声纹识别2
声纹识别,也称作说话人识别,是一种通过声音判别说话人身份的技术。从直觉上来说,声纹虽然不像人脸、指纹的个体差异那样直观可见,但由于每个人的声道、口腔和鼻腔也具有个体的差异性,因此反映到声音上也具有差异性。如果说将口腔看作声音的发射器,那作为接收器的人耳生来也具备辨别声音的能力。
最直观的是当我们打电话给家里的时候,通过一声“喂?”就能准确地分辨出接电话的是爸妈或是兄弟姐妹,这种语音中承载的说话人身份信息的唯一性使得声纹也可以像人脸、指纹那样作为生物信息识别技术的生力军,辅助甚至替代传统的数字符号密码,在安防和个人信息加密的领域发挥重要的作用。本文意在和读者一起分享声纹识别中主流的技术以及优图实验室在声纹识别的研发积累中取得的成果,希望能让读者对于声纹识别这个糅合语音信号处理+模式识别,且理论研究与工程背景兼具的领域有一个基本又全面的认识。
1. 拨云见日 – 声纹的基础“姿势”
我们常常会用“花言巧语”来形容一个嘴皮子不靠谱的人,但其实这个成语用来形容语音信号也是十分贴切的。人脸、指纹都是基于图像的二维信号,而语音是一种时变的一维信号,语音承载的首先是语意的信息,即我们说了什么内容,在语意信息的背后才是身份信息的体现。我们讲的话可以对应到成百上千个字词信息,但是这背后却只对应了一个不变的身份。
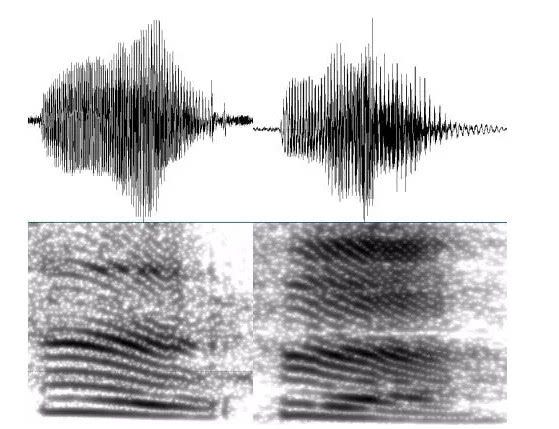
图1. 说话人A对应“四”的语音波形
图2. 说话人B对应“四”的语音波形
图3. 说话人A对应“九”的语音波形
如果上方的时域波形不够直观的话,那下方的短时语谱图从二维图像的角度能提供更多的直观信息。似乎图1和图2的相似度更高一些,图3因为对应了不同的语意,因此和图1,2差别更明显,但实际上图1和图3来自于同一个说话人,按照需求,1和3应该被分在同一类别! 似乎有点难,那我们干脆不要比较九了,只比较四好了…
因此,从语音字典是否受限的角度上来区分,声纹识别可以文本无关识别与文本相关识别。文本无关,顾名思义就是说系统对于输入的语音的内容并不做限制,识别系统应当可以克服语音中字典信息(亦或语意信息)的多变性和差异性,对语音背后的身份做出准确判断;而文本相关识别,意思是我们预先会限制语音的字典集合的规模。
再往细了区分又有两种常用的应用场景: 一种是固定口令,用户必须要说“天王盖地虎”,系统才会去识别声纹,你说“宝塔镇河妖”,对不起,不管你是谁,一概不行; 另一种是有限搭配的字典集合,系统会随机搭配一些数字或符号,用户需正确念出对应的内容才可识别声纹,这种随机性的引入使得文本相关识别中每一次采集到的声纹都有内容时序上的差异。
相较于指纹和人脸等静态的图像特征,这种数序的随机性无疑提升了安全性和防盗取能力。优图实验室自研的随机数字声纹识别方案已经应用于线上系统中,通过自主研发的人脸识别、活体检测、语音+声纹的多重验证手段,在最大程度上保障了用户的安全,杜绝了仿冒、窃取或复制用户自身生物信息的可能性.

