python 详解
- 1 Types and Operations
- 1-1 Built-in Objects preview
- 1-2 Numbers
- 1-3 String
- 1-3-1 Sequence Operations
- 1-3-2 Immutable
- 1-3-3 Type-Specific Methods
- 1-3-4 Getting Help
- 1-3-5 Unicode Strings
- 1-3-6 Pattern Matching
- 1-4 Lists
- 1-4-1 Sequence Operations
- 1-4-2 Type-Specific Operations
- 1-4-2 Bounds Checking
- 1-4-3 Nesting
- 1-4-4 Comprehensions
- 1-5 Dictionaries
- 1-5-1 Mapping Operations
- 1-5-2 Nesting Revisited
- 1-5-3 Missing Keys if Tests
- 1-5-4 Sorting Keys for Loops
- 1-5-5 Iteration and Optimization
- 1-6 Tuples
- 1-7 Files
- 1-7-1 Binary Bytes Files
- 1-7-2 Unicode Text files
- 1-8 Other Core Types
- 1-8-1 How to break your codes flexibility
- 2 Statements and Syntax
- 2-1 Introducing Python Statements
- 2-2 Iterations and Comprehensions
- 2-2-1 The Iteration Protocol File Iterators
- 2-2-2 The full iteration protocol
- 2-2-3 List Comprehensions A First Detailed Look
- 2-2-4 List Comprehensions Basics
- 2-2-4 Using List Comprehensions on Files
- 2-2-5 Extended List Comprehension Syntax
- 2-2-5-1 Filter clauses if
- 2-2-5-2 Nested loops for
- 3 The Documentation interlude
- 3-1 Python Documentation Sources
- 3-2 Comments
- 3-3 The dir Function
- 3-4 Docstrings doc
- 3-4-1 User-defined docstrings
- 3-4-2 Built-in docstrings
- 3-5 PyDoc The help Function
- 3-6 PyDoc HTML Reports
- 3-6-1 Python 32 and later PyDocs all-browser mode
- 3-6-2 Python 32 and earlier GUI client
- 3-7 Beyond docstrings Sphinx
- 4 Functions and Generators
- 4-1 Function Basics
- 4-2 Coding Functions
- 4-2-1 def Statements
- 4-2-2 def Executes at Runtime
- 4-3 Scopes
- 4-3-1 Python Scope Basics
- 4-3-1-1 Scope Details
- 4-3-1-2 Name Resolution The LEGB Rule
- 4-3-2 Scope Example
- 4-3-3 The Built-in Scope
- 4-3-4 Scopes and Nested Functions
- 4-3-4-1 Nested Scope Details
- 4-3-4-2 Nested Scope Example
- 4-3-4-3 Factory Functions Closures
-
- A simple function factory
-
- 4-3-1 Python Scope Basics
- 4-4 Arguments
- 4-4-1 Argument-Passing Basics
- 4-4-1-1 Arguments and Shared References
- 4-4-1-2 Avoiding Mutable Argument Changes
- 4-4-1-3 Simulating Output Parameters and Multiple Results
- 4-4-2 Special Argument-Matching Modes
- 4-4-2-1 Argument Matching Basics
- 4-4-2-2 Argument Matching Syntax
- 4-4-2-3 The Gritty Details
- 4-4-3 Arbitrary Arguments Examples
- 4-4-3-1 Calls Unpacking arguments
- 4-4-4 Python 3X Keyword-Only Arguments
- 4-4-1 Argument-Passing Basics
- 4-5 Advanced Function Topics
- 4-5-1 functions Design Concepts
- 4-5-2 Function Objects Attributes and Annotations
- 4-5-2-1 Indirect Function Calls First Class Objects
- 4-5-2-2 Function Introspection
- 4-5-2-3 Function Attributes
- 4-5-2-4 Function Annotations in 3X
- 4-5-3 Anonymous Functions lambda
- 4-5-3-1 lambda Basics
- 4-5-4 Functional Programming Tools
- 4-5-4-1 Mapping Functions over Iterables map
- 4-5-4-2 Selecting Items in Iterables filter
- 4-5-4-3 Combining Items in Iterables reduce
- 4-6 Comprehensions and Generations
- 4-6-1 List Comprehensions Versus map
- 4-6-2 Adding Tests and Nested Loops filter
- 4-6-2 Formal comprehension syntax
- 4-6-3 Dont Abuse List Comprehensions KISS
- 4-6-3-1 On the other hand performance conciseness expressiveness
- 4-7 Generator Functions and Expressions
- 4-7-1 Generator Functions yield Versus return
- 4-7-1-1 State suspension
- 4-7-1-2 Iteration protocol integration
- 4-7-1-3 Generator functions in action
- 4-7-1-4 Why generator functions
- 4-7-1-5 Extended generator function protocol send versus next
- 4-7-2 Generator Expressions Iterables Meet Comprehensions
- 4-7-3 Generator Functions Versus Generator Expressions
- 4-7-4 Generators Are Single-Iteration Objects
- 4-7-5 Preview User-defined iterables in classes
- 4-7-1 Generator Functions yield Versus return
- 4-8 The Benchmarking Interlude
- 4-8-1 Timing Iteration Alternatives
- 4-8-1-1 Timing Module Homegrown
- 4-8-1 Timing Iteration Alternatives
- 5 Modules and Packages
- 5-1 Modules The Big Picture
- 5-2-1 Python Program Architecture
- 5-2-1-1 How to Structure a Program
- 5-2-1-2 Imports and Attributes
- 5-2-1-3 Standard Library Modules
- 5-2-2 How Imports Work
- 5-2-2-1 Find it
- 5-2-2-2 Compile it Maybe
- 5-2-2-3 Run It
- 5-2-3 Byte Code Files pycache in Python 32
- 5-2-4 The Module Search Path
- 5-2-4-1 The syspath List
- 5-2-1 Python Program Architecture
- 5-1 Modules The Big Picture
- 6 Classes and OOP
- 6-1 OOP The Big Picture
- 6-1-1 Why Use Classes
- 6-1-2 Attribute Inheritance Search
- 6-1-3 Classes and Instances
- 6-1-4 Method Calls
- 6-1-5 Coding Class Trees
- 6-1-6 Operator Overloading
- 6-1-7 Polymorphism and classes
- 6-2 Class Coding Basics
- 6-2-1 Classes Generate Multiple Instance Objects
- 6-2-1-1 Class Objects Provide Default Behavior
- 6-2-1-2 Instance Objects Are Concrete Items
- 6-2-1-3 A First Example
- 6-2-2 Classes Are Customized by Inheritance
- 6-2-2-1 Classes Are Attributes in Modules
- 6-2-3 Classes Can Intercept Python Operators
- 6-2-3-1 Examples
- 6-2-4 Future Directions
- 6-2-1 Classes Generate Multiple Instance Objects
- 6-3 Operator Overloading
- 6-3-1 The Basics
- 6-3-1-1 Constructors and Expressions init and sub
- 6-3-1-2 Common Operator Overloading Methods
- 6-3-1 The Basics
- 6-4 Advanced Class Topics
- 6-4-1 The New Style Class Model
- 6-4-2 New-Style Classes changes
- 6-4-2-1 Diamond Inheritance Change
- 6-4-2-1-1 Implications for diamond inheritance trees
- 6-4-2-1-2 Explicit conflict resolution
- 6-4-2-2 More on the MRO Method Resolution Order
- 6-4-2-1 Diamond Inheritance Change
- 6-4-3 New-Style Class Extensions
- 6-4-3-1 Slots Attribute Declarations
- 6-4-3-1-1 Slot basics
- 6-4-3-1-2 Slots and namespace dictionaries
- 6-4-3-1-3 Multiple slot lists in superclasses
- 6-4-3-1-4 Slot usage rules
- 6-4-3-2 Properties Attribute Accessors
- 6-4-3-2-1 Property basics
- 6-4-3-2-2 getattribute and Descriptors Attribute Tools
- 6-4-3-1 Slots Attribute Declarations
- 6-4-4 Static and Class Methods
- 6-4-4-1 Static Methods in 2X and 3X
- 6-4-4-2 Static Method Alternatives
- 6-4-4-3 Using Static and Class Methods
- 6-4-5 Decorators and Metaclasses Part 1
- 6-4-5-1 Function Decorator Basics
- 6-4-5-2 A First Look at User-Defined Function Decorators
- 6-4-5-3 A First Look at Class Decorators and Metaclasses
- 6-4-6 The super Built-in Function For Better or Worse
- 6-4-6-1 The Great super Debate
- 6-4-6-2 Traditional Superclass Call Form Portable General
- 6-4-6-3 Basic super Usage and Its Tradeoffs
- 6-4-6-3-1 Odd semantics A magic proxy in Python 3X
- 6-4-6-3-2 Pitfall Adding multiple inheritance naively
- 6-1 OOP The Big Picture
- 7 Exceptions and Tools
- 7-1 Exception Basics
- 7-1-1 Exception Roles
- 7-1-2 User-Defined Exceptions
- 7-1-3 Termination Actions
- 7-2 Exception Coding Details
- 7-2-1 Try Statement Clauses
- 7-2-2 Catching any and all exceptions
- 7-2-3 The try else Clause
- 7-2-4 The raise Statement
- 7-2-4 Python 3X Exception Chaining raise from
- 7-2-5 The assert Statement
- 7-2-6 withas Context Managers
- 7-2-6-1 Basic Usage
- 7-2-6-2 The Context Management Protocol
- 7-2-6-3 Multiple Context Managers in 31 27 and Later
- 7-3 Exception Objects
- 7-3-1 Exceptions Back to the future
- 7-3-1-1 String Exceptions Are Right Out
- 7-3-1-2 Class-Based Exceptions
- 7-3-1-3 Coding Exceptions Classes
- 7-3-2 Built-in Exception Classes
- 7-3-3 Custom Data and Behavior
- 7-3-3-1 Providing Exception Details
- 7-3-3-2 Providing Exception Methods
- 7-3-1 Exceptions Back to the future
- 7-4 Designing with Exceptions
- 7-4-1 Exception idioms
- 7-4-1-1 Breaking Out of Multiple Nested Loops
- 7-4-1-2 Exceptions Arent Always Errors
- 7-4-1-3 Functions Can Signal Conditions with raise
- 7-4-1-4 Closing Files and Server Connections
- 7-4-1-5 Debugging with Outer try Statements
- 7-4-1-6 Running In-Process Tests
- 7-4-1-7 More on sysexc_info
- 7-4-1-8 Displaying Errors and Tracebacks
- 7-4-1 Exception idioms
- 7-1 Exception Basics
- 8 Advanced Topics
- 8-1 Unicode and Byte Strings
- 8-1-1 String Basics
- 8-1-1-1 Character Encoding Schemes
- 8-1-1 String Basics
- 8-2 Managed Attributes
- 8-2-1 Why Manage Attributes
- 8-2-1-1 Inserting Code to Run on Attribute Access
- 8-2-2 Properties
- 8-2-2-1 The Basics
- 8-2-2-2 A First Example
- 8-2-2-3 Coding Properties with Decorators
- 8-2-3 Descriptors
- 8-2-3-1 The Basics
- 8-2-3-1-1 Descriptor method arguments
- 8-2-3-1-2 Read-only descriptors
- 8-2-3-2 A First Example
- 8-2-3-3 Using State Information in Descriptors
- 8-2-3-4 How Properties and Descriptors Relate
- 8-2-3-1 The Basics
- 8-2-4 getattr and getattribute
- 8-2-4-1 The Basics
- 8-2-1 Why Manage Attributes
- 8-3 Decorators
- 8-3-1 Whats a Decorator
- 8-3-1-1 Managing Calls and Instances
- 8-3-1-2 Managing Functions and Classes
- 8-3-2 Function Decorators
- 8-3-2-1 Usage
- 8-3-2-2 Implementation
- 8-3-2-3 Supporting method decoration
- 8-3-3 Class Decorators
- 8-3-3-1 Usage
- 8-3-3-2 Implementation
- 8-3-3-3 Supporting multiple instances
- 8-3-4 Decorator Nesting
- 8-3-5 Decorator Arguments
- 8-3-1 Whats a Decorator
- 8-4 Metaclasses
- 8-1 Unicode and Byte Strings
1) Types and Operations
1-1) Built-in Objects preview
| Object type | Example literals/creation |
|---|---|
| Numbers | 1234, 3.1415, 3+4j, 0b111, Decimal(), Fraction() |
| Strings | ‘spam’, “Bob’s”, b’a\x01c’, u’sp\xc4m’ |
| Lists | [1, [2, ‘three’], 4.5],list(range(10)) |
| Dictionaries | {‘food’: ‘spam’, ‘taste’: ‘yum’},dict(hours=10) |
| Tuples | (1, ‘spam’, 4, ‘U’),tuple(‘spam’),namedtuple |
| Files | open(‘eggs.txt’),open(r’C:\ham.bin’, ‘wb’) |
| Sets | set(‘abc’),{‘a’, ‘b’, ‘c’} |
| Other core types | Booleans, types, None |
| Program unit types | Functions, modules, classes |
| Implementation-related types | Compiled code, stack tracebacks |
1-2) Numbers
Although it offers some fancier options, Python’s basic number types are, well, basic. Numbers in Python support the normal mathematical operations. For instance, the plus sign (+) performs addition, a star () is used for multiplication, and two stars (*) are used for exponentiation:
>>> 123 + 222 345
>>> 1.5 * 4 6.0
>>> 2 ** 100 1267650600228229401496703205376
# Integer addition
# Floating-point multiplication # 2 to the power 100, againNotice the last result here: Python 3.X’s integer type automatically provides extra precision for large numbers like this when needed (in 2.X, a separate long integer type handle numbers too large for the normal integer type in similar ways)
On Pythons prior to 2.7 and 3.1, once you start experimenting with floating-point numbers, you’re likely to stumble across something that may look like a bit odd at fist glance:
>>> 3.1415 * 2 # repr: as code (Pythons < 2.7 and 3.1) 6.2830000000000004
>>> print(3.1415 * 2) # str: user-friendly
6.283The first result isn’t a bug, it’s a display issue. It turns out that there are two ways to print server object in Python - with full precision (as in the first result shown here), and in a user-friendly form (as in the second). Formally, the first form is known as an objects as-code repr, and the second is its user-friendly str. In older Pythons, the floating-point repr sometimes displays more precision than you might expect. The difference can also matter when we step up to using classes.
Better yet, upgrade to Python 2.7 and the latest 3.X, where floatin-point numbers display themselves more intelligently, usually with fewer extraneous digits.
>>> 3.1415 * 2 # repr: as code (Pythons >= 2.7 and 3.1)
6.283Besides expressions, there are a handful of useful numeric modules that ship with Python - modules are just packages of additional tools that we import to use:
>>> import math
>>> math.pi
3.141592653589793
>>> math.sqrt(85)
9.2195444572928871-3) String
Strings are used to record both textual information, as well as arbitrary collections of bytes (such as an image file’s contents).
1-3-1) Sequence Operations
As sequences, strings support operations that assume a positional ordering among items.
>>> S = 'Spam'
>>> len(S) 4
>>> S[0]
'S'
>>> S[1] 'p'In Python, we can also index backward, from the end - positive indexes count from the left, and negative indexes count back from the right:
>>> S[-1] # The last item from the end in S
'm'
>>> S[-2] # The second-to-last item from the end
'a'In addition to simple positional indexing, sequences also support a more general form of indexing known as slicing. which is a way to extract an entire section (slice) in a single step. For Example:
>>> S # A 4-character string
'Spam'
>>> S[1:3] # Slice of S from offsets 1 through 2 (not 3)
'pa'Finally, as sequences, strings also support concatenation with plus sign (joining two strings into a new string) and repetition (making a new string by repeating another):
>>> S
'Spam'
>>> S + 'xyz' # Concatenation
'Spamxyz'
>>> S
'Spam'
>>> S * 8 # Repetition
'SpamSpamSpamSpamSpamSpamSpamSpam'Notice that the plus sign (+) means different things for different objects: addition for numbers, and concatenation for strings.
1-3-2) Immutable
Also notice in the prior examples that we were not changing the original string with any of the operations we run on it. Every string operation is define to produce a new string as its result, because strings are immutable in Python.
>>> S 'Spam'
>>> S[0] = 'z' # Immutable objects cannot be changed
...error text omitted...
TypeError: 'str' object does not support item assignment
>>> S = 'z' + S[1:] # But we can run expressions to make new objects
>>> S
'zpam'Strictly speaking, you can change text-based data in place if you either expand it into a list of individual characters and join it back together with nothing between, or use the newer bytearray type avaliable in Pythons 2.6, 3.0 and later:
>>> S = 'shrubbery'
>>> L = list(S) # Expand to a list: [...]
>>> L
['s', 'h', 'r', 'u', 'b', 'b', 'e', 'r', 'y']
>>> L[1] = 'c' # Change it in place
>>> ''.join(L) # Join with empty delimiter
'scrubbery'
>>> B = bytearray(b'spam') # A bytes/list hybrid (ahead)
>>>> B.extend(b'eggs') # 'b' needed in 3.X, not 2.X
>>> B bytearray(b'spameggs') # B[i] = ord(c) works here too
>>> B.decode() # Translate to normal string
'spameggs'The bytearray supports in-place changes for text, but only for text whose characters are all at most 8-bits wide. All other strings are still immutable – bytearray is a distinct hybrid of immutable bytes strings
(whose b’…’ syntax is required in 3.X and optional 2.X) and mutable lists (coded and displayed in []), and we have to learn more about both these and Unicode text to fully grasp this code.
1-3-3) Type-Specific Methods
Every string operation we’ve studied so far is really a sequence operation – that is, these operations will work on other sequences in Python as well, including lists and tuples. In addition to generic sequence operations, though, strings also have operations all their own, available as methods – functions that are attached to and act upon a specific object, which are triggered with a call expression.
>>> S = 'Spam'
>>> S.find('pa')
1
>>> S
'Spam'
>>> S.replace('pa', 'XYZ') 'SXYZm'
>>> S
'Spam'
>>> line = 'aaa,bbb,ccccc,dd'
>>> line.split(',')
['aaa', 'bbb', 'ccccc', 'dd']
>>> S = 'spam'
>>> S.upper()
'SPAM'
>>> S.isalpha()
True
>>> line = 'aaa,bbb,ccccc,dd\n'
>>> line.rstrip()
'aaa,bbb,ccccc,dd'
>>> line.rstrip().split(',')
['aaa', 'bbb', 'ccccc', 'dd']
Strings also support an advanced substitution operation known as formatting, available as both an expression and a string method call; the second of these allows you to omit relative argument value numbers as of 2.7 and 3.1:
>>> '%s, eggs, and %s' % ('spam', 'SPAM!') # Formatting expression (all)
'spam, eggs, and SPAM!'
>>> '{0}, eggs, and {1}'.format('spam', 'SPAM!') # Formatting method (2.6+, 3.0+)
'spam, eggs, and SPAM!'
