tushare是一个经典的python环境下的量化工具箱,最近仔细阅读了一下他的代码逻辑,做一定的解析.
开始
tushare的代码是从init.py文件下开始的,我们一块一块的分析.
"""
for trading data
"""
from tushare.stock.trading import (get_hist_data, get_tick_data,
get_today_all, get_realtime_quotes,
get_h_data, get_today_ticks,
get_index, get_hists,
get_k_data,
get_sina_dd)
可以看出,tushare的10个api是从stock下的trading模块中打包出来的,查看trading.py.
先查看trading.py的依赖项
import time
import json
import lxml.html
from lxml import etree
import pandas as pd
import numpy as np
from tushare.stock import cons as ct //引入cons.py
import re
from pandas.compat import StringIO
from tushare.util import dateu as du //引入util下的dateu.py(工具箱)
from tushare.stock.reference import new_stocks /
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
我们可以看出,引入了三个模块,分别是cons.py 作为连接函数,dateu作为日期工具 和 股票数据
API: get_hist_data 个股历史数据
def get_hist_data(code=None, start=None, end=None,
ktype='D', retry_count=3,
pause=0.001):
"""
获取个股历史交易记录
Parameters
------
code:string
股票代码 e.g. 600848
start:string
开始日期 format:YYYY-MM-DD 为空时取到API所提供的最早日期数据
end:string
结束日期 format:YYYY-MM-DD 为空时取到最近一个交易日数据
ktype:string
数据类型,D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为D
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
return
-------
DataFrame
属性:日期 ,开盘价, 最高价, 收盘价, 最低价, 成交量, 价格变动 ,涨跌幅,5日均价,10日均价,20日均价,5日均量,10日均量,20日均量,换手率
"""
(code=None, start=None, end=None,
ktype='D', retry_count=3,
pause=0.001):
预分配的是 code股票代码,起始日期start,终止日期end
数据类型是D(r日线),retry_count=3(如遇网络等问题重复执行3次 )
重复请求数据过程中暂停0.001秒
symbol = _code_to_symbol(code)
url = ''
if ktype.upper() in ct.K_LABELS:
url = ct.DAY_PRICE_URL%(ct.P_TYPE['http'], ct.DOMAINS['ifeng'],
ct.K_TYPE[ktype.upper()], symbol)
elif ktype in ct.K_MIN_LABELS:
url = ct.DAY_PRICE_MIN_URL%(ct.P_TYPE['http'], ct.DOMAINS['ifeng'],
symbol, ktype)
else:
raise TypeError('ktype input error.')
数据是从凤凰网上爬下来的,ifeng.com,这段代码主要负责组装参数
第一句 _code_to_symbol(code)
我们查找这个函数
def _code_to_symbol(code):
"""
生成symbol代码标志
"""
if code in ct.INDEX_LABELS:
return ct.INDEX_LIST[code]
else:
if len(code) != 6 :
return ''
else:
return 'sh%s'%code if code[:1] in ['5', '6', '9'] else 'sz%s'%code
我们可以看出,_code_to_symbol主要是对输入的股票代码进行判断,然后组装成标准的例如sh600001这种代码的
code in ct.INDEX_LABELS
ct是从cons.py里面引入的,在cons里面,
INDEX_LABELS = ['sh', 'sz', 'hs300', 'sz50', 'cyb', 'zxb', 'zx300', 'zh500']
INDEX_LIST = {'sh': 'sh000001', 'sz': 'sz399001', 'hs300': 'sz399300',
'sz50': 'sh000016', 'zxb': 'sz399005', 'cyb': 'sz399006', 'zx300': 'sz399008', 'zh500':'sh000905'}
