ElasticSearch Aggregations使用总结详解
1.单字段情况下聚合
假设只需要对一个字段聚合,比如b字段,b字段是keyword类型,需要考虑的情况最为简单,当要对b字段聚合时语句很好写,如下即可
{
"from": 0,
"size": 0,
"query": {
"bool": {
"must": [{
"bool": {
"should": [{
"terms": {
"field_a": ["1", "2", "3"],
"boost": 1.0
}
}, {
"terms": {
"field_b": ["1", "2", "3"],
"boost": 1.0
}
}],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 1.0
}
}],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"aggregations": {
"my_agg": {
"terms": {
"field": "field_b"
}
}
}
}
这是完整的query,后面的查询会省略掉query部分。query部分的用处也很明显:只把需要做聚合的部分过滤出来做聚合,我们需要统计的数据就在这部分中,而不是整个索引库。这样有两个好处:
1.提高效率,减少需要聚合的数据的数量
2.剔除需要考虑的意外情况,降低语句的复杂度
而聚合部分就非常简单了,仅仅对field_b聚合即可,但是很遗憾,离我们最终目标很远,这样只能统计出b字段的数据分布情况。
示例:
{
"query": {
"bool": {
"must": [{
"terms": {
"track_type": ["31","32"]
}
}
],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 0,
"sort": [],
"aggs": {
"obj_value": {
"terms": {
"field": "obj_value",
"size": 100
}
}
}
}2.多字段情况的聚合
相对于上面的那种,接下来把另外一个字段也考虑进来看看。所以我们写下了这样的请求语句:
"aggregations": {
"my_agg1": {
"terms": {
"field": "tag_brand_id"
}
},
"my_agg2": {
"terms": {
"field": "brand_cid_array"
}
}
}
勉强的可以看到确实也是“统计了两个字段的情况”,但是是分开的,意味着要自己去解析返回结果并做计算来得到最终的返回结果。这确实是很令人恶心的事,那还有没有其他办法呢。但是观察语句的结构发现,似乎并没有过多可以更改的余地,所以需要寻求其他灵活的解决办法。
3.script agg的聚合
简单的单聚合无法表达出多字段聚合的需求,在谷歌过后我寻找到了这样一种解决方案:使用script,即脚本来描述我的需求。下面这段agg就是为了表达我想要根据我的需求灵活处理的一个方式:
"aggregations": {
"my_agg1": {
"terms": {
"script": " if (doc['field_a'].values.contains('1') || doc['field_b'].values.contains('1')){1};if (doc['field_a'].values.contains('2') || doc['field_b'].values.contains('2')){2};
if (doc['field_a'].values.contains('3') || doc['field_b'].values.contains('3')){3};"
}
}
}
这一段脚本的作用很明显,就是告诉es:当a字段或者b字段包括1的时候,扔到桶1;当a字段或者b字段包括2的时候,扔到桶2;……以此类推。看上去确实似乎完全解决了开头提出来的问题,验证后效率还能接受,不是特别慢。但是正当我沾沾自喜以为解决了问题的时候,随手验证了另外一个case,就直接冷水泼头了:
a字段和b字段是可能包含同一个id比如2,但是对于统计结果来说要求算作一条。
用上面这个脚本并无法体现出这个区别,而且还会有一个问题:
请求123和请求321时会返回不同统计结果
因为ifelse语句的关系,和||的性质,在满足条件1后便会扔到桶1,而无法在去后续条件中判断。这个脚本有很明显的bug存在。但是painless毕竟是脚本,可以使用的API和关键字都非常有限,写的复杂了还会很严重影响效率,无奈这个方案也只能pass,即使它看上去差点解决了我的问题。
4.filter agg的聚合
在重新看了官方文档后,我发现了agg中的一个用法,filter agg。
filter agg的用法其实很简单,但是全意外的和我的需求很契合。之前忽视掉这个用法的主要原因是看到的示例都是对单字段做聚合。那如何同时聚合多个字段呢?从API入手验证是否可以使用比较灵活的写法
public KeyedFilter(String key, QueryBuilder filter) {
if (key == null) {
throw new IllegalArgumentException("[key] must not be null");
}
if (filter == null) {
throw new IllegalArgumentException("[filter] must not be null");
}
this.key = key;
this.filter = filter;
}
这是es提供的javaapi中filter agg的构造函数,key就是过滤名称,filter就是过滤条件。而且很友好的是,filter类型为QueryBuilder,也就是说,可以做成比较复杂的过滤方式。
"aggregations": {
"batch_count": {
"filters": {
"filters": {
"1": {
"bool": {
"should": [{
"term": {
"field_a": {
"value": "1",
"boost": 1.0
}
}
}, {
"term": {
"field_b": {
"value": "1",
"boost": 1.0
}
}
}],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"2": {
"bool": {
"should": [{
"term": {
"field_a": {
"value": "2",
"boost": 1.0
}
}
}, {
"term": {
"field_b": {
"value": "2",
"boost": 1.0
}
}
}],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"3": {
"bool": {
"should": [{
"term": {
"field_a": {
"value": "3",
"boost": 1.0
}
}
}, {
"term": {
"field_b": {
"value": "3",
"boost": 1.0
}
}
}],
"adjust_pure_negative": true,
"boost": 1.0
}
}
},
"other_bucket": false,
"other_bucket_key": "-1"
}
}
}ES使用script进行聚合
使用es进行聚合, 但是常规的聚合无法在聚合中进行复杂操作,
如:
select avg(field1> 12), sum(round(field2, 1)) from table; ES可以使用
ScriptedMetricAggregationBuilder进行复杂的聚合操作但是目前处于试验阶段, 后期可能继续完善, 也可能删除.
官网原文:
This functionality is experimental and may be changed or removed completely in a future release. Elastic will take a best effort approach to fix any issues, but experimental features are not subject to the support SLA of official GA features.
引用:https://www.elastic.co/guide/en/elasticsearch/reference/6.3/search-aggregations-metrics-scripted-metric-aggregation.html
案例:
POST ledger/_search?size=0
{
"query" : {
"match_all" : {}
},
"aggs": {
"profit": {
"scripted_metric": {
"init_script" : "params._agg.transactions = []",
"map_script" : "params._agg.transactions.add(doc.type.value == 'sale' ? doc.amount.value : -1 * doc.amount.value)",
"combine_script" : "double profit = 0; for (t in params._agg.transactions) { profit += t } return profit",
"reduce_script" : "double profit = 0; for (a in params._aggs) { profit += a } return profit"
}
}
}
}
输出
{
"took": 218,
...
