Spark
一、运行模式
spark是基于内存计算的计算框架,性能很强悍,但是它支持单机模式,同时也支持集群模式,它的运行模式有好多种,为了不混淆方便区分,这里进行一些总结。网上总结了,多数为三种,四种,其实真实要细分,spark有六种运行模式,这里给出区分。
1. local模式【单机】
Local模式又称为本地模式,运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别。
运行实例
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local lib/spark-examples-1.0.0-hadoop2.2.0.jar
# 注:看到 --master local 就可以确定是单机的local模式了!
这个SparkSubmit进程又当爹、又当妈,既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。
2. 本地伪集群运行模式(单机模拟集群)
这种运行模式,和Local[N]很像,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程只能在一个进程下委屈求全的共享资源。通常也是用来验证开发出来的应用程序逻辑上有没有问题,或者想使用Spark的计算框架而没有太多资源。
用法是:提交应用程序时使用local-cluster[x,y,z]参数:x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数。
# spark-submit --master local-cluster[2, 3, 1024]
# 上面这条命令代表会使用2个executor进程,每个进程分配3个core和1G的内存,来运行应用程序。
SparkSubmit依然充当全能角色,又是Client进程,又是driver程序,还有点资源管理的作用。生成的两个CoarseGrainedExecutorBackend
运行该模式依然非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。而不用启动Spark的Master、Worker守护进程( 只有集群的standalone方式时,才需要这两个角色 ),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别。
3. standalone模式【集群】
和单机运行的模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。不用启动Hadoop服务,除非你用到了HDFS的内容。
运行实例
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.123.101:7077 lib/spark-examples-1.0.0-hadoop2.2.0.jar
# 注:看到 --master spark://IP:7077 就可以确定是standalone模式了!
Master进程做为cluster manager,用来对应用程序申请的资源进行管理;SparkSubmit 做为Client端和运行driver程序;CoarseGrainedExecutorBackend 用来并发执行应用程序;
Standalone模式是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
- 运行流程如下:
-
1.SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory);
2.Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;
3.StandaloneExecutorBackend向SparkContext注册;
4.SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
5.StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
6.所有Task完成后,SparkContext向Master注销,释放资源。
4. on yarn client模式【集群】
现在越来越多的场景,都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用YARN来做为Spark的Cluster Manager,来为Spark的应用程序分配资源。
运行实例
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client lib/spark-examples-1.0.0-hadoop2.2.0.jar
# 注:这里执行方式是--master yarn-client
在执行Spark应用程序前,要启动Hadoop的各种服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Worker守护进程。也就是不需要在spark的sbin目录下执行start-all.sh了
- 运行流程如下:
-
(1).Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
(2).ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
(3).Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
(4).一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
(5).Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
(6).应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己
5. on yarn cluster(on-yarn-standalone)模式【集群】
运行实例
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples-1.0.0-hadoop2.2.0.jar
# 注:这里的执行方式是 --master yarn-cluster
- 运行模式:
-
(1). Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
(2). ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
(3). ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
(4). 一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
(5). ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
(6). 应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
6. mesos模式【集群】
上面4、5两种,是基于hadoop的yarn来进行资源管理的,这里是采用mesos来进行资源管理,Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核。Mesos最初是由加州大学伯克利分校的AMPLab开发的,后在Twitter得到广泛使用。Apache Mesos是一个通用的集群管理器,起源于 Google 的数据中心资源管理系统Borg。
Twitter从Google的Borg系统中得到启发,然后就开发一个类似的资源管理系统来帮助他们摆脱可怕的“失败之鲸”。后来他们注意到加州大学伯克利分校AMPLab正在开发的名为Mesos的项目,这个项目的负责人是Ben Hindman,Ben是加州大学伯克利分校的博士研究生。后来Ben Hindman加入了Twitter,负责开发和部署Mesos。现在Mesos管理着Twitter超过30,0000台服务器上的应用部署,“失败之鲸”已成往事。其他公司纷至沓来,也部署了Mesos,比如Airbnb(空中食宿网)、eBay(电子港湾)和Netflix。
这块接触不多,一般不太采用!
附件
Spark Client 和 Spark Cluster的区别
- 理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
-
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
二、伪分布式
搭建部署了hadoop环境后,使用MapReduce来进行计算,速度非常慢,因为MapReduce只是分布式批量计算,用于跑批的场景,并不追求速率,因为它需要频繁读写HDFS,并不能实时反馈结果,这种跑批的场景用的还是比较少的。一般客户最想看到的是输入后立马有结果反馈。那此时我们就需要在Hadoop伪分布式集群上部署Spark环境了!因为Spark是内存计算,它把计算的中间结果存到了内存中,不用频繁读取HDFS,做了极大的优化,当然Spark也是今后的潮流,慢慢将取代Hadoop的很多组件,Spark还有一个优势就是,它是天然与Hadoop完美结合的!
