重拾数据结构与算法(七)查找算法
java知识归纳总结
github: https://a870439570.github.io/interview-docs
顺序表查找
- 顺序查找又叫线性查找,是最基本的查找技术。
- 它的查找过程是:从表中第一个(或最后一个)记录开始,逐个进行记亲的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功 。
有序表查找
二分查找
- 在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;
- 若给定值小于中间记录的关键字,则在中间记录的左边部分继续查找;
- 若给定值大于中间记录的关键字,则在中间记录的右边部分继续查找。不断重复以上过程。
public static void main(String[] args) {
int[] number = {1,2,3,4,5,6,7,8,9,10};
int key = 5;
System.out.println("递归查找出的下标:"+binSearch(number,0,number.length-1,key));
System.out.println("查找出的下标:"+halfSort(number, key));
}
public static int halfSort(int[] data,int key){
int left=1, right=data.length;
while(left<=right){
int mid = (left+right)/2;
if(data[mid]>key){
right = mid-1;
}else if(data[mid]<key){
left = mid+1;
}else{
return mid;
}
}
return 0;
}
// 二分查找递归实现
public static int binSearch(int srcArray[], int start, int end, int key){
int mid = (end - start) / 2 + start;
if (srcArray[mid] == key) {
return mid;
}
if (start >= end) {
return -1;
} else if (key > srcArray[mid]) {
return binSearch(srcArray, mid + 1, end, key);
} else if (key < srcArray[mid]) {
return binSearch(srcArray, start, mid - 1, key);
}
return -1;
}
插值查找
- 插值查找是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法。
- 计算公式:
int mid=left+(right-left)*(key-data[left])/(data[right]-data[left]); - 从时间复杂度来 看,它也是O(logn),,但对表长比较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好得多
- 反之,数组中如果分布类似币,1,2,2000,2001…999998, 999999}这种极端不均匀的数据,用插值查找未必是很合适的选择
上述二分法查找计算中间值部分更换为计算公式即可实现插值查找
public static int halfSort(int[] data,int key){
int left=0, right=data.length-1;
while(left<=right){
int mid=left+(right-left)*(key-data[left])/(data[right]-data[left]); //插值
if(data[mid]>key){
right = mid-1;
}else if(data[mid]<key){
left = mid+1;
}else{
return mid;
}
}
return 0;
}
线性索引查找
- 索引就是把一个关键字与宫对应的记录相关联的过程 , 一个索引由若干个索引项构成,每个索引项至少应包含关键字和其对应的记录在存储器中的位置等信息
- 所谓线性索引就是将索引项集合组织为线性结构,也称为索引表。
稠密索引
- 稠密索引是指在线性索引中,将数据集中的每个记录对应一个索引项
- 对于稠密索引这个索引表来说,索引项一定是按照关键码有序的排列。索引项有序也就意味着,我们要查找关键字时,可以用到折半、插值、斐被那契 等有序查找算法,大大提高了效率 ,

public class Index {
public int key;
public Object value;
public int size;//分块存储数量
}
public class Student implements Comparable {
public Student(int no, String name) {
this.no = no;
this.name = name;
}
public int no;
public String name;
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
@Override
public int compareTo(Object o) {
Student other = (Student) o;
if (no < other.no) //这里比较的是什么 sort方法实现的就是按照此比较的东西从小到大排列
return -1;
if (no > other.no)
return 1;
return 0;
}
public static void main(String[] args) {
Student[] array=new Student[]{
new Student(2,"2222"),new Student(1,"1111"),
new Student(3,"3333"),new Student(4,"44444"),
new Student(5,"5555"),new Student(6,"7777"),
new Student(7,"7777"),new Student(8,"8888")};
int key=4;
System.out.println(denseIndex(array,8).toString());
}
//创建稠密索引表
public static Student denseIndex(Student[] array, int key) {
if (array != null && array.length > 0) {