"aggregations": {
"profit": {
"value": 240.0
}
}
}
关键词说明:
脚本化度量标准聚合在其执行的4个阶段使用脚本:
init_script
在任何文件集合之前执行。允许聚合设置任何初始状态。
在上面的示例中,在对象中init_script创建一个数组。transactions_agg
map_script
每个收集的文件执行一次。这是唯一必需的脚本。如果未指定combine_script,则生成的状态需要存储在名为的对象中_agg。
在上面的示例中,map_script检查type字段的值。如果值为sale,则amount字段的值将添加到transactions数组中。如果类型字段的值不是销售,则金额字段的否定值将添加到交易中。
combine_script
文档收集完成后,在每个分片上执行一次。允许聚合合并从每个分片返回的状态。如果未提供combine_script,则组合阶段将返回聚合变量。
在上面的示例中,combine_script迭代遍历所有存储的事务,对profit变量中的值求和并最终返回profit。
reduce_script
在所有分片返回结果后,在协调节点上执行一次。该脚本提供对变量的访问,该变量_aggs是每个分片上combine_script结果的数组。如果未提供reduce_script,则reduce阶段将返回_aggs变量。
在上面的示例中,reduce_script迭代通过profit每个分片返回的值,在返回最终组合利润之前对值进行求和,该最终组合利润将在聚合的响应中返回。JavaAPI
案例
ScriptedMetricAggregationBuilder aggregation = AggregationBuilders
.scriptedMetric("agg")
.initScript(new Script("params._agg.heights = []"))
.mapScript(new Script("params._agg.heights.add(doc.gender.value == 'male' ? doc.height.value : -1.0 * doc.height.value)"))
.combineScript(new Script("double heights_sum = 0.0; for (t in params._agg.heights) { heights_sum += t } return heights_sum"))
.reduceScript(new Script("double heights_sum = 0.0; for (a in params._aggs) { heights_sum += a } return heights_sum"));
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.metrics.tophits.TopHits;
// sr is here your SearchResponse object
ScriptedMetric agg = sr.getAggregations().get("agg");
Object scriptedResult = agg.aggregation();
logger.info("scriptedResult [{}]", scriptedResult);
输出:
scriptedResult object [Double]
scriptedResult [2.171917696507009]
elasticsearch aggregation groovy script 语法各种输出
返回map
"scripted_terms": {
"scripted_metric": {
"init_script": "_agg[\"prd\"] = []",
"map_script": "if(doc[\"cat2_id\"].value) {_agg.prd.add(doc[\"cat2_id\"].value.toString())}",
"combine_script": "combined = [:]; for (tmp in _agg.prd) { if(!combined[tmp]) { combined[tmp] = 1 } }; return combined",
"reduce_script": "reduced = [:]; for (a in _aggs) { for (entry in a) { word = entry.key; if (!reduced[word] ) { reduced[word] = entry.value; } } }; return reduced"
}
}
返回array
"scripted_terms": {
"scripted_metric": {
"init_script": "_agg[\"prd\"] = []",
"map_script": "if(doc[\"cat2_id\"].value) {_agg.prd.add(doc[\"cat2_id\"].value.toString())}",
"combine_script": "combined = [:]; for (tmp in _agg.prd) { if(!combined[tmp]) { combined[tmp] = 1 } }; return combined",
"reduce_script": "reduced = []; for (a in _aggs) { for (entry in a) { reduced.add(entry.key); } }; return reduced"
}
}
统计求和
"agg1" : {
"scripted_metric" : {
"init_script" : {
"inline" : "_agg[\"prd\"] = []"
},
"map_script" : {
"inline" : "if(doc[\"cat2_id\"].value) {_agg.prd.add(doc[\"cat2_id\"].value.toString())}"
},
"combine_script" : {
"inline" : "combined = [:]; for (tmp in _agg.prd) { if(!combined[tmp]) { combined[tmp] = 1 } else { combined[tmp]=combined[tmp]+1 } }; return combined"
},
"reduce_script" : {
"inline" : "reduced = [:]; for (a in _aggs) { for (entry in a) { word = entry.key; if (!reduced[word] ) { reduced[word] = entry.value; } else { reduced[word]=reduced[word]+entry.value} } }; return reduced"
}
}
}返回set
{
"query": {
"bool": {
"must": [{
"term": {
"business_code": "005"
}
}, {
"term": {
"tenant_code": "00000007"
}
}, {
"term": {
"delete_status": "0"
}
}, {
"bool": {
"should": [{
"term": {
"list_type": "02"
}
}, {
"term": {
"list_type": "01"
}
}]
}
}],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 1000,
"sort": [],
"aggs": {
"obj_value": {
"terms": {
"field": "obj_value",
"size": 1000
},
"aggs": {
"list_types": {
"scripted_metric": {
"init_script": "params._agg.list_type_set=[];",
"map_script": "params._agg.list_type_set.add(doc['list_type'].value)",
"reduce_script": "def list_types=new HashSet();params._aggs.forEach(item->{list_types.addAll(item.list_type_set);});return list_types"
}
}
}
}
}
}
返回string
{
"query": {
"bool": {
"must": [{
"term": {
"business_code": "005"
}
}, {
"term": {
"tenant_code": "00000007"
}
}, {
"term": {
"delete_status": "0"
}
}, {
"bool": {
"should": [{
"term": {
"list_type": "02"
}
}, {
"term": {
"list_type": "01"
}
}]
}
}],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 1000,
"sort": [],
"aggs": {
"obj_value": {
"terms": {
"field": "obj_value",
"size": 1000
},
"aggs": {
"list_types": {
"scripted_metric": {
"init_script": "params._agg.list_type_set=[];",
"map_script": "params._agg.list_type_set.add(doc['list_type'].value)",
"reduce_script": "def list_types=new HashSet();params._aggs.forEach(item->{list_types.addAll(item.list_type_set);});return list_types.toString()"
}
}
}
}
}
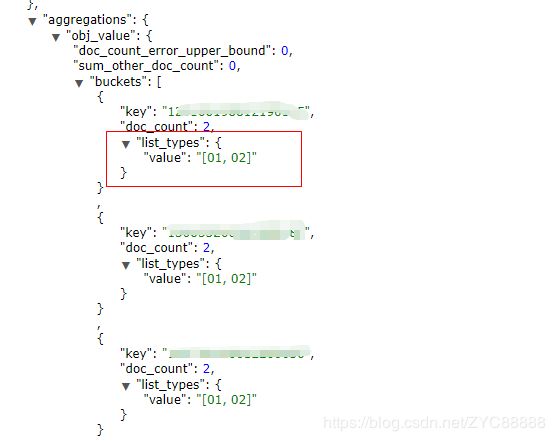
}
计算两个字段的乘积
每成交一笔生成一条记录,其中有两个字段,一个是单价(price),一个是成交量(amount),计算出5天内成交总额
curl -XPOST 'localhost:9200/order/_search?size=0&pretty' -H 'Content-Type: application/json' -d'
{
"query" : {
"filtered": {
"query": {"match_all": {}},
"filter": {
"range": {
"date": {
"from": ...,
"to": ...
