4.2. 内存虚拟化之数据结构
文章目录
- 1. 几个缩写
- 2. kvm_memslots: 虚拟机所有slot信息
- 3. kvm_mem_slot 结构体: 一个代表一段空间, GPA -> HVA
- 4. kvm中与mmu相关成员
- 5. kvm_vcpu中与mmu相关成员
- 6. kvm_mmu 结构体: vMMU数据结构
- 7. kvm_mmu_page: 一个层级的影子页表页
1. 几个缩写
- GVA - Guest Virtual Address,虚拟机的虚拟地址
- GPA - Guest Physical Address,虚拟机的物理地址
- GFN - Guest Frame Number,虚拟机的页框号
- HVA - Host Virtual Address,宿主机虚拟地址,也就是对应Qemu中申请的地址
- HPA - Host Physical Address,宿主机物理地址
- HFN - Host Frame Number,宿主机的页框号
- PFN - host page frame number, 宿主页框号
- PTE - page table entry,页表项,指向下一级页表或者页的物理地址,以及相应的权限位
- GPTE - guest pte,客户机页表项,指向GPT中下一级页表或者页的gpa,以及相应的权限位
- TDP - two dimentional paging(二维分页, 可以是NPT和EPT)
- SPTE - shadow page table entry, 影子页表项,也就是EPT页表项,指向EPT中下一级页表或者页的hpa,以及相应的权限位
以上唯一需要解释的是spte,在这里被叫做shadow pte,如果不了解的话,会很容易和以前的shadow paging机制搞混。
KVM在还没有EPT硬件支持的时候,采用的是影子页表(shadow page table)机制,为了和之前的代码兼容,在当前的实现中,EPT机制是在影子页表机制代码的基础上实现的,所以EPT里面的pte和之前一样被叫做 shadow pte,这个会在之后进行详细的说明。
2. kvm_memslots: 虚拟机所有slot信息
一个struct kvm代表一个虚拟机, memslots是该虚拟机所有内存条, 注意最大KVM_ADDRESS_SPACE_NUM(这里是1), 用于将GPA转换为HVA.
一个虚拟机的所有slot(即kvm->memslots)构成完整的虚拟机物理地址空间.
struct kvm {
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM];
}
/*
* Note:
* memslots are not sorted by id anymore, please use id_to_memslot()
* to get the memslot by its id.
*/
struct kvm_memslots {
u64 generation;
/* The mapping table from slot id to the index in memslots[]. */
short id_to_index[KVM_MEM_SLOTS_NUM];
atomic_t lru_slot;
int used_slots;
// 所有插槽
struct kvm_memory_slot memslots[];
};
kvm_memslots结构体是kvm_mem_slot的封装,其中包含一个kvm_mem_slot的数组,对应于该虚拟机使用的所有内存区域(slot)。以数组形式存储这些slot的地址信息。
kvm_mem_slot是kvm内存管理相关主要数据结构,用来表示虚拟机GPA和主机HVA之间的映射关系,一个kvm_mem_slot表示一段内存区域(slot)的映射关系.
获取某一个kvm_memory_slot, 通过id_to_memslot(struct kvm_memslots *slots, int id)实现, 虚拟机物理内存注册有具体代码.
kvm->memslots结构在创建虚拟机时被创建. kvm_create_vm, 而插槽IDslot id和其索引index是在id_to_index中维护, 即slots->id_to_index[i] = slots->memslots[i].id = i, 而这个映射关系是新加一个内存条(即虚拟机物理内存注册)时候建立的.
static struct kvm *kvm_create_vm(unsigned long type)
{
...
for (i = 0; i < KVM_ADDRESS_SPACE_NUM; i++) {
struct kvm_memslots *slots = kvm_alloc_memslots();
if (!slots)
goto out_err_no_arch_destroy_vm;
/* Generations must be different for each address space. */
slots->generation = i;
rcu_assign_pointer(kvm->memslots[i], slots);
}
...
