捋一捋Unified Language Model Pre-training for Natural Language Understanding and Generation
论文地址:https://arxiv.org/pdf/1905.03197.pdf
1.这是个什么东西?
首先我想尽量用比较通俗的方式和语言去描述一下我理解的这个UNILM模型,如果有哪些不太专业严谨的地方各位看官可以留言给我我再改.
其实看完这篇论文以后有两个地方让我情绪产生了比较激烈的波动:
1.当然第一个就是这个模型的结构(如下,后面详细介绍),很有创意,当然最后的结果也被证实了的确很厉害,不仅在NLU(自然语言理解)上相较于bert有提升,在bert表现的不是那么好的NLG(自然语言生成)方面表现的那也是相当的好,在:CNN/DailyMail abstractive summarization , Gigaword abstractive summarization ,CoQA generative question answering,SQuAD question generation,DSTC7 document-grounded dialog response generation.等五个NLG数据集上都拿到了state of art,并且在GLUE benchmark,SQuAD 2.0和CoQA上都超越了bert,具体的对比情况可以看论文的第三部分,反正就是最终效果很NB就是了.
2.第二点让我比较激动的就是这真不是个普通人能玩儿的起的东西,他的预训练模型一共跑了770000步,在8片Nvidia Telsa V100 32GB 显卡上跑10000步需要7个小时,算下来77 * 7 = 539个小时= 22天半,啊,每一秒都是金钱在燃烧的味道. 而且他微调(Fine-tuning)也推荐使用2到4片Nvidia Telsa V100 32GB, 我觉得这就劝退了大部分想试一试的人(然而尝试了一下,batch_size调到32在1080上也是能跑的,用了三片1080,跑他提供的第一个demo大概三分钟一个epoch), 而且现在也没有中文的预训练模型,我猜测这就是为啥虽然他效果很好,但是热度不比bert的原因吧(虽然bert也是挺贵,不过微调的话1080也是可以用的),毕竟bert提供的预训练模型种类更多,大多数人也能玩儿的起. 希望UNILM也能在后续出一些低配版,让我这种穷人也能尝尝鲜.
说了这么多废话,那他到底是个什么东西呢? 看这篇论文的名字, 翻译过来就是 : 一个可以用来做自然语言理解和自然语言生成的统一预训练模型, 说白了也和bert啊 ,elmo啊之类的一样, 但是人家更优秀的一个地方就是既能用在自然语言理解上, 又能用在自然语言生成上, 不像bert在自然语言生成上不太行(因为他是双向的), 这个UNILM在各个方面都很能打,那他为什么这么秀呢 ? 接下来咱们来一起捋一捋.
2.汝何秀?
首先无可争议的是预训练语言模型在自然语言处理任务上的成果是优秀的,有目共睹的,为啥呢,因为咱们的文章语句天生就是蕴含着语法语义的训练资源,预训练语言模型在海量的语料数据中遨游学习,所以他能够基于足够多的上下文文本表征来预测目标token的语义信息,俗话说 : 熟读诗书三百首,不会写来也会抄么, 我觉得说的在理, 看咱们先人在多少年前就领悟了非监督学习的真谛!
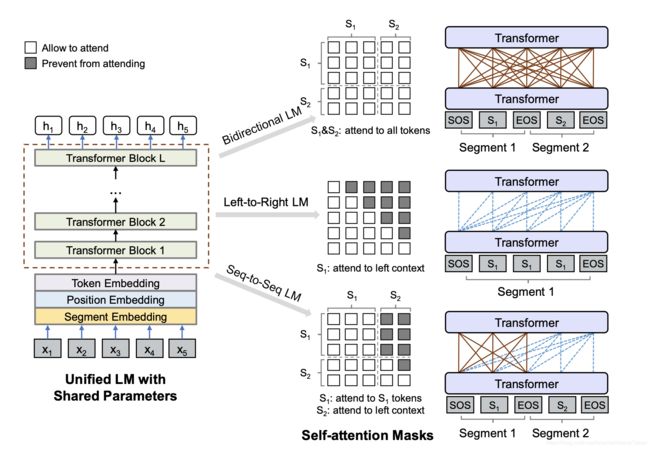
首先,这个UNILM和bert一样,都可以微调(fine-tuned)来适用于各种各样的下游任务,但是不像bert多被用在自然语言理解上,UNILM可以通过配置的方式来使用不同的自注意力的mask机制(看上图),为不同类型的语言模型聚合上下文,从而既可以被用在自然语言理解任务上,又可以被用在自然语言生成任务上.
