hadoop分布式文件系统(HDFS)是hadoop上部署的存储架构。有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。为了熟练应用hadoop,必须对HDFS文件进行创建和读写等操作。
本关任务
利用HDFS文件系统开放的API对HDFS系统进行文件的创建和读写
要求:
1. 在HDFS的路径/user/hadoop/下新建文件myfile,并且写入内容“china cstor cstor cstor china”; 2. 输出HDFS系统中刚写入的文件myfile的内容
相关知识
HDFS文件系统
HDFS设计成能可靠地在集群中大量机器之间存储大量的文件,它以块序列的形式存储文件。文件中除了最后一个块,其他块都有相同的大小(一般64M)。属于文件的块为了故障容错而被复制到不同节点备份(备份数量有复制因子决定)。块的大小和读写是以文件为单位进行配置的。HDFS中的文件是一次写的,并且任何时候都只有一个写操作,但是可以允许多次读。
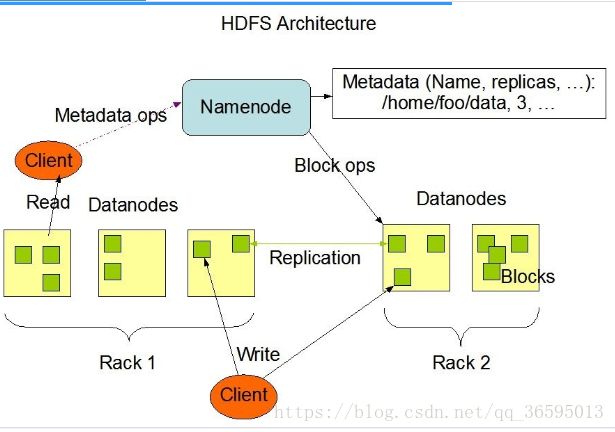
创建HDFS文件

- 客户端通过在DistributedFileSystem中调用create()来创建文件。
- DistributedFileSystem 使用RPC去调用namenode,在文件系统的命名空间创一个新的文件,没有块与之相联系。namenode执行各种不同的检查以确保这个文件不会已经存在,并且在client有可以创建文件的适当的许可。如果检查通过,namenode就会生成一个新的文件记录;否则,文件创建失败并向client抛出一个IOException异常。分布式文件系统返回一个文件系统数据输出流,让client开始写入数据。就像读取事件一样,文件系统数据输出流控制一个DFSOutputStream,负责处理datanode和namenode之间的通信。
- 在client写入数据时,DFSOutputStream将它分成一个个的包,写入内部队列,称为数据队列。数据流处理数据队列,数据流的责任是根据适合的datanode的列表要求namenode分配适合的新块来存储数据副本。这一组datanode列表形成一个管线————假设副本数是3,所以有3个节点在管线中。
- 数据流将包分流给管线中第一个的datanode,这个节点会存储包并且发送给管线中的第二个datanode。同样地,第二个datanode存储包并且传给管线中的第三个数据节点。
- DFSOutputStream也有一个内部的数据包队列来等待datanode收到确认,称为确认队列。一个包只有在被管线中所有的节点确认后才会被移除出确认队列。如果在有数据写入期间,datanode发生故障, 则会执行下面的操作,当然这对写入数据的client而言是透明的。首先管线被关闭,确认队列中的任何包都会被添加回数据队列的前面,以确保故障节点下游的datanode不会漏掉任意一个包。为存储在另一正常datanode的当前数据块制定一个新的标识,并将该标识传给namenode,以便故障节点datanode在恢复后可以删除存储的部分数据块。从管线中删除故障数据节点并且把余下的数据块写入管线中的两个正常的datanode。namenode注意到块复本量不足时,会在另一个节点上创建一个新的复本。后续的数据块继续正常接收处理。只要dfs.replication.min的副本(默认是1)被写入,写操作就是成功的,并且这个块会在集群中被异步复制,直到其满足目标副本数(dfs.replication 默认值为3)。
- client完成数据的写入后,就会在流中调用close()。
- 在向namenode节点发送完消息之前,此方法会将余下的所有包放入datanode管线并等待确认。namenode节点已经知道文件由哪些块组成(通过Data streamer 询问块分配),所以它只需在返回成功前等待块进行最小量的复制。
读取HDFS文件
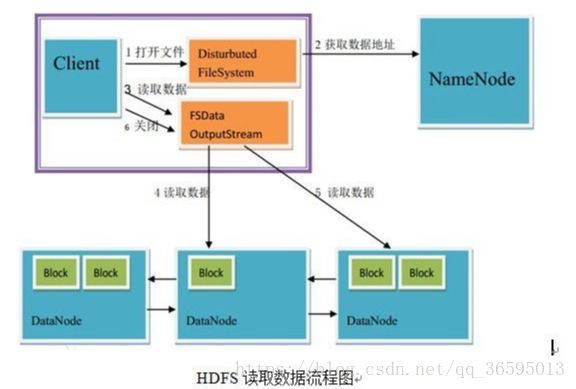
8. 客户端通过调用FileSystem对象的open()来读取希望打开的文件。对于HDFS来说,这个对象是分布式文件系统的一个实例。