操作步骤
1. 下载Scala和Spark
SCALA2.10.4下载地址
spark1.6.1下载地址
2. 解压并配置环境变量
下载解压scala,添加配置环境变量:
export SCALA_HOME=/opt/scala-2.10.4
export PATH=$JAVA_HOME/bin$HADOOP_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin:$PATH
下载解压spark,添加配置环境变量:
export SPARK_HOME=/opt/spark-1.6.1
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HIVE_HOME/bin:$PATH
3. 修改spark-env.sh
进入Spark的配置文件路径,
# cd $SPARK_HOME/conf
在spark-env.sh文件中添加如下配置:
export JAVA_HOME=/opt/jdk1.7.0_79
export SCALA_HOME=/opt/scala-2.10.4
export HADOOP_CONF_DIR=/opt/hadoop-2.6.0/etc/hadoop
4. 启动spark:
# cd /opt/spark-1.6.1
# ./sbin/start-all.sh
5. 验证
启动完毕,命令行输入jps,如果有master,worker那么就是启动成功
浏览器访问:http://192.168.208.110:8080
# ./bin/spark-shell
浏览器访问:http://192.168.208.110:4040
访问spark-shell页面
# ./bin/spark-sql
通过spark-sql连接hive,访问hive中的数据
# ./sbin/start-thriftserver.sh
# ./bin/beeline
重要,启动后,可以直接使用hive的程序,即HQL执行时默认用spark来进行内存计算
三、分布式
当我们安装好Hadoop分布式集群后,默认底层计算是采用MapReduce,速度比较慢,适用于跑批场景,而Spark可以和hadoop完美的融合,Spark提供了更强劲的计算能力,它基于内存计算,速度快,效率高。虽然Spark也支持单机安装,但是这样就不涉及分布式计算,以及分布式存储,如果我们要用Spark集群,那么就需要分布式的hadoop环境,调用hadoop的分布式文件系统,本篇博文来学习分布式Spark的安装部署!
操作步骤
1. Scala2.11.6配置
1.1 下载Scala2.11.6
Scala2.11.6下载地址,下载scala2.11.6压缩包,上传到主节点的opt目录下
1.2 解压缩并更换目录
# cd /opt/
# tar -xzvf scala-2.11.6.tgz
# mv scala-2.11.6 scala2.11.6
1.3 配置环境变量
# vim /etc/profile
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hive2.1.1
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=.:$HIVE_HOME/lib:$CLASSPATH
export PATH=$PATH:$HIVE_HOME/bin
export SQOOP_HOME=/opt/sqoop1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
export ZK_HOME=/opt/zookeeper3.4.10
export PATH=$PATH:$ZK_HOME/bin
export HBASE_HOME=/opt/hbase1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export SCALA_HOME=/opt/scala2.11.6
export PATH=$PATH:$SCALA_HOME/bin
#加上最后两行,关于scala的环境变量配置
# source /etc/profile #使环境变量配置生效
1.4 验证scala配置
# scala -version
![]()
2. Spark1.6.1配置
2.1 下载Spark1.6.1
spark1.6.1下载地址,下载spark1.6.1压缩包,上传到主节点的opt目录下
2.2 解压缩并更换目录
# cd /opt
# tar -xzvf spark-1.6.1-bin-hadoop2.6.tgz
# mv spark-1.6.1-bin-hadoop2.6 spark1.6.1
2.3 配置环境变量
# vim /etc/profile
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hive2.1.1
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=.:$HIVE_HOME/lib:$CLASSPATH
export PATH=$PATH:$HIVE_HOME/bin
export SQOOP_HOME=/opt/sqoop1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
export ZK_HOME=/opt/zookeeper3.4.10
export PATH=$PATH:$ZK_HOME/bin
export HBASE_HOME=/opt/hbase1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export SCALA_HOME=/opt/scala2.11.6
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/opt/spark1.6.1
export PATH=$PATH:$SPARK_HOME/bin
#加上最后两行,关于spark的环境变量配置
#切记,不要把SPARK_HOME/sbin也配置到PATH中,因为sbin下的命令和hadoop中的sbin下的命令很多相似的,避免冲突,所以执行spark的sbin中的命令,要切换到该目录下再执行
# source /etc/profile #使环境变量配置生效
3. 修改Spark-env.sh配置文件
# cd /opt/spark1.6.1/conf/
# cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
export SCALA_HOME=/opt/scala2.11.6
export JAVA_HOME=/opt/jdk1.8
export HADOOP_HOME=/opt/hadoop2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark1.6.1
export SPARK_MASTER_IP=hadoop0
export SPARK_EXECUTOR_MEMORY=4G #在末尾添加上述配置
4. 修改slaves配置文件
# cd /opt/spark1.6.1/conf/
# cp slaves.template slaves
# vim slaves
hadoop1
hadoop2 #删除localhost,添加从节点的两个主机名
5. 将主节点的scala2.11.6,spark1.6.1搬到两个从节点上
# cd /opt
# scp -r scala2.11.6 root@hadoop1:/opt/
# scp -r scala2.11.6 root@hadoop2:/opt/
# scp -r spark1.6.1 root@hadoop1:/opt/
# scp -r spark1.6.1 root@hadoop2:/opt/
并且修改从节点的环境变量!而且使环境变量生效!