}
static struct kvm_memslots *kvm_alloc_memslots(void)
{
int i;
struct kvm_memslots *slots;
slots = kvzalloc(sizeof(struct kvm_memslots), GFP_KERNEL_ACCOUNT);
if (!slots)
return NULL;
// 这里并没有建立, 而是在虚拟机物理内存注册时候建立
for (i = 0; i < KVM_MEM_SLOTS_NUM; i++)
slots->id_to_index[i] = -1;
return slots;
}
3. kvm_mem_slot 结构体: 一个代表一段空间, GPA -> HVA
由于GPA不能直接用于物理 MMU 进行寻址!!!,所以需要将GPA转换为HVA,kvm中利用 kvm_memory_slot 数据结构来记录每一个地址区间(Guest中的物理地址区间)中GPA与HVA的映射关系.
struct kvm_memory_slot {
// 虚拟机物理地址(即GPA)对应的页框号, GPA
// 等于: mem->guest_phys_addr >> PAGE_SHIFT;
gfn_t base_gfn;
// 当前slot中包含的page数目
unsigned long npages;
// 一个slot由许多客户机虚拟页面构成, 通过这个标识每个页是否可用(脏页的bitmap)
unsigned long *dirty_bitmap;
// 架构相关部分
struct kvm_arch_memory_slot arch;
/*
* GPA对应的host虚拟地址(HVA), 由于虚拟机都运行在qemu的地址空间中
* 而qemu是用户态程序, 所以通常使用root-module下的用户地址空间.
*/
unsigned long userspace_addr;
// slot的标志位
u32 flags;
// slot的id
short id;
};
众所周知,KVM虚拟机运行在qemu的进程地址空间中,所以其实虚拟机使用的物理地址是从对应qemu进程的地址空间中分配的。
虚拟机物理内存!!! 被分成若干个kvm_memory_slot,每个memslot是不能重叠的,也就是说每一段内存区间都必须有独立的作用。一般来说Qemu会对RAM、IO memory、High memory等分别注册若干个memslot.
一个虚拟机的所有slot(即kvm->memslots)构成完整的虚拟机物理地址空间.
每个虚拟机的物理内存由多个slot组成,每个slot对应一个kvm_memory_slot结构,从结构体的字段可以看出,该结构记录slot映射的是哪些客户物理page,由于映射多个页面,所以有一个ditty_bitmap来标识各个页的状态,注意这个页是客户机的虚拟page。映射架构如下:
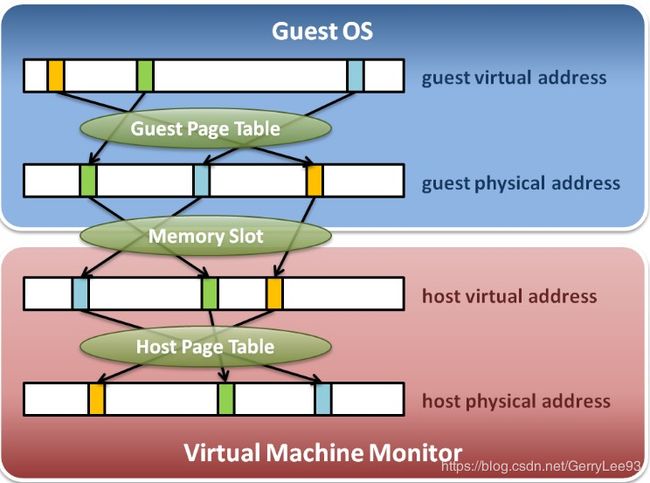
kvm_memory_slot本质是qemu进程用户空间的hva, 仅仅是qemu进程的虚拟地址空间,并没有对应物理地址,各个字段的意义不言自明了。其中有一个kvm_arch_memory_slot结构,我们重点描述。
/* KVM Hugepage definitions for x86 */
enum {
// 页面的起始地址在 页表(PT) 中
PT_PAGE_TABLE_LEVEL = 1,
// 2M大页(2^20), 页面的起始地址在 页目录项(PDE) 中
PT_DIRECTORY_LEVEL = 2,
// 1G大页(2^30), 页面的起始地址在 页目录指针项(PDPE) 中
PT_PDPE_LEVEL = 3,
/* set max level to the biggest one */
PT_MAX_HUGEPAGE_LEVEL = PT_PDPE_LEVEL,
};
// 这里是3
#define KVM_NR_PAGE_SIZES (PT_MAX_HUGEPAGE_LEVEL - \
PT_PAGE_TABLE_LEVEL + 1)
struct kvm_rmap_head {
unsigned long val;
};
struct kvm_lpage_info {
int disallow_lpage;
};
struct kvm_arch_memory_slot {
// 反向映射结构(reverse map)
// 数组, 3个指针, 每种页面大小对应一个链表
struct kvm_rmap_head *rmap[KVM_NR_PAGE_SIZES];
// Large page结构(如2MB、1GB大小页面)
struct kvm_lpage_info *lpage_info[KVM_NR_PAGE_SIZES - 1];
