11.pgsql批量插入测试数据测试
1.测试准备
-- 1.创建测试表t_user
create table if not exists t_user(
id serial primary key,
user_name varchar(255),
pass_word varchar(255),
create_time date,
dr char(1)
)
-- 2.注释
comment on column t_user.id is '测试表';
comment on column t_user.user_name is '账号';
comment on column t_user.pass_word is '密码';
comment on column t_user.create_time is '创建日期';
comment on column t_user.dr is 'delete remark';2.测试4种不同的批量插入测试数据效率
创建存储过程
-- 创建存储过程插入数据
create or replace function batch_insert_proc(num int) returns void as
$$
begin
while num > 0 loop
insert into t_user(user_name,pass_word,create_time,dr) values('username'||round(random()*num),'password'||round(random()*num),now(),0);
num = num -1;
end loop;
exception
when others then
raise exception'(%)',SQLERRM;
end;
$$ language plpgsql;2.1直接调用存储过程
-- 插入100*10000条数据
select batch_insert_proc(100*10000); 测试结果:
![]()
![]()

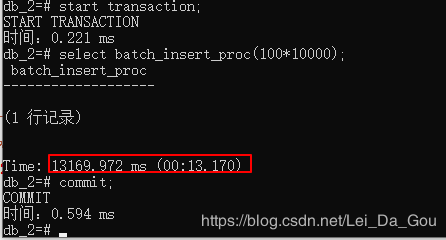
2.2尝试关闭自动提交调用存储过程
-- 也可以使用set autocommit off关闭自动提交
START TRANSACTION;
select batch_insert_proc(100*10000);
commit;测试结果:
![]()
![]()
![]()
shell执行sql默认不显示执行时间,显示执行时间使用命令:
![]()
为防止浏览器关闭自动提交未生效,我又使用shell执行了一次,如下如图:
2.3直接使用插入语句
insert into t_user select generate_series(1,100*10000),'username'||round(random()*1000000),'password'||round(random()*1000000),now(),0;![]()
![]()
![]()
2.4直接使用插入语句并关闭自动提交
start transaction;
insert into t_user select generate_series(1,100*10000),'username'||round(random()*1000000),'password'||round(random()*1000000),now(),0;
commit;![]()
![]()
![]()
总结:关闭自动提交性能并不能得到显著提升。
3.测试复制表效率
3.1 导出导入数据文件并使用copy复制
-- 导出数据到文件(100*10000条记录)
copy t_user to 'E:\\sql\\user.sql';
-- 复制表结构
create table t_user_copy as (select * from t_user limit 0);
-- 从数据文件copy数据到新表
copy t_user_copy from 'E:\\sql\\user.sql';测试结果:
![]()
![]()
![]()
3.2直接使用sql语句复制
-- 测试2:直接复制表结构及数据(100W耗时3.445秒)
create table t_user_copy as (select * from t_user);![]()
![]()
![]()
4.总结
1、插入测试数据直接使用2.4,复制表数据使用copy即可。
2、postgresql在function不能用start transaction, commit 或rollback,因为函数中的事务其实就是begin...exception.end块。所有你如果要写事务,请直接用begin...exception...end就够了,这也说明了为什么上面开启事务,或者换种说法关闭自动提交根本就没有提升批量插入数据的性能,但是copy确实对性能提升有一定帮助。
3、postgresql在函数(存储过程)中引入了异常的概念,即begin...exception...end块,这里有三种情况,第一种:这个函数体的结构就是一个全局的begin...exception...end块(后文简称bee块),可以把bee块理解为一个事务,当这个函数体,即全局事务出现异常,则全部rollback。第二种情况:如果在某个子bee块中出现异常,则该bee块会回滚,但是不会影响其它bee块。感觉pgsql在函数这块得些细节整得有点晦涩难懂。