图4:优图人脸核身示意图
文本相关识别因为限制了可选的字典信息,因此在系统复杂度和识别准确率上都要远好于文本无关的系统,只要采集相对比较短的一段语音即可实现声纹的识别;但文本无关的识别系统在某些领域也会有重要的作用,例如刑侦比对,我们可以采集到嫌疑人的一段声音,但是没法对声音对应的内容做限制,这时候文本无关识别就会派上重要的用场。
在过去的20年中,学界研究的重点大部分放在了更具挑战性的文本无关识别上(科学家の精神…),所取得的突破也都是围绕着文本无关的识别展开。美国国家标准技术局(National Institute of Standard and Technology,NIST)从90年代开始都会不定期地举办声纹识别评测竞赛(Speaker Recognition Evaluation, NIST SRE)[1],也是针对文本无关的识别进行评测,吸引了学术界和工业界的诸多重量级团队参与。
2014年,在语音界的学术盛会interspeech上,新加坡的I2R实验室发布了一套用于评测文本相关识别的标准数据集RSR 2015,涵盖了文本相关领域的多个应用场景[2]。自此,文本相关识别的研究热度开始渐渐提升,而近几年大热的“深度学习”也是最先在文本相关识别上取得了比较大的突破 [3]。这里不再过多展开,有兴趣的读者可以参考各大学术数据库的资源,或者和我们团队进行交流。
而从识别的场景上考虑的话,声纹识别又可以分为说话人辨识(Speaker Identification,SI)和说话人确认(Speaker Verification,SV)两个不同的应用场景:SI指的是我们有了一段待测的语音,需要将这段语音与我们已知的一个集合内的一干说话人进行比对,选取最匹配的那个说话人。
这方面的应用案例是刑侦比对,暗中收集到的一段嫌疑人(身份未知)的声音,需要与数个可能的嫌疑人身份进行比对,选取最相似的那一个,则我们就可以认为收集到的这段语音在很大程度上就是来自于锁定的这个嫌疑人,SI是一个1对多的判别问题;而SV指的是我们只有一个目标身份,对于一段未知的语音,我们只需要判断这段语音是否来源于这个目标用户即可,SV本质上是一1对1的二分类问题。这方面典型的应用是手机端的声纹锁或声纹验证工具,对于一段验证语音,系统只需要回答“通过”或者“拒绝”即可。而SI可以间接分解为多个SV的问题,因此对于声纹识别系统性能的评测多是以SV的方式进行。
2. 动中取静-从离散信号到特征
前面提到了,声纹之所以能被识别,是因为每个人的口腔、鼻腔与声道结构都存在唯一的差异性,但这种差异性既看不到又摸不着,更要命的是,它是一个时刻都在运动着的器官构造。我们只能通过录音设备采集到的离散语音信号,间接去分析发声器官的差异性。
既然语音一直在变,那我们该如何去对语音进行分析呢?答案是:语音具备了一个良好的性质,称为短时平稳,在一个20-50毫秒的范围内,语音近似可以看作是良好的周期信号。
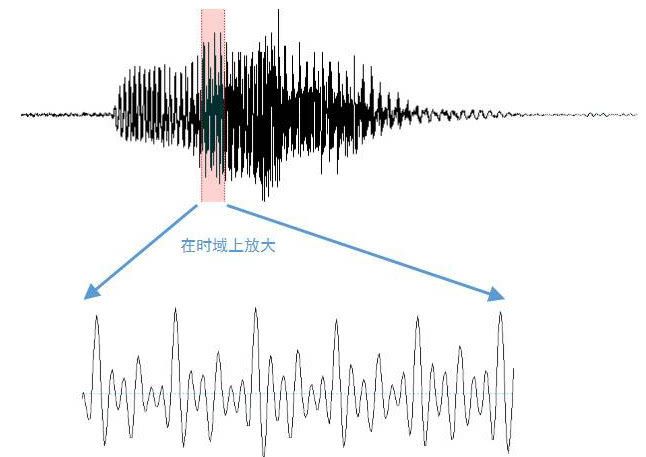
图5:图1中话者A“四”的发声中截取出的30毫秒长度的信号。
这种良好的平稳性为我们针对语音进行信号处理层面的分析提供了极大的便利。读者都应该还记得,在音调,响度和音色这三个声音(注意,这里我用了声音,而不是语音)的基本属性中,音色是最能反映一个人身份信息的属性(讲道理,老婆对你吼的时候,响度和音调都可以极速飙升,但老婆的音色是不大会发生剧烈变化的)。