6. 启动并且验证spark
注:在运行spark之前,必须确保hadoop在运行中,因为spark集群是依托于hadoop的。
# cd /opt/spark1.6.1/sbin
# ./start-all.sh
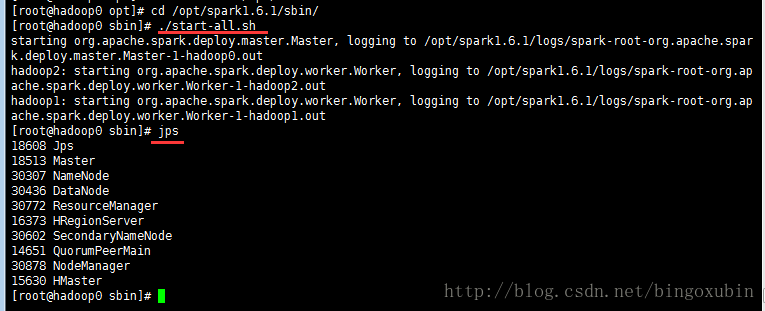
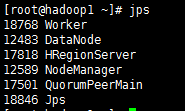

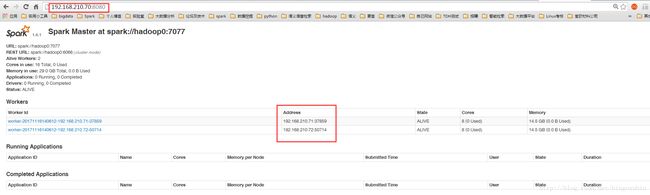
浏览器访问http://192.168.210.70:8080
四、注意
安装部署完完全分布式的spark后,发现yarn-cluster模式可以运行不报错,但是yarn-client报错,无法进行计算PI的值,导致spark并不能使用,报错信息如下所示,只需要修改yarn的配置即可!
操作方案
# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client lib/spark-examples-1.6.1-hadoop2.6.0.jar
1. 报错信息:
[root@hadoop0 spark1.6.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client lib/spark-examples-1.6.1-hadoop2.6.0.jar
17/11/16 16:04:59 INFO spark.SparkContext: Running Spark version 1.6.1
17/11/16 16:05:00 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/16 16:05:00 INFO spark.SecurityManager: Changing view acls to: root
17/11/16 16:05:00 INFO spark.SecurityManager: Changing modify acls to: root
17/11/16 16:05:00 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/11/16 16:05:00 INFO util.Utils: Successfully started service 'sparkDriver' on port 56204.
17/11/16 16:05:00 INFO slf4j.Slf4jLogger: Slf4jLogger started
17/11/16 16:05:01 INFO Remoting: Starting remoting
17/11/16 16:05:01 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:56916]
17/11/16 16:05:01 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 56916.
17/11/16 16:05:01 INFO spark.SparkEnv: Registering MapOutputTracker
17/11/16 16:05:01 INFO spark.SparkEnv: Registering BlockManagerMaster
17/11/16 16:05:01 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-9e904d0f-0d09-4c9a-b523-86dc52613223
17/11/16 16:05:01 INFO storage.MemoryStore: MemoryStore started with capacity 511.1 MB
17/11/16 16:05:01 INFO spark.SparkEnv: Registering OutputCommitCoordinator
17/11/16 16:05:01 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/11/16 16:05:01 INFO server.AbstractConnector: Started [email protected]:4040
17/11/16 16:05:01 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
17/11/16 16:05:01 INFO ui.SparkUI: Started SparkUI at http://192.168.210.70:4040
17/11/16 16:05:01 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-a3aae429-abe4-4bcb-b73e-8fe359aa92d9/httpd-742c21cf-89df-4af2-8b81-431523fe7bfd
17/11/16 16:05:01 INFO spark.HttpServer: Starting HTTP Server
17/11/16 16:05:01 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/11/16 16:05:01 INFO server.AbstractConnector: Started [email protected]:37440
17/11/16 16:05:01 INFO util.Utils: Successfully started service 'HTTP file server' on port 37440.
17/11/16 16:05:01 INFO spark.SparkContext: Added JAR file:/opt/spark1.6.1/lib/spark-examples-1.6.1-hadoop2.6.0.jar at http://192.168.210.70:37440/jars/spark-examples-1.6.1-hadoop2.6.0.jar with timestamp 1510819501618
17/11/16 16:05:01 INFO client.RMProxy: Connecting to ResourceManager at hadoop0/192.168.210.70:8032
17/11/16 16:05:01 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
17/11/16 16:05:01 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (12288 MB per container)
17/11/16 16:05:01 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
17/11/16 16:05:01 INFO yarn.Client: Setting up container launch context for our AM
17/11/16 16:05:01 INFO yarn.Client: Setting up the launch environment for our AM container
17/11/16 16:05:01 INFO yarn.Client: Preparing resources for our AM container
17/11/16 16:05:02 INFO yarn.Client: Uploading resource file:/opt/spark1.6.1/lib/spark-assembly-1.6.1-hadoop2.6.0.jar -> hdfs://hadoop0:9000/user/root/.sparkStaging/application_1510653707211_0005/spark-assembly-1.6.1-hadoop2.6.0.jar
17/11/16 16:05:04 INFO yarn.Client: Uploading resource file:/tmp/spark-a3aae429-abe4-4bcb-b73e-8fe359aa92d9/__spark_conf__7623958375810260855.zip -> hdfs://hadoop0:9000/user/root/.sparkStaging/application_1510653707211_0005/__spark_conf__7623958375810260855.zip
17/11/16 16:05:04 INFO spark.SecurityManager: Changing view acls to: root
17/11/16 16:05:04 INFO spark.SecurityManager: Changing modify acls to: root
17/11/16 16:05:04 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/11/16 16:05:04 INFO yarn.Client: Submitting application 5 to ResourceManager
17/11/16 16:05:04 INFO impl.YarnClientImpl: Submitted application application_1510653707211_0005
17/11/16 16:05:06 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:06 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1510819504598
final status: UNDEFINED
tracking URL: http://hadoop0:8088/proxy/application_1510653707211_0005/
user: root
17/11/16 16:05:07 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:08 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:09 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:10 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:11 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:12 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:13 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:14 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:15 ERROR server.TransportRequestHandler: Error sending result RpcResponse{requestId=89567902
java.nio.channels.ClosedChannelException
17/11/16 16:05:15 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:16 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:17 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:18 INFO yarn.Client: Application report for application_1510653707211_0005 (state: ACCEPTED)
17/11/16 16:05:18 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as
17/11/16 16:05:18 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.07211_0005
17/11/16 16:05:18 INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFi
17/11/16 16:05:19 INFO yarn.Client: Application report for application_1510653707211_0005 (state: RUNNING)
17/11/16 16:05:19 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.210.71