}
}
}
}
}
},
"aggs": {
"total": {
"scripted_metric": {
"init_script" : "params._agg.transactions = []",
"map_script" : "params._agg.transactions.add(doc.price.value * doc.amount.value)",
"combine_script" : "double total = 0; for (t in params._agg.transactions) { total += t } return total",
"reduce_script" : "double total = 0; for (a in params._aggs) { total += a } return total"
}
}
}
}
'聚合查询结果后过滤
{
"query": {
"bool": {
"must": [{
"term": {
"business_code": "005"
}
}, {
"term": {
"tenant_code": "00000007"
}
}, {
"term": {
"delete_status": "0"
}
}, {
"bool": {
"should": [{
"term": {
"list_type": "02"
}
}, {
"term": {
"list_type": "01"
}
}]
}
}],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 1000,
"sort": [],
"post_filter": {
"bool": {
"must": [{
"wildcard": {
"list_types": "*02*"
}
}]
}
},
"aggs": {
"obj_value": {
"terms": {
"field": "obj_value",
"size": 1000
},
"aggs": {
"list_types": {
"scripted_metric": {
"init_script": "params._agg.list_type_set=[];",
"map_script": "params._agg.list_type_set.add(doc['list_type'].value)",
"reduce_script": "def list_types=new HashSet();params._aggs.forEach(item->{list_types.addAll(item.list_type_set);});return list_types.toString()"
}
}
}
}
}
} 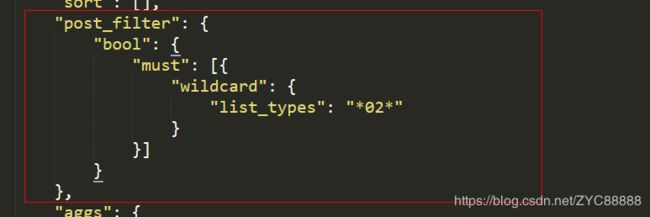
过滤 仅 01 情况

参照:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_post_filter.html
官网API引用:
https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.3/_metrics_aggregations.html#_use_aggregation_response_13
聚合分组排序分页查询
{
"query": {
"bool": {
"must": [
{
"term": {
"business_code": "005"
}
},
{
"term": {
"tenant_code": "00000007"
}
},
{
"term": {
"delete_status": "0"
}
},
{
"bool": {
"should": [
{
"term": {
"list_type": "02"
}
},
{
"term": {
"list_type": "01"
}
}
]
}
}
],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 0,
"sort": [
{
"create_time": {
"order": "desc"
}
}
],
"post_filter": {
"bool": {
"must": [
{
"term": {
"list_type": "02"
}
}
]
}
},
"aggs": {
"obj_value": {
"terms": {
"field": "obj_value",
"order": {
"create_time_order": "desc"
},
"size": 1000
},
"aggs": {
"list_type_value": {
"scripted_metric": {
"init_script": "params._agg.list_type_set=[];",
"map_script": "params._agg.list_type_set.add(doc['list_type'].value)",
"reduce_script": "def list_types=new HashSet();def ret=1; params._aggs.forEach(item->{list_types.addAll(item.list_type_set);}); if(list_types.contains('01')){ret*=2} if(list_types.contains('02')){ret*=3} return ret;"
}
},
"list_types": {
"scripted_metric": {
"init_script": "params._agg.list_type_set=[];",
"map_script": "params._agg.list_type_set.add(doc['list_type'].value)",
"reduce_script": "def list_types=new HashSet();params._aggs.forEach(item->{list_types.addAll(item.list_type_set);});return list_types.toString()"
}
},
"list_type_filter": {
"bucket_selector": {
"buckets_path": {
"listTypeValue": "list_type_value.value"
},
"script": "params.listTypeValue % 3 == 0"
}
},
"create_time_order": {
"max": {
"field": "create_time"
}
},
"bucket_field": {
"bucket_sort": {
"sort": [
{
"create_time_order": {
"order": "desc"
}
}
],
"from": 10,
"size": 10
}
}
}
}
}
}特别注意:
外层排序字段应该与内层排序一致,from、size均保持一致
内层bucket size大小应大于等于 内层from*size大小

部分java关键代码
/**
* 根据参数查询
*
* @param queryParam 查询参数
* @return 查询构建器
*/
public static TermsAggregationBuilder queryAggregationBuilder(ObjectMultiListQueryParam queryParam) {
int page = queryParam.getPageNum() == null || queryParam.getPageNum() <= 0 ? 1 : queryParam.getPageNum();
int pageSize = queryParam.getPageSize() == null || queryParam.getPageSize() <= 0 ? 50
: queryParam.getPageSize();
pageSize = pageSize > 500 ? 500 : pageSize;
int size = page * pageSize;
//聚合分组 先按value
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms(ObjectBasicFieldCst.OBJ_VALUE)
.field(ObjectBasicFieldCst.OBJ_VALUE)
.size(size);
StringBuilder reduceScriptSb = new StringBuilder();
reduceScriptSb.append(
"def list_types=new HashSet();def ret=1; params._aggs.forEach(item->{list_types.addAll(item"
+ ".list_type_set);}); ");
if (CollectionUtils.isNotEmpty(queryParam.getIncludeListTypes())) {
for (String code : queryParam.getIncludeListTypes()) {
ListTypeEnum listTypeEnum = ListTypeEnum.parse(code);
if (ObjectUtils.nonNull(listTypeEnum)) {
reduceScriptSb.append("if(list_types.contains('").append(listTypeEnum.getCode()).append("')){ret*=")
.append(listTypeEnum.getScore()).append("}");
}
}
}
reduceScriptSb.append("return ret;");
// 算分
Script initScript = new Script("params._agg.list_type_set=[];");
Script mapScript = new Script("params._agg.list_type_set.add(doc['list_type'].value)");
Script reduceScript = new Script(reduceScriptSb.toString());
ScriptedMetricAggregationBuilder listTypeValueScriptedMetricAggregationBuilder = AggregationBuilders
.scriptedMetric(
ObjectBasicFieldCst.LIST_TYPES_VALUE).initScript(initScript).mapScript(mapScript).reduceScript(
reduceScript);
aggregationBuilder.subAggregation(listTypeValueScriptedMetricAggregationBuilder);
Script listTypesReduceScript = new Script(