而音色上的差异在信号处理的层面可以表示为在频域不同频段能量的差异,因此我们通过抽取不同频段上的能量值,即可以表示在这个短时语音范围内频谱的性质。通常我们会综合考虑人耳的听觉属性(人耳的一个听觉属性是在可听到的频段内,对于低频的变化更加敏感,而对于高频相对弱一些)、均衡不同频段的能量差异(对于一段8KHz采样的音频,尽管语音会分布于0-4KHz的范围内,但能量更多的集中在相对比较低频的区域)、噪声鲁棒性(我们希望特征只对语音的变化敏感,而对其他噪声等无关信息不变)以及后续的计算便利(系数之间尽可能要去除相关性)设计合适的短时声学特征,通过一系列复杂的信号处理层面的变换,一段20-50毫秒长度的语音(以8KHz采样为例,这个长度的语音对应着160-400个采样点)可以映射为一段39-60维的向量。为了充分保留语音中的原始信息,同时不增加计算的负担,通常会以15-20毫秒为间隔依次取短时段语音,然后提取特征。
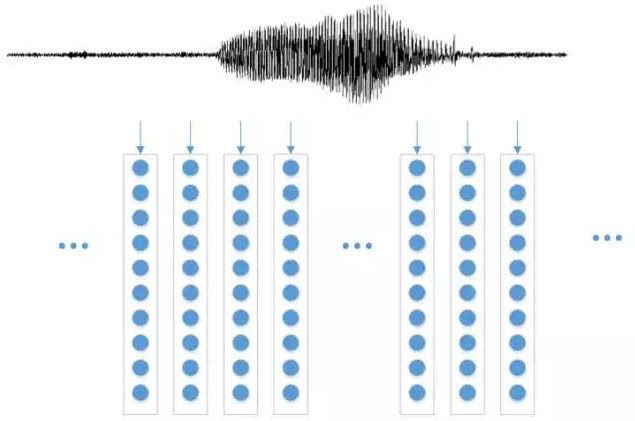
图6:短时声学特征的提取
在声纹识别,包括语音识别领域,传统的声学特征包括梅尔倒谱系数MFCC、感知线性预测系数PLP、近几年的逐渐受到关注的深度特征Deep Feature [4]、以及15年公开发表的能量规整谱系数PNCC [5]等,都能作为声纹识别在特征提取层面可选且表现良好的声学特征。
综上,一段语音就被映射为时间轴上一系列的向量集合,这些集合再通过一些规整的操作后,即可成为反映语音特性的特征集合。但仅靠这些特征集合还难以实现声纹识别的目标,声学特征可以理解为时间轴上为声道拍摄的一系列快照,它直接映射的仍然是语意的内容,如何从一堆变化的特征中提取出不变的身份特性呢?接下来,就是统计建模发挥威力的时候了。
3. 化繁为简-声纹模型的进化路
既然希望计算机能够识别一个用户的声纹,那首先得让计算机“认识”这个用户的身份。典型的声纹识别的系统的框架如下图所示:

图7:典型的说话人确认系统流程图
声纹识别系统是一个典型的模式识别的框架,为了让计算机认识一个用户的身份,需要目标用户首先提供一段训练语音,这段语音经过特征提取和模型训练等一系列操作,会被映射为用户的声纹模型。在验证阶段,一个身份未知的语音也会经过一系列的操作被映射为测试特征,测试特征会与目标模型进行某种相似度的计算后得到一个置信度的得分,这个得分通常会与我们人工设定的期望值进行比较,高于这个期望值,我们认为测试语音对应的身份与目标用户身份匹配,通过验证;反之则拒绝掉测试身份。因此,识别性能好坏的关键在于对语音中身份信息的建模能力与区分能力,同时对于身份无关的其余信息具有充分的抗干扰能力和鲁棒性。
尽管每个人的语音看起来千变万化,但也不是完全没有规律可循。尽管我们每天会说很多话,但常用的字词至多只有数千个左右的级别;另外我们也做不到和家里的旺财发出一模一样的叫声。这也引出了声纹识别,同时也是传统的语音识别框架下的一个很合理的假设:将语音拆分到音素(phone)的级别,狭义的现代汉语只需要32个音素就已经足够用了。
如果考虑到每个音素的形态还会受到前后音素的影响,构建三音素模型(tri-phone)的话,那至多也只有几千个备选的三音素集合(不是简单的32的三次方,我们也会去掉一些稀有的和根本不会出现的搭配),而不同说话人的三音素样本尽管有明显的差异,但都能在空间中的某个区域内聚类。由语音和对应的声学特征的这些性质启发,1995年DA Reynolds首次将混合高斯模型(Gaussian Mixture Model,GMM)成功地应用于文本无关的声纹识别任务,至此之后的20多年,奠定了GMM在声纹识别中地基的地位,后续声纹的发展演进都是以GMM作为基础进行改进和拓展的。
在继续深入了解建模之前,我们有必要明确声纹识别,或者把范围再缩小一些,明确文本无关声纹识别任务,它的难点在哪里?在前文也提到过,声纹识别是一个兼具理论研究价值与工程应用背景的领域,声纹的难点主要在以下几个方面:
如何在语音多变性的背后,挖掘不变的身份信息。
实际应用中,从用户体验和成本的角度上考虑,针对目标用户可采集到的语料是极其有限的(按照学术上的定义,实际可用的语音是稀疏(sparse)的),如何在有限的数据中完成稳定的建模与识别。
对于同一个用户,即便采集到的两段语音内容都是相同的,但由于情绪、语速、疲劳程度等原因,语音都会有一些差异性。如何补偿这种说话人自身语音的差异性。
声音是通过录音设备进行采集的,不同的型号的录音设备对语音都会造成一定程度上的畸变,同时由于背景环境和传输信道等的差异,对语音信息也会造成不同程度的损伤,一般在研究中将这些外界影响语音的效应称为信道易变性(Channel Variability)。我们难以做到针对每一种信道效应都开发对应专属的声纹识别系统,那么如何补偿这种由于信道易变性带来的干扰。
明确了需要解决的问题之后,再回过来看GMM,它的优势在哪里?首先GMM是什么,它是一大堆形状不定的高斯分量的加权组合。有研究表明,当GMM中高斯分量的数量足够多的时候,GMM可以模拟任意的概率分布。

图8:我们只利用了七个葫芦娃就拟合出了一座山(画图真心太累,你们懂了就好_(¦3」∠)_)
从模式识别的相关定义上来说,GMM是一种参数化(Parameterized)的生成性模型(Generative Model),具备对实际数据极强的表征力;但反过来,GMM规模越庞大,表征力越强,其负面效应也会越明显:参数规模也会等比例的膨胀,需要更多的数据来驱动GMM的参数训练才能得到一个更加通用(或称泛化)的GMM模型。
假设对维度为50的声学特征进行建模,GMM包含1024个高斯分量,并简化多维高斯的协方差为对角矩阵,则一个GMM待估参数总量为1024(高斯分量的总权重数)+1024×50(高斯分量的总均值数)+1024×50(高斯分量的总方差数)=103424,超过10万个参数需要估计(搞深度学习的同学你们中箭了吗?)!
这种规模的变量别说目标用户几分钟的训练数据,就算是将目标用户的训练数据量增大到几个小时,都远远无法满足GMM的充分训练要求,而数据量的稀缺又容易让GMM陷入到一个过拟合(Over-fitting)的陷阱中,导致泛化能力急剧衰退。因此,尽管一开始GMM在小规模的文本无关数据集合上表现出了超越传统技术框架的性能,但它却远远无法满足实际场景下的需求(毕竟95年的技术了...)。
时间来到了2000年前后,仍然是DA Reynolds的团队,提出了一种改进的方案:既然没法从目标用户那里收集到足够的语音,那就换一种思路,可以从其他地方收集到大量非目标用户的声音,积少成多,我们将这些非目标用户数据(声纹识别领域称为背景数据)混合起来充分训练出一个GMM,这个GMM可以看作是对语音的表征,但是又由于它是从大量身份的混杂数据中训练而成,它又不具备表征具体身份的能力。
那它有什么用呢?
学术圈的人就会告诉你:从贝叶斯框架的角度上来说,这个四不像GMM可以看作是某一个具体说话人模型的先验模型。形象的比方就是说你准备去相亲,媒人给你看了小莉的照片,你耳边浮现的肯定是小莉各种可能的温柔的声音,而不是你家旺财的叫声。
这个混合GMM就是起到了类似的作用,它对语音特征在空间分布的概率模型给出了一个良好的预先估计,我们不必再像过去那样从头开始计算GMM的参数(GMM的参数估计是一种称为EM的迭代式估计算法),只需要基于目标用户的数据在这个混合GMM上进行参数的微调即可实现目标用户参数的估计,这个混合GMM也有一个很洋气的名字,叫通用背景模型(Universal Background Model,UBM)。