论文说了,UNILM主要有三个优点:
1、他统一的预训练过程,使用一个transformer语言模型囊括了了不同类型的语言模型的的参数和结构(bi, left-t-right,right-t-left,seq-t-seq),从而不需要分开训练多个语言模型.
2、因为他囊括了多种语言模型参数和结构呀,所以参数共享使得他学习到的文本表征更加通用化了,他会针对不同的语言建模目标进行联合优化,上下文信息会以不同的方式去使用,所以可以减少自然语言任务训练中的过拟合.
3、因为UNILM有seq-to-seq的用法,所以他天生适用自然语言生成任务,比如摘要提取,问题生成.
说了那么多优点,咱们接下来一起看一下这个“统一语言模型”是怎么做预训练的吧!
还是看这个图,
2.1.首先看输入
首先我们看到了他的输入是 [x1,x2,x3....xn],整个输入字符串也可以有两种格式,一个句子-单项语言模型用(unidirectional LMs) 或者一对句子,给双向(bidirectional LM)或者seq-t-seq用,每个x就是一个英文单词儿或者说是一个汉字,总之就是基本语言单位,然后和bert一样一样的,每个基本语言单位的向量表示都包括了三个部分,分别是字符表示向量,位置表示向量,句子序号表示向量.
然后在输入开头加入[SOS] token(start-of-sequence), 表示句子输入开始啦,然后在每一句末尾加[EOS] token(end-of-sequence),这个标签不仅在自然语言理解任务中表示句子边界,还在自然语言生成任务中标示着到这个点儿了就该结束解码过程了,让模型学习该怎么停止,还有就是他的英文处理的时候参照bert,(比如会把playing切成两个词play和##ing) , 中文? UNILM好像还没中文的预训练模型, 现在好像就出了一个预训练模型, 用的bert-large的参数初始化的.
2.2.然后看一下主要模型结构(敲黑板,这里要考)
他的主要模型结构是一个多层的transformer,看上图,把输入的字符串处理妥当,转成向量表示以后交给第一个transformer,然后第一个transformer一顿料理以后给下一层transformer,可以表示为以下这个公式:
H(l) = Transformer-l(H(l−1)), l ∈ [1, L] 当前层的输出等于上一层的输出输入进当前层的transformer后产生的结果
在每一层transformer中,我们用多个自注意力头(self-attention heads)来聚合上一层transformer的输出,其中每一个自注意力头的操作步骤可以表示为以下这几个公式(别慌,这公式不难懂)