"def list_types=new HashSet();params._aggs.forEach(item->{list_types.addAll(item.list_type_set);});return"
+ " list_types");
ScriptedMetricAggregationBuilder listTypeScriptedMetricAggregationBuilder = AggregationBuilders.scriptedMetric(
ObjectBasicFieldCst.LIST_TYPE_SET).initScript(initScript).mapScript(mapScript).reduceScript(
listTypesReduceScript);
aggregationBuilder.subAggregation(listTypeScriptedMetricAggregationBuilder);
if (CollectionUtils.isNotEmpty(queryParam.getMustIncludeListTypes())) {
// 声明BucketPath,用于后面的bucket筛选
Map bucketsPathsMap = new HashMap<>(1, 1);
bucketsPathsMap.put("listTypesValue", "list_types_value.value");
int filterScore = 1;
for (String code : queryParam.getMustIncludeListTypes()) {
ListTypeEnum listTypeEnum = ListTypeEnum.parse(code);
if (ObjectUtils.nonNull(listTypeEnum)) {
filterScore *= listTypeEnum.getScore();
}
}
// 设置脚本
Script listTypeFilterScript = new Script("params.listTypesValue % " + filterScore + " == 0");
// 构建bucket选择器
BucketSelectorPipelineAggregationBuilder filterBs = PipelineAggregatorBuilders.bucketSelector(
"list_type_filter",
bucketsPathsMap, listTypeFilterScript);
aggregationBuilder.subAggregation(filterBs);
}
//
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("create_time_order").field(
ObjectBasicFieldCst.CREATE_TIME);
aggregationBuilder.subAggregation(maxAggregationBuilder);
List sorts = Lists.newArrayList();
FieldSortBuilder fieldSortBuilder = new FieldSortBuilder("create_time_order");
fieldSortBuilder.order(SortOrder.DESC);
sorts.add(fieldSortBuilder);
BucketSortPipelineAggregationBuilder bucketSortPipelineAggregationBuilder = PipelineAggregatorBuilders
.bucketSort("create_time_bucket_field", sorts).from(page - 1).size(pageSize);
aggregationBuilder.subAggregation(bucketSortPipelineAggregationBuilder);
aggregationBuilder.executionHint("map").collectMode(Aggregator.SubAggCollectionMode.BREADTH_FIRST);
return aggregationBuilder;
}
post filter
searchSourceBuilder.size(0);
searchSourceBuilder.aggregation(termsAggregationBuilder);
if (CollectionsHelper.isNotEmpty(param.getMustIncludeListTypes())) {
QueryBuilder postQueryBuilder = QueryBuilders.boolQuery().must(
QueryBuilders.termsQuery(ObjectBasicFieldCst.LIST_TYPE,
param.getMustIncludeListTypes()));
searchSourceBuilder.postFilter(postQueryBuilder);
}
searchRequest.source(searchSourceBuilder);
==============================================
bucket_selector前提
假设我们的文档包括以下几个字段 : activityId, clientIp, orderNumber
目标
依据activityId(策略ID) + clientIp(IP地址)分组聚合, 查找相同策略ID+相同IP下订单数目超过2的聚合结果
实现
{
"request_body": {
// 不返回具体的查询数据
"size": 0,
"aggs": {
"group_by_activityId": {
"terms": {
// 多字段聚合
"script": "doc['activityId'].values +'#split#'+ doc['clientIp'].values",
// 设置聚合返回的最大数目
"size": 2147483647
},
"aggs": {
// 依据orderNumber去重统计数目
"orderNumber_count": {
"cardinality": {
"field": "orderNumber"
}
},
"orderNumber_count_filter": {
"bucket_selector": {
"buckets_path": {
"orderNumberCount": "orderNumber_count"
},
// 筛选去数目>1
"script": "params.orderNumberCount>1"
}
}
}
}
}
}
}
这个聚合使用于做分桶后的过滤的,父聚合传下来的参数需要为数值型,聚合中的script需要返回一个布尔型的结果
语法
{
"bucket_selector": {
"buckets_path": {
"my_var1": "the_sum",
"my_var2": "the_value_count"
},
"script": "params.my_var1 > params.my_var2"
}
}参数
| 参数 | 描述 | 是否必填 | 默认值 |
|---|---|---|---|
| script | 过滤条件 | 是 | |
| buckets_path | 上层聚合的变量 | 是 | |
| gap_policy | 当出现间隔时候的处理方式 | 否 | skip |
#示例 返回按月聚合后销售额大于400的结果
POST /sales/_search
{
"size": 0,
"aggs" : {
"sales_per_month" : {
"date_histogram" : {
"field" : "date",
"interval" : "month"
},
"aggs": {
"total_sales": {
"sum": {
"field": "price"
}
},
"sales_bucket_filter": {
"bucket_selector": {
"buckets_path": {
"totalSales": "total_sales"
},
"script": "params.totalSales > 200"
}
}
}
}
}
}每个IP登录人数超过2的IP
这个是对登录记录用户ID的去重数聚合,然后过滤。对用户ID进行去重可以使用Cardinality Aggregation聚合,然后再使用Bucket Selector Aggregation聚合过滤器过滤数据。具体内容如下: 查询语句
{
"aggs": {
"IP": {
"terms": {
"field": "IP",
"size": 3000,
"order": {
"distinct": "desc"
},
"min_doc_count": 5
},
"aggs": {
"distinct": {
"cardinality": {
"field": "IP.keyword"
}
},
"dd":{
"bucket_selector": {
"buckets_path": {"userCount":"distinct"},
"script": "params.userCount > 2"
}
}
}
}
},
"size": 0
}桶聚合选择器:
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/search-aggregations-pipeline-bucket-selector-aggregation.html
Elasticsearch多字段分组聚合, 并对分组聚合的count进行筛选
前提
假设我们的文档包括以下几个字段 : activityId, clientIp, orderNumber
目标
依据activityId(策略ID) + clientIp(IP地址)分组聚合, 查找相同策略ID+相同IP下订单数目超过2的聚合结果
实现
{
"request_body": {
// 不返回具体的查询数据
"size": 0,
"aggs": {
"group_by_activityId": {
"terms": {
// 多字段聚合
"script": "doc['activityId'].values +'#split#'+ doc['clientIp'].values",
// 设置聚合返回的最大数目
"size": 2147483647
},
"aggs": {
// 依据orderNumber去重统计数目
"orderNumber_count": {
"cardinality": {
"field": "orderNumber"
}
},
"orderNumber_count_filter": {
"bucket_selector": {
"buckets_path": {
"orderNumberCount": "orderNumber_count"
},
// 筛选去数目>1
"script": "params.orderNumberCount>1"