//排序 对于稠密索引这个索引表来说,索引项一定是按照关键码有序的排列
Arrays.sort(array);
Index[] list = new Index[array.length];
//建立索引
for (int i = 0; i < array.length; i++) {
Index index = new Index();
index.key = array[i].no;
index.value = array[i];
list[i] = index;
}
//根据索引关键码搜索
int code = binarySearch(list, key);
if (code != -1) {
return (Student) list[code].value;
}
}
return null;
}
public static int binarySearch(Index[] array, int key) {
if (array.length > 0) {
int low, high, mid;
low = 0;
high = array.length - 1;
while (low <= high) {
mid = (low + high) / 2;//折半
if (key < array[mid].key)
high = mid - 1;
else if (key > array[mid].key)
low = mid + 1;
else
return mid;
}
}
return -1;
}
}
分块索引
- 稠密索引因为索引项与数据集的记录个数相同,所以空间代价很大。为了减少索引项的个数,我们可以对数据集进行分块,使其分块有序,然后再对每一块建立一个索引项,从而减少索引项的个数。
分块有序,是把数据集的记录分成了若干块,并且这些块需要满足两个条件:
- 块内无序,即每一块内的记录不要求有序。
- 块间有序,例如,要求第二块所有记录的关键字均要大于第一块中所有记录的关键字,第三块的所有记录的关键字均要大于第二块的所有 记录关键字…因为只有块间有序,才有可能在查找时带来放率。
对于分块有序的数据集,将每块对应一个索引项,这种索引方法叫做分块索引。我们定义的分块索引的索引项结构分三个数据项
- 最大关键码,它存储每一块中的最大关键字,这样的好处就是可以使得在它之后的下一块中的最小关键字也能比这一块最大的关键字要大 i
- 存储了块中的记录个数,以便于循环时使用;
- 用于指向块首数据元素的指针,便于开始对这一块中记景进行遍历。
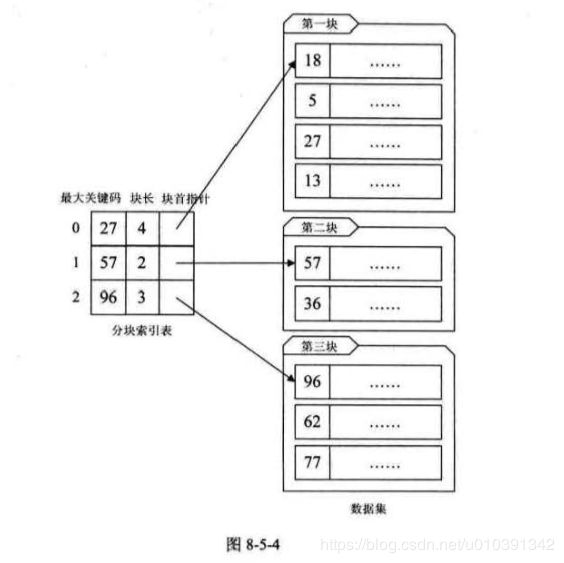
在分块索引表中查找,就是分两步进行:
- 在分块索引表中查找要查关键字所在的块。由于分块索引表是块间有序的, 因此很容易利用折半、插值等算法得到结果。例如,在图 8-5-4的数据集中 查找62,我们可以很快可以从左上角的索引表中由 57<62<96 得到 62 在第三 个块中。
- 根据块首指针找到相应的块,并在块中顺序查找关键码。因为块中可以是无序的,因此只能顺序查找。
public class BlockIndex {
public int[] index; //索引表
public ArrayList[] list; //块内元素 可以无序
//初始化分块索引表
public BlockIndex(int[] index) {
this.index=index;
this.list=new ArrayList[index.length];
for (int i = 0; i < list.length; i++) {
// 分配元素到各自的块内
list[i]=new ArrayList<>();
}
}
/**
* 分配块内元素
*/
public void insert(int value) {
for (int i = 0; i < index.length; i++) {
if(value<index[i]){
list[i].add(value);
break;
}
}
}
/**
* 打印每块元素
*/
public void printAll() {
for (int i = 0; i < list.length; i++) {
ArrayList l = list[i];
System.out.print("ArrayList" + i + ":");
for (int j = 0; j < l.size(); j++) {
System.out.print(l.get(j) + " ");
}
System.out.println();
}
}
/**
* 二分查找
*/
private int binarysearch(int value) {
int start = 0;
int end = index.length;
int mid = -1;
while (start <= end) {
mid = start + (end - start) / 2;
if (index[mid] > value) {
end = mid - 1;
} else {
start = mid + 1;
}
}
return start;
}
/**
* 查找元素
*/
public boolean search(int data) {
int i = binarysearch(data);
// 先二分查找确定在哪个块
for (int j = 0; j < list[i].size(); j++) {
// 然后顺序查找在该块内哪个位置
if (data == (int) list[i].get(j)) {
System.out.println(String.format("查找元素为 %d 第: %d块 第%d个 元素",data, i + 1, j + 1));
return true;
}
}
return false;
}
public static void main(String[] args) {
int [] data={1,12,22,10,18,23,5,15,27};
//分为三个块
int[] index = {10, 20, 30};
BlockIndex blocksearch=new BlockIndex(index);
for (int i = 0; i < data.length; i++) {
blocksearch.insert(data[i]);
}
blocksearch.printAll();
blocksearch.search(18);
}
}
倒排索引
- 现在有两篇极短的英文"文章"一一其实只能算是句子,我们暂认为是文章,编号分别是 1 和 2。

- 假设我们忽略掉如