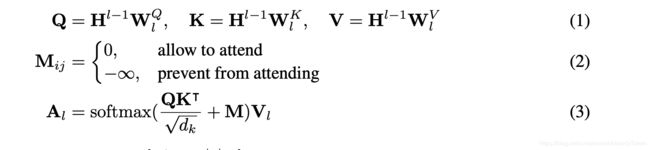
了解bert的同学是不是看着感觉很熟悉? 根本不用讲嘛一眼就看懂了. 对嘛 , 本来unilm用的也是transformer, 能有多大的不同呢是吧, 如果不太了解bert和transformer的同学可以先去熟悉以下 , 学习路线推荐 attention -> transformer -> bert .传送门:
Self-Attention与Transformer : https://zhuanlan.zhihu.com/p/47282410
bert : https://zhuanlan.zhihu.com/p/46652512
其实这些一搜一大堆的啦,毕竟热度还是比较高的,有时间的话可以直接看那两篇论文
Attention Is All You Need https://arxiv.org/pdf/1706.03762.pdf
BERT: https://arxiv.org/pdf/1810.04805.pdf
(这两篇我觉得网上解读的比较好的已经比较多了,就不捋了)
好了,言归正传,那到这里我就不多解释QKV以及缩放因子dk了, 我们可以看到unilm在这里创新的一点就是第二个公式,那这是个什么东西呢? 大家还要看那个结构图来理解
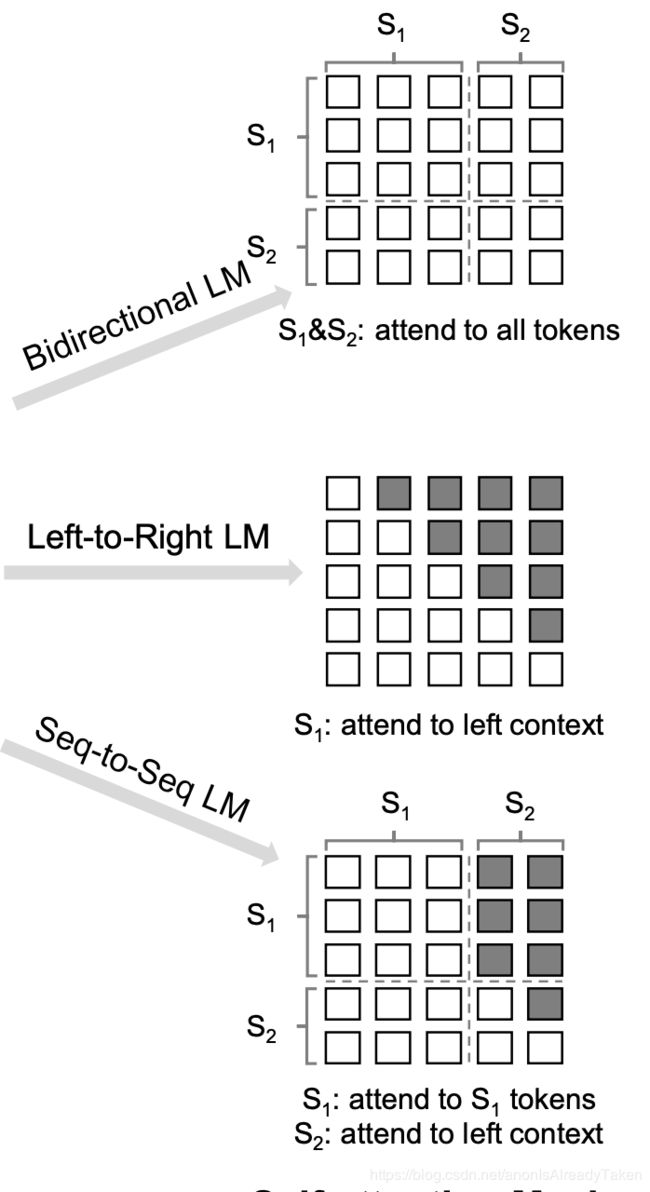
是不是对照着这个图一看,有种一下子就明白了的感觉? 是的, 这一个公式也很好理解, 这个M 就代表Mask Matrix , 意思很直白,就是对于当前的token来讲, 哪些token他可见, 哪些token他不可见 , 可见的部分就在Q乘以K的转置除根号dk以后得到的矩阵的相应位置上加0 ,也就是不做任何改变, 不可见的部分就是在相应位置加上个负无穷大 , 就表示对当前token不可见.
就拿第一个Bidirectional LM来说, 每一个token都可见其完整的上下文(就像地图全开一样)
第二个单方向的 LM, 每个token只能看见其(左/右)单方向的信息(有战争迷雾,走过的地方才能看见)
seq-t-seq LM , 作为source的句子里地图全开了, 作为target的句子里只能看见左面的也就是已经生成的.
2.3.看一看unilm怎么做完形
咱们都知道, 预训练的语言模型是不需要标注的,他会随机的遮住一些基本的语言单位 ,也就是把一些字符替换成[MASK]这个特殊token, 然后让模型通过上下文信息去猜这个盖住的是什么字, 然后和真实的做对比求loss, 然后照着loss降低的方向去优化模型参数.
