python使用requests库爬取淘宝食品信息,包含sign参数破解
python使用requests库爬取淘宝食品信息,包含sign参数破解。
1.网站分析
参考资料:JS断点调试 https://blog.csdn.net/qq_39009348/article/details/81563831
打开淘宝页面搜索"美食"
共有一百页数据,一页100条数据
右键——检查 或者 按F12 在 NetWork 中的一大坨里找到自己想要的东西(看response里有没有自己想要的数据,想看主页面里有没有,再到XHR里看看是不是Ajiax传得,最后到JS里翻)

找到了之后就可以分析请求头里有啥了
先看看 request URL 和 request Headers
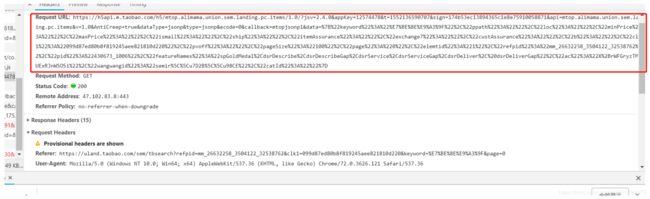
这个URL就是我们的目标了
request URL 中发现有一堆参数,那么看看下面都传了些啥参数
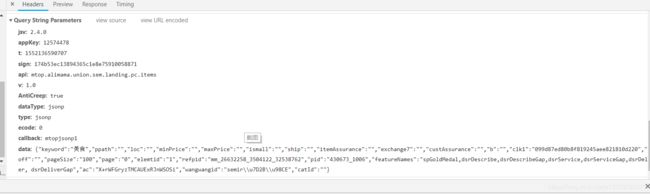
翻翻页发现很多值是固定不变的,一定会变或者可能会变的有下面这些值
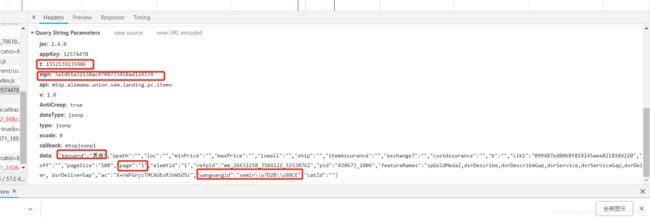
经过观察和一些尝试(这里就不细说了)t 和 sign 的值是每次都会变的,keyword则是自己搜索的字段,page则是页数,最后面那个wangwangid则是你当前登陆的用户名(随cookies变化)
经过我的测试,根据上面的参数构造请求可以获取到数据,但是 t 和 sign 的值每次都会变,不可能我每翻一页都要自己改参数,所以只能去找这两个参数是怎么来的了,嗯 t 明显是时间戳(t = int(time.tiam()*1000)), 主要是 sign 的值
经过一番努力,我找到了这个参数怎么构造的
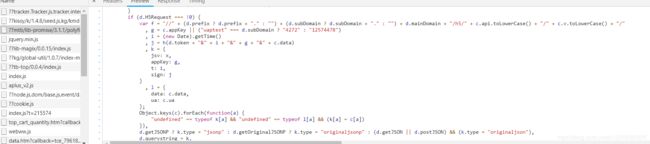
发现 sign 是将几个参数用"&"连接后再有MD5加密所得,然后使用js断点调试看看这几个参数都是什么意思,上面有js断点的文献,不明白的可以参考一下。
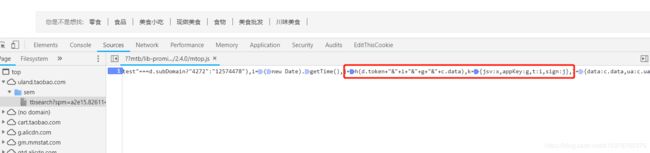
j = h(d.token + “&” + i + “&” + g + “&” + c.data)
sign: j
1. d.token