>>> '{}, eggs, and {}'.format('spam', 'SPAM!') # Numbers optional (2.7+, 3.1+)
'spam, eggs, and SPAM!'Formatting is rich with features, which we’ll postpone discussing until later in this book, and which tend to matter most when you must generate numeric reports:
>>> '{:,.2f}'.format(296999.2567) # Separators, decimal digits
'296,999.26'
>>> '%.2f | %+05d' % (3.14159, −42) # Digits, padding, signs
'3.14 | −0042'1-3-4) Getting Help
What is available for string object, you can always call the built-in dir function. This functions lists variables assigned in the caller’s scope when called with no argument; more usefully, it returns a list of all the attributes available for any objects passed to it.
>>> dir(S)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']You probable won’t care about the names with double underscores in this list until later in the book, when we study operator overloading in classes – they represent the implementation of the string object and are available to support customization. The add method of strings, for example, is what really performs concatenation; Python maps the first of following to the second internally, though you shouldn’t usually use the second form yourself (it’s less intuitive, and might even run slower):
>>> S + 'NI!'
'spamNI!'
>>> S.__add__('NI!')
'spamNI!'In general, leading and trailing double underscores is the naming pattern Python uses for implementation details. The names without the underscores in this list are the callable methods on string object.
The dir function simply gives the method’s names. To ask what they do, you can pass them to the help function:
>>> help(S.replace)
Help on built-in function replace:
replace(...)
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring old replaced by new. If the optional argument count is given, only the first count occurrences are replaced.1-3-5) Unicode Strings
Python’s strings also come with full Unicode support required for processing text in internationalized character sets.
In Python 3.X, the normal str string handles Unicode text (including ASCII, which is just a simple kind of Unicode); a distinct bytes string type represents raw byte values (including media and encoded text); and 2.X Unicode literals are supported in 3.3 and later for 2.x compatibility (they are treated the same as normal 3.X str strings):
>>> 'sp\xc4m' # 3.X: normal str strings are Unicode text
'spÄm'
>>> b'a\x01c' # bytes strings are byte-based data
b'a\x01c'
>>> u'sp\u00c4m''spÄm' # The 2.X Unicode literal works in 3.3+: just strIn Python 2.X, the normal str string handles both 8-bits character strings (including ASCII text) and raw byte values; a distinct unicode string type represents Unicode text; and 3.X bytes literals are supported in 2.6 and later for 3.X compatibility.
>>> print u'sp\xc4m' # 2.X: Unicode strings are a distinct type
spÄm
>>> 'a\x01c' # Normal str strings contain byte-based text/data
'a\x01c'
>>> b'a\x01c' # The 3.X bytes literal works in 2.6+: just str
'a\x01c'
Formally, in both 2.X and 3.X, non-Unicode strings are sequences of 8-bit bytes that print with ASCII characters when possible, and Unicode strings are sequences of Uni- code code points—identifying numbers for characters, which do not necessarily map to single bytes when encoded to files or stored in memory. In fact, the notion of bytes doesn’t apply to Unicode: some encodings include character code points too large for a byte, and even simple 7-bit ASCII text is not stored one byte per character under some encodings and memory storage schemes:
>>> 'spam' # Characters may be 1, 2, or 4 bytes in memory
'spam'
>>> 'spam'.encode('utf8') # Encoded to 4 bytes in UTF-8 in files
b'spam'
>>> 'spam'.encode('utf16') # But encoded to 10 bytes in UTF-16
b'\xff\xfes\x00p\x00a\x00m\x00'Both 3.X and 2.X also support the bytearray string type we met earlier, which is es- sentially a bytes string (a str in 2.X) that supports most of the list object’s in-place mutable change operations.
Both 3.X and 2.X also support coding non-ASCII characters with \x hexadecimal and short \u and long \U Unicode escapes, as well as file-wide encodings declared in program source files. Here’s our non-ASCII character coded three ways in 3.X (add a leading “u” and say “print” to see the same in 2.X):
>>> 'sp\xc4\u00c4\U000000c4m'
'spÄÄÄm'What these values mean and how they are used differs between text strings, which are the normal string in 3.X and Unicode in 2.X, and byte strings, which are bytes in 3.X and the normal string in 2.X. All these escapes can be used to embed actual Unicode code-point ordinal-value integers in text strings. By contrast, byte strings use only \x hexadecimal escapes to embed the encoded form of text, not its decoded code point values—encoded bytes are the same as code points, only for some encodings and char- acters:
>>> '\u00A3', '\u00A3'.encode('latin1'), b'\xA3'.decode('latin1') ('£', b'\xa3', '£')As a notable difference, Python 2.X allows its normal and Unicode strings to be mixed in expressions as long as the normal string is all ASCII; in contrast, Python 3.X has a tighter model that never allows its normal and byte strings to mix without explicit conversion:
u'x' + b'y' # Works in 2.X (where b is optional and ignored)
u'x' + 'y' # Works in 2.X: u'xy'
u'x' + b'y' # Fails in 3.3 (where u is optional and ignored)
u'x' + 'y' # Works in 3.3: 'xy'
'x' + b'y'.decode() # Works in 3.X if decode bytes to str: 'xy'
'x'.encode() + b'y' # Works in 3.X if encode str to bytes: b'xy'1-3-6) Pattern Matching
Readers with background in other scripting languages may be interested in to know that to do pattern matching in Python. we import a module called re. This module has analogous calls for searching, splitting, and replacement, but because we can use patterns to specify substrings, we can be much more general:
>>> import re
>>> match = re.match('Hello[ \t]*(.*)world', 'Hello Python world') >>> match.group(1)
'Python '
>>> match = re.match('[/:](.*)[/:](.*)[/:](.*)', '/usr/home:lumberjack') >>> match.groups()
('usr', 'home', 'lumberjack')
>>> re.split('[/:]', '/usr/home/lumberjack') ['', 'usr', 'home', 'lumberjack']1-4) Lists
1-4-1) Sequence Operations
>>> L = [123, 'spam', 1.23] # A list of three different-type objects
>>> len(L) # Number of items in the list
3
>>> L[0]
>123
>>> L[:-1]
[123, 'spam']
>>> L + [4, 5, 6]
[123, 'spam', 1.23, 4, 5, 6]
>>> L * 2
[123, 'spam', 1.23, 123, 'spam', 1.23]1-4-2) Type-Specific Operations
>>> L.append('NI') # Growing: add object at end of list
>>> L
[123, 'spam', 1.23, 'NI']
>>> L.pop(2) # Shrinking: delete an item in the middle
1.23
>>> L # "del L[2]" deletes from a list too
[123, 'spam', 'NI']
>>> M = ['bb', 'aa', 'cc'] >>> M.sort()
>>> M
['aa', 'bb', 'cc']
>>> M.reverse()
>>> M
['cc', 'bb', 'aa']The list sort method here, for example, orders the list in ascending fashion by default, and reverse reverses it – in both cases, the methods modify the list directly.
1-4-2) Bounds Checking
Although lists have no fixed size, Python still doesn’t allow us to reference items that are not present. Indexing off the end of a list is always a mistake, but so is assigning off the end:
>>> L
[123, 'spam', 'NI']
>>> L[99]
...error text omitted...
IndexError: list index out of range
>>> L[99] = 1
...error text omitted...
IndexError: list assignment index out of range1-4-3) Nesting
One nice feature of Python’s core data types is that they support arbitrary nesting.
>>> M = [[1, 2, 3], # A 3 × 3 matrix, as nested lists [4, 5, 6],
# Code can span lines if bracketed
[7, 8, 9]] >>> M
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> M[1] # Get row 2 [4, 5, 6]
>>> M[1][2] # Get row 2, then get item 3 within the row 61-4-4) Comprehensions
In addition to sequence operations and list methods, Python includes a more advanced operation known as a list comprehension expression, which turns out to be a powerful way to process structures like our matrix. Suppose, for instance, that we need to extract the second column of our example matrix. It’s easy to grab rows by simple indexing because the matrix is stored by rows, but it’s almost as easy to get a column with list comprehension:
>>> col2 = [row[1] for row in M] # Collect the items in column 2
>>> col2
[2, 5, 8]
>>> M # The matrix is unchanged
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]List comprehensions derive from set notation; they are a way to build a new list by running an expression on each item in a sequence, once at a time, from left to right.
List comprehensions can be more complex in practice:
>>> [row[1] + 1 for row in M] # Add 1 to each item in column 2
[3, 6, 9]
>>> [row[1] for row in M if row[1] % 2 == 0] # Filter out odd items
[2, 8]These expressions can also be used to collect multiple values, as long as we wrap those values in a nested collection. The following illustrates using range – a built-in that generates successive integers, and requires a surrounding list to display all its values in 3.X only:
>>> list(range(4)) # 0..3 (list() required in 3.X)
>[0, 1, 2, 4]
>> list(range(-6, 7, 2)) # −6 to +6 by 2 (need list() in 3.X)
>[−6, −4, −2, 0, 2, 4, 6]
>>> [[x**2, x ** 3] for x in range(4)]
>[[0, 0], [1, 1], [4, 8], [9, 27]]
>>> [[x, x / 2, x * 2] for x in range(−6, 7, 2) if x > 0]
[[2, 1, 4], [4, 2, 8], [6, 3, 12]]As a preview, though, you’ll find that in recent Pythons, comprehensions syntax has been generalized for other roles: it’s not just for making lists today. For example, enclosing a comprehension in a parentheses can also be used to create generators that produce results on demand.
>>> G = (sum(row) for row in M) # Create a generator of row sums
>>> next(G) # iter(G) not required here
6
>>> next(G) # Run the iteration protocol next()
>15
>>> next(G)
24The map built-in can do similar work, by generating the results of running iterms through a function, one at a time and on request. Like range, wrapping it in list forces it to return all its values in Python3.X; this isn’t needed in 2.X where map makes a list of results all at once instead, and is not needed in order contexts that iterate automatically, unless multiple scans or list-like behavior is also required:
>>> list(map(sum, M)) # Map sum over items in M
[6, 15, 24]
>>> {sum(row) for row in M} # Create a set of row sums
{24, 6, 15}
>>> {i : sum(M[i]) for i in range(3)} # Creates key/value table of row sums
{0: 6, 1: 15, 2: 24}In fact, lists, sets, dictionaries, and generators can all be built with comprehensions in 3.X and 2.7:
>>> [ord(x) for x in 'spaam'] # List of character ordinals
[115, 112, 97, 97, 109]
>>> {ord(x) for x in 'spaam'} # Sets remove duplicates
{112, 97, 115, 109}
>>> {x: ord(x) for x in 'spaam'} # Dictionary keys are unique
{'p': 112, 'a': 97, 's': 115, 'm': 109}
>>> (ord(x) for x in 'spaam') # Generator of values
at 0x000000000254DAB0> 1-5) Dictionaries
Dictionaries are instead known as mapping. Mappings are also collections of other objects, but they store objects by key instead of by relative position.
1-5-1) Mapping Operations
>>> D = {'food': 'Spam', 'quantity': 4, 'color': 'pink'}
>>> D['food'] # Fetch value of key 'food' 'Spam'
>>> D['quantity'] += 1 # Add 1 to 'quantity' value
>>> D
{'color': 'pink', 'food': 'Spam', 'quantity': 5}Although the curly-braces literal form does see use, it is perhaps more common to see dictionaries built up in different ways. The following code, for example, starts with an empty dictionary and fills it out one key at a time. Unlike out-of-bounds assignments in lists, which are forbidden, assignments to new dictionary keys create those keys:
>>> D = {}
>>> D['name'] = 'Bob' # Create keys by assignment
>>> D['job'] = 'dev'
>>> D['age'] = 40
>>> D
{'age': 40, 'job': 'dev', 'name': 'Bob'}
>>> print(D['name']) BobWe can also make dictionaries by passing to the dict type name ether keyword arguments or the result of zipping together sequences of keys and values obtained at runtime.
>>> bob1 = dict(name='Bob', job='dev', age=40) # Keywords
>>> bob1
{'age': 40, 'name': 'Bob', 'job': 'dev'}
>>> bob2 = dict(zip(['name', 'job', 'age'], ['Bob', 'dev', 40])) # Zipping
>>> bob2
{'job': 'dev', 'name': 'Bob', 'age': 40}Notice how the left-to-right order of dictionary keys is scrambled. Mappings are not positionally ordered.
1-5-2) Nesting Revisited
>>> rec = {'name': {'first': 'Bob', 'last': 'Smith'}, 'jobs': ['dev', 'mgr'],
'age': 40.5}
>>> rec['name']
>{'last': 'Smith', 'first': 'Bob'}
>>> rec['name']['last']
'Smith'
>>> rec['jobs'].append('janitor')
>>> rec
{'age': 40.5, 'jobs': ['dev', 'mgr', 'janitor'], 'name': {'last': 'Smith', 'first': 'Bob'}}
>>> rec = 0 # Now the object's space is reclaimed1-5-3) Missing Keys: if Tests
Although we can assign to a new key to expand a dictionary, fetching a nonexistent key is still a mistake:
>>> D = {'a': 1, 'b': 2, 'c': 3}
>>> D
{'a': 1, 'c': 3, 'b': 2}
>>> D['e'] = 99 # Assigning new keys grows dictionaries
>>> D
{'a': 1, 'c': 3, 'b': 2, 'e': 99}
>>> D['f'] # Referencing a nonexistent key is an error
...error text omitted...
KeyError: 'f'
>>> 'f' in D
False
>>> if not 'f' in D: # Python's sole selection statement
print('missing')
missingBesides the in test, there are a variety of ways to avoid accessing nonexistent keys in the dictionaries we create: the get method, a conditional index with a default; the Python 2.X has_key method, an in work-alike that is no longer available in 3.X;
>>> value = D.get('x', 0)
>>> value
0
>>> value = D['x'] if 'x' in D else 0
>>> value
01-5-4) Sorting Keys: for Loops
As mentioned earlier, because dictionaries are not sequences, they don’t maintain any dependable left-to-right order. If we make a dictionary and print is back, its keys may come back in a different order than that in which we type them, and may vary per Python version and other variables:
>>> D = {'a': 1, 'b': 2, 'c': 3}
>>> D
{'a': 1, 'c': 3, 'b': 2}
>>> Ks = list(D.keys()) # Unordered keys list
>>> Ks
['a', 'c', 'b']
>>> Ks.sort() # Sorted keys list
>>>> Ks
['a', 'b', 'c']
>>> for key in Ks: # Iterate though sorted keys
print(key, '=>', D[key]) # <== press Enter twice here (3.X print)
a => 1 b => 2 c => 3This is a three-step process, although, as we’ll see in later chapters, in recent versions of Python it can be done in one step with the newer sorted built-in function. The sorted call returns the result and sorts a variety of object types, in this case sorting dictionary keys automatically:
>>> D
{'a': 1, 'c': 3, 'b': 2}
>>> for key in sorted(D):
print(key, '=>', D[key])
a => 1
b => 2
c => 31-5-5) Iteration and Optimization
Formally, both types of objects are considered iterable because they support the iteration protocol – they respond to the iter call with an object that advances in response to next calls and raises an exception when finished producing values.
The generator comprehension expression we saw earlier is such an object: its values aren’t stored in memory all at once, but are produced as requested, usually by iteration tools. Python file objects similarly iterate line by line when used by an iteration tool: file content isn’t in a list, it’s fetched on demand. Both are iterable objects in Python – a category that expands in 3.X to include core tools like range and map.
Keep in mind that every Python tool that scans on object from left to right uses the iteration protocol. This is why the sorted call used in the prior section works on the dictionary directly– we don’t have to call the keys method to get a sequence because dictionaries are iterable objects, with a next that returns successive keys.
It may also help you to see that any list comprehension expression, such as this one, which computes the squares of a list of numbers:
>>> squares = [x ** 2 for x in [1, 2, 3, 4, 5]]
>>> squares
[1, 4, 9, 16, 25]A major rule of thumb in Python is to code for simplicity and readability first and worry about performance later, after your program is working, and after you’ve proved that there is a genuine performance concern. More often than not, your code will be quick enough as it is. If you do need to tweak code for performance, though, Python includes tools to help you out, including the time and itmeit modules for timing the speed of alternative, and the profile module for isolating bottlenecks.
1-6) Tuples
The tuple object is roughly like a list that cannot be changed – tuples are sequences, like lists, but they are immutable, like strings. Functionally, they’re used to represent fixed collections of items. the components of a specific calendar date, for instance. Syntactically, they are normally coded in parentheses instead of square brackets, and they support arbitrary types, arbitrary nesting, and the usual sequence operations:
>>> T = (1, 2, 3, 4)
>>> len(t)
4
>>> T + (5, 6)
(1, 2, 3, 4, 5, 6)
>>> T[0]
1The primary distinction for tuples is that they cannot be changed once created. That is, they are immutable sequences (one-item tuples like the one here require a trailing comma):
>>> T[0] = 2 # Tuples are immutable
...error text omitted...
TypeError: 'tuple' object does not support item assignment
>>> T = (2,) + T[1:] # Make a new tuple for a new value
>>> T
(2, 2, 3, 4)1-7) Files
File objects are Python code’s main interface to external files on your computer. There is no literal syntax for creating them. Rather, to create a file object, you call the built-in open function, passing an external filename and an optional processing mode as strings.
>>> f = open('data.txt', 'w')
>>> f.write('Hello\n')
6
>>> f.write('world\n')
6
>>> f.close()
>>> f = open('data.txt')
>>> text = f.read()
>>> text
'Hello\nworld\n'
>>> print(text)
Hello
world
>>> text.split()
['Hello', 'world']
>>> for line in open('data.txt'):
print(line)1-7-1) Binary Bytes Files
The prior section’s examples illustrate file basics that suffice for many roles. Techni- cally, though, they rely on either the platform’s Unicode encoding default in Python 3.X, or the 8-bit byte nature of files in Python 2.X. Text files always encode strings in 3.X, and blindly write string content in 2.X. This is irrelevant for the simple ASCII data used previously, which maps to and from file bytes unchanged. But for richer types of data, file interfaces can vary depending on both content and the Python line you use.
As hinted when we met strings earlier, Python 3.X draws a sharp distinction between text and binary data in files: text files represent content as normal str strings and per- form Unicode encoding and decoding automatically when writing and reading data, while binary files represent content as a special bytes string and allow you to access file content unaltered. Python 2.X supports the same dichotomy, but doesn’t impose it as rigidly, and its tools differ
>>> import struct
# Create packed binary data
>>> packed = struct.pack('>i4sh', 7, b'spam', 8)
>>> packed # 10 bytes, not objects or text
b'\x00\x00\x00\x07spam\x00\x08'
>>> file = open('data.bin', 'wb') # Open binary output file
>>> file.write(packed) # Write packed binary data
10
>>> file.close()
>>> data = open('data.bin', 'rb').read()
>>> data b'\x00\x00\x00\x07spam\x00\x08'
>>> data[4:8]
b'spam'
>>> list(data)
[0, 0, 0, 7, 115, 112, 97, 109, 0, 8]
>>> struct.unpack('>i4sh', data) # Unpack into objects again
(7, b'spam', 8)1-7-2) Unicode Text files
Text files are used to process all sort of text-based data, from memos to email content to json and xml documents.
