数据挖掘——聚类算法
一、问题描述
分别用k均值、合并聚类和DBSCAN聚类算法对鸢尾花数据集聚类,并检验结果是否与数据标签一致。
二、实验目的
学习聚类算法。
三、实验内容
1. 分别用k均值、合并聚类和DBSCAN聚类算法对鸢尾花数据集聚类,并检验结果是否与数据标签一致。
2. 数据导入

3.主要代码

四、实验结果及分析
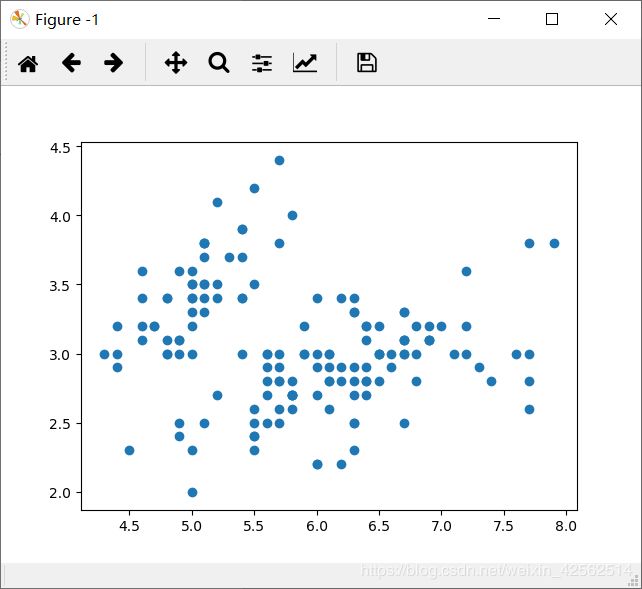
原始数据
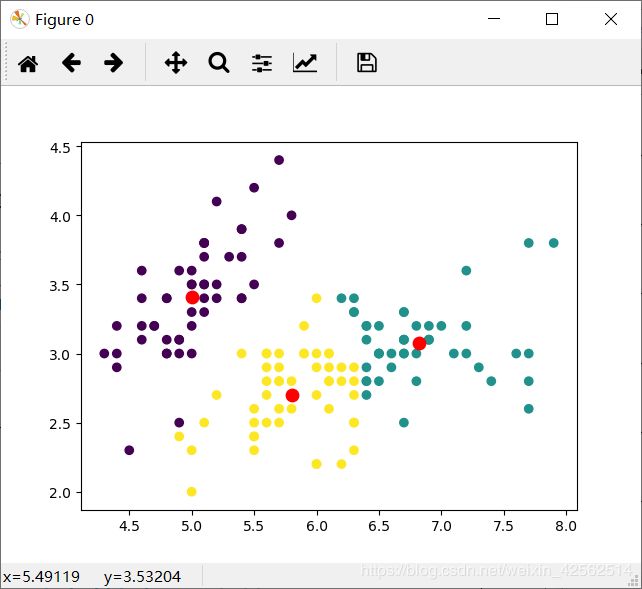
1. k均值model = KMeans(n_clusters = 3,max_iter = 100)
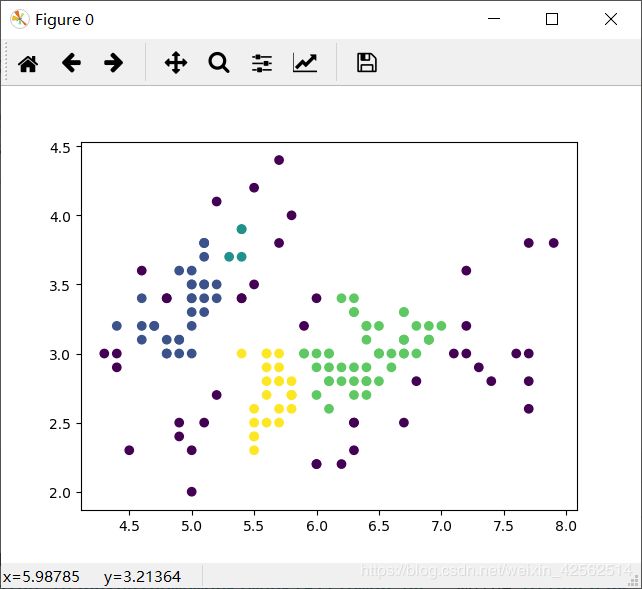
2. 合并聚类agg = AgglomerativeClustering(n_clusters=4)