books,friends中的复数s以及如A这样的大小写差异。我们可以整理出这样一张单词表,如表 8-5-1 所示,并将单词做了排序 , 也就是表格显示了每个不同的单词分别出现在哪篇文章中,比如good它在两篇文章中都有出现,而is只是在文章 2 中才有,

- 有了这样一张单词衰,我们要搜索文章,就非常方便了.如果在搜索框中搜索
book关键字。系统就先在这张单词表中有序查找 “book”,找到后将它对应的文章编号 1 和 2的文章地址(通常在搜索引擎中就是网页的标题和链接)返回,并告诉你,查找到两条记录,用时 0.0001 秒。由于单词表是有序的,查找效率很高,返回的又只是文章的编号,所以整体速度都非常快 。
在这里这张单词表就是索引表, 索引项的通用结构是:
- 次关键码.例如上面的"英文单词"。
- 记录号衰,例如上面的"文章编号" 。
其中记录号表存储具有相同次关键字的所有记录的记录号。这样的索引方法就是倒排索引
优点:
- 倒排索引的优点显然就是查找记录非常快,基本等于生成索引表后,查找时都不 用去读取记录,就可以得到结果。
缺点:
- 它的缺点是这个记录号不定长。维护比较困难,插入和删除操作都要做相应的处理。
package com.example.chazhao;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
/**
* 倒排索引
* 倒排索引的优点显然就是查找记录非常快,基本等于生成索引表后,查找时都不 用去读取记录,就可以得到结果
*
* 它的缺点是这个记录号不定长。维护比较困难,插入和删除操作都要做相应的处理
*
* 1.txt:i live in hangzhou where are you
2.txt:i love you i love you
3.txt:i love you today is a good day
*/
public class IntertedIndex {
// 存储单词对应 多个文件列表
private Map<String, ArrayList<String>> map=new HashMap<>();
//文路径列表
private ArrayList<String> list;
//词频统计
private Map<String, Integer> nums=new HashMap<>();
public void CreateIndex(String filepath){
String[] words = null;
try {
File file=new File(filepath);
BufferedReader reader=new BufferedReader(new FileReader(file));
String s=null;
while((s=reader.readLine())!=null){
//获取单词
words=s.split(" ");
}
for (String string : words) {
if (!map.containsKey(string)) {
//集合汇总不不存在当前单词
list=new ArrayList<String>();
list.add(filepath);
map.put(string, list); //单词对应的 文件列表
nums.put(string, 1); //单词出现的次数 首次默认1
}else {
list=map.get(string);
//如果没有包含过此文件名,则把文件名放入
if (!list.contains(filepath)) {
list.add(filepath);
}
//文件总词频数目
int count=nums.get(string)+1;
nums.put(string, count);
}
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
IntertedIndex index=new IntertedIndex();
for(int i=1;i<=2;i++){
String path="C:\\Users\\admin\\Desktop\\"+i+".txt";
index.CreateIndex(path);
}
for (Map.Entry<String, Integer> num : index.nums.entrySet()) {
System.out.println("单词:"+num.getKey()+" "
+ "出现次数:"+num.getValue()+" "+index.map.get(num.getKey()));
}
}
}
二叉排序树
二叉排序树 又称为二叉查找树。它或者是一棵空树,或者是具有下列性质的二叉树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结构的值
- 若它的右子树不空 ,则右子树上所有结点的值均大于宫的根结点的值
- 它的左、右子树也分别为二叉排序树
- 它的结点间满足一定的次序关系,左子树结点一定比其双亲结点小,右子树结点一定比其双亲结点大。
- 构造一棵二叉排序树的目的,其实并不是为了排序,而是为了提高查找和插入删除关键字的速度
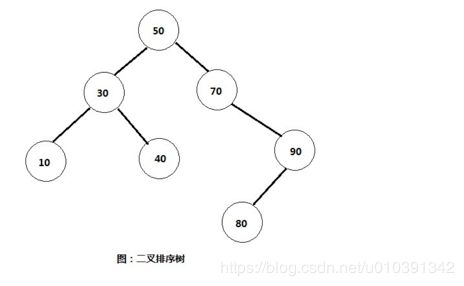
插入节点
(1)首先将20与根节点进行比较,发现比根节点小,所以继续与根节点的左子树30比较。
(2)发现20比30也要小,所以继续与30的左子树10进行比较。
(3)发现20比10要大,所以就将20插入到10的右子树中。

查找节点
比如我们要查找节点10,那么思路如下:
(1)还是一样,首先将10与根节点50进行比较,发现比根节点要小,所以继续与根节点的左子树30进行比较。
(2)发现10比左子树30要小,所以继续与30的左子树10进行比较。
(3)发现两值相等,即查找成功,返回10的位置。
删除节点
删除节点的情况相对复杂,主要分为以下三种情形:
删除的是叶节点(即没有孩子节点的)。比如20,删除它不会破坏原来树的结构,最简单。如图所示
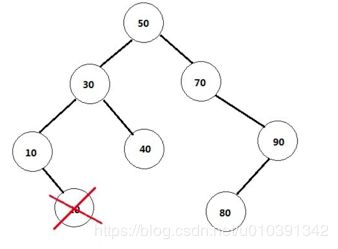
删除的是单孩子节点。比如90,删除它后需要将它的孩子节点与自己的父节点相连。情形比第一种复杂一些。

删除的是有左右孩子的节点。比如根节点50
这里有一个问题就是删除它后,谁将作为根节点?利用二叉树的中序遍历,就是右节点的左子树的最左孩子。

public class Node {
private int value;// 结点值
protected Node leftChild;// 左孩子结点
protected Node rightChild;// 右孩子结点
public Node(int value) {
this.value = value;