unsigned short *gfn_track[KVM_PAGE_TRACK_MAX];
};
该结构的rmap字段是指针数组,每种页面大小对应一个链表,KVM的大页面支持2M和1G的页面,普通的页面就是4KB了。结合上面的kvm_memory_slot结构可以发现,kvm_arch_memory_slot其实是kvm_memory_slot的一个内嵌结构,所以每个slot都关联一个kvm_arch_memory_slot,也就有一个rmap数组。其实在虚拟机中,qemu为虚拟机分配的页面主要是大页面。
至于kvm_userspace_memory_region可以看qemu部分
4. kvm中与mmu相关成员
// include/linux/kvm_host.h
struct kvm {
struct kvm_vcpu *vcpus[KVM_MAX_VCPUS];
// 保护mmu的spinlock, mmu范围最大的锁
spinlock_t mmu_lock;
// 内存槽操作锁
struct mutex slots_lock;
// host上arch的一些参数
struct kvm_arch arch;
// 指向qemu用户态进程的mm_struct
struct mm_struct *mm; /* userspace tied to this vm */
// 该kvm所有的memslot
struct kvm_memslots __rcu *memslots[KVM_ADDRESS_SPACE_NUM];
kvm结构体, 每个虚拟机一个,代表一个虚拟机
- arch成员是虚拟机级别的arch特性,其中通过hash和链表会将
kvm_mmu_page结构管理起来,以后通过gfn就可以快速索引到一个gfn地址所用的页表页(kvm_mmu_page) - vcpus成员指向一组虚拟机内的VCPU结构
其中address_space_id = mem->slot >> 16;, 详细见虚拟机物理内存注册.
5. kvm_vcpu中与mmu相关成员
// include/linux/kvm_host.h
struct kvm_vcpu {
// 当前VCPU虚拟的架构, 默认x86
// 架构相关部分,包括的寄存器、apic、mmu相关等架构相关的内容
struct kvm_vcpu_arch arch;
};
kvm_vcpu结构体, 对应一个VCPU
- arch成员是架构特性部分,如x86特性部分,arm特定部分等
struct kvm_vcpu_arch {
......
/*
* Paging state of the vcpu
*
* If the vcpu runs in guest mode with two level paging this still saves
* the paging mode of the l1 guest. This context is always used to
* handle faults.
*/
// vcpu以两级页表运行在guest模式下, 这里仍然保存L1虚拟机的页表
// 这个用于处理异常
struct kvm_mmu *mmu;
/* Non-nested MMU for L1 */
// 非嵌套情况下的虚拟机 mmu
struct kvm_mmu root_mmu;
/* L1 MMU when running nested */
// 嵌套情况下的 L1 的mmu
struct kvm_mmu guest_mmu;
/*
* Paging state of an L2 guest (used for nested npt)
*
* This context will save all necessary information to walk page tables
* of an L2 guest. This context is only initialized for page table
* walking and not for faulting since we never handle l2 page faults on
* the host.
*/
//
struct kvm_mmu nested_mmu;
/*
* Pointer to the mmu context currently used for
* gva_to_gpa translations.
*/
// 用于 GVA 转换成 GPA
struct kvm_mmu *walk_mmu;
struct kvm_mmu_memory_cache mmu_pte_list_desc_cache;
struct kvm_mmu_memory_cache mmu_page_cache;
struct kvm_mmu_memory_cache mmu_page_header_cache;
......