Luckily, this is easier than it may sound. To access files containing non-ASCII Unicode text of the sort introduced earlier in this chapter, we simply pass in an encoding name if the text in the file doesn’t match the default encoding for our platform. In this mode, Python text files automatically encode on writes and decode on reads per the encoding scheme name you provide. In Python 3.X:
>>> S = 'sp\xc4m' # Non-ASCII Unicode text
>>> S
'spÄm'
>>> S[2] # Sequence of characters
'Ä'
# Write/encode UTF-8 text
>>> file = open('unidata.txt', 'w', encoding='utf-8')
>>> file.write(S) # 4 characters written
4
>>> file.close()
# Read/decode UTF-8 text
>>> text = open('unidata.txt', encoding='utf-8').read()
>>> text
'spÄm'
>>> len(text) # 4 chars (code points)
4This automatic encoding and decoding is what you normally want. Because files handle this on transfers, you may process text in memory as a simple string of characters without concern for its Unicode-encoded origins. If needed, though, you can also see what’s truly stored in your file by stepping into binary mode:
>>> raw = open('unidata.txt', 'rb').read() # Read raw encoded bytes
>>> raw
b'sp\xc3\x84m'
>>> len(raw) # Really 5 bytes in UTF-8 5You can also encode and decode manually if you get Unicode data from a source other than a file – parsed from an email message or fetched over a network connection, for example:
>>> text.encode('utf-8') # Manual encode to bytes b'sp\xc3\x84m'
>>> raw.decode('utf-8') # Manual decode to str
'spÄm'This all works more or less the same in Python 2.X, but Unicode strings are coded and display with a leading “u,” byte strings don’t require or show a leading “b,” and Unicode text files must be opened with codecs.open, which accepts an encoding name just like 3.X’s open, and uses the special unicode string to represent content in memory. Binary file mode may seem optional in 2.X since normal files are just byte-based data, but it’s required to avoid changing line ends if present
>>> import codecs
# 2.X: read/decode text
>>> codecs.open('unidata.txt', encoding='utf8').read() u'sp\xc4m'
# 2.X: read raw bytes
>>> open('unidata.txt', 'rb').read()
'sp\xc3\x84m'
# 2.X: raw/undecoded too
>>> open('unidata.txt').read()
'sp\xc3\x84m'1-8) Other Core Types
Beyond the core types we’ve seen so far, there are others that may or may not qualify for membership in the category, depending on how broadly it is defined. Sets, for ex- ample, are a recent addition to the language that are neither mappings nor sequences; rather, they are unordered collections of unique and immutable objects. You create sets by calling the built-in set function or using new set literals and expressions in 3.X and 2.7, and they support the usual mathematical set operations (the choice of new {…} syntax for set literals makes sense, since sets are much like the keys of a valueless dic- tionary):
>>> X = set('spam')
>>> Y = {'h', 'a', 'm'}
>>> X, Y # A tuple of two sets without parentheses
({'m', 'a', 'p', 's'}, {'m', 'a', 'h'})
>>> X & Y # Intersection
{'m', 'a'}
>>> X | Y # Union
{'m', 'h', 'a', 'p', 's'}
>>> X - Y # Difference
{'p', 's'}
>>> X > Y # Superset False
>>> {n ** 2 for n in [1, 2, 3, 4]} # Set comprehensions in 3.X and 2.7
{16, 1, 4, 9}In addition, Python recently grew a few new numeric types: decimal numbers, which are fixed-precision floating-point numbers, and fraction numbers, which are rational numbers with both a numerator and a denominator. Both can be used to work around the limitations and inherent inaccuracies of floating-point math:
>>> 1 / 3
0.3333333333333333
>>> (2/3) + (1/2)
1.1666666666666665
>>> import decimal
>>> d = decimal.Decimal('3.141')
>>> d + 1
Decimal('4.141')
# Floating-point (add a .0 in Python 2.X)
# Decimals: fixed precision
>>> decimal.getcontext().prec = 2
>>> decimal.Decimal('1.00') / decimal.Decimal('3.00') Decimal('0.33')
>>> from fractions import Fraction >>> f = Fraction(2, 3)
>>> f + 1
Fraction(5, 3)
>>> f + Fraction(1, 2) Fraction(7, 6)1-8-1) How to break your code’s flexibility
The type object, returned by the type built-in function, is an object that gives the type of another object; its result differs slightly in 3.X, because types have merged with classes completely. Assuming L is still the list of the prior section:
# In Python 2.X:
>>> type(L) # Types: type of L is list type object
<type 'list'>
>>> type(type(L)) # Even types are objects
<type 'type'>
# In Python 3.X:
>>> type(L) # 3.X: types are classes, and vice versa
<class 'list'>
>>> type(type(L))
<class 'type'>Besides allowing you to explore your objects interactively, the type object in its most practical application allows code to check the types of the object it processes. In fact, there are at least three ways to do so in a Python script:
>>> if type(L) == type([]): # Type testing, if you must...
print('yes')
yes
>>> if type(L) == list: # Using the type name
print('yes')
yes
>>> if isinstance(L, list): # Object-oriented tests
print('yes')
yes2) Statements and Syntax
2-1) Introducing Python Statements
| Statement | Role | Example |
|---|---|---|
| Assignment | Creating references | a, b = ‘good’, ‘bad’ |
| Calls and other expressions | Running functions | log.write(“spam, ham”) |
| print calls | Printing objects | print(‘The Killer’, joke) |
| if/elif/else | Selecting actions | if “python” in text: print(text) |
| for/else | Iteration | for x in mylist: print(x) |
| while/else | General loops | while X > Y: print(‘hello’) |
| pass | Empty placeholder | while True: pass |
| break | Loop exit | while True: if exittest(): break |
| continue | Loop continue | while True: if skiptest(): continue |
| def | Functions and methods | def f(a, b, c=1, *d): print(a+b+c+d[0]) |
| return | Functions results | def f(a, b, c=1, *d): return a+b+c+d[0] |
| yield | Generator functions | def gen(n): for i in n: yield i*2 |
| global | Namespaces | x = 'old' def function(): global x,y;x = 'new' |
| nonlocal | Namespaces (3.X) | def outer(): x = 'old' def function(): nonlocal x; x = 'new' |
| import | Module access | import sys |
| from | Attribute access | from sys import stdin |
| class | Building objects | class Subclass(Superclass): staticData = [] def method(self): pass |
| try/except/ finally | Catching exceptions | try: action() except: print('action error') |
| raise | Triggering exceptions | raise EndSearch(location) |
| assert | Debugging checks | assert X > Y, ‘X too small’ |
| with/as | Context managers (3.X, 2.6+) | with open('data') as myfile: process(myfile) |
| del | Deleting references | del data[k] |
2-2) Iterations and Comprehensions
2-2-1) The Iteration Protocol: File Iterators
One of the easiest ways to understand the iteration protocol is to see how it works with the built-in type such as the file. In this chapter, we’ll be using the following input file to demonstrate:
>>> print(open('script2.py').read())
import sys
print(sys.path) x =2
print(x ** 32)
>>> open('script2.py').read()
'import sys\nprint(sys.path)\nx = 2\nprint(x ** 32)\n'Following codes that open file objects have a method called readline, which reads one line of next from a file at a time – each time we call the readline method, we advance to the next line. At the end of the file, an empty string is returned, which we can detect to break out of the loop:
>>> f = open('script2.py')
>>> f.readline()
'import sys\n'
>>> f.readline()
'print(sys.path)\n'
>>> f.readline()
'x = 2\n'
>>> f.readline()
'print(x ** 32)\n'
>>> f.readline()However, file also have a method named next in 3.X (and next in 2.X) that has a nearly identical effect – it returns the next line from a file each time it is called. The only noticeable difference is that next raises a built-in StopIteration exception at end-of-file instead of returning an empty string:
>>> f = open('script2.py') # __next__ loads one line on each call too
>>> f.__next__() # But raises an exception at end-of-file
'import sys\n'
>>> f.__next__() ' # Use f.next() in 2.X, or next(f) in 2.X or 3.X
print(sys.path)\n'
>>> f.__next__()
'x = 2\n'
>>> f.__next__()
'print(x ** 32)\n'
>>> f.__next__()
Traceback (most recent call last):
File "" , line 1, in StopIteration This interface is most of what we call the iteration protocol in Python. Any object with a next method to advance to next result, which raises StopIteration exception at the end of the series of results, is considered an iterator in Python.
The net effect of this magic is that, the best way to read a text file line by line today is not read it at all – instead, allow the for loop to automatically call next to advance to the next line on each iteration.
>>> for line in open('script2.py'):
... print(line.upper(), end='')
...
IMPORT SYS
PRINT(SYS.PATH) X =2
PRINT(X ** 32)Notice that the print use end=” here to suppress adding a ‘\n’, because line strings already have one. This is considered the best way to read text file line by line today, for three reasons: it’s the simplest to code, might be the quickest to run, and is the best in terms of memory usage. The older, original way to achieve the same effect with a for loop is to call the file readlines method to load the file’s content into memory as a list of line strings:
>>> for line in open('script2.py').readlines():
... print(line.upper(), end='')
...
IMPORT SYS
PRINT(SYS.PATH) X =2
PRINT(X ** 32)This readlines technique still works but is not considered the best practice today and performs poorly in terms of memory usage. In fact, because this version really does load the entire file into memory all at once, it will not even work for files too big to fit into the memory space available on your computer.
2-2-2) The full iteration protocol
It’s really based on two objects, used in two distinct steps by iteration tools:
- The iterable object you request iteration for, whose iter is run by iter
- The iteration object returned by the iterable that actually produces values during the iteration, whose next is run by next and raises StopIteration when finished producting results
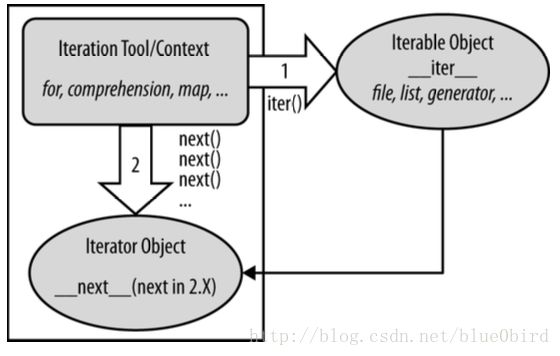
In actual code, the protocol’s first step becomes obvious if we look at how for loops internally process built-in sequence types such as lists:
>>> L = [1, 2, 3]
>>> I = iter(L) # Obtain an iterator object from an iterable
>>> I.__next__() # Call iterator's next to advance to next item
1
>>> I.__next__()
2
>>> I.__next__()
3
...error next omiited ...
StopIteration2-2-3) List Comprehensions: A First Detailed Look
We use range to change a list as we step across it:
>>> L = [1, 2, 3, 4, 5]
>>> for i in range(len(L)):
L[i] += 10
>>> L
[11, 12, 13, 14, 15]This works, but it may not be the optimal “best practice” approach in Python. Today, the list comprehension expression makes many such prior coding patterns obsolete.
>>> L= [x+10 for x in L]
>>> L
[21, 22, 23, 24, 25]2-2-4) List Comprehensions Basics
To run the expression, Python executes an iteration across L inside the interpreter, assigning x to each item in turn, and collects the results of running the items through the expression on the left side.
Technically speaking, list comprehensions are never really required because we can always build up a list of expression results manually with for loops that append results as we go:
>>> res = []
>>> for x in L:
... res.append(x + 10)
...
>>> res
[31, 32, 33, 34, 35]In fact, this is exactly what the list comprehension does internally.
However, list comprehensions are more concise to write, and because this pattern of building up a list is so common in Python work, they turn out to be very useful in many contexts. Moreover, depending on your Python and code, list comprehensions might much faster than manual for loop statements (often roughly twice as fast) because their iterations are performed at C language speed inside the interpreter, rather than with manual Python code. Especially for larger data sets, there is often a major performance advantage to using this expression.
2-2-4) Using List Comprehensions on Files
Anytime we start thinking about performing an operations on each item in a sequence, we’re in the realm of list comprehensions.
>>> lines = [line.rstrip() for line in lines]
>>> lines
['import sys', 'print(sys.path)', 'x=2', 'print(x ** 32)']we don’t have to open the file ahead of time. If we open it inside the expression, the list comprehension will automatically use the iteration protocol.
>>> lines = [line.rstrip() for line in open('script2.py')]
>>> lines
['import sys', 'print(sys.path)', 'x = 2', 'print(x ** 32)']
>>> [line.upper() for line in open('script2.py')]
['IMPORT SYS\n', 'PRINT(SYS.PATH)\n', 'X = 2\n', 'PRINT(X ** 32)\n']
>>> [line.rstrip().upper() for line in open('script2.py')] ['IMPORT SYS', 'PRINT(SYS.PATH)', 'X = 2', 'PRINT(X ** 32)']
>>> [line.split() for line in open('script2.py')]
[['import', 'sys'], ['print(sys.path)'], ['x', '=', '2'],['print(x', '**', '32)']]
>>> [line.replace(' ', '!') for line in open('script2.py')] ['import!sys\n', 'print(sys.path)\n', 'x!=!2\n', 'print(x!**!32)\n']
>>> [('sys' in line, line[:5]) for line in open('script2.py')] [(True, 'impor'), (True, 'print'), (False, 'x = 2'), (False, 'print')]2-2-5) Extended List Comprehension Syntax
2-2-5-1) Filter clauses: if
As one particularly useful extension, the for loop nested in a comprehension expression can have an associated if clause to filter out of the result items for which the test is not true.
>>> lines = [line.rstrip() for line in open('script2.py') if line[0] == 'p']
lines
['print(sys.path)', 'print(x ** 32)']2-2-5-2) Nested loops: for
List comprehension can become even more complex if we need them to – for instance, they may contain nested loops, coded as a series of for clauses. In fact, their full syntax allows for any number of for clauses, each of which can have an optional associated if clause.
>>> [x + y for x in 'abc' for y in 'lmn']
['al', 'am', 'an', 'bl', 'bm', 'bn', 'cl', 'cm', 'cn']3) The Documentation interlude
3-1) Python Documentation Sources
One of the first questions that bewildered beginners often ask is: how do I find information on all the built-in tools? This section provides hints on the various documentation sources available in Python. It also presents documentation strings (docstrings) and the PyDoc system that make use of them.
Python documentation sources
| Tables | Are |
|---|---|
| comments | In-file documentation |
| The dir function | Lists of attributes available in objects |
| Docstrings: doc | In-file documentation attached to objects |
| PyDoc: thehelpfunction | Interactive help for objects |
| PyDoc: HTML reports | Module documentation in a browser |
| Sphinx third-party tool | Richer documentation for larger projects |
| The standard manual set | Official language and library descriptions |
| Web resources | Online tutorials, examples, and so on |
| Published books | Commercially polished reference texts |
3-2) # Comments
As we’ve learned, hash-mark comments are the most basic way to document your code.
3-3) The dir Function
As we’ve also seen, the built-in dir function is an easy way to grab a list of all the attributes available inside on object. It can be called with no arguments to list variables in the caller’s scope. More usefully, it can also be called on object that has attributes, including imported modules and built-in types, as well as the name of a data type.
>>> import sys
>>> dir(sys)
['__displayhook__', ...more names omitted..., 'winver']Notice that you can list built-in type attributes by passing a type name to dir instead of a literal:
>>> dir(str) == dir('') # Same result, type name or literal True
>>> dir(list) == dir([])
TrueThis works because names like str and list that were once type converter functions are actually names of types in Python today; calling one of these invokes its constructor to generate an instance of that type.
3-4) Docstrings: doc
Besides # comments, Python supports documentation that is automatically attached to objects and retained at runtime for inspection. Syntactically, such comments are coded as strings at the tops of module files and function and class statements, before any other executable code (# comments, including Unix-stye #! lines are OK before them). Python automatically stuffs the text of these strings, known informally as docstrings, into the doc attributes of the corresponding objects.
3-4-1) User-defined docstrings
Its docstrings appear at the beginning of the file and at the start of a function and a class within it. Here, I’ve used triple-quoted block strings for multiline comments in the file and the function, but any sort of string will work; single- or double-quoted one-liners like those in the class are fine, but don’t allow multiple-line text. We haven’t studied the def or class statements in detail yet, so ignore everything about them here except the strings at their tops:
"""
Module documentation Words Go Here
"""
spam = 40
def square(x):
"""
function documentation
can we have your liver then?
"""
return x ** 2
class Employee:
"class documentation"
pass
print(square(4))
print(square.__doc__)The whole point of this documentation protocol is that your comments are retained for inspection in doc attributes after the file is imported.
>>> import docstrings
function documentation
can we have your liver then?
>>> print(docstrings.__doc__)
Module documentation
Words Go Here
>>> print(docstrings.square.__doc__)
function documentation
>>> print(docstrings.Employee.__doc__)
class documentation
3-4-2) Built-in docstrings
As it turns out, built-in modules and objects in Python use similar techniques to attach documentation above and beyond the attribute lists returned by dir. For example, to see an actual human-readable description of a built-in module, import it and print its doc string:
>>> import sys
>>> print(sys.__doc__)
This module provides access to some objects used or maintained by the interpreter and to functions that interact strongly with the interpreter.
Dynamic objects:
argv -- command line arguments; argv[0] is the script pathname if known path -- module search path; path[0] is the script directory, else '' modules -- dictionary of loaded modules
...more text omitted...Functions, classes, and methods within built-in modules have attached descriptions in their doc attributes as well:
>>> print(sys.getrefcount.__doc__) getrefcount(object) -> integer
Return the reference count of object. The count returned is generally one higher than you might expect, because it includes the (temporary) reference as an argument to getrefcount().3-5) PyDoc: The help Function
The docstring technique proved to be so useful that Python eventually added a tool that makes docstrings even easier to display. The standard PyDoc tool is Python code that knows how to extract docstrings and associated structural information and format them into nicely arranged reports of various types.
There are a variety of ways to launch PyDoc, including command-line script options that can save the resulting documentation for later viewing. Perhaps the two most prominent PyDoc interfaces are the built-in help function and the PyDoc GUI and web-based HTML report interfaces.
>>> import sys
>>> help(sys.getrefcount)
Help on built-in function getrefcount in module sys:
getrefcount(...)
getrefcount(object) -> integer
Return the reference count of object. The count returned is generally one higher than you might expect, because it includes the (temporary) reference as an argument to getrefcount().Note that you do not have to import sys in order to call help, but you do have to import sys to get help on sys this way; it expects an object reference to be passed in. In Pythons 3.3 and 2.7, you can get help for a module you have not imported by quoting the module’s name as a string – for example, help(‘re’), help(‘email.message’) – but support for this and other modes may differ across Python versions.