发现这个 token 与 cookies 里的 token 有点像,去看看,发现

就是这个了,这里要注意 这个 token 的大概每隔一个小时就会改变一次
2. i

这个 i 的值和之前 t 的值一样 ,int(就是 time.time()*1000)
3. g

不难发现 g 就是之前请求里的一个固定值 appKey : 12574478
4. c.data
![]()
就是之前请求的参数里的 data

所有 sign = md5(d.token + “&” + i + “&” + g + “&” + c.data) 这种形式
下面上代码
import requests
from pymongo import MongoClient
from urllib.parse import urlencode
import re
import hashlib
import time
from requests.exceptions import RequestException
conn = MongoClient('127.0.0.1', 27017) # 连接 mongodb
db = conn.taobao # 连接taobao数据库,没有则自动创建
my_set = db.meishi # 连接meishi表,没有则自动创建
# 获取请求需要的信息
def get_request_headers(page, keyword):
page = str(page)
referer = 'https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&clk1=099d87ed80b8f8' \
'19245aee821810d220&keyword=%E7%BE%8E%E9%A3%9F&page=0'
headers = {
'Connection': 'close',
'referer': referer,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'cookie': 'cna=X+rWFGryzTMCAUExRJnWSOSi; enc=nsDkgllsoBPb0wIc0Q8sA4xK0DSWUGILWESmQjTZ0N5v9rvesE96OKtukWmMQNlvKtXJmzc1TT6VuFqddpQepw%3D%3D; hng=US%7Czh-CN%7CUSD%7C840; t=45d44be7431b1beb974ab74f954b16db; tg=0; thw=cn; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; l=bBMEN2egvsEedSQ-BOfZhurza77t1IRb4sPzaNbMiICP9wfp7rr1WZwXnMT9C3GVw1WeR3-QiNZbBeYBq6C..; _fbp=fb.1.1549863216405.2066565933; uc3=vt3=F8dByE0JQHSmXHF%2BSgM%3D&id2=UNDXmQXXFncoVA%3D%3D&nk2=EFtb3MsoNHDb&lg2=U%2BGCWk%2F75gdr5Q%3D%3D; tracknick=semir%5Cu7D2B%5Cu98CE; lgc=semir%5Cu7D2B%5Cu98CE; _cc_=VFC%2FuZ9ajQ%3D%3D; UM_distinctid=168db3b076d3e9-045df96dd398bd-57b153d-144000-168db3b076e230; mt=ci=-1_0; ctoken=6MWCnVa6pQyqEUr_CqYD5DdN; cookie2=5721f26ad532d929eb75be4146fad480; v=0; _tb_token_=874387eb3d5e; _m_h5_tk=3d843a5726d1c5fae79b96e5527fc27d_1552153109599; _m_h5_tk_enc=f5d23cea9652db72aca2d2f2f2005493; uc1=cookie14=UoTZ5iTLQWRGag%3D%3D; isg=BGtrP22cszE6X-82z0jp7ZRA-o9fUH4m1DAO393oR6oBfIveZVAPUgne1vy33Nf6'
}
data = '{"keyword":"%s","ppath":"","loc":"","minPrice":"","maxPrice":"","ismall":"","ship":"","itemAss' \
'urance":"","exchange7":"","custAssurance":"","b":"","clk1":"099d87ed80b8f819245aee821810d220","p' \
'voff":"","pageSize":"100","page":"%s","elemtid":"1","refpid":"mm_26632258_3504122_32538762","pid' \
'":"430673_1006","featureNames":"spGoldMedal,dsrDescribe,dsrDescribeGap,dsrService,dsrServiceGap' \
',dsrDeliver, dsrDeliverGap","ac":"X+rWFGryzTMCAUExRJnWSOSi","wangwangid":"' \
'semir\\\\u7D2B\\\\u98CE","catId":""}' % (keyword, page)
t = int(time.time()*1000)
t = str(t) # 要转化成字符串
token = "3d843a5726d1c5fae79b96e5527fc27d"
appkey = "12574478"
datas = token+'&'+t+'&'+appkey+'&'+data
sign = hashlib.md5() # 创建md5对象
sign.update(datas.encode()) # 使用md5加密要先编码,不然会报错,我这默认编码是utf-8
signs = sign.hexdigest() # 加密
data1 = {
"jsv": "2.4.0",
"appKey": "12574478",
"t": t, # 上面的t
"sign": signs, # 加密之后的值
"api": "mtop.alimama.union.sem.landing.pc.items",
"v": "1.0",
"AntiCreep": "true",
"dataType": "jsonp",
"type": "jsonp",
"ecode": "0",
"callback": "mtopjsonp1",
"data": {
"keyword": keyword, # 关键词别忘了
"ppath": "",
"loc": "",
"minPrice": "",
"maxPrice": "",
"ismall": "",
"ship": "",
"itemAssurance": "",
"exchange7": "",
"custAssurance": "",
"b": "",
"clk1": "099d87ed80b8f819245aee821810d220",
"pvoff": "",
"pageSize": "100",
"page": page, # 页码
"elemtid": "1",
"refpid": "mm_26632258_3504122_32538762",
"pid": "430673_1006",
"featureNames": "spGoldMedal,dsrDescribe,dsrDescribeGap,dsrService,dsrServiceGap,dsrDeliver,2020dsrDeliverGap", # 2020这里是一个空格
"ac": "X+rWFGryzTMCAUExRJnWSOSi",
"wangwangid": "semir\\u7D2B\\u98CE",
"catId": "",
}
}
# 返回请求头和要传的参数
return headers, data1
def get_data(url, headers):
try:
response = requests.get(url, headers=headers)
print(response.url)
if response.status_code == 200:
return response.text
else:
return None
except RequestException as E:
print(E)
return None
def parse_data(data):
# 使用正则表达式解析数据,经测试其他类型商品数据结构是一样的,这个也能用
pattern = re.compile('{"dsrDeliver":"(.*?)".*?dsrDescribe":"(.*?)".*?dsrService":"(.*?)".*?eurl":"(.*?)".*?'
+ 'imgUrl":"(.*?)".*?loc":"(.*?)".*?promoPrice":"(.*?)".*?redkeys":\[(.*?)\].*?title":"(.*?)"'
+ '.*?wangwangId":"(.*?)"}', re.S)
datalist = re.findall(pattern, data)
return datalist
def main():
keyword = "美食" # 设置关键词
for i in range(1, 101): # 循环一百页
time.sleep(5) # 睡5s,降低频率,防止被搞
page = i
headers, data1 = get_request_headers(page, keyword)
data1 = urlencode(data1) # 将要传输的数据编码 ,这里有个坑,有一个空格编码不出来,只能想换成2020再替换回来
data1 = re.sub('\+', '', data1)
data1 = data1.replace('2020', '%20')
data1 = data1.replace('%27', '%22')
base_url = 'https://h5api.m.taobao.com/h5/mtop.alimama.union.sem.landing.pc.items/1.0/?' + data1 #可以用这个完整的url 和页面上的比较,看一不一样,一样就可以了
datas = get_data(base_url, headers)
if datas is None or datas == []:
print(page)
continue
vallist = parse_data(datas)
if vallist == []:
print(page)
continue
print(len(vallist))
for s in vallist:
data = {
'title': s[8],
'img': s[4],
'price': s[6],
'xiangxixinxi': s[3],
'area': s[5],
'fenlei': s[7],
'dianpu': s[9],
'fahuosudu': s[0],
'shangpinmiaosu': s[1],
'fuwutaidu': s[2],
}
print(data)
my_set.insert(data) # 插入数据
if __name__ == '__main__':
main()
最后贴下结果