- mmu成员指向vMMU结构,可以看出vMMU是每VCPU一个
walk_mmu成员指向mmu
注释已经很清楚了,我就不做过多的解释了,说一下三个cache:
mmu_pte_list_desc_cache:用来分配struct pte_list_desc结构,该结构主要用于反向映射,参考rmap_ad函数,每个rmapp指向的就是一个pte_list。后面介绍反向映射的时候会详细介绍。mmu_page_cache:用来分配spt页结构,spt页结构是存储spt paging structure的页,对应kvm_mmu_page.sptmmu_page_header_cache:用来分配struct kvm_mmu_page结构,从该cache分配的页面可能会调用kmem_cache机制来分配
这三个cache使用的是kvm_mmu_memory_cache结构,该结构是KVM定义的cache结构,进一步优化了MMU分配的效率。有两个对应的kmem_cache结构:
static struct kmem_cache *pte_list_desc_cache;
static struct kmem_cache *mmu_page_header_cache;
他们分别对应mmu_pte_list_desc_cache和mmu_page_header_cache,也就是说如果这两个cache中缓存的object数目不够,则会从上述对应的kmem_cache中获取,对应的代码可以参考函数mmu_topup_memory_cache;
static int mmu_topup_memory_cache(struct kvm_mmu_memory_cache *cache,
struct kmem_cache *base_cache, int min)
{
void *obj;
if (cache->nobjs >= min)
return 0;
while (cache->nobjs < ARRAY_SIZE(cache->objects)) {
obj = kmem_cache_zalloc(base_cache, GFP_KERNEL_ACCOUNT);
if (!obj)
return cache->nobjs >= min ? 0 : -ENOMEM;
cache->objects[cache->nobjs++] = obj;
}
return 0;
}
而mmu_page_cache中的object数目不够时,则调用mmu_topup_memory_cache_page函数,其中直接调用了__get_free_page函数来获得页面。在一些初始化函数中,需要初始化这些cache以便加速运行时的分配,初始化函数为mmu_topup_memory_caches,该初始化过程在mmu page fault处理函数(如tdp_page_fault)、MMU初始化函数(kvm_mmu_load)和写SPT的pte函数(kvm_mmu_pte_write)中被调用。
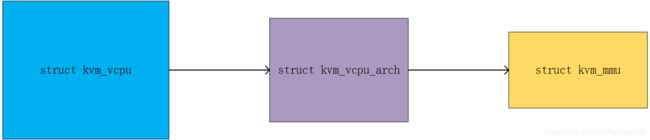
从上图可以看到,struct kvm_mmu是struct kvm_vcpu_arch的一个字段。
6. kvm_mmu 结构体: vMMU数据结构
/*
* x86 supports 4 paging modes (5-level 64-bit, 4-level 64-bit, 3-level 32-bit,
* and 2-level 32-bit). The kvm_mmu structure abstracts the details of the
* current mmu mode.
*/
struct kvm_mmu {
// 函数指针
unsigned long (*get_guest_pgd)(struct kvm_vcpu *vcpu);
u64 (*get_pdptr)(struct kvm_vcpu *vcpu, int index);
int (*page_fault)(struct kvm_vcpu *vcpu, gpa_t cr2_or_gpa, u32 err,
bool prefault);
void (*inject_page_fault)(struct kvm_vcpu *vcpu,
struct x86_exception *fault);
//
gpa_t (*gva_to_gpa)(struct kvm_vcpu *vcpu, gpa_t gva_or_gpa,
u32 access, struct x86_exception *exception);
gpa_t (*translate_gpa)(struct kvm_vcpu *vcpu, gpa_t gpa, u32 access,
struct x86_exception *exception);
int (*sync_page)(struct kvm_vcpu *vcpu,
struct kvm_mmu_page *sp);
void (*invlpg)(struct kvm_vcpu *vcpu, gva_t gva, hpa_t root_hpa);
void (*update_pte)(struct kvm_vcpu *vcpu, struct kvm_mmu_page *sp,
u64 *spte, const void *pte);
// 存储paging structure中根目录的地址(如EPT中的EPTP), 这是HPA
// 影子页表level4页表页物理地址,EPT情况下,该值就是VMCS的EPT_pointer
hpa_t root_hpa;
// 虚拟机本身页表的cr3地址, GPA
gpa_t root_cr3;
// 创建 mmu 页面时候使用的基本的 page role
// 里面设置了vMMU角色所代表的一些硬件特性,如是否开启了NX,是否开启了SMEP等
union kvm_mmu_role mmu_role;
// host paging structure中根目录的级别(如64位支持paging可以支持level=4的页结构)
// guest中页表的级别,根据VCPU特性不同而不同,如开启long mode就是4,开启PAE的就是3等等
u8 root_level;
// SPT Paging Structure中根目录的级别(如64位支持paging的系统可以支持level=4的EPT页结构)
// 就是影子页表的级数,EPT情况下这个是4
u8 shadow_root_level;
u8 ept_ad;
// 该MMU是否保证存储的页结构和VCPU使用的页结构的一致性。
// 如果为true则每次MMU内容时都会刷新VCPU的TLB,否则需要手动同步。
bool direct_map;
struct kvm_mmu_root_info prev_roots[KVM_MMU_NUM_PREV_ROOTS];
/*
* Bitmap; bit set = permission fault
* Byte index: page fault error code [4:1]
* Bit index: pte permissions in ACC_* format
*/
// 在page fault处理时不同page fault error code对应的权限,权限由 ACC_* 系列宏指定
u8 permissions[16];
/*
* The pkru_mask indicates if protection key checks are needed. It
* consists of 16 domains indexed by page fault error code bits [4:1],
* with PFEC.RSVD replaced by ACC_USER_MASK from the page tables.