For larger objects such as modules and classes, the help display is break down into multiple sections, the preambles of which are shown here. Run this interactively to see the full report:
>>> help(sys)
Help on built-in module sys:
NAME
sys
MODULE REFERENCE
http://docs.python.org/3.3/library/sys
...more omitted...
DESCRIPTION
This module provides access to some objects used or maintained by the interpreter and to functions that interact strongly with the interpreter.
...more omitted...
FUNCTIONS
__displayhook__ = displayhook(...)
displayhook(object) -> None
...more omitted...
DATA
__stderr__ = <_io.TextIOWrapper name='' mode='w' encoding='cp4...
__stdin__ = <_io.TextIOWrapper name='<stdin>' mode='r' encoding='cp437...
__stdout__ = <_io.TextIOWrapper name='' mode='w' encoding='cp4... ...more omitted...
FILE
(built-in)Some of the information in this report is docstrings, and some of if (e.g., function call patterns) is structural information that PyDoc gleans automatically by inspecting objects’ internals, when available.
Besides modules, you can also use help on built-in functions, methods, and types. Usage varies slightly across Python versions, but to get help for a built-in type, try either the type name (e.g., dict for dictionary, str for string, list for list); an actual object of the type (e.g., {}, ”, []); or a method of an actual object or type name (e.g., str.join, ‘s’.join).
3-6) PyDoc: HTML Reports
The text displays of the help function are adequate in many contexts, especially at the interactive prompt. To readers who’ve grown accustomed to richer presentation mediums, though, they may seem a bit primitive. This section presents the HTML-based flavor of PyDoc, which renders module documentation more graphically for viewing in a web browser. and can even open one automatically for you. The way this is run has changed as of Python 3.3:
- Prior to 3.3, Python ships with a simple GUI desktop client for submitting search requests. This client launches a web browser to view documentation produced by an automatically started local server.
- As of 3.3, the former GUI client is replaced by an all-browser interface scheme, which combines both search and display in a web page that communicates with an automatically started local server.
3-6-1) Python 3.2 and later: PyDoc’s all-browser mode
As of Python 3.3 the original GUI client mode of PyDoc, present in 2.X and earlier 3.X releases, is no longer available. This mode is present through Python 3.2 with the “Module Docs” Start button entry on Windows 7 and earlier, and via the pydoc -g command line. This GUI mode was reportedly deprecated in 3.2, though you had to look closely to notice – it works fine and without warning on 3.2.
In 3.3, though, this mode goes away altogether, and is replaced with a pydoc -b command line, which instead spawns both a locally running documentation server, as well as a web browser that functions as both search engine client and page display.
To launch the newer browser-only mode of PyDoc in Python 3.2 and later, a command line like any of the following suffice: they all use the -m Python command-line argument for convenience to locate PyDoc’s module file on your module import search path.
c:\code> python -m pydoc -b
Server ready at http://localhost:62135/ Server commands: [b]rowser, [q]uit server> q
Server stopped
c:\code> py −3 -m pydoc -b
Server ready at http://localhost:62144/ Server commands: [b]rowser, [q]uit server> q
Server stopped
c:\code> C:\python33\python -m pydoc -b Server ready at http://localhost:62153/ Server commands: [b]rowser, [q]uit server> q
Server stopped
3-6-2) Python 3.2 and earlier: GUI client
c:\code> c:\python32\python -m pydoc -g # Explicit Python path
c:\code> py −3.2 -m pydoc -g
On Pythons 3.2 and 2.7, I had to add “.” to my PYTHONPATH to get PyDoc’s GUI client mode to look in the directory it was started from by command line:
c:\code> set PYTHONPATH=.;%PYTYONPATH%
c:\code> py −3.2 -m pydoc -g3-7) Beyond docstrings: Sphinx
If you’re looking for a way to document your Python system in a more sophisticated way, you may wish to check out Sphinx ((currently at http://sphinx-doc.org))
4) Functions and Generators
4-1) Function Basics
Functions are the alternative to programming by cutting and pasting – rather than having multiple redundant copies of an operation’s code, we can factor it into a single function. In so doing, we reduce our future work radically: if the operation must be changed later, we have only one copy to update in the function, not many scattered throughout the program.
4-2) Coding Functions
Here is a brief introduction to the main concepts behind Python functions:
- def is executable code. Python functions are written with a new statement, the def. Unlike functions in compiled languages such as C, def is an executable state- ment—your function does not exist until Python reaches and runs the def. In fact, it’s legal (and even occasionally useful) to nest def statements inside if statements, while loops, and even other defs. In typical operation, def statements are coded in module files and are naturally run to generate functions when the module file they reside in is first imported.
- def creates an object and assigns it to a name. When Python reaches and runs a def statement, it generates a new function object and assigns it to the function’s name. As with all assignments, the function name becomes a reference to the func- tion object. There’s nothing magic about the name of a function—as you’ll see, the function object can be assigned to other names, stored in a list, and so on. Function objects may also have arbitrary user-defined attributes attached to them to record data.
- lambda creates an object but returns it as a result. Function may also be created with the lambda expression, a feature that allows us to in-line function definitions in places where a def statement won’t work syntactically.
- return sends a result object back to the caller. When a function is called, the caller stops until the function finishes its work and returns control to the caller. Functions that compute a value send it back to the caller with a return statement; the returned value becomes the result of the function call. A return without a value simply returns to the caller (and sends back None, the default result).
- yield sends a result object back to the caller, but remembers where it left off. Functions known as generators may also use the yield statement to send back a value and suspend their state such that they may be resumed later, to produce a series of results over time.
- global declares module-level variables that are to be assigned. By default, all names assigned in a function are local to that function and exist only while the function runs. To assign a name in the enclosing module, functions need to list it in a global statement. More generally, names are always looked up in scopes— places where variables are stored—and assignments bind names to scopes.
- nonlocal declares enclosing function variables that are to be assigned. Simi- larly, the nonlocal statement added in Python 3.X allows a function to assign a name that exists in the scope of a syntactically enclosing def statement. This allows enclosing functions to serve as a place to retain state—information remembered between function calls—without using shared global names.
- Arguments are passed by assignment (object reference). In Python, arguments are passed to functions by assignment (which, as we’ve learned, means by object reference). As you’ll see, in Python’s model the caller and function share objects by references, but there is no name aliasing. Changing an argument name within a function does not also change the corresponding name in the caller, but changing passed-in mutable objects in place can change objects shared by the caller, and serve as a function result.
- Arguments are passed by position, unless you say otherwise. Values you pass in a function call match argument names in a function’s definition from left to right by default. For Flexibility, functions calls can also pass arguments by name with name=value keyword syntax, and unpack arbitrarily many arguments to send with *pargs and **kargs starred-arguments notation. Function definitions use the same two forms to specify argument defaults, and collect arbitrarily many arguments received.
- Arguments, return values, and variables are not declared. As with everything in Python, there are no type constraints on functions. In fact, nothing about a function needs to be declared ahead of time: you can pass in arguments of any type, return any kind of object, and so on. As one consequence, a single function can often be applied to a variety of object types—any objects that sport a compatible interface (methods and expressions) will do, regardless of their specific types.
4-2-1) def Statements
The def statement creates a function object and assigns it to a name. Its general format is as follows:
def name(arg1, arg2,... argN):
statements
def name(arg1, arg2,... argN):
...
return value4-2-2) def Executes at Runtime
if test:
def func(): # Define func this way
...
else:
def func(): # Or else this way
...
...
func() # Call the version selected and built
4-3) Scopes
4-3-1) Python Scope Basics
Now that you’re ready to start writing your own functions, we need to get more formal about what names mean in Python. When you use a name in a program, Python creates, changes, or looks up the name in what is known as a namespace – a place where names live. When we talk about the search for a name’s value in relation to code, the term scope refers to a namespace: that is, the location of a name’s assignment in your source code determines the scope of the name’s visibility to your code.
Just about everything related to names, including scope classification, happens at assignment time in Python. As we’ve seen, names in Python spring into existence when they are first assigned values, and they must be assigned before they are used. Because names are not declared ahead of time, Python uses the location of the assignment of a name to associate it with a particular namespace. In other words, the place where you assign a name in your source code determines the namespace it will live in, and hence its scope of visibility.
Besides packaging code for reuse, functions add an extra namespace layer to your pro- grams to minimize the potential for collisions among variables of the same name—by default, all names assigned inside a function are associated with that function’s namespace, and no other. This rule means that:
- Namesassignedinsideadefcanonlybeseenbythecodewithinthatdef.You cannot even refer to such names from outside the function.
- Names assigned inside a def do not clash with variables outside the def, even if the same names are used elsewhere. A name X assigned outside a given def (i.e., in a different def or at the top level of a module file) is a completely different variable from a name X assigned inside that def.
4-3-1-1) Scope Details
Before we started writing functions, all the code we wrote was at the top level of a module (i.e., not nested in a def), so the names we used either lived in the module itself or were built-ins predefined by Python (e.g., open). Technically, the interactive prompt is a module named main that prints results and doesn’t save its code; in all other ways, though, it’s like the top level of a module file.
Functions, though, provide nested namespaces (scopes) that localize the names they use, such that names inside a function won’t clash with those outside it (in a module or another function). Functions define a local scope and modules define a global scope with the following properties:
The enclosing module is a global scope. Each module is a global scope—that is, a namespace in which variables created (assigned) at the top level of the module file live. Global variables become attributes of a module object to the outside world after imports but can also be used as simple variables within the module file itself.
The global scope spans a single file only. Don’t be fooled by the word“global” here—names at the top level of a file are global to code within that single file only. There is really no notion of a single, all-encompassing global file-based scope in Python. Instead, names are partitioned into modules, and you must always import a module explicitly if you want to be able to use the names its file defines. When you hear “global” in Python, think “module.”
Assigned names are local unless declared global or . nonlocal. By default, all the names assigned inside a function definition are put in the local scope (the namespace associated with the function call). If you need to assign a name that lives at the top level of the module enclosing the function, you can do so by declaring it in a global statement inside the function. If you need to assign a name that lives in an enclosing def, as of Python 3.X you can do so by declaring it in a nonlocal statement.
All other names are enclosing function locals, globals, or built-ins. Names not assigned a value in the function definition are assumed to be enclosing scope locals, defined in a physically surrounding def statement; globals that live in the enclosing module’s namespace; or built-ins in the predefined built-ins module Python provides.
Each call to a function creates a new local scope. Every time you call a function, you create a new local scope—that is, a namespace in which the names created inside that function will usually live. You can think of each def statement (and lambda expression) as defining a new local scope, but the local scope actually cor- responds to a function call. Because Python allows functions to call themselves to loop
4-3-1-2) Name Resolution: The LEGB Rule
If the prior section sounds confusing, it really boils down to three simple rules. With a def statement:
- Name assignment create or change local names by default.
- Name reference search at most four scope: local, then enclosing functions (if any), then global, then built-in.
- Names declared in global and nonlocal statement map assigned names to enclosing module and function scopes, respectively.
Python’s name-resolution scheme is sometimes called the LEGB rule, after the scope name:
When you use a unqualified name inside a function, Python searches up to four scope – then local (L) scope, then the local scopes of any enclosing (E) defs and lambdas, then the global (G) scope, and then the built-in (b) scope – and stops at the first place the name is found. If the name is not found during this search, Python report an error.
When you assign a name in function (instead of just referring to it in an expression), Python always creates or changes the name in the local scope, unless it’s declared to be global or nonlocal in that function.

##### 4-3-1-2-1) Other Python scopes: Preview
Though obscure at this point in the book, there are technically three more scopes in Python – temporary loop variables in some comprehensions, exception reference variables in some try handlers, and local scopes in class statements. The first two of these special cases that rarely impact real code, and the third falls under the LEGB umbrella rule.
Comprehension variables—the variable X used to refer to the current iteration item in a comprehension expression such as [X for X in I]. Because they might clash with other names and reflect internal state in generators, in 3.X, such variables are local to the expression itself in all comprehension forms: generator, list, set, and dictionary. In 2.X, they are local to generator expressions and set and dictionary compressions, but not to list comprehensions that map their names to the scope outside the expression. By contrast, for loop statements never localize their variables to the statement block in any Python.
Exception variables—the variable X used to reference the raised exception in a try statement handler clause such as except E as X. Because they might defer garbage collection’s memory recovery, in 3.X, such variables are local to that except block, and in fact are removed when the block is exited (even if you’ve used it earlier in your code!). In 2.X, these variables live on after the try statement.
4-3-2) Scope Example
# Global scope
X = 99 # X and func assigned in module: global
def func(Y): # Y and Z assigned in function: locals
# Local scope
Z = X + Y # X is a global
return Z
func(1) # func in module: result=1004-3-3) The Built-in Scope
The built-in scope is just a built-in module called builtins, but you have to import builtins to query built-ins because the name builtins is not itself built in…
No, I’m serious! The built-in scope is implemented as a standard library module named builtins in 3.X, but that name itself is not placed in the built-in scope, so you have to import it in order to inspect it. Once you do, you can run a dir call to see which names are predefined. In Python 3.3 (see ahead for 2.X usage):
>>> import builtins
>>> dir(builtins)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning',
...many more names omitted...
'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']There are really two ways to refer to a built-in function—by taking advantage of the LEGB rule, or by manually importing the builtins module:
>>> zip # The normal way
<class 'zip'>
>>> import builtins # The hard way: for customizations
>>> builtins.zip
<class 'zip'>
>>> zip is builtins.zip # Same object, different lookups
True4-3-4) Scopes and Nested Functions
It’s time to take a deeper look at the letter E in the LEGB lookup rule. The E layer was added in Python 2.2; it takes the form of the local scopes of any and all enclosing function’s local scopes. Enclosing scopes are sometimes also called statically nested scopes. Really, the nesting is a lexical one – nested scopes correspond to physically and syntactically nested code structures in your program’s source code text.
4-3-4-1) Nested Scope Details
With the addition of nested functions scopes, variable lookup rules become slightly more complex. Within a function:
A reference (X) looks for the name x first int current local scope (function); then in then local scopes of . any lexically enclosing functions in your source code, from inner to outer; then in the current global scope (the module file); and finally in the built-in scope (the module builtins). global declarations make the search begin in the global (module file ) scope instead.
An assignment (X = value) creates or changes the name X in teh current local scope, by default. If x is declared global within the function, the assignment creates or changes the name X in the enclosing module’s scope instead. If, on the other hand, X is declared nonlocal within the function in 3.X (only), the assignment changes the name X in the closest enclosing function’s local scope.
4-3-4-2) Nested Scope Example
X = 99 # Global scope name: not used
def f1():
X = 88 # Enclosing def local
def f2():
print(X) # Reference made in nested def
f2()
f1() # Prints 88: enclosing def local4-3-4-3) Factory Functions: Closures
Depending on whom you ask, this sort of behavior is also sometimes called a closure or a factory function—the former describing a functional programming technique, and the latter denoting a design pattern. Whatever the label, the function object in question remembers values in enclosing scopes regardless of whether those scopes are still present in memory. In effect, they have attached packets of memory (a.k.a. state retention), which are local to each copy of the nested function created, and often provide a simple alternative to classes in this role.
A simple function factory
Factory functions (a.k.a. closures) are sometimes used by programs that need to generate event handlers on the fly in response to conditions at runtime.
>>> def maker(N):
def action(X): # Make and return action
return X ** N # action retains N from enclosing scope
return action
>>> f = maker(2) # Pass 2 to argument N
>>> f
.action at 0x0000000002A4A158>
>>> f(3) # Pass 3 to X, N remembers 2: 3 ** 2
9
>>> f(4) # 4 ** 2
16 4-4) Arguments
4-4-1) Argument-Passing Basics
This has a few ramifications that aren’t always obvious to newcomers, which I’ll expand on in this section. Here is a rundown of the key points in passing arguments to functions:
Arguments are passed by automatically assigning objects to local variable names. Function arguments—references to (possibly) shared objects sent by the caller—are just another instance of Python assignment at work. Because references are implemented as pointers, all arguments are, in effect, passed by pointer. Objects passed as arguments are never automatically copied.
Assigning to argument names inside a function does not affect the caller. Argument names in the function header become new, local names when the func- tion runs, in the scope of the function. There is no aliasing between function ar- gument names and variable names in the scope of the caller.
Changing a mutable object argument in a function may impact the caller. On the other hand, as arguments are simply assigned to passed-in objects, func- tions can change passed-in mutable objects in place, and the results may affect the caller. Mutable arguments can be input and output for functions.
Python’s pass-by-assignment scheme isn’t quite the same as C++’s reference parameter option, but it turns out to be very similar to the argument-passing model of the C language in practice:
Immutable arguments are effectively passed “by value”. Objects such as integers and strings are passed by object reference instead of by copying, but because you can’t change immutable objects in place anyhow, the effect is much like making a copy.
Mutable arguments are effectively passed “by pointer”. Objectssuchaslists and dictionaries are also passed by object reference, which is similar to the way C passes arrays as pointers—mutable objects can be changed in place in the function, much like C arrays.
4-4-1-1) Arguments and Shared References
To illustrate argument-passing properties at work, consider the following code:
>>> def f(a): # a is assigned to (references) the passed object
a = 99 # Changes local variable a only
>>> b = 88
>>> f(b) # a and b both reference same 88 initially
>>> print(b) # b is not changed
88
>>> def changer(a, b): # Arguments assigned references to objects
a= 2 # Changes local name's value only
b[0] = 'spam' # Changes shared object in place
>>> X = 1
>>> L = [1, 2] # Caller:
>>> changer(X, L) # Pass immutable and mutable objects
>>> X, L # X is unchanged, L is different!
(1, ['spam', 2])4-4-1-2) Avoiding Mutable Argument Changes
This behavior of in-place changes to mutable arguments isn’t a bug – it’s simple the way argument passing works in Python, and turns out to be widely useful in practice.
If we don’t want in-place changes within functions to impact objects we pass to them, though, we can simply make explicit copies of mutable objects.
L = [1, 2]
changer(X, L[:])We can also copy within the function itself, if we never want to change passed-in objects, regardless of how the function is called:
def changer(a, b):
b = b[:]
a = 2
b[0] = 'spam'Both of these coping schemes don’t stop the function from changing the object – they just prevent those changes from impacting the caller. To really prevent changes, we can always convert to immutable objects to force the issue. Tuples, for example, raise an exception when changes the attempted:
L = [1, 2]
changer(X, tuple(L)) # Pass a tuple, so changes are errors4-4-1-3) Simulating Output Parameters and Multiple Results
We’ve already discussed the return statement and used in a few examples. Here’s a another way to use this statement: because return can send back any sort of object, it can return multiple values by packing them in a tuple or other collection type. In fact, although doesn’t support what some language label “call by reference” argument passing, we can usually simulate it by returning tuples and assigning the results back to the original argument names in the caller:
>>> def multiple(x, y):
x = 2 # Changes local names only
y = [3, 4]
return x, y # Return multiple new values in a tuple
>>> X = 1
>>> L = [1, 2]
>>> X, L = multiple(X, L) # Assign results to caller's names
>>> X, L
(2, [3, 4])4-4-2) Special Argument-Matching Modes
By default, arguments are matched by position, from left to right, and you must pass exactly as many arguments as there are argument names in the function header. However, you can also specify matching by name, provide default values, and use collectors for extra arguments.