ApplicationMaster RPC port: 0
queue: default
start time: 1510819504598
final status: UNDEFINED
tracking URL: http://hadoop0:8088/proxy/application_1510653707211_0005/
user: root
17/11/16 16:05:19 INFO cluster.YarnClientSchedulerBackend: Application application_1510653707211_0005 has s
17/11/16 16:05:19 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockT
17/11/16 16:05:19 INFO netty.NettyBlockTransferService: Server created on 60932
17/11/16 16:05:19 INFO storage.BlockManagerMaster: Trying to register BlockManager
17/11/16 16:05:19 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.210.70:60932 w
17/11/16 16:05:19 INFO storage.BlockManagerMaster: Registered BlockManager
17/11/16 16:05:22 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (h
17/11/16 16:05:22 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop1:35613 with 2.7
17/11/16 16:05:22 ERROR cluster.YarnClientSchedulerBackend: Yarn application has already exited with state
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,nul
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,nul
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
17/11/16 16:05:22 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
17/11/16 16:05:22 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (h
17/11/16 16:05:22 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.210.70:4040
17/11/16 16:05:22 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
17/11/16 16:05:22 INFO cluster.YarnClientSchedulerBackend: Asking each executor to shut down
17/11/16 16:05:22 INFO cluster.YarnClientSchedulerBackend: Stopped
17/11/16 16:05:22 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/11/16 16:05:22 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop2:51640 with 2.7
17/11/16 16:05:22 INFO storage.MemoryStore: MemoryStore cleared
17/11/16 16:05:22 INFO storage.BlockManager: BlockManager stopped
17/11/16 16:05:22 ERROR scheduler.LiveListenerBus: SparkListenerBus has already stopped! Dropping event Spa
17/11/16 16:05:22 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
17/11/16 16:05:22 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoord
17/11/16 16:05:22 INFO spark.SparkContext: Successfully stopped SparkContext
17/11/16 16:05:22 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
17/11/16 16:05:22 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceedin
17/11/16 16:05:22 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginni
17/11/16 16:05:22 ERROR spark.SparkContext: Error initializing SparkContext.
java.lang.NullPointerException
at org.apache.spark.SparkContext.(SparkContext.scala:584)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:29)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.sc
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
17/11/16 16:05:22 INFO spark.SparkContext: SparkContext already stopped.
Exception in thread "main" java.lang.NullPointerException
at org.apache.spark.SparkContext.(SparkContext.scala:584)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:29)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.sc
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
17/11/16 16:05:22 INFO util.ShutdownHookManager: Shutdown hook called
17/11/16 16:05:22 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-a3aae429-abe4-4bcb-b73e-8fe3
17/11/16 16:05:22 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
17/11/16 16:05:22 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-a3aae429-abe4-4bcb-b73e-8fe
2. 修改yarn-site.xml配置添加最后两个配置:
# vim /opt/hadoop2.6.0/etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
hadoop0
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
8182
每个节点可用内存,单位MB,默认8182MB
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
# 添加最后两个false的属性即可!
3. 运行成功后的展示:
[root@hadoop0 spark1.6.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client lib/spark-examples-1.6.1-hadoop2.6.0.jar
17/11/20 11:23:30 INFO spark.SparkContext: Running Spark version 1.6.1
17/11/20 11:23:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/20 11:23:30 INFO spark.SecurityManager: Changing view acls to: root
17/11/20 11:23:30 INFO spark.SecurityManager: Changing modify acls to: root
17/11/20 11:23:30 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/11/20 11:23:30 INFO util.Utils: Successfully started service 'sparkDriver' on port 50890.
17/11/20 11:23:31 INFO slf4j.Slf4jLogger: Slf4jLogger started
17/11/20 11:23:31 INFO Remoting: Starting remoting
17/11/20 11:23:31 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:43819]
17/11/20 11:23:31 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 43819.
17/11/20 11:23:31 INFO spark.SparkEnv: Registering MapOutputTracker
17/11/20 11:23:31 INFO spark.SparkEnv: Registering BlockManagerMaster
17/11/20 11:23:31 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-c0631ca3-48c6-45ed-b1bd-c785e7ed4e52
17/11/20 11:23:31 INFO storage.MemoryStore: MemoryStore started with capacity 511.1 MB
17/11/20 11:23:31 INFO spark.SparkEnv: Registering OutputCommitCoordinator
17/11/20 11:23:31 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/11/20 11:23:31 INFO server.AbstractConnector: Started [email protected]:4040
17/11/20 11:23:31 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
17/11/20 11:23:31 INFO ui.SparkUI: Started SparkUI at http://192.168.210.70:4040
17/11/20 11:23:31 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-603bd57a-5f73-41dc-84d0-e732cbd37788/httpd-8b6ce293-389a-4564-bedb-8560a3a924d5
17/11/20 11:23:31 INFO spark.HttpServer: Starting HTTP Server
17/11/20 11:23:31 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/11/20 11:23:31 INFO server.AbstractConnector: Started [email protected]:44183
17/11/20 11:23:31 INFO util.Utils: Successfully started service 'HTTP file server' on port 44183.