}
}
}
}
}
}
}======================================
常见问题:
1、类型异常
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "lbs_20190410",
"node": "Uj-ZStATT9y66mIBIHbpKA",
"reason": {
"type": "i_o_exception",
"reason": "can not write type [class java.util.HashSet]"
}
}
]只支持primitive types,String,Map,Array四种类型
异常查询语句
{
"query": {
"bool": {
"must": [{
"term": {
"business_code": "005"
}
}, {
"term": {
"tenant_code": "00000007"
}
}, {
"term": {
"delete_status": "0"
}
}, {
"bool": {
"should": [{
"term": {
"list_type": "02"
}
}, {
"term": {
"list_type": "01"
}
}]
}
}],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 1000,
"sort": [],
"aggs": {
"obj_value": {
"terms": {
"field": "obj_value",
"size": 1000
},
"aggs": {
"list_types": {
"scripted_metric": {
"init_script": "params._agg.list_type_set=new HashSet();",
"map_script": "params._agg.list_type_set.add(doc['list_type'].value)",
"reduce_script": "def list_types=new HashSet();params._aggs.forEach(item->{list_types.addAll(item.list_type_set);});return list_types"
}
}
}
}
}
}
解决方式:
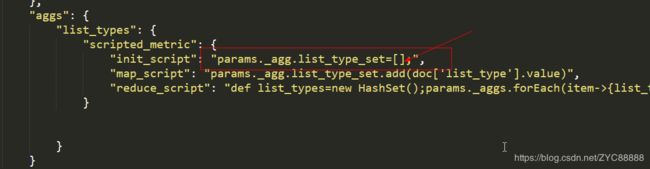
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/search-aggregations-metrics-scripted-metric-aggregation.html#_allowed_return_types
Whilst any valid script object can be used within a single script, the scripts must return or store in the _agg object only the following types:
primitive types
String
Map (containing only keys and values of the types listed here)
Array (containing elements of only the types listed here)
params._agg.a=new HashSet(); 改为params._agg.a=[];
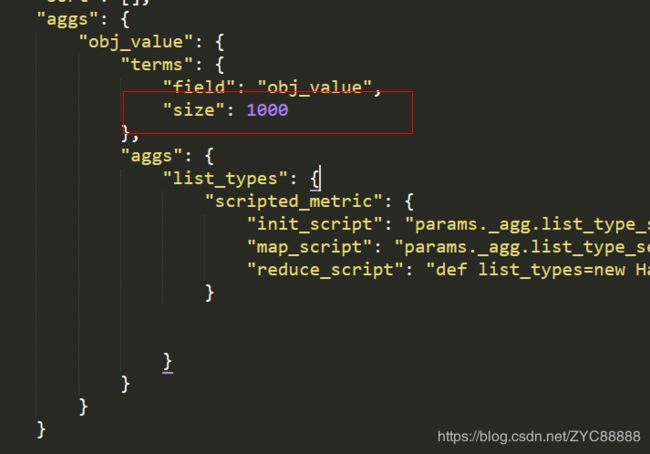
2、聚合返回仅10条(默认)
解决方式,需要在聚合中增加限制
3、elasticsearch中must和should组合查询
例如在a=1且b=2的数据中,找出c=1或者d=2的数据例如在a=1且b=2的数据中,找出c=1或者d=2的数据:
{"query": {
"bool": {
"must": [
{"term": {"a": "1"}},
{"term":{"b": "2"}}
],
"should": [
{"term": {"c": "1"}},
{"term": {"d": "2"}}
]
}
}
}
这样写的时候should是没有用的,这是新手可能犯的错误之一。
在编写查询条件的时候,不能用口头上的逻辑进行编写,而是要换成数学逻辑才能进行执行(数据库同理)。
如上例,数学逻辑应该是 (a==1&&b==2&&c==1)||(a==1&&b==2&&d==2)(java and c语言版),这样的结构去查询。解决
具体写法有2种:
{
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{"term": {"a": "1"}},
{"term":{"b": "2"}},
{"term": {"c": "1"}}
]
}
},
{
"bool": {
"must": [
{"term": {"a": "1"}},
{"term":{"b": "2"}},
{"term": {"d": "2"}}
]
}
}
]
}
},
"sort": {
"time": {
"order": "desc"
}
},
"size": 100
}
或者:
{
"query": {
"bool": {
"must": [
{"term": {"a": "1"}},
{"term":{"b": "2"}}
{
"bool": {
"should": [
{"term": {"c": "1"}},
{"term": {"d": "2"}}
]
}
}
]
}
},
"sort": {
"time": {
"order": "desc"
}
},
"size": 100
}JAVA API
QueryBuilder query = QueryBuilders.boolQuery()
.should(QueryBuilders.boolQuery()
.filter(QueryBuilders.termQuery("a", 1))
.filter(QueryBuilders.termQuery("b", 2))
.filter(QueryBuilders.termQuery("c", 1))
.should(QueryBuilders.boolQuery()
.filter(QueryBuilders.termQuery("a", 1))
.filter(QueryBuilders.termQuery("b", 2))
.filter(QueryBuilders.termQuery("d", 2));
============================================
其实shoule在与must或者filter同级时,默认是不需要满足should中的任何条件的,此时我们可以加上minimum_should_match 参数,来达到我们的目的,即上述代码改为:
{
"query": {
"bool": {
"must": [
{
"match": {
"c": "3"
}
}
],
"should": [
{
"match": {
"a": "1"
},
{
"match": {
"b": "2"
}
}
],
"minimum_should_match": 1
}
}
}
上述代码表示,必须满足must中的所有条件,并且至少满足should中的一个条件,这样,就得到了预期的结果。
==========================================================
JAVA开发
Aggregation 概述
Aggregation 可以和普通查询结果并存,一个查询结果中也允许包含多个不相关的Aggregation. 如果只关心聚合结果而不关心查询结果的话会把SearchSource的size设置为0,能有效提高性能.
Aggregation 类型
-
Metrics:
简单聚合类型, 对于目标集和中的所有文档计算聚合指标, 一般没有嵌套的sub aggregations. 比如 平均值(avg) , 求和 (sum), 计数 (count), 基数 (cardinality). Cardinality对应distinct count -
Bucketing:
桶聚合类型, 在一系列的桶而不是所有文档上计算聚合指标,每个桶表示原始结果集合中符合某种条件的子集. 一般有嵌套的sub aggregations. 典型的如TermsAggregation, HistogramAggregation -
Matrix:
矩阵聚合, 多维度聚合, 即根据两个或者多个聚合维度计算二维甚至多维聚合指标表格. 目前貌似只有一种MatrixStatAggregation. 并且目前不支持脚本(scripting) - Pipeline:
管道聚合, 在之前聚合结果的基础上再次进行聚合计算, 往往和Bucketing Aggregation 结合起来使用. 举列: 先求出过去30天每天的交易总金额 (Bucketing aggregation),再统计交易总金额大于10000的天数 (Pipeline aggregation).
Aggregation 结构
Aggregation request:
两层结构:
Aggregation -> SubAggregation
Sub aggregation是在原来的Aggregation的计算结果中进一步做聚合计算
Aggregation response:
三层结构: (针对Bucketing aggregation) MultiBucketsAggregation -> Buckets -> Aggregations
Aggregation 属性:
name: 和请求中的Aggregation的名字对应
buckets: 每个Bucket对应Agggregation结果中每一个可能的取值和相应的聚合结果.
Bucket 属性:
key: 对应的是聚合维度可能的取值, 具体的值和Aggregation的类型有关, 比如Term aggregation (按交易类型计算总金额), 那么Bucket key值就是所有可能的交易类型 (credit/debit etc). 又比如DateHistogram aggregation (按天计算交易笔数), 那么Bucket key值就是具体的日期.
docCount: 对应的是每个桶中的文本数量.
value: 对应的是聚合指标的计算结果. 注意如果是多层Aggregation计算, 中间层的Aggregation value一般没有值, 比如Term aggregation. 只有到底层具体计算指标的Aggregation才有值.
aggregations: 对应请求中当前Aggregation的subAggregation的计算结果 (如果存在)
SQL映射成Aggregation
SQL映射实现的前提: 只针对聚合计算,即sql select部分存在聚合函数类型的column
映射过程很难直接描述,上几个例子方便大家理解,反正SQL的结构也无非就是SELECT/FROM/WHERE/GROUP BY/HAVING/ORDER BY. ORDER BY先不讨论,一般聚合结果不太关心顺序. FROM也很容易理解,就是索引的名字.