UBM的一个重要的优势在于它是通过最大后验估计(Maximum A Posterior,MAP)的算法对模型参数进行估计,避免了过拟合的发生。MAP算法的另外一个优势是我们不必再去调整目标用户GMM的所有参数(权重,均值,方差)只需要对各个高斯成分的均值参数进行估计,就能实现最好的识别性能。 这下子待估的参数一下子减少了一半还多(103424 -> 51200),越少的参数也意味着更快的收敛,不需要那么多的目标用户数据即可模型的良好训练。(八卦时间:据说Douglas A. Reynolds正是因为提出了GMM-UBM的框架而当选了IEEE的Fellow,如果有误请忽略)
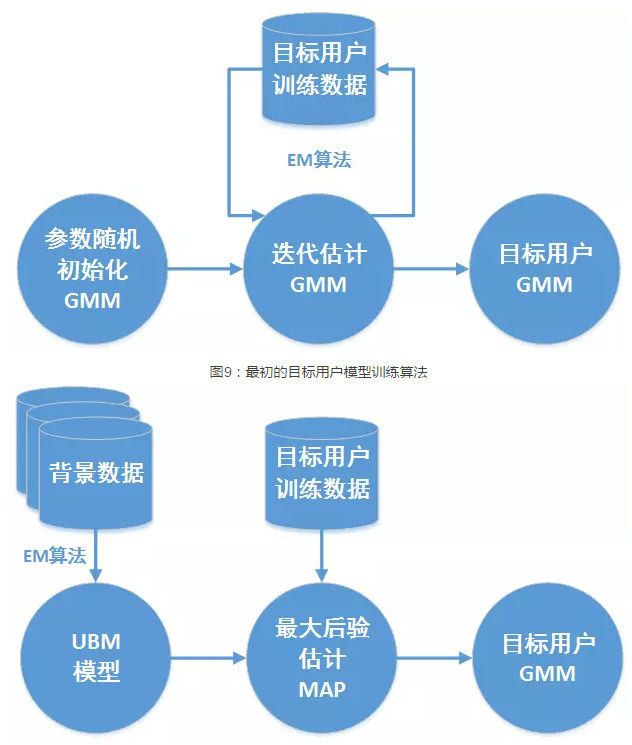
图10:基于UBM的MAP用户模型训练算法
但GMM-UBM框架够好了吗?并没有 (咳咳,2000年前后…),至少有两个问题GMM-UBM框架仍然没法解决:
待估的参数仍然还是太多了。在NIST SRE的标准测试中,一个目标用户的可用语音约在5min左右,去掉静音段和停顿,大约只能保留1分半到2分半左右的有效长度,看起来已经挺短了,但是你能想象在在实际产品中一个用户对着手机连续读五分钟进行注册吗?absolutely no!这个长度的有效语音对于一个1024个高斯分量组成的GMM模型来说还是太短了,MAP算法只能对其中一部分落在某些高斯分量上的特征进行相应的高斯分量进行参数优化,而另外相当一部分得不到观测数据的高斯分量怎么办?那就只能老老实实待在原地不动了。这就造成了目标用户GMM某些区域具备良好的目标用户身份表达能力,而另外一些GMM区域则基本和UBM的参数相同,这无疑降低了文本无关识别应用中模型的表达能力;
GMM-UBM缺乏对应于信道多变性的补偿能力,直白点说就是它不抗干扰,你拿爱疯手机在云端注册模型,换个小米手机拿来做识别,不通过!这下真的发烧了。但了不起的科学家们总有改进的办法,WM Campbell将支持向量机(Support Vector Machine,SVM)引入了GMM-UBM的建模中,通过将GMM每个高斯分量的均值单独拎出来,构建一个高斯超向量(Gaussian Super Vector,GSV)作为SVM的样本,利用SVM核函数的强大非线性分类能力,在原始GMM-UBM的基础上大幅提升了识别的性能,同时基于GSV的一些规整算法,例如扰动属性投影(Nuisance Attribute Projection, NAP),类内方差规整(Within Class Covariance Normalization,WCCN)等,都在一定程度上补偿了由于信道易变形对声纹建模带来的影响,这里也不多过多展开,有兴趣的读者们也可以查阅相关文献或与我们一起讨论。
时间继续前进,为了解决GMM-UBM待估参数过多的问题,学界与工业界可谓费尽心思,忽然有一天,学者们发现了:在MAP框架下,我们都是单独去调整GMM的每一个高斯分量,参数太多太累了,那有没有办法同时调整一串高斯分量呢?我们玩街霸也不用给每个关节都配备一个按钮,四个按键照样也能发出波动拳啊。
那有没有这样一种方法,让我们只能用少量的参数就能控制GMM中所有高斯成分的变化呢?答案当然是有,我们借助一种称为因子分析(Factor Analysis,FA)的算法框架,只用数百个基向量的线性组合(每个基向量的权重就可以看作是在这个基坐标上的坐标点),就足够能表征全体高斯超向量的变化了,也就是说,我们现在只需要几百个变量(通常为400-600),就足够表示一个50000维度的高斯分量均值集合!