17/11/20 11:23:31 INFO spark.SparkContext: Added JAR file:/opt/spark1.6.1/lib/spark-examples-1.6.1-hadoop2.6.0.jar at http://192.168.210.70:44183/jars/spark-examples-1.6.1-hadoop2.6.0.jar with timestamp 1511148211815
17/11/20 11:23:31 INFO client.RMProxy: Connecting to ResourceManager at hadoop0/192.168.210.70:8032
17/11/20 11:23:32 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
17/11/20 11:23:32 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
17/11/20 11:23:32 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
17/11/20 11:23:32 INFO yarn.Client: Setting up container launch context for our AM
17/11/20 11:23:32 INFO yarn.Client: Setting up the launch environment for our AM container
17/11/20 11:23:32 INFO yarn.Client: Preparing resources for our AM container
17/11/20 11:23:32 INFO yarn.Client: Uploading resource file:/opt/spark1.6.1/lib/spark-assembly-1.6.1-hadoop2.6.0.jar -> hdfs://hadoop0:9000/user/root/.sparkStaging/application_1511146953298_0003/spark-assembly-1.6.1-hadoop2.6.0.jar
17/11/20 11:23:33 INFO yarn.Client: Uploading resource file:/tmp/spark-603bd57a-5f73-41dc-84d0-e732cbd37788/__spark_conf__5627219911217194032.zip -> hdfs://hadoop0:9000/user/root/.sparkStaging/application_1511146953298_0003/__spark_conf__5627219911217194032.zip
17/11/20 11:23:33 INFO spark.SecurityManager: Changing view acls to: root
17/11/20 11:23:33 INFO spark.SecurityManager: Changing modify acls to: root
17/11/20 11:23:33 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/11/20 11:23:33 INFO yarn.Client: Submitting application 3 to ResourceManager
17/11/20 11:23:33 INFO impl.YarnClientImpl: Submitted application application_1511146953298_0003
17/11/20 11:23:34 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:34 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1511148213962
final status: UNDEFINED
tracking URL: http://hadoop0:8088/proxy/application_1511146953298_0003/
user: root
17/11/20 11:23:36 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:37 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:38 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:39 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:41 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:42 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:43 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:47 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:56 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:57 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:58 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:23:59 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:24:12 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:24:13 INFO yarn.Client: Application report for application_1511146953298_0003 (state: ACCEPTED)
17/11/20 11:24:14 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(null)
17/11/20 11:24:14 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> hadoop0, PROXY_URI_BASES -> http://hadoop0:8088/proxy/application_1511146953298_0003), /proxy/application_1511146953298_0003
17/11/20 11:24:14 INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
17/11/20 11:24:14 INFO yarn.Client: Application report for application_1511146953298_0003 (state: RUNNING)
17/11/20 11:24:14 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.210.70
ApplicationMaster RPC port: 0
queue: default
start time: 1511148213962
final status: UNDEFINED
tracking URL: http://hadoop0:8088/proxy/application_1511146953298_0003/
user: root
17/11/20 11:24:14 INFO cluster.YarnClientSchedulerBackend: Application application_1511146953298_0003 has started running.
17/11/20 11:24:14 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 33528.
17/11/20 11:24:14 INFO netty.NettyBlockTransferService: Server created on 33528
17/11/20 11:24:14 INFO storage.BlockManagerMaster: Trying to register BlockManager
17/11/20 11:24:14 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.210.70:33528 with 511.1 MB RAM, BlockManagerId(driver, 192.168.210.70, 33528)
17/11/20 11:24:14 INFO storage.BlockManagerMaster: Registered BlockManager
17/11/20 11:24:15 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: 30000(ms)
17/11/20 11:24:15 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:36
17/11/20 11:24:15 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 2 output partitions
17/11/20 11:24:15 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:36)
17/11/20 11:24:15 INFO scheduler.DAGScheduler: Parents of final stage: List()
17/11/20 11:24:15 INFO scheduler.DAGScheduler: Missing parents: List()
17/11/20 11:24:15 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents
17/11/20 11:24:15 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1904.0 B, free 1904.0 B)
17/11/20 11:24:15 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1218.0 B, free 3.0 KB)
17/11/20 11:24:15 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.210.70:33528 (size: 1218.0 B, free: 511.1 MB)
17/11/20 11:24:15 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
17/11/20 11:24:15 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32)
17/11/20 11:24:15 INFO cluster.YarnScheduler: Adding task set 0.0 with 2 tasks
17/11/20 11:24:26 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (hadoop1:41774) with ID 2
17/11/20 11:24:26 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, hadoop1, partition 0,PROCESS_LOCAL, 2157 bytes)
17/11/20 11:24:26 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop1:40640 with 1247.3 MB RAM, BlockManagerId(2, hadoop1, 40640)
17/11/20 11:24:40 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop1:40640 (size: 1218.0 B, free: 1247.2 MB)
17/11/20 11:24:40 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, hadoop1, partition 1,PROCESS_LOCAL, 2157 bytes)
17/11/20 11:24:40 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 14708 ms on hadoop1 (1/2)
17/11/20 11:24:40 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 34 ms on hadoop1 (2/2)
17/11/20 11:24:40 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) finished in 24.994 s
17/11/20 11:24:40 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
17/11/20 11:24:40 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 25.166251 s
Pi is roughly 3.14648
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
17/11/20 11:24:40 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
17/11/20 11:24:40 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.210.70:4040
17/11/20 11:24:40 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
17/11/20 11:24:40 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
17/11/20 11:24:40 INFO cluster.YarnClientSchedulerBackend: Asking each executor to shut down
17/11/20 11:24:41 INFO cluster.YarnClientSchedulerBackend: Stopped
17/11/20 11:24:41 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/11/20 11:24:41 INFO storage.MemoryStore: MemoryStore cleared
17/11/20 11:24:41 INFO storage.BlockManager: BlockManager stopped
17/11/20 11:24:41 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
17/11/20 11:24:41 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/11/20 11:24:41 INFO spark.SparkContext: Successfully stopped SparkContext
17/11/20 11:24:41 INFO util.ShutdownHookManager: Shutdown hook called
17/11/20 11:24:41 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-603bd57a-5f73-41dc-84d0-e732cbd37788
17/11/20 11:24:41 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
17/11/20 11:24:41 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
17/11/20 11:24:41 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-603bd57a-5f73-41dc-84d0-e732cbd37788/httpd-8b6ce293-389a-4564-bedb-8560a3a924d5
4. 以下关于RPC的错误也可以通过上述方案,解决:
17/11/20 10:43:02 INFO spark.SparkContext: Running Spark version 1.6.1
17/11/20 10:43:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/11/20 10:43:02 INFO spark.SecurityManager: Changing view acls to: root
17/11/20 10:43:02 INFO spark.SecurityManager: Changing modify acls to: root
17/11/20 10:43:02 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/11/20 10:43:03 INFO util.Utils: Successfully started service 'sparkDriver' on port 43103.