this.leftChild = null;
this.rightChild = null;
}
public void setValue(int value) {
this.value = value;
}
public int getValue() {
return value;
}
}
public class SortTree {
// 递归实现二叉排序树的插入
public void insertBST(Node root, int value) {
if (root == null) {
root = new Node(value);
root.leftChild = null;
root.rightChild = null;
}
//大于根节点则 分配在右子树
if (value > root.getValue()) {
//如果右子树为空则直接赋值给右子树
if (root.rightChild == null) {
root.rightChild = new Node(value);
} else {
//右子树不为空,则递归判断,以右子树为父节点的
insertBST(root.rightChild, value);
}
} else {
//左子树分配原理同上
if (root.leftChild == null) {
root.leftChild = new Node(value);
} else {
insertBST(root.leftChild, value);
}
}
}
// 递归实现二叉排序树查找
public Node searchBSTByRecursion(Node root, int value) {
if (root == null) {
return null;
}
if (root.getValue() == value) {// 步骤1
return root;
} else if (value < root.getValue()) {// 步骤2
return searchBST(root.leftChild, value);
} else if (value > root.getValue()) {// 步骤3
return searchBST(root.rightChild, value);
}
return null;// 如果没找到,就返回null
}
// 非递归实现二叉排序树查找
public Node searchBST(Node root, int value) {
Node temp = root;
while (temp != null) {
if (temp.getValue() == value) {
return temp;
}
if (value < temp.getValue()) {
temp = temp.leftChild;
} else {
temp = temp.rightChild;
}
}
return null;
}
// 二叉排序树的删除
public Node deleteBST(Node root, int value) {
Node cur = root; // 当前结点
Node parent = null; // 待删结点的父结点
Node delNode = null; // 在后面用来引用待删结点
Node temp = null; // 作为一个局域内的根结点
// 查找待删结点p和待删结点的父结点f
while (cur != null) {
if (value == cur.getValue()) {
break;
}
parent = cur;
if (value > cur.getValue()) {
cur = cur.rightChild;
} else {
cur = cur.leftChild;
}
}
// 当前结点为null,即没有找到待删结点。 此时cur指向待删结点
if (cur == null) {
return null;
}
// 待删结点只有右子树
if (cur.leftChild == null) {
// 待删结点的父结点为null,即待删结点为根结点
if (parent == null) {
// 根结点为待删结点的右子树
root = cur.rightChild;
} else if (parent.leftChild == cur) { // 待删结点为父结点的左子树
// 把待删结点的右子树作为待删结点父结点的左子树
parent.leftChild = cur.rightChild;
} else { // 待删结点为父结点的右子树
parent.rightChild = cur.rightChild;
}
} else {// 待删结点有左子树,要找左子树的最右下角的结点
temp = cur;
delNode = cur.leftChild; // 此时s指向待删结点
while (delNode.rightChild != null) {// 查找待删结点的最右下角结点
temp = delNode;
delNode = delNode.rightChild;
}
if (temp == cur) {// 即,待删结点没有右子树,把左子树向上移动
temp.leftChild = delNode.leftChild;
} else {// 即,待删结点有右子树
temp.rightChild = delNode.leftChild;
}
cur.setValue(delNode.getValue());
}
return root;
}
//先序遍历
public void preOrder(Node root) {
if(root != null) {
System.out.print(root.getValue() + " ");
preOrder(root.leftChild);
preOrder(root.rightChild);
}
}
/**
* 先序遍历
* 非递归
*/
public void preOrder1(Node root){
Stack<Node> stack = new Stack<>();
while(root != null || !stack.empty()){
while(root != null) {
System.out.print(root.getValue() + " ");
stack.push(root);
root = root.leftChild;
}
if(!stack.empty()){
root = stack.pop();
root = root.rightChild;
}
}
}
//中序遍历
public void inOrder(Node root) {
if(root != null) {
