Elasticsearch6.2 研究--介绍与安装
目录
- 1 Elasticsearch6.2介绍
- 1.1 介绍
- 1.2原理与应用
- 1.2.1索引结构
- 1.2.3 RESTful应用方法
- 2 Elasticasearch6.2安装
- 2.1 安装
- 2.2 配置文件
- 2.2.1 三个配置文件
- 2.2.2 Elasticsearch.yml
- 2.2.3 jvm.options
- 2.2.4 log4j2.properties
- 2.2.5 系统配置
- 2.3 启动ES
- 2.4 head插件安装
1 Elasticsearch6.2介绍
1.1 介绍
引用百度百科中的描述:
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
官方网址:https://www.elastic.co/cn/products/Elasticsearch
Github:https://github.com/elastic/Elasticsearch
总结:
1、Elasticsearch是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用。
2、Elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
突出优点:
1.扩展性好,可部署上百台服务器集群,处理PB级数据。
2.近实时的去索引数据、搜索数据。
es和solr选择哪个?
1.如果你公司现在用的solr可以满足需求就不要换了。
2.如果你公司准备进行全文检索项目的开发,建议优先考虑Elasticsearch,因为像Github这样大规模的搜索都在用它。
1.2原理与应用
1.2.1索引结构
下图是Elasticsearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述Elasticsearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和docment都有关联。
如下:
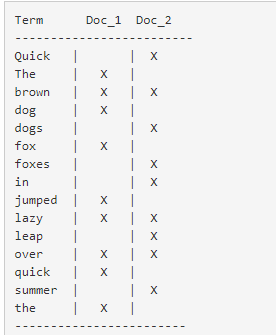
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
1.2.3 RESTful应用方法
如何使用es?
Elasticsearch提供 RESTful Api接口进行索引、搜索,并且支持多种客户端。
下图是es在项目中的应用方式:
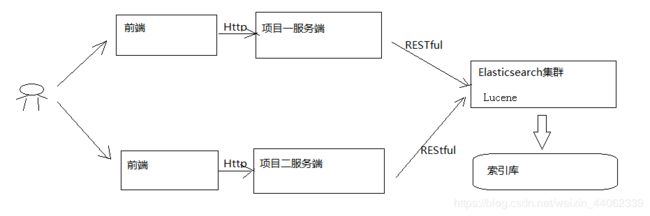
1)用户在前端搜索关键字
2)项目前端通过http方式请求项目服务端
3)项目服务端通过Http RESTful方式请求ES集群进行搜索
4)ES集群从索引库检索数据。
2 Elasticasearch6.2安装
2.1 安装
安装配置:
1、新版本要求至少jdk1.8以上。
2、支持tar、zip、rpm等多种安装方式。
在windows下开发建议使用ZIP安装方式。
3、支持docker方式安装
详细参见:https://www.elastic.co/guide/en/Elasticsearch/reference/current/install-Elasticsearch.html
下载ES: Elasticsearch 6.2.1
https://www.elastic.co/downloads/past-releases
解压 Elasticsearch-6.2.1.zip

bin:脚本目录,包括:启动、停止等可执行脚本
config:配置文件目录
data:索引目录,存放索引文件的地方
logs:日志目录
modules:模块目录,包括了es的功能模块
plugins :插件目录,es支持插件机制
2.2 配置文件
2.2.1 三个配置文件
ES的配置文件的地址根据安装形式的不同而不同:
使用zip、tar安装,配置文件的地址在安装目录的config下。
使用RPM安装,配置文件在/etc/Elasticsearch下。
使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF。
本教程使用的zip包安装,配置文件在ES安装目录的config下。
配置文件如下:
Elasticsearch.yml : 用于配置Elasticsearch运行参数
jvm.options : 用于配置Elasticsearch JVM设置
log4j2.properties: 用于配置Elasticsearch日志
2.2.2 Elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
方式1:层次方式
path:
data: /var/lib/Elasticsearch
logs: /var/log/Elasticsearch
方式2:属性方式
path.data: /var/lib/Elasticsearch
path.logs: /var/log/Elasticsearch
本项目采用方式2,例子如下:
cluster.name: xuecheng
node.name: xc_node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
#discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: false
node.max_local_storage_nodes: 1
path.data: D:\Elasticsearch\Elasticsearch-6.2.1\data
path.logs: D:\Elasticsearch\Elasticsearch-6.2.1\logs
http.cors.enabled: true
http.cors.allow-origin: /.*/
