揭秘LOL背后的IT基础架构丨SDN解锁新基础架构
欢迎来到Tungsten Fabric用户案例系列文章,一起发现TF的更多应用场景。“揭秘LOL”系列的主人公是Tungsten Fabric用户Riot Games游戏公司,作为LOL《英雄联盟》的开发和运营商,Riot Games面临全球范围复杂部署的挑战,让我们一起揭秘LOL背后的“英雄们”,看他们是如何运行在线服务的吧。
作者:Doug Lardo和David Press(文章来源:Riot Games)译者:TF中文社区

本文作者David Press和Doug Lardo是Riot的两名工程师,他们致力于改善数据中心网络,以支撑Riot的在线服务。本文是关于该主题的系列文章第三部分,将讨论我们的SDN(软件定义网络)方法,如何将SDN与Docker集成,以及该组合为我们解锁的新基础架构范例。如果你对SDN如何转换基础架构,如何使开发人员能够通过API获得并保护网络资源,或者如何摆脱购买越来越大的专用网络设备感到好奇,请参阅本文。
在第一篇文章中,Jonathan提到了为支持《英雄联盟》的新功能,在推出服务时面临的一些网络挑战。事实证明,(网络上面的部署)这并不像在服务器上安装代码并按回车那样容易。
新功能需要网络基础架构的所提供的功能,包括:
- 连接性:对玩家和内部服务的低延迟和高吞吐量访问
- 安全性:防止未经授权的访问和DoS攻击,并在需要时进行通信,以最大程度地减少发生漏洞时的影响
- 数据包服务:负载均衡,网络地址转换(NAT),虚拟专用网(VPN),连接性和组播转发
传统上,设置这些网络服务,一直是超级专业的网络工程师的工作领域,他们登录单个网络设备,并输入那些我敢保证就是“纯巫术”一样的命令。配置这些内容通常需要对网络、相关配置,以及出现问题时的响应有深入的了解。
但是,因为不断地扩建,数据中心之间的差异越来越大,使得情况变得更加复杂。对于两个不同数据中心的两个网络工程师来说,相同的目标可能看起来完全不同的动作和任务。
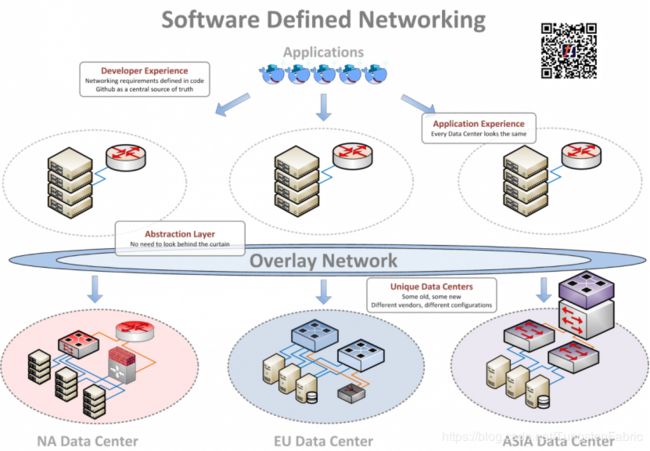
所有这些都意味着,数据中心网络基础架构的更改,通常都会成为推出新服务的瓶颈。幸运的是,在Riot,任何阻碍向玩家提供新奇特效的因素都会立即受到严重关注。rCluster平台旨在解决这一瓶颈,在以下各节中,我们将深入研究它的关键组件:overlay网络概念,OpenContrail(编者按:已更名为Tungsten Fabric,下文中出现OpenContrail之处,均以Tungsten Fabric代替)实施,以及与Docker的集成。在本系列的下一篇文章中,我们将介绍一些细节,例如安全性、负载均衡和系统扩展。
SDN和overlay网络
SDN变成了一个流行语,对不同的人意味着不同的事情:对于某些人来说,这意味着网络配置应由软件定义;但是在Riot,这意味着我们的网络功能应通过一致的API进行编程。
通过使网络可编程化,我们可以编写自动化程序,从而极大地扩展了我们的能力,能够快速将更改部署到网络。我们只需要运行一个命令,而不必将其封装到众多的设备中进行更改(附注:封装的概念是,将网络的功能要求变成不同的的网络设备命令)。我们将全球网络变更的时间从天变成了分钟级,并且这样,还能在空闲时间里去做其它很酷的事情。
网络设备的可编程已经有一段时间了,不过在整个行业中,对这些设备进行编程的接口在不断变化和发展,并且不存在适用于所有类型设备和所有供应商的统一标准。因此,编写能够与多个供应商的每个接口通信的强大自动化程序,是一项非常艰巨的任务。我们也知道,在硬件上方拥有一致的API作为抽象层,是Riot有效扩展其网络配置管理和操作的关键要求。于是,我们转向了overlay网络。(编者按:特意在overlay前面解释网络设备可编程的原因是,网络为应用服务,因为应用的不断变化,因此网络的配置也需要不断变化,尽管网络设备具有可编程性,可以实现业务和网络的编排,但是也面临挑战,供应商不同,配置不同,API不同,很难统一。)
毫无疑问,overlay网络位于现有网络之上。在overlay网络内部的应用程序并不知道网络的存在,因为它在感觉上完全类似于物理网络。如果你熟悉虚拟机,则相同的“物理内部的虚拟”范例也适用于虚拟网络。一个物理网络可以承载许多虚拟网络。在一个虚拟机中,应用程序认为它们拥有一整台物理机,但实际上,它们仅拥有一小部分虚拟机。Overlay网络也是类似的概念,一种内部创建的有虚拟网络的物理基础架构(称为underlay网络)。