其实,这种降维的思想在过去就已经广泛应用于图像,语音和数据的压缩技术中,因为真实数据总是带着相当多的冗余信息,我们可以做到只损失一小部分精度,甚至不损失精度,就能实现数据的压缩与降维,而基向量的估计是通过一种称为基于概率的主成份分析的(Probabilistic Principal Component Analysis, PPCA)的类EM算法,基于海量的背景说话人数据学习而来。这下好了,模型参数一下子从50000一下子降到了500,简直堪比梦中的房价走势。这样少量的数据就能实现GMM高斯分量的整体参数估计,随着数据量的增加,GMM会迅速趋于一个稳定的参数估计。在上面提到的难点中,a,b,c在很大程度上得到了解决。
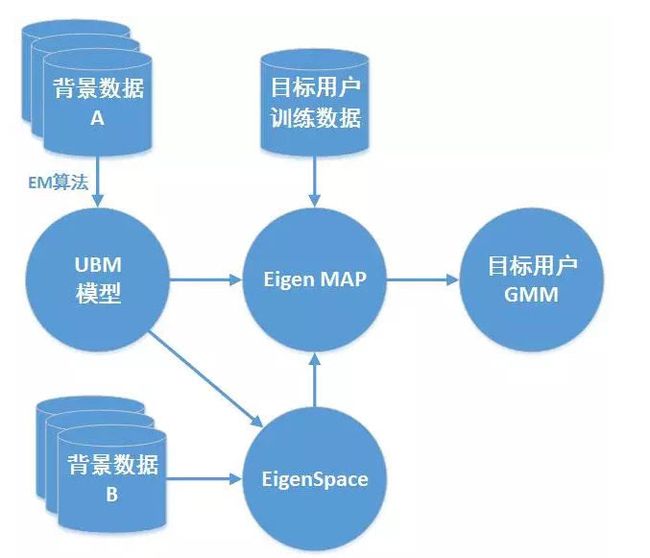
图11:基于FA框架的Eigenvoice MAP用户模型训练算法
但是,别忘了还有难点d啊,那怎么办?加拿大蒙特利尔研究所(Computer Research Institute of Montreal,CRIM)的科学家兼公式推导帝Patrick Kenny在05年左右提出了一个设想,既然声纹信息可以用一个低秩的超向量子空间来表示,那噪声和其他信道效应是不是也能用一个不相关的超向量子空间进行表达呢?
基于这个假设,Kenny提出了联合因子分析(Joint Factor Analysis,JFA)的理论分析框架,将说话人所处的空间和信道所处的空间做了独立不相关的假设,在JFA的假设下,与声纹相关的信息全部可以由特征音空间(Eigenvoice)进行表达,并且同一个说话人的多段语音在这个特征音空间上都能得到相同的参数映射,之所以实际的GMM模型参数有差异,都是由特征信道(Eigenchannel),即信道效应的干扰导致的,我们只需要同时估计出一段语音在特征音空间上的映射和特征信道上的映射,然后撇掉特征信道上的干扰就可以实现更好的声纹环境鲁棒性。
而JFA两个子空间的联合推导简直堪称是Kenny大神夺目的数学表演,有兴趣的读者可以参考 [5],我估计不是声纹圈的翻了第一页和最后一页就可以直接关闭pdf了。
JFA在05之后的NIST声纹比赛中以绝对的优势成为了性能最优的识别系统,但JFA就足够好了吗?声纹领域的天空中仍然漂浮着一小朵乌云,尽管JFA对于特征音空间与特征信道空间的独立假设看似合理,但天下没有免费的午餐,现实世界中,尽管任何数据都存在冗余,即数据之间都具有相关性,但绝对的独立同分布的假设又是一个过于强的假设,你可以说你和你家旺财在长相上没什么相关性,但你们都有一对儿眼睛一张嘴啊…(也许都很能吃),这种独立同分布的假设往往为数学的推导提供了便利,但却限制了模型的泛化能力。
那肿么办?时间来到了09年,Kenny的学生,N.Dehak,提出了一个更加宽松的假设:既然声纹信息与信道信息不能做到完全独立,那干脆就用一个超向量子空间对两种信息同时建模拉倒!回想下JFA的假设:
同一个说话人,不管怎么采集语音,采集了多少段语音,在特征音子空间上的参数映射都应该是相同的;而最终的GMM模型参数之所以有差别,这个锅就丢给特征信道子空间来背;
特征音子空间和特征信道子空间互相独立。
JFA的这种“强”假设在实际使用中已经被验证必然不会满足。因此N.Dehak同志说:大家都是战友,不要再分你的我的,有福同享有难同当啦。这个更宽松的假设就是:既然正交独立性没有办法满足,那我们就干脆用一个子空间同时描述说话人信息和信道信息。
这时候,同一个说话人,不管怎么采集语音,采集了多少段语音,在这个子空间上的映射坐标都会有差异,这也更符合实际的情况。这个即模拟说话人差异性又模拟信道差异性的空间称为全因子空间(Total Factor Matrix),每段语音在这个空间上的映射坐标称作身份向量(Identity Vector, i-vector),i-vector向量通常维度也不会太高,一般在400-600左右 [6]。
这是什么概念读者们?折腾来折腾去声纹还是在搞GMM,但一路走来,从最初95年采用的32个高斯分量的GMM,一路飙升到1024、2048、甚至4096(敢这么玩的都是业界土豪)个高斯分量的GMM,模型改改改,公式推推推,折腾到最后一个说话人的声纹模型只需要保存一个400×1的向量就够了?