SQL组成部分对应的ES Builder:
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| select column (聚合函数) | MetricsAggregationBuilder 由 column对应聚合函数决定 (例如 MaxAggregationBuilder) | |
| select column (group by 字段) | Bucket key | |
| where | FiltersAggregationBuilder + FiltersAggregator.KeydFilter | keyedFilter = FiltersAggregator.KeyedFilter("combineCondition", sub QueryBuilder) AggregationBuilders.filters("whereAggr", keyedFilter) |
| group by | TermsAggregationBuilder | AggregationBuilders.terms("aggregation name").field(fieldName) |
| having | MetricsAggregationBuilder 由 having 条件聚合函数决定 (例如 MaxAggregationBuilder) + BucketSelectorPipelineAggregationBuilder | PipelineAggregatorBuilders.bucketSelector(aggregationName, bucketPathMap, script) |
常用的SQL运算符和聚合函数对应的ES Builder:
| Sql element | Aggregation Type | Code to build |
|---|---|---|
| count(field) | ValueCountAggregationBuilder | AggregationBuilders.count(metricsName).field(fieldName) |
| count(distinct field) | CardinalityAggregationBuilder | AggregationBuilders.cardinality(metricsName).field(fieldName) |
| sum(field) | SumAggregationBuilder | AggregationBuilders.sum(metricsName).field(fieldName) |
| min(field) | MinAggregationBuilder | AggregationBuilders.min(metricsName).field(fieldName) |
| max(field) | MaxAggregationBuilder | AggregationBuilders.max(metricsName).field(fieldName) |
| avg(field) | AvgAggregationBuilder | AggregationBuilders.avg(metricsName).field(fieldName) |
| AND | BoolQueryBuilder | QueryBuilders.boolQuery().must().add(sub QueryBuilder) |
| OR | BoolQueryBuilder | QueryBuilders.boolQuery().should().add(sub QueryBuilder) |
| NOT | BoolQueryBuilder | QueryBuilders.boolQuery().mustNot().add(sub QueryBuilder) |
| = | TermQueryBuilder | QueryBuilders.termQuery(fieldName, value) |
| IN | TermsQueryBuilder | QueryBuilders.termsQuery(fieldName, values) |
| LIKE | WildcardQueryBuilder | QueryBuilders.wildcardQuery(fieldName, value) |
| > | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).gt(value) |
| >= | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).gte(value) |
| < | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).lt(value) |
| <= | RangeQueryBuilder | QueryBuilders.rangeQuery(fieldName).lte(value) |
1.select count(payerId) as payerCount from Payment group by country
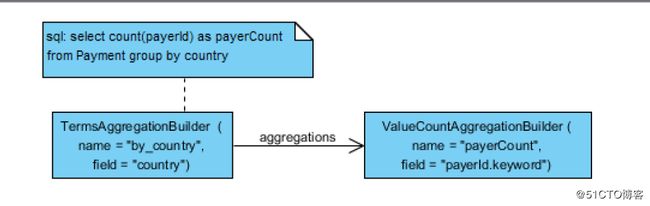
这里需要注意的是payerId这个doc的属性在实际构造的Aggregation query 中变成了 payerId.keyword,Elasticsearch 默认对于分词的字段(text类型)不支持聚合,会报出 "Fielddata is disabled on text fields by default. Set fielddata=true"的错误. fielddata聚合是一个非常costly的运算,一般不建议使用. 好在Elasticsearch索引时默认会对payerId这个属性生成两个字段, payerId 是分词的text类型, payerId.keyword是不分词的keyword类型.
2.select max(payerId) from Payment group by accountId, country
两个group by 条件对应两层term aggregation
3.select count(distinct payerId) as payerCount from Payment where country in (‘CN‘, ‘GE‘) group by accountId, country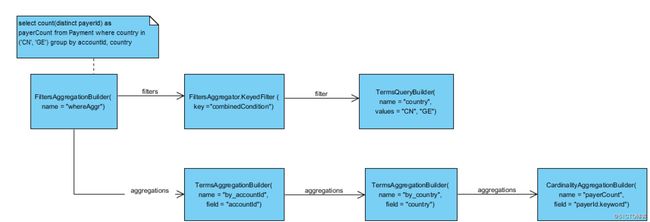
增加了where条件, 在顶层是一个FiltersAggregationBuilder. 其中分为两部分, 其中filters对应的是所有查询条件构建的一个KeyedFilter, 其中又包含了多个子查询条件. aggregations 对应的是groupBy条件和select部分的聚合函数
4.select count(distinct payerId) as payerCount from Payment where withinTime(createAt, 1, ‘DAY‘) and name like ‘%SH%‘ group by accountId, country
多个where条件, 用BoolQueryBuilder组合起来
5.select max(amount) as maxAmt, min(amount) as minAmt from Payment where amount > 1000.00 or amount <= 50.53 group by accountId, country having count(distinct beneficiaryId) > 3 and sum(amount) > 1530.20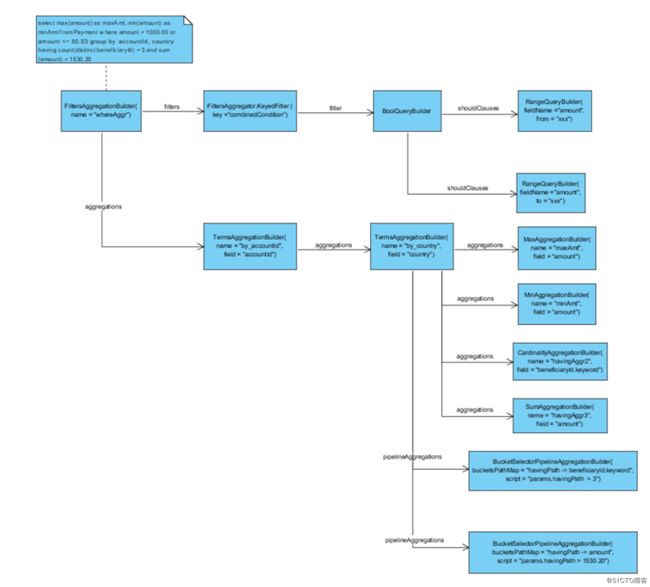
史上最复杂SQL产生! 这里主要关注having部分的处理, 用到了Pipeline类型的BucketSelectorPipelineAggregationBuilder. 在最后一个GroupBy 条件对应的term aggregation下增加了两类子节点: sub aggregations 除了包括select 部分的聚合函数还包括having条件对应的聚合函数. pipeline aggregations 包括having条件对应的 BucketSelectorPipelineAggregationBuilder. BucketSelectorPipelineAggregationBuilder 主要的属性有: bucketsPathMap: 保存了path的名字和对应的聚合属性的映射,script: 用脚本描述聚合条件,但是条件左侧不直接使用属性名而是path的名字替换
注意虽然从逻辑上来说having 条件是应用在之前计算出聚合的结果之上, 但是从ES Aggregation的结构来看, BucketSelectorPipelineAggregationBuilder和having 条件中对应聚合指标的Aggregation是兄弟关系而不是父子关系!
另外要注意script path 是对于兄弟节点(sibling node)一个相对路径而不是从根节点Aggregation的绝对路径,用的是聚合属性的名称而不是Aggregation本身的名称. 并且要求根据路径访问到的Bucket必须是唯一的,因为BucketSelector只是根据条件判断当前Bucket是否被选择, 如果路径返回多个Bucket则无法应用这种Bool判断.
6.select count(paymentId) from Payment group by timeRange(createdAt, ‘1D‘, ‘yyyy/MM/dd‘)
这里用到一个自定义函数timeRage, 表示对于createAt这个属性按天聚合,对应的ES aggregation类型为DateHistogramAggregation
其他注意事项
Bucket count
Distinct count: Elasticsearch 采用的是基于hyperLogLog的近似算法.