inOrder(root.leftChild);
System.out.print(root.getValue() + " ");
inOrder(root.rightChild);
}
}
/**
* 中序遍历
* 非递归
*/
public void inOrder1(Node root) {
Stack<Node> stack = new Stack<>();
while(root != null || !stack.empty()){
while (root != null){
stack.push(root);
root = root.leftChild;
}
if(!stack.empty()){
root = stack.pop();
System.out.print(root.getValue() + " ");
root = root.rightChild;
}
}
}
//后序遍历
public void postOrder(Node root) {
if(root != null) {
postOrder(root.leftChild);
postOrder(root.rightChild);
System.out.print(root.getValue() + " ");
}
}
/**
* 后序遍历
* 非递归
*/
public void posOrder1(Node root){
Stack<Node> stack1 = new Stack<>();
Stack<Integer> stack2 = new Stack<>();
int i = 1;
while(root != null || !stack1.empty()){
while (root != null){
stack1.push(root);
stack2.push(0);
root = root.leftChild;
}
while(!stack1.empty() && stack2.peek() == i){
stack2.pop();
System.out.print(stack1.pop().getValue() + " ");
}
if(!stack1.empty()){
stack2.pop();
stack2.push(1);
root = stack1.peek();
root = root.rightChild;
}
}
}
public static void main(String[] args) {
SortTree t=new SortTree();
Node root=new Node(44); //根节点
t.insertBST(root, 21); //左子树
t.insertBST(root, 65); //右子树
t.insertBST(root, 14);
t.insertBST(root, 72);
t.insertBST(root, 32);
t.insertBST(root, 58);
t.insertBST(root, 80);
t.postOrder(root);
System.out.println("-----------------");
t.posOrder1(root);
// t.deleteBST(root, 44);
System.out.println();
// t.preOrder(t.deleteBST(root, 44));
}
}
平衡二叉树(AVL树)
- 是一种二叉排序树,其中每一个节点的左子树和右子树的高度差至多等于1
- 它是一种高度平衡的二叉排序树。要么它是一棵空树,要么它的左子树和右子树都是平衡二叉树, 旦左子树和右子树的深度之差的绝对值不超过 1
- 我们将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF。平衡二叉树上所有结点的平衡因乎只可能是-1 , 0 和 1.
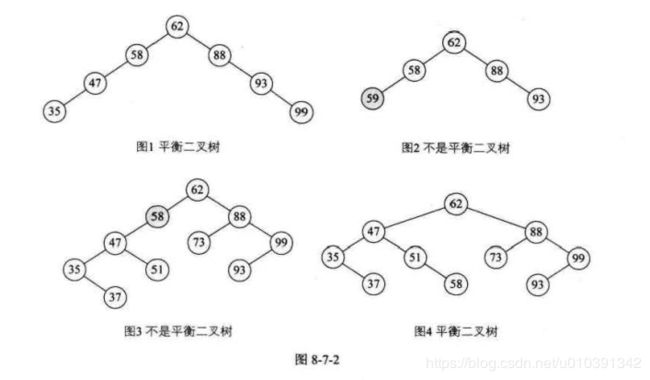
- 图二 59 比 58 大却是 58 的左子树,这是不符合二叉排序树的定义的
- 图 3 不是平衡二叉树的原因就在于,结点 58 的左子树高度为 2 ,而右子树为空,二者差大于了绝对值 1
距离插入结点最近的,且平衡困子的绝对值大于 1 的结点为根的子树,我们称为最小不平衡子树

- 上图当新插入结点37时,距离它最近的平衡因子绝对值超过1的结点是58 (即它的左子树高度2减去右子树高度的,所以从58 开始以下的子树为最小不平衡子树 。
public class AVLNode<T extends Comparable> {
public AVLNode<T> left;//左结点
public AVLNode<T> right;//右结点
public T data;
public int height;//当前结点的高度
public AVLNode(T data) {
this(null,null,data);
}
public AVLNode(AVLNode<T> left, AVLNode<T> right, T data) {
this(left,right,data,0);
}
public AVLNode(AVLNode<T> left, AVLNode<T> right, T data, int height) {
this.left=left;
this.right=right;
this.data=data;
this.height = height;
}
}
public class AVLTree<T extends Comparable> {
public AVLNode<T> root;
public boolean isEmpty() {
return root == null;
}
public int size() {
return size(root);
}
public int size(AVLNode<T> subtree) {
if (subtree == null) {
return 0;
} else {
return size(subtree.left) + 1 + size(subtree.right);
}
}
public int height() {
return height(root);
}
/**
* @param p
* @return
*/
public int height(AVLNode<T> p) {
return p == null ? -1 : p.height;
}
public String preOrder() {
String sb = preOrder(root);
if (sb.length() > 0) {
// 去掉尾部","号
sb = sb.substring(0, sb.length() - 1);