3. DBSCAN聚类算法dbscan = db.DBSCAN(eps=0.2, min_sample = 3)
五、完整代码
agglomerative_clustering.py
import numpy as np
import heapq
class AgglomerativeClustering:
def __init__(self, n_clusters = 1):
self.k = n_clusters
def fit_transform(self, X):
m, n = X.shape
C, centers = {}, {}
assignments = np.zeros(m)
for id in range(m):
C[id] = [id]
centers[id] = X[id]
assignments[id] = id
H = []
for i in range(m):
for j in range(i+1, m):
d = np.linalg.norm(X[i] - X[j], 2)
heapq.heappush(H, (d, [i, j]))
new_id = m
while len(C) > self.k:
distance, [id1, id2] = heapq.heappop(H)
if id1 not in C or id2 not in C:
continue
C[new_id] = C[id1] + C[id2]
for i in C[new_id]:
assignments[i] = new_id
del C[id1], C[id2], centers[id1], centers[id2]
new_center = sum(X[C[new_id]]) / len(C[new_id])
for id in centers:
center = centers[id]
d = np.linalg.norm(new_center - center, 2)
heapq.heappush(H, (d, [id, new_id]))
centers[new_id] = new_center
new_id += 1
return np.array(list(centers.values())), assignments
dbscan3.py
import numpy as np
class DBSCAN:
def __init__(self, eps = 0.5, min_sample = 5):
self.eps = eps
self.min_sample = min_sample
def get_neighbors(self, X, i):
m = len(X)
distances = [np.linalg.norm(X[i] - X[j], 2) for j in range(m)]
neighbors_i = [j for j in range(m) if distances[j] < self.eps]
return neighbors_i
def grow_cluster(self, X, i, neighbors_i, id):
self.assignments[i] = id
Q = neighbors_i
t = 0
while t < len(Q):
j = Q[t]
t += 1
if self.assignments[j] == 0:
self.assignments[j] = id
neighbors_j = self.get_neighbors(X, j)
if len(neighbors_j) > self.min_sample:
Q += neighbors_j
def fit_transform(self, X):
self.assignments = np.zeros(len(X))
id = 1
for i in range(len(X)):
if self.assignments[i] != 0:
continue
neighbors_i = self.get_neighbors(X, i)
if len(neighbors_i) > self.min_sample:
self.grow_cluster(X, i, neighbors_i, id)
id += 1
return self.assignments
flower.py
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from week15.k_means import KMeans
from week15.agglomerative_clustering import AgglomerativeClustering
import week15.dbscan3 as db
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris["data"][:, (0, 1)]
y = 2* (iris["target"] == 0).astype(np.int)-1
X_train, X_test, y_train, y_test = train_test_split(X ,y ,test_size=0.4,random_state=5)
plt.figure(-1)
plt.scatter(X[:, 0],X[:, 1])
#k均值
model = KMeans(n_clusters = 3,max_iter = 100)
centers, assignments = model.fit_transform(X)
plt.figure(0)
plt.scatter(X[:, 0], X[:, 1], c = assignments)
plt.scatter(np.array(centers)[:,0],np.array(centers)[:,1],c = 'r',s=80)
plt.show()
#合并聚类
agg = AgglomerativeClustering(n_clusters=4)
agg_center, agg_assignments = agg.fit_transform(X)
plt.figure(0)
plt.scatter(X[:, 0], X[:, 1])
plt.scatter(agg_center[:, 0], agg_center[:, 1], c='b',marker='*',s = 300)
#DBSCAN聚类算法
dbscan = db.DBSCAN(eps=0.2, min_sample = 3)
db_assignments = dbscan.fit_transform(X)
plt.figure(0)
plt.scatter(X[:, 0], X[:, 1], c = db_assignments)
plt.show()k_means.py
import numpy as np
class KMeans:
def __init__(self, n_clusters = 1, max_iter = 50, random_state=0):
self.k = n_clusters
self.max_iter = max_iter
np.random.seed(random_state)
def assign_to_centers(self, centers, X):
assignments = []
for i in range(len(X)):
distances = [np.linalg.norm(X[i] - centers[j], 2) for j in range(self.k)]
assignments.append(np.argmin(distances))
return assignments
def adjust_centers(self, assignments, X):
new_centers = []
for j in range(self.k):
cluster_j = [X[i] for i in range(len(X)) if assignments[i] == j]
new_centers.append(np.mean(cluster_j, axis=0))
return new_centers
def fit_transform(self, X):
idx = np.random.randint(0, len(X), self.k)
centers = [X[i] for i in idx]
for iter in range(self.max_iter):
assignments = self.assign_to_centers(centers, X)
centers = self.adjust_centers(assignments, X)
return np.array(centers), np.array(assignments)