因为unilm他本质上存在四种不同的语言模型结构嘛.所以他共有四种完形填空的方式,接下来咱们一一道来.
Unidirectional LM : 单向的语言模型, 包括从左到右和从右到左,这里就单说从左到右, 在考虑每个基本字符单位的向量表示的时候,只考虑他本身及本身左边的基本字符单位, 打个比方 “我 是 大 [MASK] 哥 呀” ,这句话, 使用单向语言模型的时候 , 我们在预测被遮住的mask的时候所能使用的上下文信息只有 “我 是 大 [MASK]” , 就是只有MASK和他左边的所有基本字符单位, 那他是怎么实现的呢? 大家往上看 , 对, 就是上一个图片 , left-to-right LM对应的那个矩阵 , 看见没, 对角线往左下包括对角线都是白色的 , 就代表了Mask Matrix这些位置是0 ,就是不做改变(回想一下上上图的公式2) , 灰黑色的块儿就代表这里是无穷小,就是在Q乘以K的转置并缩放以后的结果响应位置上加上无穷小,就是变不可见了呗.
Bidirectional LM : 双向的语言模型可以在每一次预测mask的时候都获得完整的上下文信息,两个方向的所有的基本字符单位信息都会编码进他的上下文信息中 , 相比于单向的语言模型 , 他这样做肯定可以会有更好的上下文表示(但是这样就搞不好生成任务了,为啥 ? 你还没生成后面的内容呢,就要用后面的内容表征这个基本字符单位的向量了,能掐还是会算啊?) . 还用上个栗子 “我 是 大 [MASK] 哥 呀” 这句话 (当然两句话也行,反正就是全局视野,都互相可见), 整个的一句话都会参与进mask的预测过程. 还是抬头看图片 , 全是白框框,就代表这时候整个mask矩阵都是0 , 所有的表征都相互可见 .
Sequence-to-Sequence LM : 我们都知道 , seq-to-seq的场景中语料是一对儿, 有个source有个target , 在source里的基本字符单位对互相都可见 , 但是在target里面的基本字符单位只能见到自己和自己左边的基本字符单位 , 举个栗子来说的话 ,比如 “[SOS]你 瞅 啥 [EOS] 瞅 你 咋 滴 [EOS]” 这句话如果喂进去的话(source是你瞅啥,target是瞅你咋滴) , 那source的[SOS], 你 , 瞅 , 啥 ,[EOS]他们五个互相可见 , target 里的 “咋” 就只能看见source里的所有字符和自己以及自己左边的俩字儿 : 瞅 , 你 .咋 . 还是抬头看么 , 图也画的很清楚了 , s1是source , s2是target.
2.4.更具体一些?
那我们现在知道了他一共有三种不同的完形填空手段, 那这是一个模型呀 , 怎么用这三种完形填空的手段呢? 在论文中作者是这样描述的 , 在一个训练batch中 , 三分之一的时间用Bidirectional LM ,三分之一的时间用Sequence-to-Sequence LM, 然后从左到右的单向和从右到左的单向各占六分之一的时间 . 同时为了和bert[large]进行公平比较, 他的模型结构和bert[large]相同, 激活参数用的gelu, 具体来说就是24层的transformer , 每层1024个节点, 使用了16个自注意力头 ,大概一共340M左右,他的参数初始化自bert[large],然后使用的English Wikipedia2 和 BookCorpus 进行的模型的预训练 , 词汇量大小是28996个 , 语料最大长度是512 , 他随机选取mask的几率是15%,在这些选出的mask中, 有80%的是直接替换成[MASK]字符, 有10%的是替换成随机基本字符单位,剩下的10%不动他, 让他保持原样. 此外,还有一个手段, 就是在替换mask时, 80%的几率是只替换一个基本字符单位 , 还有20%的几率是替换一个二元组或者三元组.
更细致的训练参数就不说了,大家感兴趣可以看论文的2.4最后一段 , 包括一些更详细的预训练参数和他的训练配置.
2.5. 如何微调?