}
return sb;
}
/**
* 先根遍历
*
* @param subtree
* @return
*/
public String preOrder(AVLNode<T> subtree) {
StringBuilder sb = new StringBuilder();
if (subtree != null) {
// 先访问根结点
sb.append(subtree.data).append(",");
// 访问左子树
sb.append(preOrder(subtree.left));
// 访问右子树
sb.append(preOrder(subtree.right));
}
return sb.toString();
}
public String inOrder() {
String sb = inOrder(root);
if (sb.length() > 0) {
// 去掉尾部","号
sb = sb.substring(0, sb.length() - 1);
}
return sb;
}
/**
* 中根遍历
*
* @param subtree
* @return
*/
private String inOrder(AVLNode<T> subtree) {
StringBuilder sb = new StringBuilder();
if (subtree != null) {
// 访问左子树
sb.append(inOrder(subtree.left));
// 访问根结点
sb.append(subtree.data).append(",");
// 访问右子树
sb.append(inOrder(subtree.right));
}
return sb.toString();
}
public String postOrder() {
String sb = postOrder(root);
if (sb.length() > 0) {
// 去掉尾部","号
sb = sb.substring(0, sb.length() - 1);
}
return sb;
}
/**
* 后根遍历
*
* @param subtree
* @return
*/
private String postOrder(AVLNode<T> subtree) {
StringBuilder sb = new StringBuilder();
if (subtree != null) {
// 访问左子树
sb.append(postOrder(subtree.left));
// 访问右子树
sb.append(postOrder(subtree.right));
// 访问根结点
sb.append(subtree.data).append(",");
}
return sb.toString();
}
public String levelOrder() {
/**
* @see BinarySearchTree#levelOrder()
* @return
*/
return null;
}
/**
* 插入方法
*
* @param data
*/
public void insert(T data) {
if (data == null) {
throw new RuntimeException("data can\'t not be null ");
}
this.root = insert(data, root);
}
private AVLNode<T> insert(T data, AVLNode<T> p) {
// 说明已没有孩子结点,可以创建新结点插入了.
if (p == null) {
p = new AVLNode<T>(data);
}
int result = data.compareTo(p.data);
if (result < 0) {// 向左子树寻找插入位置
p.left = insert(data, p.left);
// 插入后计算子树的高度,等于2则需要重新恢复平衡,由于是左边插入,左子树的高度肯定大于等于右子树的高度
if (height(p.left) - height(p.right) == 2) {
// 判断data是插入点的左孩子还是右孩子
if (data.compareTo(p.left.data) < 0) {
// 进行LL旋转
p = singleRotateLeft(p);
} else {
// 进行左右旋转
p = doubleRotateWithLeft(p);
}
}
} else if (result > 0) {// 向右子树寻找插入位置
p.right = insert(data, p.right);
if (height(p.right) - height(p.left) == 2) {
if (data.compareTo(p.right.data) < 0) {
// 进行右左旋转
p = doubleRotateWithRight(p);
} else {
p = singleRotateRight(p);
}
}
} else
;// if exist do nothing
// 重新计算各个结点的高度
p.height = Math.max(height(p.left), height(p.right)) + 1;
return p;// 返回根结点
}
/**
* 删除方法
*
* @param data
*/
public void remove(T data) {
if (data == null) {
throw new RuntimeException("data can\'t not be null ");
}
this.root = remove(data, root);
}
/**
* 删除操作
*
* @param data
* @param p
* @return
*/
private AVLNode<T> remove(T data, AVLNode<T> p) {
if (p == null)
return null;
int result = data.compareTo(p.data);
// 从左子树查找需要删除的元素
if (result < 0) {
p.left = remove(data, p.left);
// 检测是否平衡
if (height(p.right) - height(p.left) == 2) {
AVLNode<T> currentNode = p.right;
// 判断需要那种旋转
if (height(currentNode.left) > height(currentNode.right)) {
// RL