* Each domain has 2 bits which are ANDed with AD and WD from PKRU.
*/
u32 pkru_mask;
u64 *pae_root;
u64 *lm_root;
/*
* check zero bits on shadow page table entries, these
* bits include not only hardware reserved bits but also
* the bits spte never used.
*/
struct rsvd_bits_validate shadow_zero_check;
struct rsvd_bits_validate guest_rsvd_check;
/* Can have large pages at levels 2..last_nonleaf_level-1. */
u8 last_nonleaf_level;
// 对应CPU efer.nx,详见Intel手册
bool nx;
// Guest的页表结构,对应VMCS中GUEST_PDPTR0、GUEST_PDPTR1、GUEST_PDPTR2和GUEST_PDPTR3,参考ept_save_pdptrs和ept_load_pdptrs函数
u64 pdptrs[4]; /* pae */
};
union kvm_mmu_role {
u64 as_u64;
struct {
union kvm_mmu_page_role base;
union kvm_mmu_extended_role ext;
};
};
union kvm_mmu_extended_role {
/*
* This structure complements kvm_mmu_page_role caching everything needed for
* MMU configuration. If nothing in both these structures changed, MMU
* re-configuration can be skipped. @valid bit is set on first usage so we don't
* treat all-zero structure as valid data.
*/
u32 word;
struct {
unsigned int valid:1;
unsigned int execonly:1;
unsigned int cr0_pg:1;
unsigned int cr4_pae:1;
unsigned int cr4_pse:1;
unsigned int cr4_pke:1;
unsigned int cr4_smap:1;
unsigned int cr4_smep:1;
unsigned int maxphyaddr:6;
};
};
/*
* the pages used as guest page table on soft mmu are tracked by
* kvm_memory_slot.arch.gfn_track which is 16 bits, so the role bits used
* by indirect shadow page can not be more than 15 bits.
*
* Currently, we used 14 bits that are @level, @gpte_is_8_bytes, @quadrant, @access,
* @nxe, @cr0_wp, @smep_andnot_wp and @smap_andnot_wp.
*/
union kvm_mmu_page_role {
u32 word;
struct {
// 该页表页的层级
// kvm_mmu_page结构管理的页面可以作为影子页表中任何一个level的页表。也就是影子页表所代表的角色不同,有时候是level1 有时候是level4。其所管理的页面被用作哪个界别是靠role.level区分的。
unsigned level:4;
unsigned gpte_is_8_bytes:1;
unsigned quadrant:2;
unsigned direct:1;
// 访问权限
unsigned access:3;
// 表示该页是否有效
unsigned invalid:1;
// 记录了efer.nxe的值
unsigned nxe:1;
unsigned cr0_wp:1;
unsigned smep_andnot_wp:1;
unsigned smap_andnot_wp:1;
unsigned ad_disabled:1;
unsigned guest_mode:1;
unsigned :6;
/*
* This is left at the top of the word so that
* kvm_memslots_for_spte_role can extract it with a
* simple shift. While there is room, give it a whole
* byte so it is also faster to load it from memory.