这种方法使我们能够将Riot工程师无需担心的各种物理网络细节隐藏起来。工程师不再需要问“有多少端口”,“我们有哪些供应商”,“安全策略应该放在那里”这样的问题。相反,我们可以提供一个一致的API程序,让工程师专注在自己想做的事情上。
在Riot运营的每个数据中心中使用相同的API,使得我们编写的自动化可以在任何地方、任何时间有效工作,无论是使用在过去的第一个数据中心,还是更现代化的设计。此外,我们还可以寻找其他云服务商,例如Amazon、Rackspace、Google Compute等,并且我们的API仍然可以使用。
这样设计,我们的底层物理硬件可能是Cisco、Juniper、Arista、Dell、D-Link、白盒、灰盒、一堆有10GE端口的Linux盒子,这都没关系。但是Underlay网络必须使用特定的方法来构建,例如自动配置模板(更多信息,参见下一篇系列文章),但这使我们能够将物理构建和配置,与应用程序所需的服务配置解耦。当我们将underlay和软件服务接口,保持underlay网络的稳定还有更多好处,我们可以让underlay可以专注于提供高可用性的数据包转发,并允许我们升级物理网络,而不必担心会破坏以前与物理基础架构紧密耦合的应用程序。它还简化了我们的运营,允许服务在任何一个数据中心迁入和移出,并消除了供应商锁定的风险。
总之,我们认为overlay网络非常棒。
Tungsten Fabric
在我们刚开始评估SDN时,研究了整个行业的各种SDN项目。有些通过中央控制器配置物理网络,还有一些则提供了抽象层,将API调用转换为特定于某个供应商的指令。有些解决方案需要新的硬件,还有一些则可以在现有基础架构上运行。有些是由大型公司开发的,还有一些是开源项目,或者由初创公司提供。
简而言之,我们花了很多时间来做功课,这并不是一个容易的决定。我们需要满足的要求包括:
- 在我们的数据中心(无论老的还是新的)、裸机和云中提供功能性
- 是开源的项目,但是也不要在一夜之间消失
- 能够对我们的部署征程提供专业辅助
最终,我们的视线落在了Juniper Networks的Tungsten Fabric项目上。Tungsten Fabric从一开始就被设计为开源的、与供应商无关的解决方案,可与任何一个现有网络一起使用。其核心是BGP和MPLS——两者都是已被证明可以规模化扩展到整个Internet的协议。Juniper Networks肯定不会很快消失,并且在我们设计和安装第一套集群时,提供了很多帮助。(点击“TF架构系列”文章,查看这个控制器的全部细节)
Tungsten Fabric包含三个主要组件:集中控制器(“大脑”),vRouter(虚拟路由器)和外部网关。每个组件都是高可用性集群的成员,因此任何单个设备故障都不会破坏整个系统。与控制器进行API交互,会立即触发其将所有必要的更改,并推送到vRouter和网关,然后由它们物理转发网络上的流量。
Overlay网络由vRouter之间的一系列隧道组成,可供选择的协议包括GRE w / MPLS、UDP w / MPLS或VXLAN。当一个容器想要与另一个容器通信时,vRouter首先在控制器先前向其推送的策略列表中查找该容器所在的位置,然后形成从一个计算节点到另一个计算节点的隧道。隧道接收端的vRouter会检查内部流量以查看其是否与策略相匹配,然后将其传递到预期的目的地。
如果容器希望与Internet或非重叠(non-overlay)目的地通信,流量将被发送到其中一个外部网关。该网关将移除隧道,并将流量发送到Internet,从而保持容器的唯一IP地址完整不变。这使得与遗留应用程序和网络的集成变得容易,因为集群外的任何人都无法分辨出流量是否来自overlay网络。

Docker整合
如果我们不能在overlay网络上让容器运转起来,为玩家做一些实际的工作,那么所有这些都不过是一个有趣的思想实验。
Tungsten Fabric是与虚拟化无关的SDN产品,因此需要与编排器集成,以将调度的计算实例与Tungsten Fabric提供的网络功能相关联。Tungsten Fabric通过Neutron API驱动程序与OpenStack进行了强大的集成,不过由于我们有自己的协调器Admiral,还需要编写我们自己的自定义集成。