4-4-2-1) Argument Matching Basics
Positionals: matched from left to right
The normal case, which we’ve mostly been used so far, is to match passed argument values to argument names in a function header by position, from left to right.Keywords: matched by argument name
Alternatively, callers can specify which argument in the function is to receive a value by using the argument’s name in the call, with the name=value syntax.Defaults: specify values for optional arguments that aren’t passed
Functions themselves can specify default values for arguments to receive if the call passes too few values, again using the name=value syntax.Varargs Collecting: collect arbitrarily many positional or keyword arguments
Functions can use special arguments preceded with one or two * characters to collect an arbitrary number of possibly extra arguments. This feature is often referred to as varargs, after a variable-length argument list tool in the C language; in Python, the arguments are collected in a normal object.Varargs unpacking: pass arbitrary many positional or keyword arguments
Callers can also use the * syntax to unpack argument collections into separate arguments. This is the inverse of * in a function header – in the header it means collect arbitrarily many arguments, while in the call it means unpack arbitrarily many arguments, and pass them individually as discrete valueKeyword-only arguments: arguments that must be passed by name
In Python 3.X (but not 2.X), functions can also specify arguments that must be passed by name with keyword arguments, not by position. Such arguments are typically used to define configuration options in addition to actual arguments.
4-4-2-2) Argument Matching Syntax
summarizes the syntax that invokes the special argument-matching modes.
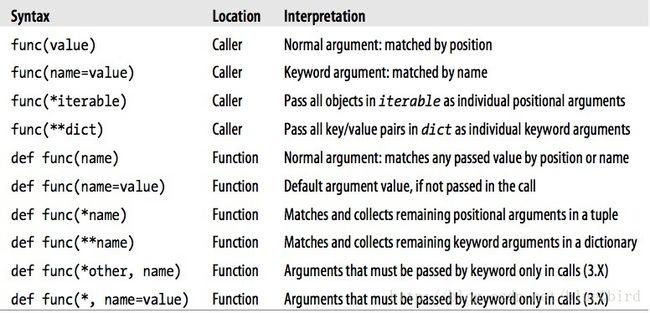
These special matching modes break down into function calls and definitions as follows:
In a function call (the first four rows of the table), simple values are matched by position, but using the name=value form tells Python to match by name to arguments instead; these are called keyword arguments. Using a *iterable or **dict in a call allows us to package up arbitrarily many positional or keyword objects in sequences (and other iterables) and dictionaries, respectively, and unpack them as separate, individual arguments when they are passed to the function.
In a function header (the rest of the table), a simple name is matched by position or name depending on how the caller passes it, but the name=value form specifies a default value. The name form collects any extra unmatched positional arguments in a tuple, and the **name form collects extra keyword arguments in a dictionary. In Python 3.X, any normal or defaulted argument names following a *name or a bare are keyword-only arguments and must be passed by keyword in calls.
4-4-2-3) The Gritty Details
If you choose to use and combine the special argument-matching modes, Python will ask you to follow these ordering rules among the modes’ optional components:
- In a function call, arguments must appear in this order: any positional arguments (value); followed by a combination of any keyword arguments (name=value) and the *iterable form; followed by the **dict form.
- In a function header, arguments must appear in this order: any normal arguments (name); followed by any default arguments (name=value); followed by the name (or in 3.X) form; followed by any name or name=value keyword-only arguments (in 3.X); followed by the **name form.
In both the call and header, the **args form must appear last if present. If you mix arguments in any other order, you will get a syntax error because the combinations can be ambiguous. The steps that Python internally carries out to match arguments before assignment can roughly be described as follows:
- Assign nonkeyword arguments by position.
- Assign keyword arguments by matching names.
- Assign extra nonkeyword arguments to *name tuple.
- Assign extra keyword arguments to **name dictionary.
- Assign default values to unassigned arguments in header.
4-4-3) Arbitrary Arguments Examples
The first use, in the function definition, collects unmatched positional arguments into a tuple:
>>> def f(*args): print(args)
>>> f()
()
>>> f(1)
(1,)
>>> f(1, 2, 3, 4)
(1, 2, 3, 4)The * feature is similar, but it only works for keyword arguments—it collects them into a new dictionary, which can then be processed with normal dictionary tools. In a sense, the * form allows you to convert from keywords to dictionaries, which you can then step through with keys calls, dictionary iterators, and the like (this is roughly what the dict call does when passed keywords, but it returns the new dictionary):
>>> def f(**args): print(args)
>>> f()
{}
>>> f(a=1, b=2)
{'a': 1, 'b': 2}Finally, function headers can combine normal arguments, the , and the * to imple- ment wildly flexible call signatures. For instance, in the following, 1 is passed to a by position, 2 and 3 are collected into the pargs positional tuple, and x and y wind up in the kargs keyword dictionary:
>>> def f(a, *pargs, **kargs): print(a, pargs, kargs)
>>> f(1, 2, 3, x=1, y=2)
1 (2, 3) {'y': 2, 'x': 1}4-4-3-1) Calls: Unpacking arguments
In all recent Python releases, we can use the * syntax when we call a function, too. In this context, its meaning is the inverse of its meaning in the function definition—it unpacks a collection of arguments, rather than building a collection of arguments. For example, we can pass four arguments to a function in a tuple and let Python unpack them into individual arguments:
>>> def func(a, b, c, d): print(a, b, c, d)
>>> args = (1, 2)
>>> args += (3, 4)
>>> func(*args) # Same as func(1, 2, 3, 4)
1 2 3 4Similarly, the ** syntax in a function call unpacks a dictionary of key/value pairs into separate keyword arguments:
>>> args = {'a': 1, 'b': 2, 'c': 3}
>>> args['d'] = 4
>>> func(**args) # Same as func(a=1, b=2, c=3, d=4)
1 2 3 4
>>> func(*(1, 2), **{'d': 4, 'c': 3}) # Same as func(1, 2, d=4, c=3)
1 2 3 4
>>> func(1, *(2, 3), **{'d': 4}) # Same as func(1, 2, 3, d=4)
1 2 3 4
>>> func(1, c=3, *(2,), **{'d': 4}) # Same as func(1, 2, c=3, d=4)
1 2 3 4
>>> func(1, *(2, 3), d=4) # Same as func(1, 2, 3, d=4)
1 2 3 4
>>> func(1, *(2,), c=3, **{'d':4}) # Same as func(1, 2, c=3, d=4)
1 2 3 44-4-4) Python 3.X Keyword-Only Arguments
Python 3.X generalizes the ordering rules in function headers to allow us to specify keyword-only arguments—arguments that must be passed by keyword only and will never be filled in by a positional argument. This is useful if we want a function to both process any number of arguments and accept possibly optional configuration options.
Syntactically, keyword-only arguments are coded as named arguments that may appear after *args in the arguments list. All such arguments must be passed using keyword syntax in the call. For example, in the following, a may be passed by name or position, b collects any extra positional arguments, and c must be passed by keyword only. In 3.X
>>> def kwonly(a, *b, c):
print(a, b, c)
>>> kwonly(1, 2, c=3)
1 (2,) 3
>>> kwonly(a=1, c=3)
1 () 3
>>> kwonly(1, 2, 3)
TypeError: kwonly() missing 1 required keyword-only argument: 'c'We can also use a * character by itself in the arguments list to indicate that a function does not accept a variable-length argument list but still expects all arguments following the * to be passed as keywords. In the next function, a may be passed by position or name again, but b and c must be keywords, and no extra positionals are allowed:
>>> def kwonly(a, *, b, c):
print(a, b, c)
>>> kwonly(1, c=3, b=2)
1 2 3
>>> kwonly(c=3, b=2, a=1)
1 2 3
>>> kwonly(1, 2, 3)
TypeError: kwonly() takes 1 positional argument but 3 were given
>>> kwonly(1)
TypeError: kwonly() missing 2 required keyword-only arguments: 'b' and 'c'4-5) Advanced Function Topics
This chapter introduces a collection of more advanced function-related topics: recursive functions, function attributes and annotation, the lambda expression, and functional programming tools such as map and filter.
4-5-1) functions Design Concepts
Here is a review of a few general guidelines for readers new to function design principles:
Coupling: use arguments for inputs and return for outputs.
Generally,you should strive to make a function independent of things outside of it. Arguments and return statements are often the best ways to isolate external dependencies to a small number of well-known places in your code.Coupling: use global variables only when truly necessary.
Global variables (i.e., names in the enclosing module) are usually a poor way for functions to com- municate. They can create dependencies and timing issues that make programs difficult to debug, change, and reuse.Coupling: don’t change mutable arguments unless the caller expects it.
Functions can change parts of passed-in mutable objects, but (as with global vari- ables) this creates a tight coupling between the caller and callee, which can make a function too specific and brittle.Cohesion: each function should have a single, unified purpose.
When designed well, each of your functions should do one thing—something you can summarize in a simple declarative sentence. If that sentence is very broad (e.g., “this function implements my whole program”), or contains lots of conjunctions (e.g., “this function gives employee raises and submits a pizza order”), you might want to think about splitting it into separate and simpler functions. Otherwise, there is no way to reuse the code behind the steps mixed together in the function.Size: each function should be relatively small.
This naturally follows from the preceding goal, but if your functions start spanning multiple pages on your display, it’s probably time to split them. Especially given that Python code is so concise to begin with, a long or deeply nested function is often a symptom of design problems. Keep it simple, and keep it short.Coupling: avoid changing variables in another module file directly.
In general though, you should strive to minimize external dependencies in functions and other program components. The more self-contained a function is, the easier it will be to understand, reuse, and modify.
4-5-2) Function Objects: Attributes and Annotations
Python functions are full-blown objects, stored in pieces of memory all their own. As such, they can be freely passed around a program and called indirectly. They also support operations that have little to do with calls at all—attribute storage and annotation.
4-5-2-1) Indirect Function Calls: “First Class” Objects
This is usually called a first-class object model; it’s ubiquitous in Python, and a necessary part of functional programming. We’ll explore this programming mode more fully in this and the next chapter; because its motif is founded on the notion of applying func- tions, functions must be treated as data.
There’s really nothing special about the name used in a def statement: it’s just a variable assigned in the current scope, as if it had appeared on the left of an = sign. After a def runs, the function name is simply a reference to an object—you can reassign that object to other names freely and call it through any reference:
>>> def echo(message): # Name echo assigned to function object
print(message)
>>> echo('Direct call') # Call object through original name
Direct call
>>> x = echo # Now x references the function too
>>> x('Indirect call!') # Call object through name by adding ()
Indirect call!Because arguments are passed by assigning objects, it’s just as easy to pass functions to other functions as arguments. The callee may then call the passed-in function just by adding arguments in parentheses:
>>> def indirect(func, arg): # Call the passed-in object by adding ()
func(arg)
>>> indirect(echo, 'Argument call!') # Pass the function to another function
Argument call!
4-5-2-2) Function Introspection
We can inspect their attributes generically:
>>> func.__name__
'func'
>>> dir(func)
['__annotations__', '__call__', '__class__', '__closure__', '__code__',
...more omitted: 34 total...
'__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']Introspection allows us to explore implementation detail too – functions have attached code objects, for example, which provide detail on aspects such as the function’s local variables and arguments:
>>> func.__code__
func at 0x00000000021A6030, file "" , line 1>
>>> dir(func.__code__)
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', ...more omitted: 37 total...
'co_argcount', 'co_cellvars', 'co_code', 'co_consts', 'co_filename', 'co_firstlineno', 'co_flags', 'co_freevars', 'co_kwonlyargcount', 'co_lnotab', 'co_name', 'co_names', 'co_nlocals', 'co_stacksize', 'co_varnames']
>>> func.__code__.co_varnames
('a', 'b')
>>> func.__code__.co_argcount
1Tool writers can make use of such information to manage functions
4-5-2-3) Function Attributes
Function objects are not limited to the system-define attributes listed in the prior section, though. it’s been possible to attach arbitrary user-defined attributes to them as well since Python 2.1:
>>> func
0x000000000296A1E0>
>>> func.count = 0
>>> func.count += 1
>>> func.count
1
>>> func.handles = 'Button-Press'
>>> func.handles
'Button-Press'
>>> dir(func)
['__annotations__', '__call__', '__class__', '__closure__', '__code__',
...and more: in 3.X all others have double underscores so your names won't clash... __str__', '__subclasshook__', 'count', 'handles'] Python’s own implementation-related data stored on functions follows naming conventions that prevent them from clashing with the more arbitrary attribute names you might assign yourself. In 3.X, all function internals’ names have leading and trailing double underscores (“X“); 2.XX follows the same scheme, but also assigns some names that begin with “func_X”:
c:\code> py −3 >>> def f(): pass
>>> dir(f)
...run on your own to see...
>>> len(dir(f))
34
>>> [x for x in dir(f) if not x.startswith('__')]
[]
c:\code> py −2
>>> def f(): pass
>>> dir(f)
...run on your own to see...
>>> len(dir(f))
31
>>> [x for x in dir(f) if not x.startswith('__')]
['func_closure', 'func_code', 'func_defaults', 'func_dict', 'func_doc', 'func_globals', 'func_name']4-5-2-4) Function Annotations in 3.X
In Python 3.X (but not 2.X), it’s also possible to attach annotation information – arbitrary user_defined data about a function’s arguments and result – to a function object. Python provides special syntax for specify annotations, but it doesn’t do anything with them itself; annotation are completely optional, and when present are simply attached to the function object’s annotations attribute for use by other tools. For instance, such a tool might use annotations in the context of error testing.
>>> def func(a, b, c):
return a + b + c
>>> func(1, 2, 3)
6Syntactically, function annotations are coded in def header lines, as arbitrary expres- sions associated with arguments and return values. For arguments, they appear after a colon immediately following the argument’s name; for return values, they are written after a -> following the arguments list. This code, for example, annotates all three of the prior function’s arguments, as well as its return value:
>>> def func(a: 'spam', b: (1, 10), c: float) -> int:
return a + b + c
>>> func(1, 2, 3)
6Calls to an annotated function work as usual, but when annotations are present Python collects them in a dictionary and attaches it to the function object itself. Argument names become keys, the return value annotation is stored under key “return” if coded (which suffices because this reserved word can’t be used as an argument name), and the values of annotation keys are assigned to the results of the annotation expressions:
>>> func.__annotations__
{'c': <class 'float'>, 'b': (1, 10), 'a': 'spam', 'return': <class 'int'>}Because they are just Python objects attached to a Python object, annotations are straightforward to process. The following annotations just two of three arguments and steps through the attached annotations generically:
>>> def func(a: 'spam', b, c: 99):
return a + b + c
>>> func(1, 2, 3)
6
>>> func.__annotations__
{'c': 99, 'a': 'spam'}
>>> for arg in func.__annotations__:
print(arg, '=>', func.__annotations__[arg])
c => 99
a => spamThere are two fine points to note here. First, you can still use default for arguments if you code annotations – the annotation (and its : character) appear before the default (and its = character). In the following, for example, a : ‘spam’ = 4 means that argument a default to 4 and is annotated with the string ‘spam’:
>>> def func(a: 'spam' = 4, b: (1, 10) = 5, c: float = 6) -> int: return a + b + c
>>> func(1, 2, 3)
6
>>> func()
15
>>> func(1, c=10) # 1 + 5 + 10 (keywords work normally)
16
>>> func.__annotations__
{'c': <class 'float'>, 'b': (1, 10), 'a': 'spam', 'return': <class 'int'>}Second, note that the blank spaces in the prior example are all optional. – you can use spaces between components in function headers or not, but omitting them might degrade your code’s readability to some observers:
>>> def func(a:'spam'=4, b:(1,10)=5, c:float=6)->int: return a + b + c
>>> func(1, 2) # 1 + 2 + 6
9
>>> func.__annotations__
{'c': <class 'float'>, 'b': (1, 10), 'a': 'spam', 'return': <class 'int'>}Annotations are a new feature in 3.X, and some of their potential uses remain to be uncovered. It’s easy to imagine annotations being used to specify constraints for argu- ment types or values, though, and larger APIs might use this feature as a way to register function interface information.
4-5-3) Anonymous Functions: lambda
Besides the def statement, Python also provides an expression form that generates function objects. Because of its similarity to a tool in the Lisp language, it’s called lambda. Like def, this expression creates a function to be called later, but it returns the function instead of assigning it to a name. This is why lambdas are sometimes known as anonymous functions. In practice, they are often used as a way to inline a function definition, or to defer execution of a piece of code.
4-5-3-1) lambda Basics
The lambda’s general form is the keyword lambda, followed by one or more arguments, followed by an expression after a colon:
lambda argument1, argument2,... argumentN : expression using argumentsFunction objects returned by running lambda expressions work exactly the same as those created and assigned by defs, but there are a few differences that make lambdas useful in specialized roles:
- lambda is an expression, not a statement. Because of this, a lambda can appear in places a def is not allowed by Python’s syntax—inside a list literal or a function call’s arguments, for example. With def, functions can be referenced by name but must be created elsewhere. As an expression, lambda returns a value (a new function) that can optionally be assigned a name. In contrast, the def statement always assigns the new function to the name in the header, instead of returning it as a result.
* lambda’s body is a single expression, not a block of statements.
The lambda’s body is similar to what you’d put in a def body’s return statement; you simply type the result as a naked expression, instead of explicitly returning it. Because it is limited to an expression, a lambda is less general than a def—you can only squeeze so much logic into a lambda body without using statements such as if. This is by design, to limit program nesting: lambda is designed for coding simple functions, and def handles larger tasks.
Apart from these distinctions, defs and lambdas do the same sort of work.
>>> def func(x, y, z): return x + y + z
>>> func(2, 3, 4)
9But you can achieve the same effect with a lambda expression by explicitly assigning its
result to a name through which you can later call the function:
>>> f = lambda x, y, z: x + y + z
>>> f(2, 3, 4)
94-5-4) Functional Programming Tools
By most definitions, today’s Python blends support for multiple programming paradigms: procedural (with its basic statements), object-oriented (with its classes), and functional. For the latter of these, Python includes a set of built-ins used for functional programming – tools that apply functions to sequences and other iterables. This set includes tools that call functions on a iterable’s items (map); filter out iterms based on a test function (filter); and apply functions to pairs of items and returning result (reduce).