17/11/20 10:43:03 INFO slf4j.Slf4jLogger: Slf4jLogger started
17/11/20 10:43:03 INFO Remoting: Starting remoting
17/11/20 10:43:03 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:54479]
17/11/20 10:43:03 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 54479.
17/11/20 10:43:03 INFO spark.SparkEnv: Registering MapOutputTracker
17/11/20 10:43:03 INFO spark.SparkEnv: Registering BlockManagerMaster
17/11/20 10:43:03 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-115d1d9d-efd2-4b77-a275-071bb880d596
17/11/20 10:43:03 INFO storage.MemoryStore: MemoryStore started with capacity 511.1 MB
17/11/20 10:43:03 INFO spark.SparkEnv: Registering OutputCommitCoordinator
17/11/20 10:43:04 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/11/20 10:43:04 INFO server.AbstractConnector: Started [email protected]:4040
17/11/20 10:43:04 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
17/11/20 10:43:04 INFO ui.SparkUI: Started SparkUI at http://192.168.210.70:4040
17/11/20 10:43:04 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-1a7d680b-c815-4c0d-b706-9751f5f1b57a/httpd-e8d7be01-495d-403b-a7a4-1332d9ae2411
17/11/20 10:43:04 INFO spark.HttpServer: Starting HTTP Server
17/11/20 10:43:04 INFO server.Server: jetty-8.y.z-SNAPSHOT
17/11/20 10:43:04 INFO server.AbstractConnector: Started [email protected]:36186
17/11/20 10:43:04 INFO util.Utils: Successfully started service 'HTTP file server' on port 36186.
17/11/20 10:43:05 INFO spark.SparkContext: Added JAR file:/opt/spark1.6.1/lib/spark-examples-1.6.1-hadoop2.6.0.jar at http://192.168.210.70:36186/jars/spark-examples-1.6.1-hadoop2.6.0.jar with timestamp 1511145785204
17/11/20 10:43:05 INFO client.RMProxy: Connecting to ResourceManager at hadoop0/192.168.210.70:8032
17/11/20 10:43:05 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
17/11/20 10:43:05 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (12288 MB per container)
17/11/20 10:43:05 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
17/11/20 10:43:05 INFO yarn.Client: Setting up container launch context for our AM
17/11/20 10:43:05 INFO yarn.Client: Setting up the launch environment for our AM container
17/11/20 10:43:05 INFO yarn.Client: Preparing resources for our AM container
17/11/20 10:43:06 INFO yarn.Client: Uploading resource file:/opt/spark1.6.1/lib/spark-assembly-1.6.1-hadoop2.6.0.jar -> hdfs://hadoop0:9000/user/root/.sparkStaging/application_1510653707211_0009/spark-assembly-1.6.1-hadoop2.6.0.jar
17/11/20 10:43:07 INFO yarn.Client: Uploading resource file:/tmp/spark-1a7d680b-c815-4c0d-b706-9751f5f1b57a/__spark_conf__910020831153605384.zip -> hdfs://hadoop0:9000/user/root/.sparkStaging/application_1510653707211_0009/__spark_conf__910020831153605384.zip
17/11/20 10:43:07 INFO spark.SecurityManager: Changing view acls to: root
17/11/20 10:43:07 INFO spark.SecurityManager: Changing modify acls to: root
17/11/20 10:43:07 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
17/11/20 10:43:07 INFO yarn.Client: Submitting application 9 to ResourceManager
17/11/20 10:43:08 INFO impl.YarnClientImpl: Submitted application application_1510653707211_0009
17/11/20 10:43:10 INFO yarn.Client: Application report for application_1510653707211_0009 (state: ACCEPTED)
17/11/20 10:43:10 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1511145788138
final status: UNDEFINED
tracking URL: http://hadoop0:8088/proxy/application_1510653707211_0009/
user: root
17/11/20 10:43:13 INFO yarn.Client: Application report for application_1510653707211_0009 (state: ACCEPTED)
17/11/20 10:43:15 INFO yarn.Client: Application report for application_1510653707211_0009 (state: ACCEPTED)
17/11/20 10:43:16 INFO yarn.Client: Application report for application_1510653707211_0009 (state: ACCEPTED)
17/11/20 10:43:17 INFO yarn.Client: Application report for application_1510653707211_0009 (state: ACCEPTED)
17/11/20 10:43:18 INFO yarn.Client: Application report for application_1510653707211_0009 (state: ACCEPTED)
17/11/20 10:43:18 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(null)
17/11/20 10:43:18 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> hadoop0, PROXY_URI_BASES -> http://hadoop0:8088/proxy/application_1510653707211_0009), /proxy/application_1510653707211_0009
17/11/20 10:43:18 INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
17/11/20 10:43:19 INFO yarn.Client: Application report for application_1510653707211_0009 (state: RUNNING)
17/11/20 10:43:19 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.210.70
ApplicationMaster RPC port: 0
queue: default
start time: 1511145788138
final status: UNDEFINED
tracking URL: http://hadoop0:8088/proxy/application_1510653707211_0009/
user: root
17/11/20 10:43:19 INFO cluster.YarnClientSchedulerBackend: Application application_1510653707211_0009 has started running.
