
1.基本概述
- Scikit-learn 也简称 Sklearn, 是机器学习领域当中最知名的 python 模块之一.
Sklearn 包含了很多种机器学习的方式:
- Classification 分类
- Regression 回归
- Clustering 非监督分类
- Dimensionality reduction 数据降维
- Model Selection 模型选择
- Preprocessing 数据预处理

一目了然的流程图
2.入门实践
# utf-8
from sklearn import datasets
from sklearn.cross_validation import train_test_split,cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVC
from sklearn import preprocessing
from sklearn.learning_curve import validation_curve
import matplotlib.pyplot as plt
import numpy as np
def knn_test():
'''
knn实现iris的分类
'''
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
# print(iris_x[:10])
# print(iris_y[:10])
x_train, x_test, y_train, y_test = train_test_split(
iris_x[:100], iris_y[:100], test_size=0.3)
print(y_train)
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
print(knn.predict(x_test))
print(y_test)
def knn_test2():
'''
knn实现iris的分类,并且使用交叉验证,并且划分成多次进行交叉验证,得到一个准确度列表scores
'''
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
x_train, x_test, y_train, y_test = train_test_split(iris_x[:100], iris_y[:100], test_size=0.3)
knn=KNeighborsClassifier(n_neighbors=5)
scores=cross_val_score(knn,iris_x,iris_y,cv=5,scoring='accuracy')#cross_val_score for classfication
print(scores)
def linear_test():
'''
生成数据,使用linear regression实现回归,画图
'''
# boston = datasets.load_boston()
# x = boston.data
# y = boston.target
x, y = datasets.make_regression(n_samples=50, n_features=1, noise=1)
x_train, x_test, y_train, y_test = train_test_split(
x[:100], y[:100], test_size=0.3)
linear = LinearRegression()
linear.fit(x_train, y_train)
linear.predict(x[:4])
print(linear.score(x_test, y_test))
plt.scatter(x, y)
plt.show()
def normalization():
'''
归一化(正则化),使用svm进行分类,并画图比较正则化前后的准确率
'''
x, y = datasets.make_classification(n_samples=300, n_features=2, n_redundant=0,
n_informative=1, random_state=22, n_clusters_per_class=1, scale=100)
x_train, x_test, y_train, y_test = train_test_split(
x[:100], y[:100], test_size=0.3)
model = SVC()
model.fit(x_train, y_train)
score1=model.score(x_test,y_test)
# print(x[:5], y[:5])
plt.subplot(121)
plt.scatter(x[:, 0], x[:, 1], c=y)
x = preprocessing.scale(x)
y = preprocessing.scale(y)
x_train, x_test, y_train, y_test = train_test_split(
x[:100], y[:100], test_size=0.3)
model = SVC()
model.fit(x_train, y_train)
score2=model.score(x_test,y_test)
# print(x[:5], y[:5])
plt.subplot(122)
plt.scatter(x[:, 0], x[:, 1], c=y)
print('precision:',score1)
print('precision:',score2)
plt.show()
def param_select():
'''
选择合适的knn参数k,分别在分类、回归
'''
iris = datasets.load_iris()
x = iris.data
y = iris.target
k_range=range(1,30)
k_scores=[]
for k in k_range:
knn=KNeighborsClassifier(n_neighbors=k)
#loss=-cross_val_score(knn,x,y,cv=10,scoring="mean_squared_error")# for regression
# k_scores.append(loss.mean())
scores = cross_val_score(
knn, x, y, cv=10, scoring='accuracy') # for classification
k_scores.append(scores.mean())
plt.plot(k_range,k_scores)
plt.xlabel('value of k for knn')
# plt.ylabel('crowss validated loss')
plt.ylabel('crowss validated accuracy')
plt.show()
def validation_curve_test():
'''
使用validation curve观察学习曲线,此处展示了过拟合的情况
'''
digits=datasets.load_digits()
x=digits.data
y=digits.target
model=SVC()
param_range=np.logspace(-6,-2.3,5)
train_loss,test_loss=validation_curve(model,x,y,param_name='gamma',param_range=param_range,cv=10,scoring='mean_squared_error')#数据大小,训练曲线、测试曲线
train_loss_mean=-np.mean(train_loss,axis=1)
test_loss_mean=-np.mean(test_loss,axis=1)
plt.plot(param_range,train_loss_mean,label='train')
plt.plot(param_range,test_loss_mean,label='cross-validation')
plt.xlabel('gamma')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
if __name__ == '__main__':
# knn_test()
# linear_test()
# normalization()
# knn_test2()
# param_select()
# validation_curve_test()
3.部分结果
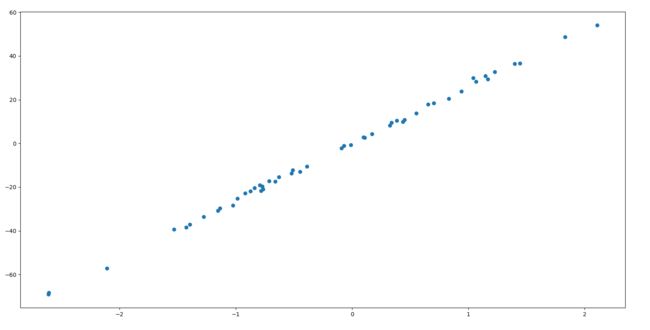
linear_test
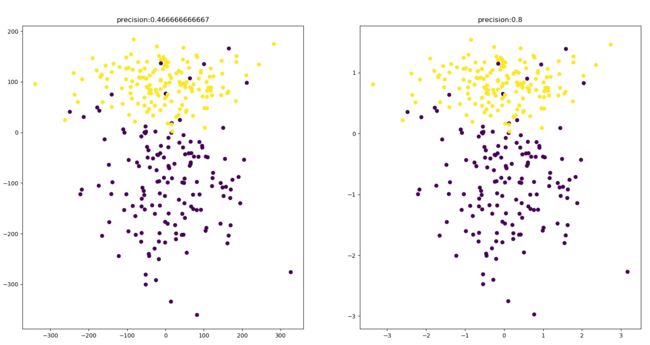
normalization

validation_curve_test
作者:Jasonhaven.D
链接:http://www.jianshu.com/u/ed031e432b82
來源:
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。