这里就大致插一嘴 , 具体有想法的还是得去看代码 , 粗略的跑了一下 ,按指示来可以跑
自然语言理解任务比如文本分类,就和bert用法一样, 把UNILM当成一个双向的transformer编码器, 后面直接跟个softmax就行.
自然语言生成任务比如seq-to-seq, 就和他预训练的时候差不多 , 都是随机mask然后预测么 , [EOS]也是可以mask的,让模型学学啥时候该结束生成.
3.关于环境的心路历程
首先声明一下,我是新手,所以搞这个环境搞了一整天,如果是老鸟的话我觉得这里可以跳过去.
系统是16.04.1-Ubuntu , 显卡是GTX 1080 ,
本来系统上装的nvidia驱动是387的,cuda是9.0
但是这个UNILM需要的cuda10才行 , cuda比较低的话会在开始跑epoch的时候core dumped , 而且pytorch不能高过1.2.0
他推荐的是使用docker-gpu来搞, 这个也好整, 可自行谷歌必应百度
那就听人家的话用docker-gpu吧 , 但是虽然docker-gpu里可以用不同版本的cuda和cudnn , 但是显卡驱动得装在容器外吧,
所以我就遇到了第一个难题 , 387的显卡驱动显然带动不了cuda10 ,然而unilm要求的环境就是cuda10.0-cudnn7.5,
没办法,卸载nvidia驱动吧, 但是服务器又不是我一人儿用是不是,还得保证机器上装的cuda是9吧,
据我一通操作之后,频繁碰壁之后, 总结出以下升级显卡驱动,系统cuda版本照旧的操作步骤(可以在docker里用高版本的cuda)
1.执行 sudo apt-get purge nvidia* 卸载nvidia驱动
2. 如果你之前是有一套旧的nvidia驱动和cuda的话这时候他会提示你还有一堆东西没用了,要你执行一个好像autoremove的命令,这个你得听话执行,要不然之后会有问题,我就是没执行这个命令浪费了好长时间
3.到你的cuda目录里的bin目录下找卸载脚本, 把cuda给干掉
4.好了,这个时候咱们的环境应该就是干净, 接下来有两种方式可以安装显卡驱动, 分别是apt-get和ubuntu-drivers , 后者会自动安装最新的,有人说是用前者会有问题,但是因为我不想装最新的,就使用了apt-get,最后看来也没出啥问题,两种安装方法分别是:
| sudo apt-get upgrade sudo apt-get update sudo apt-get install nvidia-418(看你想要什么版本了) |
ubuntu-drivers devices |
5.然后现在我们就有了显卡驱动了,该安装cuda了,cuda的安装可以去nvidia官网上下文件,也可以直接用apt-get,两种方法我都试过了,然而去官网上下载run文件安装让我始终没有办法在nvidia-418下用上cuda9,这种方式自行谷歌必应百度吧,不多说了.然而apt-get install cuda-9-0 当时尝试的也不行, 正当我要崩溃回退nvidia版本的时候发现了个帖子:
https://devtalk.nvidia.com/default/topic/1042638/linux/is-nvidia-driver-410-57-incompatible-with-cuda-9-0/
啊,这个时候不能装cuda,要装cuda-toolkit
简直就是提壶灌顶 , 潇洒的敲下 apt-get install cuda-toolkit-9-0 ,
完美收官
6.安装cudnn也就不用多说了吧,网上一堆堆教程,不用在csdn上花币下载,直接去nvidia官网注册个账号下载就行,不算慢
7.然后你就可以用他的github上的教程了, 传送门: https://github.com/microsoft/unilm
8.然而当你开始快乐的跑demo的时候是不是发现他竟然还要下载东西? 而且很慢 ! 这个时候你可以直接去下载下来bert-larger模型,放在本地,然后在这里把路径改成你的本地路径,就OK了,当然tokenization.py里也有这么个类似的vocab,不过这个小,整不整无所谓.
4.如何微调和使用?
这个,就不放在这里说了吧, 如果有需要的话再加一篇代码分析, 不过没有中文的预训练模型 ,unilm感觉还不太具备很好的适用性 , 暂时先不去撸他的代码了就