4-5-4-1) Mapping Functions over Iterables: map
One of the more common things programs do with lists and other sequences is apply an operation to each item and collect the results – selecting columns database tables, incrementing pay fields of employees in a company, parsing email attachments, and so on. Python has multiple tools that make such collection-wide operations easy to code. For instance, updating all the counters in a list can be done easily with a for loop:
>>> counters = [1, 2, 3, 4] >>>
>>> updated = []
>>> for x in counters:
updated.append(x + 10)
>>> updated
[11, 12, 13, 14]Because map expects a function to be passed in and applied, it also happens to be one of the places where lambda commonly appears:
>>> list(map((lambda x: x + 3), counters)) # Function expression
[4, 5, 6, 7]Moreover, map can be used in more advanced ways than shown here. For instance, given multiple sequence arguments, it sends items taken from sequences in parallel as distinct arguments to the function:
>>> pow(3, 4) # 3**4
81
>>> list(map(pow, [1, 2, 3], [2, 3, 4])) # 1**2, 2**3, 3**4
[1, 8, 81]4-5-4-2) Selecting Items in Iterables: filter
Filter (like range) requires a list call to display all its results in 3.X. For example, the following filter call picks out items in a sequence that are greater than zero:
>>> list(range(−5, 5)) # An iterable in 3.X
[−5, −4, −3, −2, −1, 0, 1, 2, 3, 4]
>>> list(filter((lambda x: x > 0), range(−5, 5))) # An iterable in 3.X
[1, 2, 3, 4]
>>> res = []
>>> for x in range(−5, 5): # The statement equivalent
if x > 0:
res.append(x)
>>> res
[1, 2, 3, 4]4-5-4-3) Combining Items in Iterables: reduce
It accepts an iterable to process, but it’s not an iterable itself—it returns a single result. Here are two reduce calls that compute the sum and product of the items in a list:
>>> from functools import reduce # Import in 3.X, not in 2.X >>> reduce((lambda x, y: x + y), [1, 2, 3, 4])
10
>>> reduce((lambda x, y: x * y), [1, 2, 3, 4])
24t each step, reduce passes the current sum or product, along with the next item from the list, to the passed-in lambda function. By default, the first item in the sequence initializes the starting value. To illustrate, here’s the for loop equivalent to the first of these calls, with the addition hardcoded inside the loop:
>>> L = [1,2,3,4]
>>> res = L[0]
>>> for x in L[1:]:
res = res + x
>>> res
10
>>> def myreduce(function, sequence): tally = sequence[0]
for next in sequence[1:]:
tally = function(tally, next)
return tally
>>> myreduce((lambda x, y: x + y), [1, 2, 3, 4, 5]) 15
>>> myreduce((lambda x, y: x * y), [1, 2, 3, 4, 5]) 1204-6) Comprehensions and Generations
4-6-1) List Comprehensions Versus map
Let’s work through an example that demonstrates the basics. Python’s built-in ord function returns the integer code point of a single character.
>>> ord('s')
115Now, suppose we wish to collect the ASCII codes of all characters in an entire string. Perhaps the most straightforward approach is to use a simple for loop and append the results to a list:
>>> res = []
>>> for x in 'spam':
res.append(ord(x))
>>> res
[115, 112, 97, 109]Now that we know about map, though, we can achieve similar results with a single function call without having to manage list construction in the code:
>>> res = list(map(ord, 'spam')) # Apply function to sequence (or other)
>>> res
[115, 112, 97, 109]However, we can get the same results from a list comprehension expression – while map maps a function over an iterable, list comprehensions map an expression over a sequence or other iterable:
>>> res = [ord(x) for x in 'spam'] # Apply expression to sequence (or other)
>>> res
[115, 112, 97, 109]4-6-2) Adding Tests and Nested Loops: filter
To demonstrate, following are both schemes picking up even numbers from 0 to 4; like the map list comprehension alternative of the prior section, the filter version here must invent a little lambda function for the test expression. For comparison, the equivalent for loop is shown here as well:
>>> [x for x in range(5) if x % 2 == 0]
[0, 2, 4]
>>> list(filter((lambda x: x % 2 == 0), range(5)))
[0, 2, 4]
>>> res = []
>>> for x in range(5):
if x % 2 == 0:
res.append(x)
>>> res [0, 2, 4]
>>> [x ** 2 for x in range(10) if x % 2 == 0]
[0, 4, 16, 36, 64]
>>> list( map((lambda x: x**2), filter((lambda x: x % 2 == 0), range(10))) )
[0, 4, 16, 36, 64]4-6-2) Formal comprehension syntax
In fact, list comprehensions are more general still. In their simplest form, you must always code and accumulation expression and a single for clause:
[ expression for target in iterable ]
[ expression for target1 in iterable1 if condition1
for target2 in iterable2 if condition2
...
for targetN in iterableN if conditionN ]>>> res = [x + y for x in [0, 1, 2] for y in [100, 200, 300]]
>>> res
[100, 200, 300, 101, 201, 301, 102, 202, 302]This has the same effect as this substantially more verbose equivalent:
>>> res = []
>>> for x in [0, 1, 2]:
for y in [100, 200, 300]:
res.append(x + y)
>>> res
[100, 200, 300, 101, 201, 301, 102, 202, 302]Although list comprehensions construct list result, remember that they can iterate over any sequence or other iterable type. Here’s a similar bit of code that traverse strings instead of lists of numbers, and so collects concatenation results:
>>> [x + y for x in 'spam' for y in 'SPAM']
['sS', 'sP', 'sA', 'sM', 'pS', 'pP', 'pA', 'pM', 'aS', 'aP', 'aA', 'aM', 'mS', 'mP', 'mA', 'mM']4-6-3) Don’t Abuse List Comprehensions: KISS
The age-old acronym KISS still applies: Keep It Simple—followed either by a word that is today too sexist (Sir), or another that is too colorful for a family-oriented book like this…
4-6-3-1) On the other hand: performance, conciseness, expressiveness
However, in this case, there is currently a substantial performance advantage to the extra complexity: based on tests run under Python today, map calls can be twice as fast as equivalent for loops, and list comprehensions are often faster than map calls. This speed difference can vary per usage pattern and Python, but is generally due to the fact that map and list comprehensions run at C language speed inside the interpreter, which is often much faster than stepping through Python for loop bytecode within the PVM.
In addition, list comprehensions offer a code conciseness that’s compelling and even warranted when that reduction in size doesn’t also imply a reduction in meaning for the next programmer. Moreover, many find the expressiveness of comprehensions to be a powerful ally. Because map and list comprehensions are both expressions, they also can show up syntactically in places that for loop statements cannot, such as in the bodies of lambda functions, within list and dictionary literals, and more.
Because of this, list comprehensions and map calls are worth knowing and using for simpler kinds of iterations, especially if your application’s speed is an important con- sideration. Still, because for loops make logic more explicit, they are generally recom- mended on the grounds of simplicity, and often make for more straightforward code. When used, you should try to keep your map calls and list comprehensions simple; for more complex tasks, use full statements instead.
4-7) Generator Functions and Expressions
Python today supports procrastination much more than it did in the past – it provides tools that produce results only when needed, instead of all at once. In particular, two language constructs delay result creation whenever possible in user-defined operations:
- Generator functions (available since 2.3) are coded as normal def statements, but use yield statement to return results one at a time, suspending and resuming their state between each.
- Generator expression (available since 2.4) are similar to the list comprehensions of the prior section, but they return an object that produces results on demand instead of building a result list.
4-7-1) Generator Functions: yield Versus return
Generator functions are like normal functions in most respects, and in fact they are coded with normal def statements. However, when created, they are compiled specially into an object that supports the iteration protocol. And when called, they don’t return a result: they return a result generator that can appear in any iteration context.
4-7-1-1) State suspension
Unlike normal functions that return a value and exit, generator functions automatically suspend and resume their execution and state around the point of value generation. Because of that, they are often a useful alternative to both computing an entire series of values up front and manually saving and restoring state in classes. The state that generator functions retain when they are suspended includes both their code location, and their entire local scope. Hence, their local variables retain information between results, and make it available when the functions are resumed.
The chief code difference between generator and normal functions is that a generator yields a value, rather than returning one—the yield statement suspends the function and sends a value back to the caller, but retains enough state to enable the function to resume from where it left off. When resumed, the function continues execution im- mediately after the last yield run. From the function’s perspective, this allows its code to produce a series of values over time, rather than computing them all at once and sending them back in something like a list.
4-7-1-2) Iteration protocol integration
To truly understand generator functions, you need to know that they are closely bound up with the notion of the iteration protocol in Python.
To support this protocol, functions containing a yield statement are compiled specially as generators—they are not normal functions, but rather are built to return an object with the expected iteration protocol methods. When later called, they return a gener- ator object that supports the iteration interface with an automatically created method named next to start or resume execution.
Generator functions may also have a return statement that, along with falling off the end of the def block, simply terminates the generation of values—technically, by raising a StopIteration exception after any normal function exit actions. From the caller’s perspective, the generator’s next method resumes the function and runs until either the next yield result is returned or a StopIteration is raised.
The net effect is that generator functions, coded as def statements containing yield statements, are automatically made to support the iteration object protocol and thus may be used in any iteration context to produce results over time and on demand.
4-7-1-3) Generator functions in action
To illustrate generator basics, let’s turn to some code. The following code defines a generator function that can be used to generate the squares of a series of numbers over time:
>>> def gensquares(N):
for i in range(N):
yield i ** 2 # Resume here laterThis function yields a value, and so returns to its caller, each time through the loop; when it is resumed, its prior state is restored, including the last values of its variables i and N, and control picks up again immediately after the yield statement.:
>>> for i in gensquares(5): # Resume the function
print(i, end=' : ') # Print last yielded value
0 : 1 : 4 : 9 : 16 : 4-7-1-4) Why generator functions?
Generators can be better in terms of both memory use and performance in larger programs. They allow functions to avoid doing all the work up front, which is especially useful when the result lists are large or when it takes a lot of computation to produce each value. Generators distribute the time required to produce the series of values among loop iterations.
Moreover, for more advanced uses, generators can provide a simpler alternative to manually saving the state between iterations in class objects, variables accessible in the function’s scopes are stored and restored automatically.
4-7-1-5) Extended generator function protocol: send versus next
In Python 2.5, a send method was added to the generator function protocol. The send method advances to the next item in the series of results, just like next, but also provide a way for the caller to communicate with the generator, to affect its operation.
Technically, yield is now an expression form that returns the item passed to send, not a statement (though it can be called either way—as yield X, or A = (yield X)). The expression must be enclosed in parentheses unless it’s the only item on the right side of the assignment statement. For example, X = yield Y is OK, as is X = (yield Y) + 42.
When this extra protocol is used, values are sent into a generator G by calling G.send(value). The generator’s code is then resumed, and the yield expression in the generator returns the value passed to send. If the regular G.next() method (or its next(G) equivalent) is called to advance, the yield simply returns None. For example:
>>> def gen():
for i in range(10):
X = yield i
print(X)
>>> G = gen()
>>> next(G)
0
>>> G.send(77)
77
1
>>> G.send(88)
88
2
>>> next(G)
None
3
# Must call next() first, to start generator
# Advance, and send value to yield expression
# next() and X.__next__() send NoneThe send method can be used, for example, to code a generator that its caller can terminate by sending a termination code, or redirect by passing a new position in data being processed inside the generator.
In addition, generators in 2.5 and later also support a throw(type) method to raise an exception inside the generator at the latest yield, and a close method that raises a special GeneratorExit exception inside the generator to terminate the iteration entirely.
4-7-2) Generator Expressions: Iterables Meet Comprehensions
Because the delayed evaluation of generator function was so useful, it eventually spread to other tools. In both Python 2.X and 3.X, the notions of iterables and list comprehensions are combined in a new tool: generator expressions. Syntactically, gen- erator expressions are just like normal list comprehensions, and support all their syntax —including if filters and loop nesting—but they are enclosed in parentheses instead of square brackets (like tuples, their enclosing parentheses are often optional):
>>> [x ** 2 for x in range(4)] # List comprehension: build a list
[0, 1, 4, 9]
>>> (x ** 2 for x in range(4)) # Generator expression: make an iterable
at 0x00000000029A8288> In fact, at least on a functionality basis, coding a list comprehension is essentially the same as wrapping a generator expression in a list built-in call to force it to produce all its results in a list at once:
>>> list(x ** 2 for x in range(4)) # List comprehension equivalence
[0, 1, 4, 9]
>>> ''.join(x.upper() for x in 'aaa,bbb,ccc'.split(',')) 'AAABBBCCC'
>>> a, b, c = (x + '\n' for x in 'aaa,bbb,ccc'.split(','))
>>> a, c ('aaa\n', 'ccc\n')Notice how the join call in the preceding doesn’t require extra parentheses around the generator. Syntactically, parentheses are not required around a generator expression that is the sole item already enclosed in parentheses used for other purposes—like those of a function call. Parentheses are required in all other cases, however, even if they seem extra, as in the second call to sorted that follows:
>>> sum(x ** 2 for x in range(4)) # Parens optional
14
>>> sorted(x ** 2 for x in range(4)) # Parens optional
[0, 1, 4, 9]
>>> sorted((x ** 2 for x in range(4)), reverse=True) # Parens required
[9, 4, 1, 0]
4-7-3) Generator Functions Versus Generator Expressions
Let’s recap what we’ve covered so far in this section:
Generator functions
A function def statement that contains a yield statement is turned into a generator function. When called, it returns a new generator object with automatic retention of local scope and code position; an automatically created iter method that simply returns itself; and an automatically created next method (next in 2.X) that starts the function or resumes it where it last left off, and raises StopItera tion when finished producing results.Generator expressions
A comprehension expression enclosed in parentheses is known as a generator ex- pression. When run, it returns a new generator object with the same automatically created method interface and state retention as a generator function call’s results —with an iter method that simply returns itself; and a next_ method (next in 2.X) that starts the implied loop or resumes it where it last left off, and raises StopIteration when finished producing results.
4-7-4) Generators Are Single-Iteration Objects
A subtle but important point: both generator functions and generator expressions are their own iterators and thus support just one active iteration – unlike some built-in types, you can’t have multiple iterations of either positioned at different locations in the set of results. Because of this, a generator’s iterator is the generator itself: in fact, as suggested earlier, calling iter on a generator expression or function is an optional noop:
>>> G = (c * 4 for c in 'SPAM')
>>> iter(G) is G # My iterator is myself: G has __next__
TrueIf you iterate over the results stream manually with multiple iterators, they will all point to the same position:
>>> G = (c * 4 for c in 'SPAM') # Make a new generator
>>> I1 = iter(G) # Iterate manually
>>> next(I1)
'SSSS'
>>> next(I1)
'PPPP'
>>> I2 = iter(G) # Second iterator at same position!
>>> next(I2)
'AAAA'Moreover, once any iteration runs to completion, all are exhausted – we have to make a new generator to start again:
>>> list(I1) # Collect the rest of I1's items
['MMMM']
>>> next(I2) # Other iterators exhausted too
StopIteration
>>> I3 = iter(G) # Ditto for new iterators
>>> next(I3)
StopIteration
>>> I3 = iter(c * 4 for c in 'SPAM') # New generator to start over
>>> next(I3)
'SSSS'This is different from the behavior of some built-in types, which support multiple iterators and passes and reflect their in-place changes in active iterators:
>>> L = [1, 2, 3, 4]
>>> I1, I2 = iter(L),
iter(L)
>>> next(I1)
1
>>> next(I1)
2
>>> next(I2) # Lists support multiple iterators
1
>>> del L[2:] # Changes reflected in iterators
>>> next(I1)
StopIterationThough not readily apparent in these simple examples, this can matter in your code: if you wish to scan a generator’s value multiple times, you must either create a new generator for each scan or build a rescannable list out of its value – a single generator’s values will be consumed and exhausted after a single pass.
4-7-5) Preview: User-defined iterables in classes
It is also possible to implement arbitrary user-defined generator objects with classes that conform to the iteration protocol. Such classes define a special iter method run by the iter built-in function, which in turn returns an object having a next method (next in 2.X) run by the next built-in function:
class SomeIterable:
def __init__(...): ... # On iter(): return self or supplemental object
def __next__(...): ... # On next(): coded here, or in another class4-8) The Benchmarking Interlude
4-8-1) Timing Iteration Alternatives
4-8-1-1) Timing Module: Homegrown
# File timer0.py
import time
def timer(func, *args): # Simplistic timing function
start = time.clock()
for i in range(1000):
func(*args)
return time.clock() - start # Total elapsed time in secondsThis works – it fetches time values from Python’s time module, and subtracts the system start time from the stop time after running 1000 calls to the passed-in function with the passed-in arguments.
>>> from timer0 import timer
>>> timer(pow, 2, 1000) # Time to call pow(2, 1000) 1000 times
0.00296260674205626
>>> timer(str.upper, 'spam') # Time to call 'spam'.upper() 1000 times
0.00051657461668597195) Modules and Packages
5-1) Modules: The Big Picture
This chapter begins our in-depth look at the Python module—the highest-level program organization unit, which packages program code and data for reuse, and provides self- contained namespaces that minimize variable name clashes across your programs. In concrete terms, modules typically correspond to Python program files. Each file is a module, and modules import other modules to use the names they define. Modules might also correspond to extensions coded in external languages such as C, Java, or C#, and even to directories in package imports. Modules are processed with two state- ments and one important function:
import
Lets a client (importer) fetch a module as a wholefrom
Allows clients to fetch particular names from a moduleimp.reload (reload in 2.X)
Provides a way to reload a module’s code without stopping Python
Modules have at least three roles:
Code reuse
Modules let you save code in files permanently. Unlike code you type at the Python interactive prompt, which goes away when you exit Python, code in module files is persistent—it can be reloaded and rerun as many times as needed. Just as importantly, modules are a place to define names, known as attributes, which may be referenced by multiple external clients. When used well, this supports a modular program design that groups functionality into reus- able units.System namespace partitioning
Modules are also the highest-level program organization unit in Python. Although they are fundamentally just packages of names, these packages are also self-con- tained—you can never see a name in another file, unless you explicitly import that file. Much like the local scopes of functions, this helps avoid name clashes across your programs. In fact, you can’t avoid this feature—everything “lives” in a mod- ule, both the code you run and the objects you create are always implicitly enclosed in modules. Because of that, modules are natural tools for grouping system com- ponents.Implementing shared services or data
From an operational perspective, modules are also useful for implementing com- ponents that are shared across a system and hence require only a single copy. For instance, if you need to provide a global object that’s used by more than one func- tion or file, you can code it in a module that can then be imported by many clients.
5-2-1) Python Program Architecture
This section introduces the general architecture of Python programs—the way you di- vide a program into a collection of source files (a.k.a. modules) and link the parts into a whole. As we’ll see, Python fosters a modular program structure that groups func- tionality into coherent and reusable units, in ways that are natural, and almost auto- matic. Along the way, we’ll also explore the central concepts of Python modules, im- ports, and object attributes.
5-2-1-1) How to Structure a Program
At a base level, a Python program consists of text files containing Python statements, with one main top-level file, and zero or more supplemental files known as modules.
Here’s how this works. The top-level (a.k.a. script) file contains the main flow of control of your program—this is the file you run to launch your application. The module files are libraries of tools used to collect components used by the top-level file, and possibly elsewhere. Top-level files use tools defined in module files, and modules use tools de- fined in other modules.
