最强大脑第二场战平听音神童!百度大脑小度声纹识别技术解析
日前,继在江苏卫视《最强大脑》第四季“人机大战”首轮任务跨年龄人脸识别竞赛中击败人类顶级选手后,在上周五晚上,百度的小度机器人再次在声纹识别任务上迎战名人堂选手——11岁的“听音神童”孙亦廷,双方最终以1:1打成平手。被称为“鬼才之眼”的水哥(王昱珩)宣布再度出山,将在下周的第三轮比赛中与“小度”在图像识别方面一决高下。
本轮题目规则为:从“千里眼”到“顺风耳”,节目组将第二场比赛范围划定在“听”的领域,策划出高难度选题《不能说的秘密》,由周杰伦化身出题人,从21位性别相同、年龄相仿、声线极为相似的专业合唱团中,选出三位每个人读一句话,加密后成为断断续续的声音样本再交给小度和孙亦廷,要求他们从合唱声音中识别出三名线人的声音。
百度语音技术部总监高亮从技术角度解读了本场的难点,他认为声纹识别对机器来说是一项‘高难度挑战’,尤其是本次比赛采用的大合唱形式能显著降低不同人的差异性,并且合唱的内容有长时间的语气词内容,更进一步增加了注册语音的混淆程度。而线人测试声音断断续续,特定说话人的一些发音习惯很大可能被损坏掉,也加大了说话人特征提取表征的难度。
一、“不能说的秘密”声纹识别难点
从技术角度来看,声纹识别有四大难点:
难度一:泛化能力
目前机器学习算法大多采用数据驱动的方法。简单来说,就是“你给了机器什么样的数据,机器以后就只认识这样的数据。”而在面对与学习时不一样的数据时,机器则往往会存在识别障碍。衡量一个机器学习算法好坏的一个重要指标,就是机器能够处理学习时没有遇见过的样本的能力,这种能力被称之为”泛化能力”。
例如,如果人们让机器学习识别狗时,用的学习样本都是成年的阿拉斯加,那么算法在遇到泰迪时,就会极有可能告诉你泰迪不是一只狗。在声纹识别中我们也会面临着同样的问题,传统的声纹识别任务都是注册和测试都是非常匹配的,即注册采用正常说话,测试也是正常说话。
而在本次比赛中,注册的语音则变成了唱歌,测试的才是正常说话。因此,需要让模型能够学到同一个人在唱歌和说话时的差异。这对声纹识别算法的泛化能力提出了更高的要求。
难度二:注册语音的趋同效应
一般而言,正常人说话时的声音特征是具有明显的差异的。而本次比赛采用的大合唱形式能显著的降低了不同人的差异性。由于合唱的要求大家的声音能像一个人那样的整齐,因此不同的合唱队员的唱歌样本就会有趋同效应,大家会刻意的通过改变发音习惯等来使得合唱的效果更好。这就好比分类难度从猫和狗的识别变成了阿拉斯加和哈士奇的区别。二者的难度有明显的差异。并且,合唱的内容有长时间的语气词内容,更进步增加了注册语音的混淆程度。
难度三:线人测试声音的断断续续
由于人在发音时,存在协同发音的效应,即前后相连的语音总是彼此影响,后面说的内容会受前面说的内容的影响。而这些特性会被机器已数据驱动的方式学习到模型中,而在面临断断续续的语音时,特定说话人的一些发音习惯就有很大可能被损坏掉,从而加大了说话人特征提取表征的难度。
难度四:线人测试声音时长过短
由于目前的机器学习的算法要能够有效的表征出一段语音能够表示的说话人信息,那么这段语音必须要有足够长。否则,语音过短,提取出来的特征不足以有效的表征该说话人的信息,就会导致系统性能出现严重下降。这就是声纹识别领域中的短时语音声纹验证难题。在实际测试中,线人说话的声音过短,不超过10个字,有效时间长短也小于3s。这就给算法带来了极大的难度,需要更为鲁棒(Robust)的来提取出短时的、断断续续的线人说话声音所能够表征的线人特性。