是的!就是这个样子,这也是为什么我用化繁为简来作为文章的副标题,i-vector是如此的简洁优雅,它的出现使得说话人识别的研究一下子简化抽象为了一个数值分析与数据分析的问题:任意的一段音频,不管长度怎样,内容如何,最后都会被映射为一段低维度的定长i-vector。
我们只需要找到一些优化手段与测量方法,在海量数据中能够将同一个说话人的几段i-vector尽可能分类得近一些,将不同说话人的i-vector尽可能分得远一些。同时Dehak在实验中还发现i-vector具有良好的空间方向区分性,即便上SVM做区分,也只需要选择一个简单的余弦核就能实现非常好的区分性。截至今日,i-vector在大多数情况下仍然是文本无关声纹识别中表现性能最好的建模框架,学者们后续的改进都是基于对i-vector进行优化,包括线性区分分析(Linear Discriminant Analysis, LDA),基于概率的线性预测区分分析(probabilistic linear discriminant analysis,PLDA)甚至是度量学习(Metric Learning)等。
4. 迷思-文本相关?文本无关?
既然i-vector在文本无关声纹识别上这么牛逼,那它在文本相关识别上一定也很厉害吧?No!在看似更简单的文本相关声纹识别任务上,i-vector表现得却并不比传统的GMM-UBM框架更好。
为什么?因为i-vector简洁的背后是它舍弃了太多的东西,其中就包括了文本差异性,在文本无关识别中,因为注册和训练的语音在内容上的差异性比较大,因此我们需要抑制这种差异性;但在文本相关识别中,我们又需要放大训练和识别语音在内容上的相似性,这时候牵一发而动全身的i-vector就显得不是那么合适了。
5. 进击:我们的youtu-vector
尽管学术界喜欢更难的挑(zuo)战(si),但工业界在很多时候没法和学术界保持一致。识别稳定,快速,用户体验好,才是一个声纹系统能够落地的核心评价指标。为此,首选的仍然是文本相关识别的应用,而在文本相关识别应用中,安全性最高的仍然是随机数字声纹识别。
尽管i-vector在文本相关上识别上似乎有点水土不服,但毕竟它在擅长的领域上已经展现了强大的性能。因此,如何能将i-vector的实力应用在我们的任务中,让随机数字声纹识别也能发挥出最大的能量,是优图实验室一致努力的目标。
针对i-vector弱化语意建模的属性,我们细化了i-vector的表征范围,即我们不再用i-vector针对一整段语音进行建模,而是将i-vector拆解为针对每个数字进行建模,这样i-vector从只表征说话人身份的一段向量细化为了表征身份+数字内容的一个向量。
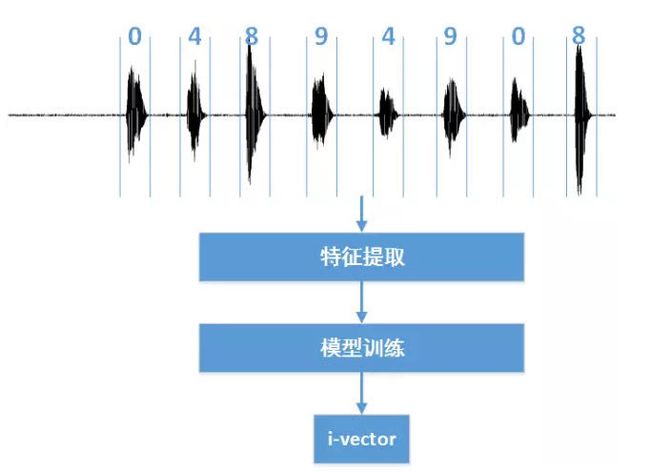
图12:传统的i-vector提取框架,并不针对文本差异进行区分
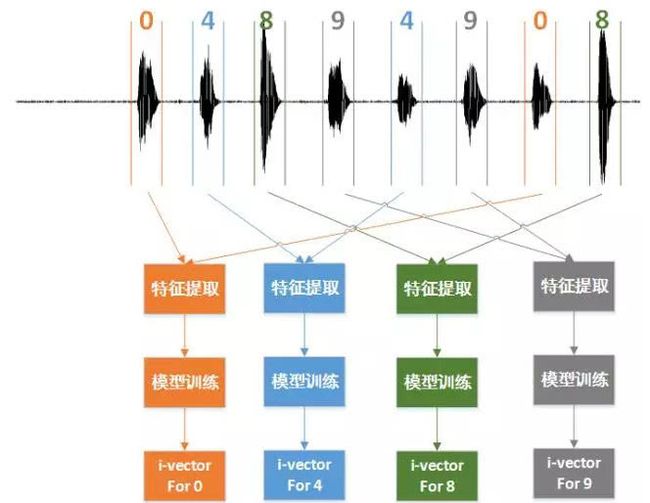
图13:针对数字内容的差异性进行更细粒度的i-vector提取
这种更细粒度的i-vector划分为i-vector应用于随机数字声纹识别带来了两个明显的改进:
为了驱动i-vector背后的UBM和全因子矩阵,我们不再需要海量的数据,只需要专注于具体的数字片段切分,极大降低了驱动系统所需的训练数据的规模;
由于每个i-vector只针对数字进行建模,每个数字i-vector背后的数字UBM和数字全因子矩阵,都不需要像文本无关那样庞大的模型规模,相较于文本无关识别的任务,模型复杂度降低数十倍后,依然能在实际场景下表现出同样好的性能。