Although they are files of code too, module files generally don’t do anything when run directly; rather, they define tools intended for use in other files. A file imports a module to gain access to the tools it defines, which are known as its attributes—variable names attached to objects such as functions. Ultimately, we import modules and access their attributes to use their tools.
5-2-1-2) Imports and Attributes
Let’s make this a bit more concrete. Figure below sketches the structure of a Python program composed of three files: a.py, b.py, and c.py. The file a.py is chosen to be the top-level file; it will be a simple text file of statements, which is executed from top to bottom when launched. The files b.py and c.py are modules; they are simple text files of statements as well, but they are not usually launched directly. Instead, as explained previously, modules are normally imported by other files that wish to use the tools the modules define.
The first of these, a Python import statement, gives the file a.py access to everything defined by top-level code in the file b.py. The code import b roughly means:
Load the file b.py (unless it’s already loaded), and give me access to all its attributes through the name b.
To satisfy such goals, import (and, as you’ll see later, from) statements execute and load other files on request. More formally, in Python, cross-file module linking is not re- solved until such import statements are executed at runtime; their net effect is to assign module names—simple variables like b—to loaded module objects. In fact, the module name used in an import statement serves two purposes: it identifies the external file to be loaded, but it also becomes a variable assigned to the loaded module.
Similarly, objects defined by a module are also created at runtime, as the import is executing: import literally runs statements in the target file one at a time to create its contents. Along the way, every name assigned at the top-level of the file becomes an attribute of the module, accessible to importers. For example, the second of the state- ments in a.py calls the function spam defined in the module b—created by running its def statement during the import—using object attribute notation. The code b.spam means:
Fetch the value of the name spam that lives within the object b.
This happens to be a callable function in our example, so we pass a string in parentheses (‘gumby’). If you actually type these files, save them, and run a.py, the words “gumby spam” will be printed.
As we’ve seen, the object.attribute notation appears throughout Python code—most objects have useful attributes that are fetched with the “.” operator. Some reference callable objects like functions that take action (e.g., a salary computer), and others are simple data values that denote more static objects and properties (e.g., a person’s name).
The notion of importing is also completely general throughout Python. Any file can import tools from any other file. For instance, the file a.py may import b.py to call its function, but b.py might also import c.py to leverage different tools defined there. Im- port chains can go as deep as you like: in this example, the module a can import b, which can import c, which can import b again, and so on.
5-2-1-3) Standard Library Modules
Notice the rightmost portion of Figure above. Some of modules that your programs will import are provided by Python itself and are not files you code.
Python automatically comes with a large collection of utility modules known as the standard library. This collection, over 200 modules large at last count, contains plat- form-independent support for common programming tasks: operating system inter- faces, object persistence, text pattern matching, network and Internet scripting, GUI construction, and much more. None of these tools are part of the Python language itself, but you can use them by importing the appropriate modules on any standard Python installation. Because they are standard library modules, you can also be rea- sonably sure that they will be available and will work portably on most platforms on which you will run Python.
5-2-2) How Imports Work
The prior section talked about importing modules without really explaining what happens when you so do. Because imports are heart of program structure in Python, this section goes into more formal detail on the import operation to make this process less abstract.
Some C programmers like to compare the Python module import operation to a C #include, but they really shouldn’t – in Python, imports are not just textual insertions of one file into another. They are really runtime operations that perform three distinct steps the first time a program imports a given file:
- Find the module’s file.
- Compile it to byte code (if needed).
- Run the module’s code to build the objects it defines.
To better understand module imports, we’ll explore these steps in turn. Bear in mind that all three of these steps are carried out only the first time a module is imported during a program’s execution; later imports of the same module in a program run bypass all of these steps and simply fetch the already loaded module object in memory. Technically, Python does this by storing loaded objects in a table named sys.modules and checking there at the start of an import operation. If the module is not present, a three-step process begins.
5-2-2-1) Find it
First, Python must locate the module file referenced by an import statement. Notice that the import statement in the prior section’s example names the file without a .py extension and without its directory path: it just says import b, instead of something like import c:\dir1\b.py. Path and extension details are omitted on purpose; instead, Python uses a standard module search path and known file types to locate the module file corresponding to an import statement.1 Because this is the main part of the import operation that programmers must know about, we’ll return to this topic in a moment.
5-2-2-2) Compile it (Maybe)
After finding a source code file that matches an import statement by traversing the module search path, Python next to compile it to byte code, if necessary. During an import operation Python checks both file modification times and the byte code’s Python version number to decide how to process. The former uses file “timestamps”, and the latter uses either a “magic” number embedded in the byte code or a filename, depending on the Python release being used. This step chooses an action as follows:
Compile
If the byte code file is older than the source file (i.e., if you’ve changed the source) or was created by a different Python version, Python automatically regenerates the byte code when the program is run.
As discussed ahead, this model is modified somewhat in Python 3.2 and later— byte code files are segregated in a pycache subdirectory and named with their Python version to avoid contention and recompiles when multiple Pythons are installed. This obviates the need to check version numbers in the byte code, but the timestamp check is still used to detect changes in the source.Don’t compile
If, on the other hand, Python finds a .pyc byte code file that is not older than the corresponding .py source file and was created by the same Python version, it skips the source-to-byte-code compile step.
In addition, if Python finds only a byte code file on the search path and no source, it simply loads the byte code directly; this means you can ship a program as just byte code files and avoid sending source. In other words, the compile step is by- passed if possible to speed program startup.
5-2-2-3) Run It
The final step of an import operation executes the byte code of the module. All statements in the file are run in turn, from top to bottom, and any assignments made to names during this step generate attributes of the resulting module object. This is how the tools defined by the module’s code are created. For instance, def statements in a file are run at import time to create functions and assign attributes within the module to those functions. The functions can then be called later in the program by the file’s importers.
5-2-3) Byte Code Files: pycache in Python 3.2+
As mentioned briefly, the way that Python stores files to retain the byte code that results from compiling your source has changed in Python 3.2 and later. First of all, if Python cannot write a file to save this on your computer for any reason, your program still runs fine—Python simply creates and uses the byte code in memory and discards it on exit. To speed startups, though, it will try to save byte code in a file in order to skip the compile step next time around. The way it does this varies per Python version:
In Python 3.1 and earlier (including all of Python 2.X)
Byte code is stored in files in the same directory as the corresponding source files, normally with the filename extension .pyc (e.g., module.pyc). Byte code files are also stamped internally with the version of Python that created them (known as a “magic” field to developers) so Python knows to recompile when this differs in the version of Python running your program. For instance, if you upgrade to a new Python whose byte code differs, all your byte code files will be recompiled auto- matically due to a version number mismatch, even if you haven’t changed your source code.In Python 3.2 and later
Byte code is instead stored in files in a subdirectory named pycache, which Python creates if needed, and which is located in the directory containing the corresponding source files. This helps avoid clutter in your source directories by segregating the byte code files in their own directory.
5-2-4) The Module Search Path
In many cases, you can rely on the automatic nature of the module import search path and won’t need to configure this path at all. If you want to be able to import user- defined files across directory boundaries, though, you will need to know how the search path works in order to customize it. Roughly, Python’s module search path is composed of the concatenation of these major components, some of which are preset for you and some of which you can tailor to tell Python where to look:
- The home directory of the program
- PYTHONPATH directories (if set)
- Standard library directories
- The contents of any .pth files (if present)
- The site-packages home of third-party extensions
Ultimately, the concatenation of these four components becomes sys.path, a mutable list of directory name strings that I’ll expand upon later in this section. The first and third elements of the search path are defined automatically. Because Python searches the concatenation of these components from first to last, though, the second and fourth elements can be used to extend the path to include your own source code di- rectories. Here is how Python uses each of these path components:
Home directory (automatic)
Python first looks for the imported file in the home directory. The meaning of this entry depends on how you are running the code. When you’re running a pro- gram, this entry is the directory containing your program’s top-level script file. When you’re working interactively, this entry is the directory in which you are working (i.e., the current working directory).PYTHONPATH directories (configurable)
Next, Python searches all directories listed in your PYTHONPATH environment vari- able setting, from left to right (assuming you have set this at all: it’s not preset for you). In brief, PYTHONPATH is simply a list of user-defined and platform-specific names of directories that contain Python code files. You can add all the directories from which you wish to be able to import, and Python will extend the module search path to include all the directories your PYTHONPATH lists.
Because Python searches the home directory first, this setting is only important when importing files across directory boundaries—that is, if you need to import a file that is stored in a different directory from the file that imports it. You’ll probably want to set your PYTHONPATH variable once you start writing substantial programs, but when you’re first starting out, as long as you save all your module files in the directory in which you’re working (i.e., the home directory, like the C:\code used in this book) your imports will work without you needing to worry about this setting at all.Standard library directories (automatic)
Next, Python automatically searches the directories where the standard library modules are installed on your machine. Because these are always searched, they normally do not need to be added to your PYTHONPATH or included in path files (discussed next)..pth path file directories (configurable)
Next, a lesser-used feature of Python allows users to add directories to the module search path by simply listing them, one per line, in a text file whose name ends with a .pth suffix (for “path”). These path configuration files are a somewhat ad- vanced installation-related feature; we won’t cover them fully here, but they pro- vide an alternative to PYTHONPATH settings.The Lib\site-packages directory of third-party extensions (automatic)
Finally, Python automatically adds the site-packages subdirectory of its standard library to the module search path. By convention, this is the place that most third- party extensions are installed, often automatically by the distutils utility de- scribed in an upcoming sidebar. Because their install directory is always part of the module search path, clients can import the modules of such extensions without any path settings.
5-2-4-1) The sys.path List
If you want to see how the module search path is truly configured on your machine, you can always inspect the path as Python knows it by printing the built-in sys.path list (that is, the path attribute of the standard library module sys). This list of directory name strings is the actual search path within Python; on imports, Python searches each directory in this list from left to right, and uses the first file match it finds.
6) Classes and OOP
6-1) OOP: The Big Picture
6-1-1) Why Use Classes?
Two aspects of OOP prove useful here:
Inheritance
Pizza-making robots are kinds of robots, so they possess the usual robot-y prop- erties. In OOP terms, we say they “inherit” properties from the general category of all robots. These common properties need to be implemented only once for the general case and can be reused in part or in full by all types of robots we may build in the future.Composition
Pizza-making robots are really collections of components that work together as a team. For instance, for our robot to be successful, it might need arms to roll dough, motors to maneuver to the oven, and so on. In OOP parlance, our robot is an example of composition; it contains other objects that it activates to do its bidding. Each component might be coded as a class, which defines its own behavior and relationships.
Classes have three critical distinctions that make them more useful when it comes to building new objects:
Multiple instances
Classes are essentially factories for generating one or more objects. Every time we call a class, we generate a new object with a distinct namespace. Each object gen- erated from a class has access to the class’s attributes and gets a namespace of its own for data that varies per object. This is similar to the per-call state retention of Chapter 17’s closure functions, but is explicit and natural in classes, and is just one of the things that classes do. Classes offer a complete programming solution.Customization via inheritance
Classes also support the OOP notion of inheritance; we can extend a class by re- defining its attributes outside the class itself in new software components coded as subclasses. More generally, classes can build up namespace hierarchies, which define names to be used by objects created from classes in the hierarchy. This supports multiple customizable behaviors more directly than other tools.Operator overloading
By providing special protocol methods, classes can define objects that respond to the sorts of operations we saw at work on built-in types. For instance, objects made with classes can be sliced, concatenated, indexed, and so on. Python provides hooks that classes can use to intercept and implement any built-in type operation.
6-1-2) Attribute Inheritance Search
In Python, it searches a tree of linked objects, looking for the first appearance of attribute that it can find. When classes are involved, the preceding Python expression effectively translates to the following in natural language:
Find the first occurrence of attribute by looking in object, then in all classes above it, from bottom to top and left to right.
In other words, attribute fetches are simply tree searches. The term inheritance is ap- plied because objects lower in a tree inherit attributes attached to objects higher in that tree. As the search proceeds from the bottom up, in a sense, the objects linked into a tree are the union of all the attributes defined in all their tree parents, all the way up the tree.
In Python, this is all very literal: we really do build up trees of linked objects with code, and Python really does climb this tree at runtime searching for attributes every time we use the object.attribute expression. To make this more concrete, Figure below sketches an example of one of these trees.
Figure above. A class tree, with two instances at the bottom (I1 and I2), a class above them (C1), and two superclasses at the top (C2 and C3). All of these objects are namespaces (packages of variables), and the inheritance search is simply a search of the tree from bottom to top looking for the lowest occurrence of an attribute name. Code implies the shape of such trees.
Notice that in the Python object model, classes and the instances you generate from them are two distinct object types:
Classes
Serve as instance factories. Their attributes provide behavior—data and functions —that is inherited by all the instances generated from them (e.g., a function to compute an employee’s salary from pay and hours).Instances
Represent the concrete items in a program’s domain. Their attributes record data that varies per specific object (e.g., an employee’s Social Security number).
6-1-3) Classes and Instances
Although they are technically two separate object types in the Python model, the classes and instances we put in these trees are almost identical—each type’s main purpose is to serve as another kind of namespace—a package of variables, and a place where we can attach attributes. If classes and instances therefore sound like modules, they should; however, the objects in class trees also have automatically searched links to other namespace objects, and classes correspond to statements, not entire files.
The primary difference between classes and instances is that classes are a kind of fac- tory for generating instances. For example, in a realistic application, we might have an Employee class that defines what it means to be an employee; from that class, we generate actual Employee instances. This is another difference between classes and modules— we only ever have one instance of a given module in memory (that’s why we have to reload a module to get its new code), but with classes, we can make as many instances as we need.
Operationally, classes will usually have functions attached to them (e.g., computeSa lary), and the instances will have more basic data items used by the class’s functions (e.g., hoursWorked). In fact, the object-oriented model is not that different from the classic data-processing model of programs plus records—in OOP, instances are like records with “data,” and classes are the “programs” for processing those records. In OOP, though, we also have the notion of an inheritance hierarchy, which supports software customization better than earlier models.
6-1-4) Method Calls
In the prior section, we saw how the attribute reference I2.w in our example class tree was translated to C3.w by the inheritance search procedure in Python. Perhaps just as important to understand as the inheritance of attributes, though, is what happens when we try to call methods—functions attached to classes as attributes.
If this I2.w reference is a function call, what it really means is “call the C3.w function to process I2.” That is, Python will automatically map the call I2.w() into the call C3.w(I2), passing in the instance as the first argument to the inherited function.
In fact, whenever we call a function attached to a class in this fashion, an instance of the class is always implied. This implied subject or context is part of the reason we refer to this as an object-oriented model—there is always a subject object when an operation is run. In a more realistic example, we might invoke a method called giveRaise attached as an attribute to an Employee class; such a call has no meaning unless qualified with the employee to whom the raise should be given.
As we’ll see later, Python passes in the implied instance to a special first argument in the method, called self by convention. Methods go through this argument to process the subject of the call. As we’ll also learn, methods can be called through either an instance—bob.giveRaise()—or a class—Employee.giveRaise(bob)—and both forms serve purposes in our scripts. These calls also illustrate both of the key ideas in OOP: to run a bob.giveRaise() method call, Python:
- Looks up giveRaise from bob, by inheritance search
- Passes bob to the located giveRaise function, in the special self argument
6-1-5) Coding Class Trees
- Each class statement generates a new class object.
- Each time a class is called, it generates a new instance object.
- Instances are automatically linked to the classes from which they are created.
- Classes are automatically linked to their superclasses according to the way we list them in parentheses in a class header line; the left-to-right order there gives the order in the tree.
To build the tree in Figure, for example, we would run Python code of the following form. Like function definition, classes are normally coded in module files and are run during an import (I’ve omitted the guts of the class statements here for brevity):
class C2: ... # Make class objects (ovals)
class C3: ...
class C1(C2, C3): ... # Linked to superclasses (in this order)
I1 = C1() # Make instance objects (rectangles)
I2 = C1() # Linked to their classesBecause of the way inheritance searches proceed, the object to which you attach an attribute turns out to be crucial—it determines the name’s scope. Attributes attached to instances pertain only to those single instances, but attributes attached to classes are shared by all their subclasses and instances. Later, we’ll study the code that hangs attributes on these objects in depth. As we’ll find:
- Attributes are usually attached to classes by assignments made at the top level in class statement blocks, and not nested inside function def statements there.
- Attributes are usually attached to instances by assignments to the special argument passed to functions coded inside classes, called self.
6-1-6) Operator Overloading
As currently coded, our C1 class doesn’t attach a name attribute to an instance until the setname method is called. Indeed, referencing I1.name before calling I1.setname would produce an undefined name error. If a class wants to guarantee that an attribute like name is always set in its instances, it more typically will fill out the attribute at con- struction time, like this:
class C2: ...
class C3: ...
class C1(C2, C3):
def __init__(self, who):
self.name = who
I1 = C1('bob')
I2 = C1('sue')
print(I1.name)If it’s coded or inherited, Python automatically calls a method named init each time an instance is generated from a class. The new instance is passed in to the self argument of init as usual, and any values listed in parentheses in the class call go to arguments two and beyond. The effect here is to initialize instances when they are made, without requiring extra method calls.
The init method is known as the constructor because of when it is run. It’s the most commonly used representative of a larger class of methods called operator over- loading methods, which we’ll discuss in more detail in the chapters that follow. Such methods are inherited in class trees as usual and have double underscores at the start and end of their names to make them distinct. Python runs them automatically when instances that support them appear in the corresponding operations, and they are mostly an alternative to using simple method calls. They’re also optional: if omitted, the operations are not supported. If no init is present, class calls return an empty instance, without initializing it.
For example, to implement set intersection, a class might either provide a method named intersect, or overload the & expression operator to dispatch to the required logic by coding a method named and. Because the operator scheme makes instances look and feel more like built-in types, it allows some classes to provide a consistent and natural interface, and be compatible with code that expects a built-in type. Still, apart from the init constructor—which appears in most realistic classes—many programs may be better off with simpler named methods unless their objects are similar to built-ins. A giveRaise may make sense for an Employee, but a & might not.