Reference
https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html
======================================================================
Elasticsearch-sql groupby 聚合查询limit查询操作
在使用Elasticsearch-sql插件查询ES中,我们经常遇到多个字段group by聚合查询,例如:
select /*! IGNORE_UNAVAILABLE */ SUM(errorCount) as num
from ctbpm-js-data-2018-w32,ctbpm-js-data-2018-w27,ctbpm-js-data-2018-w28,
ctbpm-js-data-2018-w29,ctbpm-js-data-2018-w30,ctbpm-js-data-2018-w31
where appCode = '5f05acfc9a084d9f9a07e165a2516c18' and logTime>= '2018-07-07T09:57:15.436Z' and logTime<= '2018-08-07T09:57:15.436Z'
group by pageRef,province,city,ip limit 100解析后:
{
"from": 0,
"size": 0,
"query": {
"bool": {
"filter": [
{
"bool": {
"must": [
{
"bool": {
"must": [
{
"match_phrase": {
"appCode": {
"query": "5f05acfc9a084d9f9a07e165a2516c18",
"slop": 0,
"boost": 1
}
}
},
{
"range": {
"logTime": {
"from": "2018-07-07T09:57:15.436Z",
"to": null,
"include_lower": true,
"include_upper": true,
"boost": 1
}
}
},
{
"range": {
"logTime": {
"from": null,
"to": "2018-08-07T09:57:15.436Z",
"include_lower": true,
"include_upper": true,
"boost": 1
}
}
}
],
"disable_coord": false,
"adjust_pure_negative": true,
"boost": 1
}
}
],
"disable_coord": false,
"adjust_pure_negative": true,
"boost": 1
}
}
],
"disable_coord": false,
"adjust_pure_negative": true,
"boost": 1
}
},
"_source": {
"includes": [
"SUM"
],
"excludes": []
},
"aggregations": {
"pageRef": {
"terms": {
"field": "pageRef",
"size": 100,
"shard_size": 2000,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"province": {
"terms": {
"field": "province",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"city": {
"terms": {
"field": "city",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"ip": {
"terms": {
"field": "ip",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"num": {
"sum": {
"field": "errorCount"
}
}
}
}
}
}
}
}
}
}
}
}
我们看到解析后的json看到:limit 15中的15只对group by 后面的第一个字段起作用,其他的字段size其实都是10,limit并没起作用,这就是Elasticsearch-sql针对group by存在的问题。
解决方式为:
使用terms(field='correspond_brand_name',size='10',alias='correspond_brand_name',include='\".*sport.*\"',exclude='\"water_.*\"')")
注意:这种方式不再添加limit关键词,另外还要注意group by后面字段的顺序不一样,因为数据的情况,查询结果条数不一样,但是整体是没有问题的。
select /*! IGNORE_UNAVAILABLE */ SUM(errorCount) as num
from ctbpm-js-data-2018-w32,ctbpm-js-data-2018-w27,ctbpm-js-data-2018-w28,
ctbpm-js-data-2018-w29,ctbpm-js-data-2018-w30,ctbpm-js-data-2018-w31
where appCode = '5f05acfc9a084d9f9a07e165a2516c18' and logTime>= '2018-07-07T09:57:15.436Z' and logTime<= '2018-08-07T09:57:15.436Z'
group by terms(field='pageRef',size='15',alias='pageRef'),
terms(field='province',size='15',alias='province'),
terms(field='city',size='15',alias='city'),
terms(field='ip',size='15',alias='ip')
解析后:
{
"from": 0,
"size": 0,
"query": {
"bool": {
"filter": [
{
"bool": {
"must": [
{
"bool": {
"must": [
{
"match_phrase": {
"appCode": {
"query": "5f05acfc9a084d9f9a07e165a2516c18",
"slop": 0,
"boost": 1
}
}
},
{
"range": {
"logTime": {
"from": "2018-07-07T09:57:15.436Z",
"to": null,
"include_lower": true,
"include_upper": true,
"boost": 1
}
}
},
{
"range": {
"logTime": {
"from": null,
"to": "2018-08-07T09:57:15.436Z",
"include_lower": true,
"include_upper": true,
"boost": 1
}
}
}
],
"disable_coord": false,
"adjust_pure_negative": true,
"boost": 1
}
}
],
"disable_coord": false,
"adjust_pure_negative": true,
"boost": 1
}
}
],
"disable_coord": false,
"adjust_pure_negative": true,
"boost": 1
}
},
"_source": {
"includes": [
"SUM"
],
"excludes": []
},
"aggregations": {
"pageRef": {
"terms": {
"field": "pageRef",
"size": 15,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"province": {
"terms": {
"field": "province",
"size": 15,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"city": {
"terms": {
"field": "city",
"size": 15,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"ip": {
"terms": {
"field": "ip",
"size": 15,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_term": "asc"
}
]
},
"aggregations": {
"num": {
"sum": {
"field": "errorCount"
}
}
}
}
}
}
}
}
}
}
}
}
从解析后的内容看出:四个字段的size都是15了,可以使用postman查询看看,结果是正确的。


语法来自: https://github.com/NLPchina/elasticsearch-sql中的terms用法。
补充:如果是nested(嵌套查询),比如:

select /*! IGNORE_UNAVAILABLE */ SUM(errorCount) as num
from ctbpm-js-data-2018-w32,ctbpm-js-data-2018-w27,ctbpm-js-data-2018-w28,ctbpm-js-data-2018-w29,ctbpm-js-data-2018-w30,ctbpm-js-data-2018-w31
where appCode = '5f05acfc9a084d9f9a07e165a2516c18'
and logTime>= '2018-07-08T06:20:13.144Z'
and logTime<= '2018-08-08T06:20:13.144Z'
group by pageRef,province,city,ip,nested(errors.message) limit 10那么需要这么来查:
select /*! IGNORE_UNAVAILABLE */ SUM(errorCount) as num
from ctbpm-js-data-2018-w32,ctbpm-js-data-2018-w27,ctbpm-js-data-2018-w28,ctbpm-js-data-2018-w29,ctbpm-js-data-2018-w30,ctbpm-js-data-2018-w31
where appCode = '5f05acfc9a084d9f9a07e165a2516c18'
and logTime>= '2018-07-08T06:20:13.144Z'
and logTime<= '2018-08-08T06:20:13.144Z'
group by terms(field='pageRef',size='15',alias='pageRef'),
terms(field='province',size='1',alias='province'),
terms(field='city',size='2',alias='city'),
terms(field='ip',size='3',alias='ip'),
terms(field='errors.message',size='4',alias='errors.message',nested="errors")
========================================================
elasticsearch的先聚合和过滤、先过滤再聚合的详解
对于elasticsearch的聚合和过滤,他的结果并不会受到你写的顺序而影响。换句话说就是你无论是在聚合语句的前面写过滤条件,还是在过滤语句后面写过滤条件都不会影响他的结果。他都会先过滤再聚合和关系数据库一样先where后group by。
但是如果你想过滤条件不影响聚合(agg)结果,而只是改变hits结果;可以使用setPostFilter() 这个方法
eg:全部数据
代码:
SearchResponse response = null;
SearchRequestBuilder responsebuilder = client.prepareSearch("company")
.setTypes("employee").setFrom(0).setSize(250);
AggregationBuilder aggregation = AggregationBuilders
.terms("agg")
.field("age") ;
response = responsebuilder
.addAggregation(aggregation)
.setExplain(true).execute().actionGet();
SearchHits hits = response.getHits();
Terms agg = response.getAggregations().get("agg");结果: 仅聚合结果不过滤(注意看hits和agg里的结果)
{
"took":100,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0
},
"hits":{
"total":7,
"max_score":1,
"hits":[
{
"_shard":1,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"5",
"_score":1,
"_source":{
"name":"Fresh",
"age":22
},
"_explanation":Object{...}