模型的简化带来的直接优势就是计算复杂度和空间复杂度的压缩,同时,尽管需要提取的i-vector数量比过去多了(目标用户语音中包含数字的集合数就是目标用户最终的i-vector集合数),但将提取过程并行化后,这种细化带来的额外计算与存储基本上是可以忽略的。

在识别性能上,我们以团队内部真实环境下采集的数据作为测试样例将数字i-vector与传统的i-vector、和RSR 2015一起发布的HiLAM文本相关识别框架进行了比较,包括了数万规模的目标样本测试与数十万规模的攻击样本测试,实现了等错误概率(EER)小于1%,千分之一错误率下的召回率大于95%的识别性能。我们自主研发的数字i-vector,性能要远好于现有的声纹识别框架。
6. 且行且思-关于声纹的展望与反思
尽管在适配i-vector与文本相关识别中,我们的尝试与探索有了一些突破,但我们仍然需要看到声纹识别在应用中的局限:动态变化的发声器官与声音,它们的稳定性依然还不及人脸与图像。除非哪天中风了,很难想像会有什么理由使得人脸识别失灵;但是感冒发烧则会改变我们的声道结构,自己的声音也会发生变化。
而声纹的识别精度相较人脸与图像还有比较明显的差距。深度学习的浪潮中,声纹的演进似乎也还是不温不火,而声纹识别的“兄弟”语音识别早已乘着深度学习的航母向前驰骋,这其中的原因有声纹固有的难点,想啃下这块硬骨头,我们要做的事情还有很多。
而优图在声纹的深度学习推进中也从未停下脚步,除了随机数字识别,在文本无关识别应用中,我们自研的从基于DNN的说话人分类网络中提取的深度特征(也称为瓶颈特征(bottleneck feature)),辅助i-vector进行分数层面的融合也让i-vector的识别性能在过去的基础上跨进了扎实的一步。在未来,优图团队有信心在人工智能的这股浪潮中激流勇进,贡献出更多更好的产品,服务大众,让每个人都能感受到科技为生活带来的便捷。
参考文献
[1] http://www.itl.nist.gov/iad/mig/tests/spk/
[2] Larcher, Anthony, et al. "RSR2015: Database for Text-Dependent Speaker Verification using Multiple Pass-Phrases." INTERSPEECH. 2012.
[3] Fu Tianfan, et al. "Tandem deep features for text-dependent speaker verification." INTERSPEECH. 2014.
[4] Vasilakakis, Vasileios, Sandro Cumani, and Pietro Laface. "Speaker recognition by means of deep belief networks." (2013).
[5] Kenny, Patrick. "Joint factor analysis of speaker and session variability: Theory and algorithms." CRIM, Montreal,(Report) CRIM-06/08-13 (2005).
[6] Dehak, Najim, et al. "Front-end factor analysis for speaker verification." IEEE Transactions on Audio, Speech, and Language Processing 19.4 (2011): 788-798.