p = doubleRotateWithRight(p);
} else {
// RR
p = singleRotateRight(p);
}
}
}
// 从右子树查找需要删除的元素
else if (result > 0) {
p.right = remove(data, p.right);
// 检测是否平衡
if (height(p.left) - height(p.right) == 2) {
AVLNode<T> currentNode = p.left;
// 判断需要那种旋转
if (height(currentNode.right) > height(currentNode.left)) {
// LR
p = doubleRotateWithLeft(p);
} else {
// LL
p = singleRotateLeft(p);
}
}
}
// 已找到需要删除的元素,并且要删除的结点拥有两个子节点
else if (p.right != null && p.left != null) {
// 寻找替换结点
p.data = findMin(p.right).data;
// 移除用于替换的结点
p.right = remove(p.data, p.right);
} else {
// 只有一个孩子结点或者只是叶子结点的情况
p = (p.left != null) ? p.left : p.right;
}
// 更新高度值
if (p != null)
p.height = Math.max(height(p.left), height(p.right)) + 1;
return p;
}
/**
* 查找最小值结点
*
* @param p
* @return
*/
private AVLNode<T> findMin(AVLNode<T> p) {
if (p == null)// 结束条件
return null;
else if (p.left == null)// 如果没有左结点,那么t就是最小的
return p;
return findMin(p.left);
}
public T findMin() {
return findMin(root).data;
}
public T findMax() {
return findMax(root).data;
}
/**
* 查找最大值结点
*
* @param p
* @return
*/
private AVLNode<T> findMax(AVLNode<T> p) {
if (p == null)
return null;
else if (p.right == null)// 如果没有右结点,那么t就是最大的
return p;
return findMax(p.right);
}
public boolean contains(T data) {
return data != null && contain(data, root);
}
public boolean contain(T data, AVLNode<T> subtree) {
if (subtree == null)
return false;
int result = data.compareTo(subtree.data);
if (result < 0) {
return contain(data, subtree.left);
} else if (result > 0) {
return contain(data, subtree.right);
} else {
return true;
}
}
/**
* 左左单旋转(LL旋转) w变为x的根结点, x变为w的右子树
*
* @param x
* @return
*/
private AVLNode<T> singleRotateLeft(AVLNode<T> x) {
// 把w结点旋转为根结点
AVLNode<T> w = x.left;
// 同时w的右子树变为x的左子树
x.left = w.right;
// x变为w的右子树
w.right = x;
// 重新计算x/w的高度
x.height = Math.max(height(x.left), height(x.right)) + 1;
w.height = Math.max(height(w.left), x.height) + 1;
return w;// 返回新的根结点
}
/**
* 右右单旋转(RR旋转) x变为w的根结点, w变为x的左子树
*
* @return
*/
private AVLNode<T> singleRotateRight(AVLNode<T> w) {
AVLNode<T> x = w.right;
w.right = x.left;
x.left = w;
// 重新计算x/w的高度
x.height = Math.max(height(x.left), w.height) + 1;
w.height = Math.max(height(w.left), height(w.right)) + 1;
// 返回新的根结点
return x;
}
/**
* 左右旋转(LR旋转) x(根) w y 结点 把y变成根结点
*
* @return
*/
private AVLNode<T> doubleRotateWithLeft(AVLNode<T> x) {
// w先进行RR旋转
x.left = singleRotateRight(x.left);
// 再进行x的LL旋转
return singleRotateLeft(x);
}
/**
* 右左旋转(RL旋转)
*
* @param w
* @return
*/
private AVLNode<T> doubleRotateWithRight(AVLNode<T> w) {
// 先进行LL旋转
w.right = singleRotateLeft(w.right);
// 再进行RR旋转
return singleRotateRight(w);
}
private void printTree(AVLNode<T> t) {
if (t != null) {
printTree(t.left);
System.out.println(t.data);
printTree(t.right);
}
}
/**
* 测试
*
* @param arg
*/
public static void main(String arg[]) {
AVLTree<Integer> avlTree = new AVLTree<>();
for (int i = 1; i < 18; i++) {
avlTree.insert(i);
}