17/11/20 10:43:19 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 44148.
17/11/20 10:43:19 INFO netty.NettyBlockTransferService: Server created on 44148
17/11/20 10:43:19 INFO storage.BlockManagerMaster: Trying to register BlockManager
17/11/20 10:43:19 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.210.70:44148 with 511.1 MB RAM, BlockManagerId(driver, 192.168.210.70, 44148)
17/11/20 10:43:19 INFO storage.BlockManagerMaster: Registered BlockManager
17/11/20 10:43:22 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (hadoop1:45801) with ID 2
17/11/20 10:43:22 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (hadoop2:32964) with ID 1
17/11/20 10:43:22 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop1:52352 with 2.7 GB RAM, BlockManagerId(2, hadoop1, 52352)
17/11/20 10:43:22 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop2:45228 with 2.7 GB RAM, BlockManagerId(1, hadoop2, 45228)
17/11/20 10:43:22 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
17/11/20 10:43:23 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:36
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 2 output partitions
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:36)
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Parents of final stage: List()
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Missing parents: List()
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents
17/11/20 10:43:23 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1904.0 B, free 1904.0 B)
17/11/20 10:43:23 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1218.0 B, free 3.0 KB)
17/11/20 10:43:23 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.210.70:44148 (size: 1218.0 B, free: 511.1 MB)
17/11/20 10:43:23 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32)
17/11/20 10:43:23 INFO cluster.YarnScheduler: Adding task set 0.0 with 2 tasks
17/11/20 10:43:23 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, hadoop2, partition 0,PROCESS_LOCAL, 2157 bytes)
17/11/20 10:43:23 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, hadoop1, partition 1,PROCESS_LOCAL, 2157 bytes)
17/11/20 10:43:23 INFO cluster.YarnClientSchedulerBackend: Disabling executor 1.
17/11/20 10:43:23 INFO scheduler.DAGScheduler: Executor lost: 1 (epoch 0)
17/11/20 10:43:23 INFO storage.BlockManagerMasterEndpoint: Trying to remove executor 1 from BlockManagerMaster.
17/11/20 10:43:23 ERROR client.TransportClient: Failed to send RPC 6494801080030835916 to hadoop0/192.168.210.70:55463: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
17/11/20 10:43:23 INFO storage.BlockManagerMasterEndpoint: Removing block manager BlockManagerId(1, hadoop2, 45228)
17/11/20 10:43:23 INFO storage.BlockManagerMaster: Removed 1 successfully in removeExecutor
17/11/20 10:43:23 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to get executor loss reason for executor id 1 at RPC address hadoop2:32964, but got no response. Marking as slave lost.
java.io.IOException: Failed to send RPC 6494801080030835916 to hadoop0/192.168.210.70:55463: java.nio.channels.ClosedChannelException
at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:239)
at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:226)
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:680)
at io.netty.util.concurrent.DefaultPromise$LateListeners.run(DefaultPromise.java:845)
at io.netty.util.concurrent.DefaultPromise$LateListenerNotifier.run(DefaultPromise.java:873)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:357)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:357)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.nio.channels.ClosedChannelException
17/11/20 10:43:23 ERROR cluster.YarnScheduler: Lost executor 1 on hadoop2: Slave lost
17/11/20 10:43:23 WARN scheduler.TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, hadoop2): ExecutorLostFailure (executor 1 exited caused by one of the running tasks) Reason: Slave lost
17/11/20 10:43:24 INFO cluster.YarnClientSchedulerBackend: Disabling executor 2.
17/11/20 10:43:24 INFO scheduler.DAGScheduler: Executor lost: 2 (epoch 1)
17/11/20 10:43:24 INFO storage.BlockManagerMasterEndpoint: Trying to remove executor 2 from BlockManagerMaster.