注意path.data和path.logs路径配置正确。
常用的配置项如下:
cluster.name:
配置Elasticsearch的集群名称,默认是Elasticsearch。建议修改成一个有意义的名称。
node.name:
节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.conf:
设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ Elasticsearch
path.data:
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。
path.logs:
设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins:
设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.memory_lock: true
设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。
network.host:
设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。
http.port: 9200
设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 集群结点之间通信端口
node.master:
指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。
node.data:
指定该节点是否存储索引数据,默认为true。
discovery.zen.ping.unicast.hosts: [“host1:port”, “host2:port”, “…”]
设置集群中master节点的初始列表。
discovery.zen.ping.timeout: 3s
设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。
discovery.zen.minimum_master_nodes:
主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
node.max_local_storage_nodes:
单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1.
2.2.3 jvm.options
设置最小及最大的JVM堆内存大小:
在jvm.options中设置 -Xms和-Xmx:
1) 两个值设置为相等
2) 将Xmx 设置为不超过物理内存的一半。
2.2.4 log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
2.2.5 系统配置
在linux上根据系统资源情况,可将每个进程最多允许打开的文件数设置大些。
su limit -n 查询当前文件数
使用命令设置limit:
先切换到root,设置完成再切回Elasticsearch用户。
sudo su
ulimit -n 65536
su Elasticsearch
也可通过下边的方式修改文件进行持久设置
/etc/security/limits.conf
将下边的行加入此文件:
Elasticsearch - nofile 65536
2.3 启动ES
进入bin目录,在cmd下运行:Elasticsearch.bat
浏览器输入:http://localhost:9200
显示结果如下(配置不同内容则不同)说明ES启动成功:
{
"name" : "xc_node_1",
"cluster_name" : "xuecheng",
"cluster_uuid" : "J18wPybJREyx1kjOoH8T-g",
"version" : {
"number" : "6.2.1",
"build_hash" : "7299dc3",
"build_date" : "2018-02-07T19:34:26.990113Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
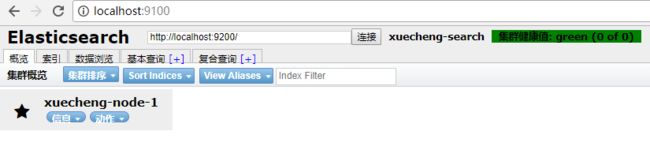
2.4 head插件安装
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等,head的项目地址在https://github.com/mobz/Elasticsearch-head 。
从ES6.0开始,head插件支持使得node.js运行。
1、安装node.js
略
2、下载head并运行
git clone git://github.com/mobz/Elasticsearch-head.git
cd Elasticsearch-head
npm install
npm run start
open HTTP://本地主机:9100 /
3、运行

打开浏览器调试工具发现报错:
Origin null is not allowed by Access-Control-Allow-Origin.
原因是:head插件作为客户端要连接ES服务(localhost:9200),此时存在跨域问题,Elasticsearch默认不允许跨域访问。
解决方案:
设置Elasticsearch允许跨域访问。
在config/Elasticsearch.yml 后面增加以下参数:
#开启cors跨域访问支持,默认为false
http.cors.enabled: true
#跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: /.*/
注意:将config/Elasticsearch.yml另存为utf-8编码格式。
成功连接ES