二、百度大脑声纹识别过程还原
一个基本的声纹识别过程如下图,主要包括声纹注册和声纹识别阶段:
Step1:声纹注册阶段
在声纹注册阶段,每个可能的用户都会录制足够的语音然后进行说话人特征的提取,从而形成声纹模型库。通俗来说,这个模型库就类似于字典,所有可能的字都会在该字典中被收录。
Step2:声纹测试阶段
在该阶段,测试者也会录制一定的语音,然后进行说话人特征提取,提取完成后,就会与声纹模型库中的所有注册者进行相似度计算。相似度最高的注册者即为机器认为的测试者身份。
因此,在实际比赛中,上述的过程可以被进一步解释如下图所示:

大合唱阶段,即可以对比成声纹注册阶段,小度通过收集每个合唱队员的唱歌语音,然后得到能够表征该合唱队员的说话人特征,从而构建好21个合唱队员的声纹模型库。
线人在与周杰伦进行对话的阶段,机器和人截获到的断断续续的语音,及可以看成是线人的测试语音,通过提取该测试语音的说话人特征,然后与模型库中的21个合唱队员依次进行相似度计算,相似度最高的合唱队员即为机器认为的线人真是身份。
值得一提的是,机器可以对采集到的语音进行录制,不存在记忆消失的问题,而人由于只能依靠记忆来完成对语音特征的存储。因此,机器在面临先听21个人合唱还是先听3个线人说话上是一样的,而人类则不同,在比赛中,人类先听线人说话,意味着人类只需要记住3个线人的说话特征,然后在从21个合唱队员中找出与这3个人相似的声音。这个难度是比,记住21个人唱歌,然后从3个人中找出对应的身份要相对简单。
三、百度大脑如何提取声纹特征?算法如何?
1.声学特征提取
语音信号可以认为是一种短时平稳信号和长时非平稳信号,其长时的非平稳特性是由于发音器官的物理运动过程变化而产生的。从发音机理上来说,人在发出不同种类的声音时,声道的情况是不一样的,各种器官的相互作用,会形成不同的声道模型,而这种相互作用的变化所形成的不同发声差异是非线性的。但是,发声器官的运动又存在一定的惯性,所以在短时间内,我们认为语音信号还是可以当成平稳信号来处理,这个短时一般范围在10到30毫秒之间。
这个意思就是说语音信号的相关特征参数的分布规律在短时间(10-30ms)内可以认为是一致的,而在长时间来看则是有明显变化的。在数字信号处理时,一般而言我们都期望对平稳信号进行时频分析,从而提取特征。因此,在对语音信号进行特征提取的时候,我们会有一个20ms左右的时间窗,在这个时间窗内我们认为语音信号是平稳的。然后以这个窗为单位在语音信号上进行滑动,每一个时间窗都可以提取出一个能够表征这个时间窗内信号的特征,从而就得到了语音信号的特征序列。这个过程,我们称之为声学特征提取。这个特征能够表征出在这个时间窗内的语音信号相关信息。如下图所示:

这样,我们就能够将一段语音转化得到一个以帧为单位的特征序列。由于人在说话时的随机性,不可能得到两段完全一模一样的语音,即便是同一个人连续说同样的内容时,其语音时长和特性都不能完全一致。因此,一般而言每段语音得到的特征序列长度是不一样的。
在时间窗里采取的不同的信号处理方式,就会得到不同的特征,目前常用的特征有滤波器组fbank,梅尔频率倒谱系数MFCC以及感知线性预测系数PLP特征等。然而这些特征所含有的信息较为冗余,我们还需要进一步的方法将这些特征中所含有的说话人信息进行提纯。