17/11/20 10:43:24 INFO storage.BlockManagerMasterEndpoint: Removing block manager BlockManagerId(2, hadoop1, 52352)
17/11/20 10:43:24 INFO storage.BlockManagerMaster: Removed 2 successfully in removeExecutor
17/11/20 10:43:24 ERROR client.TransportClient: Failed to send RPC 6980255577157578925 to hadoop0/192.168.210.70:55463: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
17/11/20 10:43:24 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to get executor loss reason for executor id 2 at RPC address hadoop1:45801, but got no response. Marking as slave lost.
java.io.IOException: Failed to send RPC 6980255577157578925 to hadoop0/192.168.210.70:55463: java.nio.channels.ClosedChannelException
at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:239)
at org.apache.spark.network.client.TransportClient$3.operationComplete(TransportClient.java:226)
at io.netty.util.concurrent.DefaultPromise.notifyListener0(DefaultPromise.java:680)
at io.netty.util.concurrent.DefaultPromise.notifyListeners(DefaultPromise.java:567)
at io.netty.util.concurrent.DefaultPromise.tryFailure(DefaultPromise.java:424)
at io.netty.channel.AbstractChannel$AbstractUnsafe.safeSetFailure(AbstractChannel.java:801)
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(AbstractChannel.java:699)
at io.netty.channel.DefaultChannelPipeline$HeadContext.write(DefaultChannelPipeline.java:1122)
at io.netty.channel.AbstractChannelHandlerContext.invokeWrite(AbstractChannelHandlerContext.java:633)
at io.netty.channel.AbstractChannelHandlerContext.access$1900(AbstractChannelHandlerContext.java:32)
at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.write(AbstractChannelHandlerContext.java:908)
at io.netty.channel.AbstractChannelHandlerContext$WriteAndFlushTask.write(AbstractChannelHandlerContext.java:960)
at io.netty.channel.AbstractChannelHandlerContext$AbstractWriteTask.run(AbstractChannelHandlerContext.java:893)
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:357)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:357)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.nio.channels.ClosedChannelException
17/11/20 10:43:24 ERROR cluster.YarnScheduler: Lost executor 2 on hadoop1: Slave lost
17/11/20 10:43:24 WARN scheduler.TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, hadoop1): ExecutorLostFailure (executor 2 exited caused by one of the running tasks) Reason: Slave lost
17/11/20 10:43:25 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(null)
17/11/20 10:43:25 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> hadoop0, PROXY_URI_BASES -> http://hadoop0:8088/proxy/application_1510653707211_0009), /proxy/application_1510653707211_0009
17/11/20 10:43:25 INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter
17/11/20 10:43:29 ERROR cluster.YarnClientSchedulerBackend: Yarn application has already exited with state FINISHED!
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
17/11/20 10:43:29 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
17/11/20 10:43:29 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.210.70:4040
17/11/20 10:43:29 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) failed in 5.680 s
17/11/20 10:43:29 INFO scheduler.DAGScheduler: Job 0 failed: reduce at SparkPi.scala:36, took 5.884625 s
17/11/20 10:43:29 ERROR scheduler.LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerStageCompleted(org.apache.spark.scheduler.StageInfo@29bb1d25)
Exception in thread "main" org.apache.spark.SparkException: Job 0 cancelled because SparkContext was shut down
at org.apache.spark.scheduler.DAGScheduler$$anonfun$cleanUpAfterSchedulerStop$1.apply(DAGScheduler.scala:806)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$cleanUpAfterSchedulerStop$1.apply(DAGScheduler.scala:804)
at scala.collection.mutable.HashSet.foreach(HashSet.scala:79)
at org.apache.spark.scheduler.DAGScheduler.cleanUpAfterSchedulerStop(DAGScheduler.scala:804)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onStop(DAGScheduler.scala:1658)
at org.apache.spark.util.EventLoop.stop(EventLoop.scala:84)
at org.apache.spark.scheduler.DAGScheduler.stop(DAGScheduler.scala:1581)
at org.apache.spark.SparkContext$$anonfun$stop$9.apply$mcV$sp(SparkContext.scala:1740)
at org.apache.spark.util.Utils$.tryLogNonFatalError(Utils.scala:1229)
at org.apache.spark.SparkContext.stop(SparkContext.scala:1739)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend$MonitorThread.run(YarnClientSchedulerBackend.scala:147)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:620)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1832)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:1952)
at org.apache.spark.rdd.RDD$$anonfun$reduce$1.apply(RDD.scala:1025)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:111)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:316)
at org.apache.spark.rdd.RDD.reduce(RDD.scala:1007)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:36)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
17/11/20 10:43:29 ERROR scheduler.LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerJobEnd(0,1511145809112,JobFailed(org.apache.spark.SparkException: Job 0 cancelled because SparkContext was shut down))
17/11/20 10:43:29 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
17/11/20 10:43:29 INFO cluster.YarnClientSchedulerBackend: Asking each executor to shut down
17/11/20 10:43:29 INFO storage.DiskBlockManager: Shutdown hook called
17/11/20 10:43:29 INFO cluster.YarnClientSchedulerBackend: Stopped
17/11/20 10:43:29 INFO util.ShutdownHookManager: Shutdown hook called
17/11/20 10:43:29 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1a7d680b-c815-4c0d-b706-9751f5f1b57a/httpd-e8d7be01-495d-403b-a7a4-1332d9ae2411
17/11/20 10:43:29 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/11/20 10:43:29 INFO storage.MemoryStore: MemoryStore cleared
17/11/20 10:43:29 INFO storage.BlockManager: BlockManager stopped
17/11/20 10:43:29 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
17/11/20 10:43:29 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
17/11/20 10:43:29 INFO spark.SparkContext: Successfully stopped SparkContext
17/11/20 10:43:29 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1a7d680b-c815-4c0d-b706-9751f5f1b57a/userFiles-e796cf1a-3942-44d1-a8cc-68295e623b03
17/11/20 10:43:29 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1a7d680b-c815-4c0d-b706-9751f5f1b57a