*/
unsigned smm:8;
};
};
7. kvm_mmu_page: 一个层级的影子页表页
由于gpa对应的hva已经存在, 所以可以直接根据gpa得到hpa, gfn_to_pfn函数实现了这个功能. 但该页对应的ept页表内存却并未分配,所以kvm需要管理分页内存和页面映射. 为此kvm引入了kvm_mmu_page结构。
kvm_mmu_page结构是KVM MMU中最重要的结构之一,其存储了KVM MMU页表的结构
struct kvm_mmu_page {
// 将该结构链接到 kvm->arch.active_mmu_pages 和 invalid_list 上,标注该页结构不同的状态
struct list_head link;
// 将该结构链接到kvm->arch.mmu_page_hash哈希表上,以便进行快速查找,hash key由接下来的gfn决定
struct hlist_node hash_link;
struct list_head lpage_disallowed_link;
// 该域只对页结构的叶子节点有效,可以执行该页的翻译是否与guest的翻译一致。
// 如果为false,则可能出现修改了该页中的pte但没有更新tlb,而guest读取了tlb中的数据,导致了不一致。
bool unsync;
// 该页的generation number, 有效版本号
// 用于和 kvm->arch.mmu_valid_gen 进行比较,比它小表示该页是invalid的
u8 mmu_valid_gen;
bool mmio_cached;
bool lpage_disallowed; /* Can't be replaced by an equiv large page */
/*
* The following two entries are used to key the shadow page in the
* hash table.
*/
// 该页的“角色”,详细参见上文对union kvm_mmu_page_role的说明
// 记录该 mmu page的各种属性
union kvm_mmu_page_role role;
// 在直接映射中存储线性地址的基地址;在非直接映射中存储guest page table,该PT包含了由该页映射的translation。非直接映射不常见
gfn_t gfn;
// 指向影子页表页地址,HPA, 页中被分为多个spte。影子页表用的页面称为shadow page,一个页面中分为多个表项,每个表项称为spte,注意不论哪个级别,表项都称为spte
// 该域可以指向一个lower-level shadow pages,也可以指向真正的数据page。
u64 *spt;
/* hold the gfn of each spte inside spt */
// 每级的页表页都会管理GUEST物理地址空间的一部分,这段GUEST物理地址空间的起止地址对应的GFN就在这个成员中被记录下来。
// 当通过gaddr遍历影子页表页的时候,就会根据gaddr算出gfn,然后看gfn落在每级中的哪个spte内,从而确定使用哪个spte,然后用spte来定位出下一级页表地址或pfn
gfn_t *gfns;
// 该页被多少个vcpu作为根页结构
int root_count; /* Currently serving as active root */
// 记录该页结构下面有多少个子节点是unsync状态的
unsigned int unsync_children;
// 指向上一级spt, 表示有哪些上一级页表页的页表项指向该页表页
struct kvm_rmap_head parent_ptes; /* rmap pointers to parent sptes */
// 记录了unsync的子结构的位图
DECLARE_BITMAP(unsync_child_bitmap, 512);
#ifdef CONFIG_X86_32
/*
* Used out of the mmu-lock to avoid reading spte values while an
* update is in progress; see the comments in __get_spte_lockless().
*/
// 仅针对32位host有效,具体作用参考函数__get_spte_lockless的注释
int clear_spte_count;
#endif
/* Number of writes since the last time traversal visited this page. */
// 在写保护模式下,对于任何一个页的写都会导致KVM进行一次emulation。
//对于叶子节点(真正指向数据页的节点),可以使用unsync状态来保护频繁的写操作不会导致大量的emulation,但是对于非叶子节点(paging structure节点)则不行。
// 对于非叶子节点的写emulation会修改该域,如果写emulation非常频繁,KVM会unmap该页以避免过多的写emulation。
atomic_t write_flooding_count;
};
页分为两类,物理页和页表页,而页表页本身也被分为两类,高层级(level-4 to level-2)的页表页,和最后一级(level-1)的页表页。
影子页表页,shadow page,就是装载影子页表项的页面,每个页面中分为多个表项,每个表项称为spte,注意不论哪个级别,表项都称为spte。一个该结构描述一个层级的页表.