},
{
"_shard":1,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"10",
"_score":1,
"_source":{
"name":"Henrry",
"age":30
},
"_explanation":Object{...}
},
{
"_shard":1,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"9",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"jiangsu",
"city":"nanjing",
"area":{
"pos":"10001"
}
}
},
"_explanation":Object{...}
},
{
"_shard":2,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"2",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"jiangsu",
"city":"nanjing"
},
"name":"jack_1",
"age":19,
"join_date":"2016-01-01"
},
"_explanation":Object{...}
},
{
"_shard":2,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"4",
"_score":1,
"_source":{
"name":"willam",
"age":18
},
"_explanation":Object{...}
},
{
"_shard":2,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"6",
"_score":1,
"_source":{
"name":"Avivi",
"age":30
},
"_explanation":Object{...}
},
{
"_shard":4,
"_node":"K7qK1ncMQUuIe0K6VSVMJA",
"_index":"company",
"_type":"employee",
"_id":"3",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"shanxi",
"city":"xian"
},
"name":"marry",
"age":35,
"join_date":"2015-01-01"
},
"_explanation":Object{...}
}
]
},
"aggregations":{
"agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":0,
"buckets":[
{
"key":30,
"doc_count":2
},
{
"key":18,
"doc_count":1
},
{
"key":19,
"doc_count":1
},
{
"key":22,
"doc_count":1
},
{
"key":35,
"doc_count":1
}
]
}
}
}1、setQuery() 写在前面
代码:
SearchResponse response = null;
SearchRequestBuilder responsebuilder = client.prepareSearch("company")
.setTypes("employee").setFrom(0).setSize(250);
AggregationBuilder aggregation = AggregationBuilders
.terms("agg")
.field("age") ;
response = responsebuilder
.setQuery(QueryBuilders.rangeQuery("age").gt(30).lt(40))
.addAggregation(aggregation)
.setExplain(true).execute().actionGet();
SearchHits hits = response.getHits();
Terms agg = response.getAggregations().get("agg");结果:
{
"took":538,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0
},
"hits":{
"total":1,
"max_score":1,
"hits":[
{
"_shard":4,
"_node":"anlkGjjuQ0G6DODpZgiWrQ",
"_index":"company",
"_type":"employee",
"_id":"3",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"shanxi",
"city":"xian"
},
"name":"marry",
"age":35,
"join_date":"2015-01-01"
},
"_explanation":Object{...}
}
]
},
"aggregations":{
"agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":0,
"buckets":[
{
"key":35,
"doc_count":1
}
]
}
}
}
2、setQuery() 写在后面
代码:
SearchResponse response = null;
SearchRequestBuilder responsebuilder = client.prepareSearch("company")
.setTypes("employee").setFrom(0).setSize(250);
AggregationBuilder aggregation = AggregationBuilders
.terms("agg")
.field("age") ;
response = responsebuilder
.addAggregation(aggregation)
.setQuery(QueryBuilders.rangeQuery("age").gt(30).lt(40)
.setExplain(true).execute().actionGet();
SearchHits hits = response.getHits();
Terms agg = response.getAggregations().get("agg");结果:
{
"took":538,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0
},
"hits":{
"total":1,
"max_score":1,
"hits":[
{
"_shard":4,
"_node":"anlkGjjuQ0G6DODpZgiWrQ",
"_index":"company",
"_type":"employee",
"_id":"3",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"shanxi",
"city":"xian"
},
"name":"marry",
"age":35,
"join_date":"2015-01-01"
},
"_explanation":Object{...}
}
]
},
"aggregations":{
"agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":0,
"buckets":[
{
"key":35,
"doc_count":1
}
]
}
}
}
3、setPostFilter() 在聚合.aggAggregation()方法后
代码:
SearchResponse response = null;
SearchRequestBuilder responsebuilder = client.prepareSearch("company")
.setTypes("employee").setFrom(0).setSize(250);
AggregationBuilder aggregation = AggregationBuilders
.terms("agg")
.field("age") ;
response = responsebuilder
.addAggregation(aggregation)
.setPostFilter(QueryBuilders.rangeQuery("age").gt(30).lt(40))
.setExplain(true).execute().actionGet();
SearchHits hits = response.getHits();
Terms agg = response.getAggregations().get("agg");结果:
{
"took":7,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0
},
"hits":{
"total":1,
"max_score":1,
"hits":[
{
"_shard":4,
"_node":"fvp3NBT5R5i6CqN3y2LU4g",
"_index":"company",
"_type":"employee",
"_id":"3",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"shanxi",
"city":"xian"
},
"name":"marry",
"age":35,
"join_date":"2015-01-01"
},
"_explanation":Object{...}
}
]
},
"aggregations":{
"agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":0,
"buckets":[
{
"key":30,
"doc_count":2
},
{
"key":18,
"doc_count":1
},
{
"key":19,
"doc_count":1
},
{
"key":22,
"doc_count":1
},
{
"key":35,
"doc_count":1
}
]
}
}
}
4、setPostFilter() 在聚合.aggAggregation()方法前
代码:
SearchResponse response = null;
SearchRequestBuilder responsebuilder = client.prepareSearch("company")
.setTypes("employee").setFrom(0).setSize(250);
AggregationBuilder aggregation = AggregationBuilders
.terms("agg")
.field("age") ;
response = responsebuilder
.setPostFilter(QueryBuilders.rangeQuery("age").gt(30).lt(40))
.addAggregation(aggregation)
.setExplain(true).execute().actionGet();
SearchHits hits = response.getHits();
Terms agg = response.getAggregations().get("agg");结果:
{
"took":5115,
"timed_out":false,
"_shards":{
"total":5,
"successful":5,
"failed":0
},
"hits":{
"total":1,
"max_score":1,
"hits":[
{
"_shard":4,
"_node":"b8cNIO5cQr2MmsnsuluoNQ",
"_index":"company",
"_type":"employee",
"_id":"3",
"_score":1,
"_source":{
"address":{
"country":"china",
"province":"shanxi",
"city":"xian"
},
"name":"marry",
"age":35,
"join_date":"2015-01-01"
},
"_explanation":Object{...}
}
]
},
"aggregations":{
"agg":{
"doc_count_error_upper_bound":0,
"sum_other_doc_count":0,
"buckets":[
{
"key":30,
"doc_count":2
},
{
"key":18,
"doc_count":1
},
{
"key":19,
"doc_count":1
},
{
"key":22,
"doc_count":1
},
{
"key":35,
"doc_count":1
}
]
}
}
}
总结:
(补充说明:setQuery()会查询后进行打分, 而setPostFilter()查询会不打分,只是判断查询结果是否满足过滤条件, 满足的话返回吗即处理"是与不是"的问题)
可以从运行的结果很好的看出无论是setPostFilter()还是setQuery(),它放在那的顺序并不会影响他的结果。更可以看出setQuery()这个方法的过滤条件不仅会影响它的hits的结果还会影响他的聚合(agg)结果。然而对于setPostFilter()这个方法,它只会影响hits的结果,并不会影响它的聚合(agg)结果。
PS:
springboot中elasticSearch查询 https://blog.csdn.net/Topdandan/article/details/81436141