2.说话人特征提取
在提取说话人特征的过程中采用了经典的DNN-ivector系统以及基于端到端深度神经网络的说话人特征(Dvector)提取系统。两套系统从不同的角度实现了对说话人特征的抓取。

小度声纹识别算法解析
A.算法1 DNN-ivector
这是目前被广泛采用的声纹识别系统。其主要特点就是将之前提取的声学特征通过按照一定的发声单元对齐后投影到一个较低的线性空间中,然后进行说话人信息的挖掘。直观上来说,可以理解成是在挖掘“不同的人在发同一个音时的区别是什么?”。
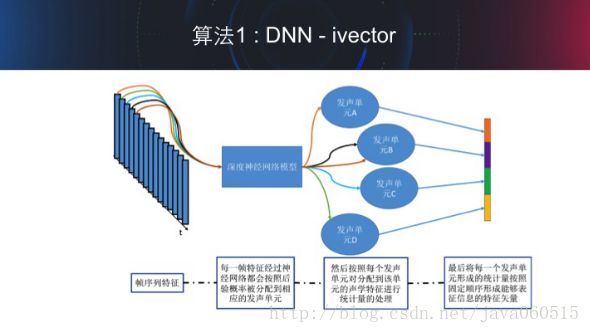
首先会用大量的数据训练一个能够将声学特征很好的对应到某一发声单元的神经网络,如下图所示。这样,每一帧特征通过神经网络后,就会被分配到某一发声单元上去。然后,我们会对每一句话在所有的发声单元进行逐个统计,按照每个发声单元没单位统计得到相应的信息。这样,对于每一句话我们就会得到一个高维的特征矢量。
在得到高维的特征矢量后,我们就会采用一种称之为total variability的建模方法对高维特征进行建模,
M=m+Tw
其中m是所有训练数据得到的均值超矢量,M则是每一句话的超矢量,T是奇通过大量数据训练得到的载荷空间矩阵,w则是降维后得到的ivector特征矢量,根据任务情况而言,一般取几百维。最后,对这个ivector采用概率线性判别分析PLDA建模,从而挖掘出说话人的信息。
在实际中,依托百度领先的语音识别技术训练了一个高精度的深度神经网络来进行发声单元的对齐,然后依托海量数据训练得到了载荷矩阵空间T,最后创造性地采用了自适应方法来进行调整T空间和PLDA空间,大大增强了模型在唱歌和说话跨方式以及短时上的声纹识别鲁棒性。
B.算法2 基于端到端深度学习的说话人信息提取
如果说上一套方法还借鉴了一些语音学的知识(采用了语音识别中的发声单元分类网络),那么基于端到端深度学习的说话人信息提取则是一个纯粹的数据驱动的方式。通过百度的海量数据样本以及非常深的卷积神经网络来让机器自动的去发掘声学特征中的说话人信息差异,从而提取出声学特征中的说话人信息表示。
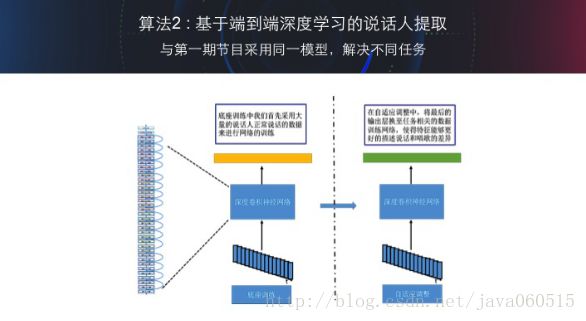
首先通过海量的声纹数据训练一个深度卷积神经网络,其输出的类别就是说话人的ID,实际训练中使用了数万个ID来进行网络的训练。从而得到了能够有效表征说话人特性底座网络。在根据特定场景的任务进行自适应调优。具体过程如下图所示:
在完成网络的训练后,就得到了一个能够提取说话人差异信息的网络,对每一句话通过该网络就得到了说话人的特征。
系统的融合
两套系统最后在得分域上进行了加权融合,从而给出最后的判决结果。
据高亮介绍,百度语音技术未来的主要技术方向包括金融反欺诈、客户呼叫中心、智能硬件声纹识别、安全领域声纹认证、个性化语音识别和语音合成辅助。
对于一胜一平的小度而言,下一轮比赛将成为“胜负手”,若战胜王昱珩,小度所代表的百度大脑将会进入《最强大脑》最终脑王的角逐,否则将遗憾退出。百度深度学习实验室主任林元庆认为,这次人机大战是以实战的方式来,来检验百度人工智能和人类差距。但是,打败人类并不是参赛的目的,而是希望在此过程中不断进步,演化出很好的技术来服务人类。
更多AI相关内容和业内领先案例,请关注【人工智能头条】