9. DistributedFileSystem通过RPC来调用namenode,以确定文件的开头部分的块位置。对于每一块,namenode返回具有该块副本的datanode地址。此外,这些datanode根据他们与client的距离来排序(根据网络集群的拓扑)。如果该client本身就是一个datanode,便从本地datanode中读取。DistributedFileSystem 返回一个FSDataInputStream对象给client读取数据,FSDataInputStream转而包装了一个DFSInputStream对象。
10. 接着client对这个输入流调用read()。存储着文件开头部分块的数据节点地址的DFSInputStream随即与这些块最近的datanode相连接。
11. 通过在数据流中反复调用read(),数据会从datanode返回client。
12. 到达块的末端时,DFSInputStream会关闭与datanode间的联系,然后为下一个块找到最佳的datanode。client端只需要读取一个连续的流,这些对于client来说都是透明的。
13. 在读取的时候,如果client与datanode通信时遇到一个错误,那么它就会去尝试对这个块来说下一个最近的块。它也会记住那个故障节点的datanode,以保证不会再对之后的块进行徒劳无益的尝试。client也会确认datanode发来的数据的校验和。如果发现一个损坏的块,它就会在client试图从别的datanode中读取一个块的副本之前报告给namenode。
14. 这个设计的一个重点是,client直接联系datanode去检索数据,并被namenode指引到块中最好的datanode。因为数据流在此集群中是在所有datanode分散进行的。所以这种设计能使HDFS可扩展到最大的并发client数量。同时,namenode只不过提供块的位置请求(存储在内存中,十分高效),不是提供数据。否则如果客户端数量增长,namenode就会快速成为一个“瓶颈”。
HDFS文件流操作
HDFS文件还提供文件数据流操作API,利用这些可以将文件读取简化为三大步骤。
- 获取文件系统实例化创建文件
- 通过获取数据流进行写入,完成后关闭数据流
- 通过输出数据流将文件内容输出
- 获取文件系统
//读取hadoop文件系统配置
Configuration conf = new Configuration(); //实例化设置文件,configuration类实现hadoop各模块之间值的传递
FileSystem fs = FileSystem.get(conf); //是hadoop访问系统的抽象类,获取文件系统, FileSystem的get()方法得到实例fs,然后fs调动create()创建文件,open()打开文件
System.out.println(fs.getUri());
Path file = new Path(""); //命名一个文件及路径
if (fs.exists(file)) {
System.out.println("File exists.");
} else
{- 通过输入数据流进行写入
1. FSDataOutputStream outStream = fs.create(file); //获取文件流 2. outStream.writeUTF("XXXXXXXX"); //使用文件流写入文件内容- 通过输出数据流将文件内容输出
// FSDataInputStream实现了和接口,从而使Hadoop中的文件输入流具有流式搜索和流式定位读取的功能 String data = inStream.readUTF(); //使用输出流读取文件编程要求
本关的编程任务是补全右侧代码片段中的代码,具体要求及说明如下:
- 在主函数main中已获取hadoop的系统设置,并在其中创建HDFS文件。在main函数中,指定创建文档路径(必须设置为/user/hadoop/myfile才能评测),输入内容必须是本关要求内容才能评测。
- 添加读取文件输出部分
- 本关只要求在指定区域进行代码编写,其他区域仅供参考请勿改动。
测试说明
本关无测试样例,直接比较文件内容确定输出是否为“china cstor cstor cstor china”
注:由于启动服务、编译等耗时,以及hdfs文件操作过程资源消耗较大且时间较长,因而单个用户使用资源有限,评测时间较长(30s左右)!
请耐心等待!相信自己!通往成功的路上不会太久!本关的许多概念和操作比较抽象,但是机智的你一定会在接下来的学习中不断深入了解其含义并最终熟练操作的!