如果输入的code是'sh', 'sz', 'hs300', 'sz50', 'cyb', 'zxb', 'zx300', 'zh500'这几种里面的一个,返还一个示例代码
'sh': 'sh000001', 'sz': 'sz399001', 'hs300': 'sz399300',
'sz50': 'sh000016', 'zxb': 'sz399005', 'cyb': 'sz399006', 'zx300': 'sz399008', 'zh500':'sh000905'
如果输入的是一个6位数的股票代码
return 'sh%s'%code if code[:1] in ['5', '6', '9'] else 'sz%s'%code
则查看代码的第一位code[:1]
如果是5,76,9开头的,则是sh 上证股票,否则是sz 深圳股票
如果输入的既不是sh这种,也不是6位数代码, return ''
第二句
url = ''
预设一个url
第三句
if ktype.upper() in ct.K_LABELS:
url = ct.DAY_PRICE_URL%(ct.P_TYPE['http'], ct.DOMAINS['ifeng'],
ct.K_TYPE[ktype.upper()], symbol)
将函数中的ktype(默认是'D'),先转化成大写的(upper),这里是避免用户的错误输入,比如说输入'd',提高容错率
在con里面,我们找到了K_LABELS = ['D', 'W', 'M']
及 日线,周线和月线
url = ct.DAY_PRICE_URL%(ct.P_TYPE['http'], ct.DOMAINS['ifeng'],
ct.K_TYPE[ktype.upper()], symbol)
此句是拼装url
DAY_PRICE_URL = '%sapi.finance.%s/%s/?code=%s&type=last'
K_TYPE = {'D': 'akdaily', 'W': 'akweekly', 'M': 'akmonthly'}
其实就是
http://api.finance.ifeng.com/akdaily/?code=sh600010&type=last
http://api.finance.ifeng.com/akweekly/?code=sh600818&type=last
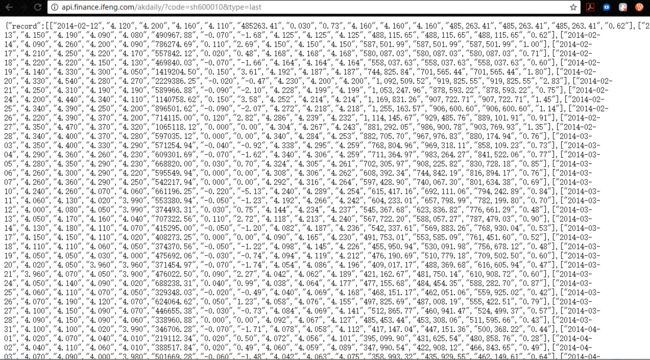

这件事其实也非常简单,他是根据凤凰财经的日线图找到的
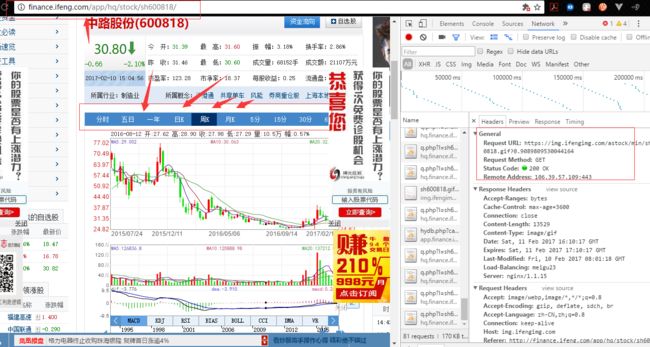
我们可以监控network,然后分别点击日k,周k,月k就能看到对应的请求了
本质是一个ajax请求的api
之后的分钟线等原理都是一致的,不再过多陈述
下面就进入到数据获取的环节,数据获取使用的是 urllib.request模块,在模块的最初的引入urllib或者urllib2 是因为python2和python3的兼容.
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(url)
lines = urlopen(request, timeout = 10).read()
我们request这个url,并且打开(下载这个网页),放到lines里面
如果lines=no data (判断条件是lines的长度<15,因为no data的长度是14),我们返还NONE,如果出现异常,则打印exception
if len(lines) < 15: #no data
return None
except Exception as e:
print(e)
else:
js = json.loads(lines.decode('utf-8') if ct.PY3 else lines)
cols = []
if (code in ct.INDEX_LABELS) & (ktype.upper() in ct.K_LABELS):
cols = ct.INX_DAY_PRICE_COLUMNS
else:
cols = ct.DAY_PRICE_COLUMNS
if len(js['record'][0]) == 14:
cols = ct.INX_DAY_PRICE_COLUMNS
df = pd.DataFrame(js['record'], columns=cols)
if ktype.upper() in ['D', 'W', 'M']:
df = df.applymap(lambda x: x.replace(u',', u''))
df[df==''] = 0
for col in cols[1:]:
df[col] = df[col].astype(float)
if start is not None:
df = df[df.date >= start]
if end is not None:
df = df[df.date <= end]
if (code in ct.INDEX_LABELS) & (ktype in ct.K_MIN_LABELS):
df = df.drop('turnover', axis=1)
df = df.set_index('date')
df = df.sort_index(ascending = False)
return df
raise IOError(ct.NETWORK_URL_ERROR_MSG)