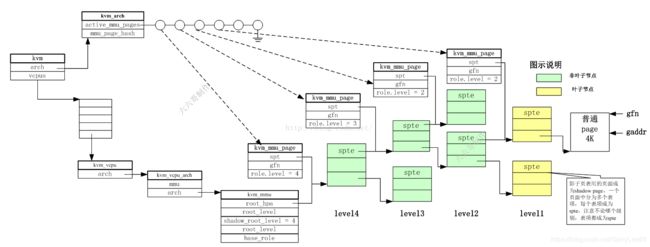

注意, 这个影子页表页的page struct描述符中的private指向了管理该页表页的kvm_mmu_page成员。
parent_spte: 一个页表页,会被会被多个上级页表项引用到,那么所有引用该页表页的上级页表项称为parent_spte,并且会将所有上级页表项的parent_spte存放在当前kvm_mmu_page的parent_ptes链表中, mmu_page_add_parent_pte(), 使用参见__direct_map()
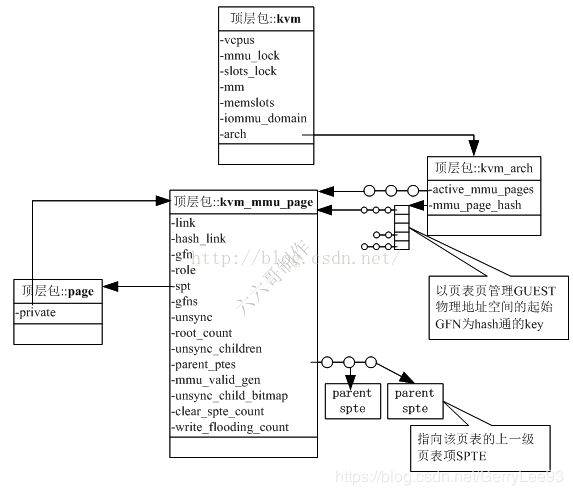
分配好kvm_mmu_page结构后, 会用其管理的GUEST物理地址空间的起始GFN!!! 为key计算一个hash值,并上到哈希表arch.mmu_page_hash[]上(在kvm_mmu_get_page()中),以便可以快速的根据gfn找到管理该物理地址空间的页表页. 这个起始GPN在__direct_map()中会计算, 使用下面公式, 即base_gfn; gfn是标准页帧号(gpa >> PAGE_SHIFT, 全局唯一值, 4K页面的标准页帧号). 也就是说base_gfn是该页表页所管理GUEST物理地址空间的起始gfn,而不是发生缺页地址所在页面的gfn。缺页gfn是被管理的GEUST物理地址空间中的一个值. 假设level=2, 如果 gfn = 513,则base_gfn = 512; 如果 gfn = 511,base_gfn = 0;
base_gfn = gfn & ~(KVM_PAGES_PER_HPAGE(it.level) - 1);
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YN40r539-1590763753132)(./images/2020-04-05-17-02-34.png)]
mmu_valid_gen:为有效版本号,KVM维护了一个全局的的gen number(vcpu->kvm->arch.mmu_valid_gen),刚开始是相同的(在kvm_mmu_alloc_page()中初始化.), 如果该域与全局的gen number不相等,则将该页标记为invalid page。该结构用来快速的碾压掉该页表项页管理的虚拟机物理地址空间。例如,如果想废弃掉当前所有的MMU页结构,需要处理掉所有的MMU页面和对应的映射;但是通过该结构,可以直接将vcpu->kvm->arch.mmu_valid_gen加1,那么当前所有的MMU页结构都变成了invalid,而处理掉页结构的过程可以留给后面的过程(如内存不够时)再处理,可以加快废弃所有MMU页结构的速度。 当mmu_valid_gen值达到最大时,可以调用kvm_mmu_invalidate_zap_all_pages手动废弃掉所有的MMU页结构。
SPT/EPT页的struct page结构中page->private域会反向指向该struct kvm_mmu_page。同样是在kvm_mmu_alloc_page()中调用set_page_private(virt_to_page(sp->spt), (unsigned long)sp)设置.
link: 表明不同状态. 同时只要是激活的页表页,也会加入vcpu->kvm->arch.active_mmu_page链表中,以便在后面快速的释放内存. 同样在kvm_mmu_alloc_page()中调用list_add(&sp->link, &vcpu->kvm->arch.active_mmu_pages)设置