开始你的任务吧,祝你成功!
代码如下:
import java.io.IOException; import java.sql.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class hdfs { public static void main(String[] args) throws IOException { //throws IOException捕获异常声明 //****请根据提示补全文件创建过程****// /*********begin*********/ Configuration conf = new Configuration(); //实例化设置文件,configuration类实现hadoop各模块之间值的传递 FileSystem fs = FileSystem.get(conf); //是hadoop访问系统的抽象类,获取文件系统, FileSystem的get()方法得到实例fs,然后fs调动create()创建文件,open()打开文件 System.out.println(fs.getUri()); //实现文件读写主要包含以下步骤: //读取hadoop文件系统配置 //实例化设置文件,configuration类实现hadoop各模块之间值的传递 //FileSystem是hadoop访问系统的抽象类,获取文件系统, FileSystem的get()方法得到实例fs,然后fs调动create()创建文件,调用open()打开文件,调用close()关闭文件 //*****请按照题目填写要创建的路径,其他路径及文件名无法被识别******// Path file = new Path("/user/hadoop/myfile"); /*********end**********/ if (fs.exists(file)) { System.out.println("File exists."); } else { //****请补全使用文件流将字符写入文件过程,使用outStream.writeUTF()函数****// /*********begin*********/ FSDataOutputStream outStream = fs.create(file); //获取文件流 outStream.writeUTF("china cstor cstor cstor china"); //使用文件流写入文件内容 /*********end**********/ } //****请补全读取文件内容****// /*********begin*********/ // 提示:FSDataInputStream实现接口,使Hadoop中的文件输入流具有流式搜索和流式定位读取的功能 FSDataInputStream inStream = fs.open(file); String data = inStream.readUTF(); /*********end**********/ //输出文件状态 //FileStatus对象封装了文件的和目录的元数据,包括文件长度、块大小、权限等信息 FileSystem hdfs = file.getFileSystem(conf); FileStatus[] fileStatus = hdfs.listStatus(file); for(FileStatus status:fileStatus) { System.out.println("FileOwer:"+status.getOwner());//所有者 System.out.println("FileReplication:"+status.getReplication());//备份数 System.out.println("FileModificationTime:"+new Date(status.getModificationTime()));//目录修改时间 System.out.println("FileBlockSize:"+status.getBlockSize());//块大小 } System.out.println(data); System.out.println("Filename:"+file.getName()); inStream.close(); fs.close(); } }第3关:倒排索引
前面通过词频统计,已经可以找出高频率的“关键词”了,这些词汇出现的频率很高以至于很难直接对其所在的文档进行查找。必须借助一定的关系模型表示单词与文本的关系,然后才可以实现快速搜索查找。
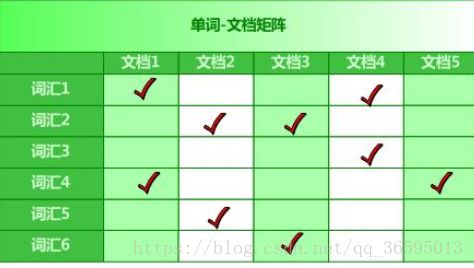
单词-文档矩阵是表达这种包含关系的最简洁的概念模型。每列代表文档包含了哪些单词,比如文档1包含了词汇1和词汇4,而不包含其它单词。每行代表了哪些文档包含了某个单词。比如对于词汇1来说,文档1和文档4中出现过单词1,而其它文档不包含词汇1。
搜索引擎的索引其实就是实现“单词-文档矩阵”的具体数据结构。可以有不同的方式来实现上述概念模型,比如“倒排索引”、“签名文件”、“后缀树”等方式。但是各项实验数据表明,“倒排索引”是实现单词到文档映射关系的最佳实现方式。本关任务
要求:编写处理带词频属性的文档倒排索引程序,运行程序,对莎士比亚文集文档数据进行倒排索引处理,结果输出到指定文件。
注:输入输出文件的路径已经指定,相关知识
文本特征
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再在本关后续内容,很多情况下会使用文档来表征文本信息。
文档集合(Document Collection):由若干文档构成的集合称之为文档集合。
文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。

倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
编程要求
本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
- 在主函数main中已初始化hadoop的系统设置,包括hadoop运行环境的连接。
- 在main函数中,已经设置好了待处理文档路径(即input),以及结果输出路径(即output)。
- 在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
- 本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
测试说明
测试输入样例数据集:文本文档test1.txt, test2.txt
文档test1.txt中的内容为:tale as old as time
true as it can be
beauty and the beast文档test2.txt中的内容为:
ever just the same
ever as before
beauty and the beast预期输出文件result.txt的内容为:

注:由于启动服务、编译等耗时,以及MapReduce过程资源消耗较大且时间较长,因而单个用户使用资源有限,评测时间较长(30s左右)!