avlTree.printTree(avlTree.root);
// 删除11,8以触发旋转平衡操作
avlTree.remove(11);
avlTree.remove(8);
System.out.println("================");
avlTree.printTree(avlTree.root);
System.out.println("findMin:" + avlTree.findMin());
System.out.println("findMax:" + avlTree.findMax());
System.out.println("15 exist or not : " + avlTree.contains(15));
System.out.println("先根遍历:" + avlTree.preOrder());
System.out.println("中根遍历:" + avlTree.inOrder());
System.out.println("后根遍历:" + avlTree.postOrder());
}
}
散列表查找
- 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字 key 对应一个存储位置 f (key) 这里我们把这种对应关系 f 称为散列函数 , 又称为哈希 (Hash) 函数。
- 采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表。那么关键字对应的记录存储位置我们称为散列地址。
- 散列技术最适合的求解问题是查找与给定值相等的记录。必须是一对一的关系。不适合范围区间查找
整个散列过程其实就是两步
- 存储肘,通过散列函数计算记录 的散列地址,并按此散列地址存储该记录
- 查找记录时,我们通过同样的散列函数计算记录的散列地址,按此散到地址访问该记录 。
散列函数的构造方法
- 散列函数的计算时间不应该超过其他查找技术与关键字比较的时间。
- 尽量让散列地址均匀地分布在存储空间中
直接定址法
- 这样的散列函数优点就是简单 ,均匀,也不会产生冲突
- 问题是这需要事先知道关键字的分布情况,适合查找表较小且连续的情况
- 此方法虽然简单,但却并不常用
比如我们要对 0 到100岁的人口数字统计表那么我们对年龄这个关键字就可以直接用年龄的数字作为地址。此时 f (key) =key
f ( key ) =a*key+b(a,b为常数)
数字分析法
- 比如我们的 11 位 手机号前三位是接入号应不同运营商公司的子品牌,中间四位HLR识别号,表示用户号的归属地;后四位才是真正的用户号。选择后面的四位成为散列地址就是不错的选择,并且还可以对抽取出来的数字再进行反转,左环位移等
- 数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布较均匀,就可以考虑用这个方法。
平方取中法
- 假设关键字是1234,那么它的平方就是1522756,再抽取中间的3位就是227,用做散列地址
- 平方取中法比较适合子不知道关键字的分布,而位数又不是很大的情况
折叠法
- 折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短些) ,然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
- 比如我们的关键字是 9876543210 ,散列表表长为三位,我们将它分为四组,9871654132110 , 然后将它们叠加求和
987+654+321+0=1962,再求后 3 位得到散列地址为 962 。 - 折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况
除留余敢法
- 此方法为最常用的构造散列函数方法。 对于散列裴长为 m 的散列函数公式为
f( key) = key %p (p <= m) - 若散列表表长为 m,通常 p 为小于或等于表长(最好接近m) 的最小质数或不包含小于20 质因子的合数。
随机数法
- 选择一个随机数,取关键字的随机函数值为它的散列地址。也就是
f (key)=random (key )。这里 random 是随机函数。当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。
处理散列冲突的方法
开放定址法
- 所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
公式:f(key)=(f(key)+d)% m d等于(1,2,3…m-1 )
- 比如说,我仍的关键字集合为{1 2,67,56,16,25,37,22,29,15,47.4B,34}表长为12我们用散列函
f(key)=ke%12 - 计算前 5 个数{1 2,67,56,16,25}时,都是没有冲突的散列地址,直接存入
- 计算 key=37 时,发现 f (37) =1 ,此时就与 25 所在的位置冲突。 于是使用开放定址法
f(37)=(f(37)+1)%12=2。加入还是重负d就是不断进行累加 - 我们把这种解决冲突的开放定址法称为线性探测法
再散列函数法
- 此方法对于我们的散列表来说,我们事先准备多个散列函数。每当发生散到地址冲突肘,就换一个散列函数计算,相信总会有一
个可以把冲突解决掉
链地址法
- 将所有关键字为同义词的记录存储在一个单链表中,我们称这种表为同义词子表,在散列表中只存储所有同义词子表的头指针。
- 对于关键字集合{12,67,S6,16,25.37,22,29,lS,47,48,34} ,我们用前面同样的 12 为除数,进行除留余数法,可得到如图
8-11-1 结构,此时, 已经不存在什么冲突换址的问题,无论有多少个冲突,都只是在当前位置给单链裴增加结点的问题 。
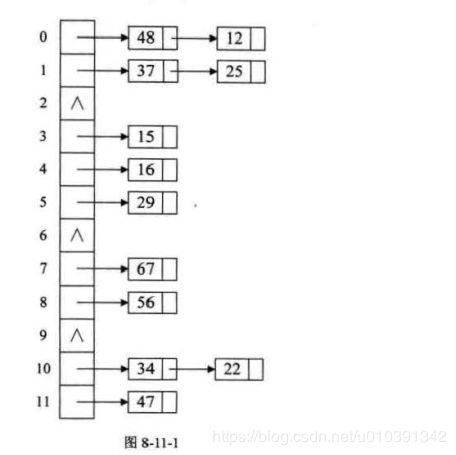
链地址法对于可能会造成很多冲突的散列函数来说,提供了绝不会出现找不到地址的保障。当然,这也就带来了查找时需要遍历单链装的性能损耗。
公共溢出区法
- 凡是冲突的都跟我走,我给你们这些冲突找个地儿待着。这就如同孤儿院收留所有无家可归的孩子一样,我们为
所有冲突的关键字建立了一个公共的溢出区来存放.
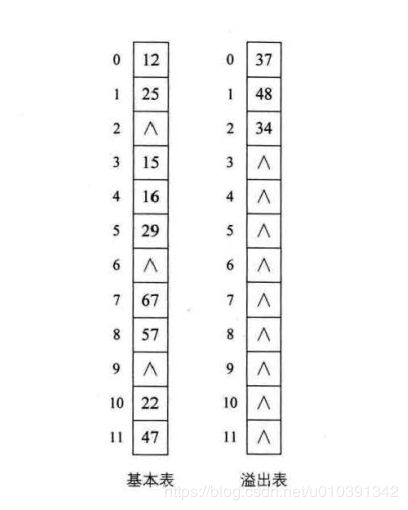
- 在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行比对,如果相等,则查找成功 i 如果不相等,则到溢出表去进行j帧序查找。
- 如果相对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对查找性能来说还是非常高的。