此外,Tungsten Fabric与OpenStack的集成最初是为虚拟机设计的,我们希望将其应用于Docker容器。这需要与Juniper Networks合作,以提供一种我们称为“Ensign”的服务,可以在每台主机上运行并处理Admiral、Docker和Tungsten Fabric之间的集成。
为了解释我们如何将Docker与Tungsten Fabric集成在一起,需要先来了解一点Linux网络。Docker使用Linux内核中被称为“网络命名空间(network namespace)”的功能来隔离容器,并防止它们相互访问。网络命名空间本质上是网络接口、路由表和iptables规则的单独堆栈。网络命名空间中的那些元素,仅应用于在命名空间中启动的进程。它与文件系统中使用的chroot很相似,但不同的是它应用于网络。
当我们开始使用Docker时,有四种方法来配置容器,将其附加到的网络命名空间:
- Host network 主机网络模式:Docker将进程放置在主机网络命名空间中,从而有效地使其完全不隔离。
- Bridge network桥接网络模式:Docker创建一个Linux桥接器,该桥接器连接主机上所有容器的网络命名空间,并管理iptables规则以将NAT流量从主机外部传输到容器。
- From network 从网络模式:Docker使用另一个容器的网络命名空间。
- None network 无网络模式:Docker设置了没有接口的网络命名空间,这意味着其中的进程无法连接到命名空间外部的任何内容。
“无网络模式”专为第三方网络整合而创建,这对我们尝试要做的事情很有帮助。在启动容器后,第三方可以将该容器连接到网络所需的所有组件,全部插入网络命名空间。
但是,这也带来了一个问题:容器已经启动,并且在一段时间内没有网络连接。对于应用程序而言,这是一种糟糕的体验,因为许多人想知道在启动时分配了哪些IP地址。尽管Riot开发人员可能已经实现了重试逻辑,但我们不想给他们增加负担。此外,许多第三方容器无法处理此问题,我们对此也无能为力。需要一个更全面的解决方案。
为了克服这个问题,我们在Kubernetes上找到了一个“网络”容器,该容器在主应用程序容器之前启动。我们先在“无网络模式”下启动网络容器(因为它不需要连接或IP地址,所以没有问题),在使用Tungsten Fabric完成网络设置并分配IP之后,再启动主应用程序容器,并使用“从网络模式”将其附加到网络容器的网络命名空间。通过此设置,应用程序在启动时便具有完全可操作的网络堆栈。
当我们在物理计算节点(或主机)内部启动一个新容器时,vRouter会为该容器提供一个虚拟NIC,一个全局唯一IP地址,以及与该容器关联的任何路由或安全策略。
这与默认的Docker网络配置大不相同,在默认配置中,服务器上的每个容器都共享相同的IP地址,并且一台机器上的所有容器都可以自由地相互通信。此行为违背了我们的安全策略,在默认情况下,两个应用程序原本永远都不能执行此操作。在一个安全的、功能丰富的虚拟网络中为每个容器提供自己的IP地址,使得我们能够为容器提供一致的、“一流的”网络体验。它简化了我们的配置、安全策略,并使我们避免了许多Docker容器与主机共享相同IP地址所带来的复杂性。
结论
我们通往SDN和基础设施自动化的道路还很漫长。我们已经学习了很多有关如何建立自主网络的最佳实践,如何调试overlay网络上的连接问题,以及如何处理新的故障模式的知识。此外,我们还必须在集群本身的两代网络架构中部署此SDN,并将其与六个“传统”的数据中心架构相集成。包括在自动化方面进行投资,并学习如何确保我们的系统值得信赖,确保测试能够保持良好的平衡。
话虽如此,我们现在每天都能看到这项工作的成果,Riot的工程师们现在可以通过自服务工作流程,在全球范围内开发、测试和部署其服务,使得网络从持续的延迟和挫折中转变出来,成为增值服务以及每个开发人员工具箱中的一个强大工具。
在rCluster的下一篇文章中,我们将讨论安全性、网络蓝图和ACL,包括系统如何扩展,以及我们为提升正常运行时间所做的一些工作。
如果你有任何想法或疑问,非常欢迎与我们取得联系。
更多“揭秘LOL”系列文章
揭秘LOL背后的IT基础架构丨踏上部署多样性的征程
揭秘LOL背后的IT基础设施丨关键角色“调度”

关注微信:TF中文社区