请耐心等待!相信自己!通往成功的路上不会太久!工欲善其事必先利其器!要想实现海量数据搜索,必须先得到文档倒排索引
开始你的任务吧,祝你成功!
代码如下:
import java.io.IOException; import java.util.HashMap; import java.util.Hashtable; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.util.Iterator; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.util.GenericOptionsParser; public class InvertedIndex { public static class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { FileSplit fileSplit = (FileSplit)context.getInputSplit(); String fileName = fileSplit.getPath().getName(); String word; IntWritable frequence=new IntWritable(); int one=1; Hashtableit=hashmap.keySet().iterator();it.hasNext();){ word=it.next(); frequence=new IntWritable(hashmap.get(word)); Text fileName_frequence = new Text(fileName+"@"+frequence.toString());//以 values,Context context) throws IOException ,InterruptedException{ //****请合并mapper函数的输出,并提取“文件@1”中‘@’后面的词频,以 values, Context context) throws IOException, InterruptedException { Iterator it = values.iterator(); StringBuilder all = new StringBuilder(); if(it.hasNext()) all.append(it.next().toString()); for(;it.hasNext();) { all.append(";"); all.append(it.next().toString()); } //****请输出最终键值对list(K3,“单词", “文件1@频次; 文件2@频次;...")****// /*********begin*********/ context.write(key, new Text(all.toString())); /*********end**********/ } } public static void main(String[] args) { if(args.length!=2){ System.err.println("Usage: InvertedIndex " 第4关: 网页排序——PageRank算法
前面我们关注了文本中词频的统计筛选出了文本中的高频词汇,也通过倒排索引建立了关键词和文本集间的索引关系。接下来从宏观地关注文本间的关系。文本间的引用最具代表性,比如网页的相互链接。显而易见某些文本(网页)被引用(链接)次数多更加重要,在面对海量的文本时可以以此对文本重要性进行排序,尽快地找到有用信息。
本关任务
要求:编写实现网页数据集PageRank算法的程序,对网页数据集进行处理得到网页权重排序。
相关知识
PageRank算法原理
1. 基本思想:
如果网页T存在一个指向网页A的连接,则表明T的所有者认为A比较重要,从而把T的一部分重要性得分赋予A。这个重要性得分值为:PR(T)/L(T)
其中PR(T)为T的PageRank值,L(T)为T的出链数。则A的PageRank值为一系列类似于T的页面重要性得分值的累加。即一个页面的得票数由所有链向它的页面的重要性来决定,到一个页面的超链接相当于对该页投一票。一个页面的PageRank是由所有链向它的页面(链入页面)的重要性经过递归算法得到的。一个有较多链入的页面会有较高的等级,相反如果一个页面没有任何链入页面,那么它没有等级。
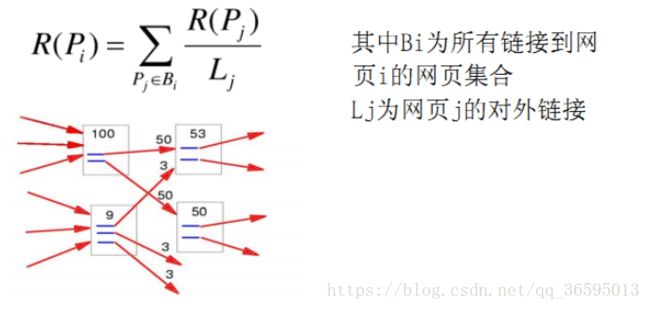
2. .PageRank简单计算:
假设一个由只有4个页面组成的集合:A,B,C和D。如图所示,如果所有页面都链向A,那么A的PR(PageRank)值将是B,C及D的和。


继续假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PageRank上。
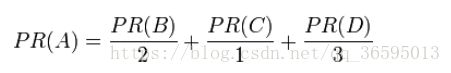
换句话说,根据链出总数平分一个页面的PR值。
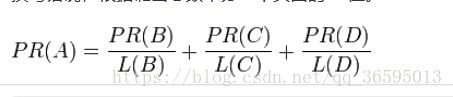
完整PageRank计算公式
由于存在一些出链为0不链接任何其他网页的网页,因此需要对 PageRank公式进行修正,即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般取值q=0.85
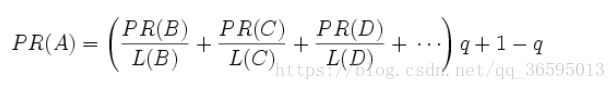
更加准确的表达为:
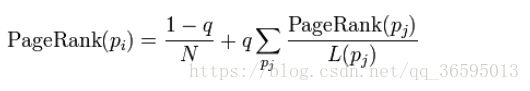
P1,P2,…,Pn是被研究的页面,M(Pi)是Pi链入页面的数量,L(Pj)是Pj链出页面的数量,而N是所有页面的数量。PageRank值是一个特殊矩阵中的特征向量。这个特征向量为:

R是如下等式的一个解:

如果网页i有指向网页j的一个链接,则

PageRank计算过程PageRank 公式可以转换为求解的值,
幂法计算过程如下:
X 设任意一个初始向量, 即设置初始每个网页的 PageRank值均。一般为1。R = AX。while (1){ if ( |X - R| < e) return R; //如果最后两次的结果近似或者相同,返回R else { X =R; R = AX; } }MapReduce计算PageRank
上面的演算过程,采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决对于如下图所示的相互链接网页关系
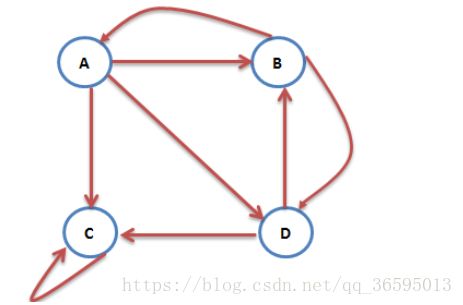
可以利用转移矩阵进行表示。转移矩阵是一个多维的稀疏矩阵,把web图中的每一个网页及其链出的网页作为一行,这样第四节中的web图结构用如下方式表示:

可以看A有三条出链,分布指向A、B、C,实际上爬取的网页结构数据就是这样的。
1、 Map阶段
Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出,,;
2、Reduce阶段
Reduce操作收集网页id相同的值,累加并按权重计算,pj=a(p1+p2+…Pm)+(1-a)1/n,其中m是指向网页j的网页j数,n所有网页数。思路就是这么简单,但是实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:

这样进行一次迭代相当于需要两次MapReduce,但第一次的MapReduce只是简单的排序,不需要任何操作,用java调用Hadoop的Streaming.编程要求
本关的编程任务是补全右侧代码片段中map和reduce函数中的代码,具体要求及说明如下:
- 在主函数main中已初始化hadoop的系统设置,包括hadoop运行环境的连接。
- 在main函数中,已经设置好了待处理文档路径(即input),在评测中设置了结果输出路径(即output),不要修改循环输出路径即可保证完成。
- 在main函数中,已经声明了job对象,程序运行的工作调度已经设定好。
- 原则上循环迭代次数越多越精准,但是为了保证平台资源,只允许运行5次迭代,多余过程被忽略无法展示,**请勿增加循环次数**。
- 本关只要求在map和reduce函数的指定区域进行代码编写,其他区域请勿改动。
测试说明
输入文件格式如下:

注:为了简化运算,已经对网页集关系进行了规整,并且给出了相应的初始PR值。
以第一行为例:1表示网址(以tab键隔开),1.0为给予的初始pr值,2,3,4,5,6,7,8为从网址1指向的网址。输出文件格式:
The origin result
1 1.0 2 3 4 5 6 7 8
2 2.0 3 4 5 6 7 8
3 3.0 4 5 6 7 8
4 4.0 5 6 7 8
5 5.0 6 7 8
6 6.0 7 8
7 7.0 8
8 8.0 1 2 3 4 5 6 7
The 1th result
1 0.150 1.121 _2 3 4 5 6 7 8
2 0.150 1.243 _3 4 5 6 7 8
3 0.150 1.526 _4 5 6 7 8
4 0.150 2.036 _5 6 7 8
5 0.150 2.886 _6 7 8
6 0.150 4.303 _7 8
7 0.150 6.853 _8
8 0.150 11.831 _1 2 3 4 5 6 7
The 2th result
1 0.150 1.587 _2 3 4 5 6 7 8
2 0.150 1.723 _3 4 5 6 7 8
3 0.150 1.899 _4 5 6 7 8
4 0.150 2.158 _5 6 7 8
5 0.150 2.591 _6 7 8
6 0.150 3.409 _7 8
7 0.150 5.237 _8
8 0.150 9.626 _1 2 3 4 5 6 7
The 3th result
1 0.150 1.319 _2 3 4 5 6 7 8
2 0.150 1.512 _3 4 5 6 7 8
3 0.150 1.756 _4 5 6 7 8
4 0.150 2.079 _5 6 7 8
5 0.150 2.537 _6 7 8
6 0.150 3.271 _7 8
7 0.150 4.720 _8
8 0.150 8.003 _1 2 3 4 5 6 7
The 4th result
1 0.150 1.122 _2 3 4 5 6 7 8
2 0.150 1.282 _3 4 5 6 7 8
3 0.150 1.496 _4 5 6 7 8
4 0.150 1.795 _5 6 7 8
5 0.150 2.236 _6 7 8
6 0.150 2.955 _7 8
7 0.150 4.345 _8
8 0.150 7.386 _1 2 3 4 5 6 7
The 5th result
1 0.150 1.047 _2 3 4 5 6 7 8
2 0.150 1.183 _3 4 5 6 7 8
3 0.150 1.365 _4 5 6 7 8
4 0.150 1.619 _5 6 7 8
5 0.150 2.000 _6 7 8
6 0.150 2.634 _7 8
7 0.150 3.890 _8
8 0.150 6.686 _1 2 3 4 5 6 7注:迭代方法和次数不同会对结果产生影响,不必完全与答案匹配,只需运行结果趋于合理即可。(第二列为多余值)
注:由于启动服务、编译、循环迭代等耗时,以及单次MapReduce过程资源消耗较大且时间较长,因而单个用户使用资源有限,评测时间较长(40s左右)!
请耐心等待!相信自己!通往成功的路上不会太久!慧眼识珍发现有用的文本信息,请先从网页排序分析开始!
开始你的任务吧,祝你成功!
代码如下:
import java.io.IOException; import java.text.DecimalFormat; import java.text.NumberFormat; import java.util.StringTokenizer; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class PageRank { public static class MyMapper extends Mapper<Object, Text, Text, Text> { private Text id = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { String line = value.toString(); //判断是否为输入文件 if(line.substring(0,1).matches("[0-9]{1}")) { boolean flag = false; if(line.contains("_")) { line = line.replace("_",""); flag = true; } //对输入文件进行处理 String[] values = line.split("\t"); Text t = new Text(values[0]); String[] vals = values[1].split(" "); String url="_";//保存url,用作下次计算 double pr = 0; int i = 0; int num = 0; if(flag) { i=2; pr=Double.valueOf(vals[1]); num=vals.length-2; } else { i=1; pr=Double.valueOf(vals[0]); num=vals.length-1; } for(;ivalues, Context context ) throws IOException, InterruptedException { double sum=0; String url=""; //****请通过url判断否则是外链pr,作计算前预处理****// /*********begin*********/ for(Text val:values) { //发现_标记则表明是url,否则是外链pr,要参与计算 if(!val.toString().contains("_")) { sum=sum+Double.valueOf(val.toString()); } else { url=val.toString(); } } pr=0.15+0.85*sum; String str=String.format("%.3f",pr); result.set(new Text(str+" "+url)); context.write(key,result); /*********end**********/ //****请补全用完整PageRank计算公式计算输出过程,q取0.85****// /*********begin*********/ /*********end**********/ } } public static void main(String[] args) throws Exception { String paths="file:///tmp/input/Wiki0";//输入文件路径,不要改动 String path1=paths; String path2=""; for(int i=1;i<=5;i++)//迭代5次 { System.out.println("This is the "+i+"th job!"); System.out.println("path1:"+path1); System.out.println("path2:"+path2); Configuration conf = new Configuration(); Job job = new Job(conf, "PageRank"); path2=paths+i; job.setJarByClass(PageRank.class); job.setMapperClass(MyMapper.class); //****请为job设置Combiner类****// /*********begin*********/ job.setCombinerClass(MyReducer.class); /*********end**********/ job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(path1)); FileOutputFormat.setOutputPath(job, new Path(path2)); path1=path2; job.waitForCompletion(true); System.out.println(i+"th end!"); } } }