6-1-7) Polymorphism and classes
As an example, suppose you’re assigned the task of implementing an employee database application. As a Python OOP programmer, you might begin by coding a general su- perclass that defines default behaviors common to all the kinds of employees in your organization:
class Employee: # General superclass
def computeSalary(self): ... # Common or default behaviors
def giveRaise(self): ...
def promote(self): ...
def retire(self): ...Once you’ve coded this general behavior, you can specialize it for each specific kind of employee to reflect how the various types differ from the norm. That is, you can code subclasses that customize just the bits of behavior that differ per employee type; the rest of the employee types’ behavior will be inherited from the more general class. For example, if engineers have a unique salary computation rule (perhaps it’s not hours times rate), you can replace just that one method in a subclass:
class Engineer(Employee): # Specialized subclass
def computeSalary(self): ... # Something custom hereBecause the computeSalary version here appears lower in the class tree, it will replace (override) the general version in Employee. You then create instances of the kinds of employee classes that the real employees belong to, to get the correct behavior:
bob = Employee() # Default behavior
sue = Employee() # Default behavior
tom = Engineer() # Custom salary calculatorUltimately, these three instance objects might wind up embedded in a larger container object—for instance, a list, or an instance of another class—that represents a depart- ment or company using the composition idea mentioned at the start of this chapter. When you later ask for these employees’ salaries, they will be computed according to the classes from which the objects were made, due to the principles of the inheritance search:
company = [bob, sue, tom] # A composite object
for emp in company:
print(emp.computeSalary()) # Run this object's version: default or customIn other applications, polymorphism might also be used to hide (i.e., encapsulate) in- terface differences. For example, a program that processes data streams might be coded to expect objects with input and output methods, without caring what those methods actually do:
def processor(reader, converter, writer):
while True:
data = reader.read()
if not data: break
writer.write(data)By passing in instances of subclasses that specialize the required read and write method interfaces for various data sources, we can reuse the processor function for any data source we need to use, both now and in the future:
class Reader:
def read(self): ... # Default behavior and tools
def other(self): ...
class FileReader(Reader):
def read(self): ... # Read from a local file
class SocketReader(Reader):
def read(self): ... # Read from a network socket
...
processor(FileReader(...), Converter, FileWriter(...)) processor(SocketReader(...), Converter, TapeWriter(...)) processor(FtpReader(...), Converter, XmlWriter(...))Moreover, because the internal implementations of those read and write methods have been factored into single locations, they can be changed without impacting code such as this that uses them. The processor function might even be a class itself to allow the conversion logic of converter to be filled in by inheritance, and to allow readers and writers to be embedded by composition
6-2) Class Coding Basics
Now that we’ve tabled about OOP in the abstract, it’s time to see how to translates to actual code. This Chapter begins to fill in the syntax details behind the class model in Python.
6-2-1) Classes Generate Multiple Instance Objects
To understand how the multiple objects ideas works, you have to first understand that there are two kinds of objects in Python’s OOP model: class objects and instance objects. Class objects provide default behavior and serve as factories for instance objects. Instance objects are the real objects your program process – each is a namespace in its own right, but inherits names in the class from which it was created. Class objects come from statements, and instances come from calls; each time you call a class, you get a new instance of that class.
6-2-1-1) Class Objects Provide Default Behavior
When we run a class statement, we get a class object. Here’s a rundown of the main properties of Python classes:
The class statement creates a class object and assigns it a name. .Just like the function def statement, the Python class statement is an executable statement. When reached and run, it generates a new class object and assigns it to the name in the class header. Also, like defs, class statements typically run when the files they are coded in are first imported.
Assignment inside the class statements make class attributes. Just like in module files, top-level assignments within a class statement (not nested in a def) generate attributes in a class object. Technically, the class statement defines a local scope that morphs into the attribute namespace of the class object, just like a module’s global scope. After running a class statement, class attributes are accessed by name qualification: object.name.
Class attributes provide object state and behavior. Attributes of a class object record state information and behavior to be shared by all instances created from the class; function def statements nested inside a class generate methods, which process instances.
6-2-1-2) Instance Objects Are Concrete Items
When we call a class object, we get an instance object, Here’s an overview of the key points behind class instances:
Calling a class object like a function makes a new instance object. Each time a class is called, it creates and returns a new instance object. Instances represent concrete items in your program’s domain.
Each instance object inherits class attributes and gets its own namespace.Instance objects created from classes are new namespaces; they start out empty but inherit attributes that live in the class objects from which they were generated.
Assignments to attributes of self in methods make per-instance attributes. Inside a class’s method functions, the first argument (called self by convention) references the instance object being processed; assignments to attributes of self create or change data in the instance, not the class.
6-2-1-3) A First Example
>>> class FirstClass: # Define a class object
def setdata(self, value): # Define class's methods
self.data = value # self is the instance
def display(self):
print(self.data) # self.data: per instance
>>> x = FirstClass() # Make two instances
>>> y = FirstClass() # Each is a new namespaceBy calling the class this way (notice the parentheses), we generate instance objects, which are just namespaces that have access to their classes’ attributes. Properly speaking, at this point, we have three objects: two instances and a class. Really, we have three linked namespaces. In OOP terms, we say that x “is a” FirstClass, as is y—they both inherit names attached to the class.
>>> x.setdata("King Arthur") # Call methods: self is x
>>> y.setdata(3.14159) # Runs: FirstClass.setdata(y, 3.14159)
>>> x.display() # self.data differs in each instance
King Arthur
>>> y.display() # Runs: FirstClass.display(y)
3.141596-2-2) Classes Are Customized by Inheritance
Let’s move on to the second major distinction of classes. Beside serving as factories for generating multiple instance objects, classes also allow us to make changes by introducing new component (called subclasses), instead of changing existing components in place.
In Python, instances inherit from classes, and classes inherit from superclasses. Here are the key ideas behind the machinery of attribute inheritance:
Superclasses are listed in parentheses in a class header. To make a class inherit attribute from another class, just list the other class in parentheses in the new class statement’s header line. The class that inherits is usually called a subclass, and the class that is inherited from is its superclass.
Classes inherit attributes from their superclasses. Justasinstancesinheritthe attribute names defined in their classes, classes inherit all of the attribute names defined in their superclasses; Python finds them automatically when they’re ac- cessed, if they don’t exist in the subclasses.
Instances inherit attributes from all accessible classes. Each instance gets names from the class it’s generated from, as well as all of that class’s superclasses. When looking for a name, Python checks the instance, then its class, then all superclasses.
Each object.attribute reference invokes a new, independent search. Python performs an independent search of the class tree for each attribute fetch expression. This includes references to instances and classes made outside class statements (e.g., X.attr), as well as references to attributes of the self instance argument in a class’s method functions. Each self.attr expression in a method invokes a new search for attr in self and above.
Logic changes are made by subclassing, not by changing superclasses. By redefining superclass names in subclasses lower in the hierarchy (class tree), sub- classes replace and thus customize inherited behavior.
6-2-2-1) Classes Are Attributes in Modules
Before we move on, remember that there’s nothing magic about a class name. It’s just a variable assigned to an object when the class statement runs, and the object can be referenced with any normal expression. For instance, if our FirstClass were coded in a module file instead of being typed interactively, we could import it and use its name normally in a class header line:
from modulename import FirstClass # Copy name into my scope
class SecondClass(FirstClass): # Use class name directly
def display(self): ...
Or, equivalently:
import modulename # Access the whole module
class SecondClass(modulename.FirstClass): # Qualify to reference
def display(self): ...6-2-3) Classes Can Intercept Python Operators
Let’s move on to the third and final major difference between classes and modules: operator overloading. In simple terms, operator overloading lets objects coded with classes intercept and respond to operations that work on built-in types: addition, slic- ing, printing, qualification, and so on. Here is a quick rundown of the main ideas behind overloading operators:
Methods named with the double underscores (_X_) are special hooks. InPython classes we implement operator overloading by providing specially named methods to intercept operations. The Python language defines a fixed and unchangeable mapping from each of these operations to a specially named method.
Such methods are called automatically when instances appear in built-in operations. For instance, if an instance object inherits an add method, that method is called whenever the object appears in a + expression. The method’s return value becomes the result of the corresponding expression.
Classes may override most built-in type operations. There are dozens of special operator overloading method names for intercepting and implementing nearly every operation available for built-in types. This includes expressions, but also basic operations like printing and object creation.
There are no defaults for operator overloading methods, and none are required. If a class does not define or inherit an operator overloading method, it just means that the corresponding operation is not supported for the class’s instances. If there is no add, for example, + expressions raise exceptions.
New-style classes have some defaults, but not for common operations. In Python 3.X, and so-called “new style” classes in 2.X that we’ll define later, a root class named object does provide defaults for some X methods, but not for many, and not for most commonly used operations.
Operations allow classes to integrate with Python’s object model. By over- loading type operations, the user-defined objects we implement with classes can act just like built-ins, and so provide consistency as well as compatibility with expected interfaces.
6-2-3-1) Examples
On to another example. This time, we’ll define a subclass of the prior section’s Second Class that implements three specially named attributes that Python will call automatically:
- init is run when a new instance object is created: self is the new ThirdClass object.
- add is run when a ThirdClass instance appears in a + expression.
- str is run when an object is printed.
>>> class ThirdClass(SecondClass): # Inherit from SecondClass
def __init__(self, value): # On "ThirdClass(value)"
self.data = value
def __add__(self, other): # On "self + other"
return ThirdClass(self.data + other)
def __str__(self): # On "print(self)", "str()"
return '[ThirdClass: %s]' % self.data
def mul(self, other): # In-place change: named
self.data *= other
>>> a = ThirdClass('abc') # __init__ called
>>> a.display() # Inherited method called
Current value = "abc"
>>> print(a) # __str__: returns display string
[ThirdClass: abc]
>>> b = a + 'xyz' # __add__: makes a new instance
>>> b.display() # b has all ThirdClass methods
Current value = "abcxyz"
>>> print(b) # __str__: returns display string
[ThirdClass: abcxyz]
>>> a.mul(3) # mul: changes instance in place
>>> print(a)
[ThirdClass: abcabcabc]6-2-4) Future Directions
We could also expand our scope to use tools that either come with Python or are freely available in the open source world:
GUIs
- As is, we can only process our database with the interactive prompt’s command- based interface, and scripts. We could also work on expanding our object data- base’s usability by adding a desktop graphical user interface for browsing and up- dating its records. GUIs can be built portably with either Python’s tkinter (Tkinter in 2.X) standard library support, or third-party toolkits such as WxPython and PyQt. tkinter ships with Python, lets you build simple GUIs quickly, and is ideal for learning GUI programming techniques; WxPython and PyQt tend to be more complex to use but often produce higher-grade GUIs in the end.
Websites
- Although GUIs are convenient and fast, the Web is hard to beat in terms of acces- sibility. We might also implement a website for browsing and updating records, instead of or in addition to GUIs and the interactive prompt. Websites can be constructed with either basic CGI scripting tools that come with Python, or full- featured third-party web frameworks such as Django, TurboGears, Pylons, web2Py, Zope, or Google’s App Engine. On the Web, your data can still be stored in a shelve, pickle file, or other Python-based medium; the scripts that process it are simply run automatically on a server in response to requests from web browsers and other clients, and they produce HTML to interact with a user, either directly or by interfacing with framework APIs. Rich Internet application (RIA) systems such as Silverlight and pyjamas also attempt to combine GUI-like interactivity with web-based deployment.
Web services
- Although web clients can often parse information in the replies from websites (a technique colorfully known as “screen scraping”), we might go further and provide a more direct way to fetch records on the Web via a web services interface such as SOAP or XML-RPC calls—APIs supported by either Python itself or the third-party open source domain, which generally map data to and from XML format for trans- mission. To Python scripts, such APIs return data more directly than text embed- ded in the HTML of a reply page.
Databases
- If our database becomes higher-volume or critical, we might eventually move it from shelves to a more full-featured storage mechanism such as the open source ZODB object-oriented database system (OODB), or a more traditional SQL-based relational database system such as MySQL, Oracle, or PostgreSQL. Python itself comes with the in-process SQLite database system built-in, but other open source options are freely available on the Web. ZODB, for example, is similar to Python’s shelve but addresses many of its limitations, better supporting larger databases, concurrent updates, transaction processing, and automatic write-through on in- memory changes (shelves can cache objects and flush to disk at close time with their writeback option, but this has limitations: see other resources). SQL-based systems like MySQL offer enterprise-level tools for database storage and may be directly used from a Python script. As we saw in Chapter 9, MongoDB offers an alternative approach that stores JSON documents, which closely parallel Python dictionaries and lists, and are language neutral, unlike pickle data.
ORMs
- If we do migrate to a relational database system for storage, we don’t have to sacrifice Python’s OOP tools. Object-relational mappers (ORMs) like SQLObject and SQLAlchemy can automatically map relational tables and rows to and from Python classes and instances, such that we can process the stored data using normal Python class syntax. This approach provides an alternative to OODBs like shelve and ZODB and leverages the power of both relational databases and Python’s class model.
6-3) Operator Overloading
6-3-1) The Basics
Really “operator overloading” simply means intercepting built-in operations in a class’s methods—Python automatically invokes your methods when instances of the class appear in built-in operations, and your method’s return value becomes the result of the corresponding operation. Here’s a review of the key ideas behind overloading:
- Operator overloading lets classes intercepter normal Python operations.
- Classes can overload all Python expression operations.
- Classes also can overload built-in operations such as printing, function calls, attribute access, etc.
- Overloading makes class instance act more like built-in types.
- Overloading is implemented by provided specially named methods in a class.
6-3-1-1) Constructors and Expressions: init and sub
As a review, consider the following simple example: its Number class, coded in the file number.py, provides a method to intercept instance construction (init), as well as one for catching subtraction expressions (sub). Special methods such as these are the hooks that let you tie into built-in operations:
# File number.py
class Number:
def __init__(self, start): # On Number(start)
self.data = start
def __sub__(self, other): # On instance - other
return Number(self.data - other) # Result is a new instance
>>> from number import Number # Fetch class from module
>>> X = Number(5) # Number.__init__(X, 5)
>>> Y= X - 2 # Number.__sub__(X, 2)
>>> Y.data # Y is new Number instance
36-3-1-2) Common Operator Overloading Methods


6-4) Advanced Class Topics
6-4-1) The “New Style” Class Model
- In Python 3.X, all classes are automatically what were formerly called “new style” whether they explicitly inherit from object or not. Coding the object superclass is optional and implied.
- In Python 2.X, classes must explicitly inherit from object (or an other built-in type) to be considered “new style” and enable and obtain all new-style behavior. Classes without this are “classic.”
class newstyle(object): # 2.X explicit new-style derivation ...normal class code... # Not required in 3.X: automatic6-4-2) New-Style Classes changes
Here are some of the most prominent ways they differ:
Attribute fetch for built-ins: instance skipped
The getattr and getattribute generic attribute interception methods are still run for attributes accessed by explicit name, but no longer for attributes implicitly fetched by built-in operations. They are not called for X operator over- loading method names in built-in contexts only—the search for such names begins at classes, not instances. This breaks or complicates objects that serve as proxies for another object’s interface, if wrapped objects implement operator overloading. Such methods must be redefined for the sake of differing built-ins dispatch in new- style classes.Classes and types merged: type testing
Classes are now types, and types are now classes. In fact, the two are essentially synonyms, though the metaclasses that now subsume types are still somewhat dis- tinct from normal classes. The type(I) built-in returns the class an instance is made from, instead of a generic instance type, and is normally the same as I.class. Moreover, classes are instances of the type class, and type may be subclassed to customize class creation with metaclasses coded with class statements. This can impact code that tests types or otherwise relies on the prior type model.Automatic object root class: defaults
All new-style classes (and hence types) inherit from object, which comes with a small set of default operator overloading methods (e.g., repr). In 3.X, this class is added automatically above the user-defined root (i.e., topmost) classes in a tree, and need not be listed as a superclass explicitly. This can affect code that assumes the absence of method defaults and root classes.Inheritance search order: MRO and diamonds
Diamond patterns of multiple inheritance have a slightly different search order— roughly, at diamonds they are searched across before up, and more breadth-first than depth-first. This attribute search order, known as the MRO, can be traced with a new mro attribute available on new-style classes. The new search order largely applies only to diamond class trees, though the new model’s implied object root itself forms a diamond in all multiple inheritance trees. Code that relies on the prior order will not work the same.Inheritance algorithm:
The algorithm used for inheritance in new-style classes is substantially more complex than the depth-first model of classic classes, incorporating special cases for descriptors, metaclasses, and built-ins.New advanced tools: code impacts
New-style classes have a set of new class tools, including slots, properties, descriptors, super, and the getattribute method. Most of these have very specific tool-building purposes. Their use can also impact or break existing code, though; slots, for example, sometimes prevent creation of an instance namespace dictionary altogether, and generic attribute handlers may require different coding.
6-4-2-1) Diamond Inheritance Change
For classic classes (the default in 2.X): DFLR
The inheritance search path is strictly depth first, and then left to right—Python climbs all the way to the top, hugging the left side of the tree, before it backs up and begins to look further to the right. This search order is known as DFLR for the first letters in its path’s directions.For new-style classes (optional in 2.X and automatic in 3.X): MRO
The inheritance search path is more breadth-first in diamond cases—Python first looks in any superclasses to the right of the one just searched before ascending to the common superclass at the top. In other words, this search proceeds across by levels before moving up. This search order is called the new-style MRO for “method resolution order” (and often just MRO for short when used in contrast with the DFLR order). Despite the name, this is used for all attributes in Python, not just methods.
6-4-2-1-1) Implications for diamond inheritance trees
To illustrate how the new-style MRO search differs, consider this simplistic incarnation of the diamond multiple inheritance pattern for classic classes. Here, D’s superclasses B and C both lead to the same common ancestor, A:
class A: attr = 1 # Classic (Python 2.X)
class B(A): pass # B and C both lead to A
class C(A): attr = 2
class D(B, C): pass # Tries A before C
>>> x = D()
>>> x.attr # Searches x, D, B, A
1The attribute x.attr here is found in superclass A, because with classic classes, the inheritance search climbs as high as it can before backing up and moving right. The full DFLR search order would visit x, D, B, A, C, and then A. For this attribute, the search stops as soon as attr is found in A, above B.
However, with new-style classes derived from a built-in like object (and all classes in 3.X), the search order is different: Python looks in C to the right of B, before trying A above B. The full MRO search order would visit x, D, B, C, and then A. For this attribute, the search stops as soon as attr is found in C.
6-4-2-1-2) Explicit conflict resolution
Of course, the problem with assumptions is that they assume things! If this search order deviation seems too subtle to remember, or if you want more control over the search process, you can always force the selection of an attribute from anywhere in the tree by assigning or otherwise naming the one you want at the place where the classes are mixed together. The following, for example, chooses new-style order in a classic class by resolving the choice explicitly:
>>> class A: attr = 1 # Classic
>>> class B(A): pass
>>> class C(A): attr = 2
>>> class D(B, C): attr = C.attr # <== Choose C, to the right
>>> x = D()
>>> x.attr # Works like new-style (all 3.X)
2Here, a tree of classic classes is emulating the search order of new-style classes for a specific attribute: the assignment to the attribute in D picks the version in C, thereby subverting the normal inheritance search path (D.attr will be lowest in the tree). New- style classes can similarly emulate classic classes by choosing the higher version of the target attribute at the place where the classes are mixed together:
>>> class A: attr = 1 # New-style
>>> class B(A): pass
>>> class C(A): attr = 2
>>> class D(B, C): attr = B.attr # <== Choose A.attr, above
>>> x = D()
>>> x.attr # Works like classic (default 2.X)
16-4-2-2) More on the MRO: Method Resolution Order
To trace how new-style inheritance works by default, we can also use the new class.mro attribute mentioned in the preceding chapter’s class lister examples— technically a new-style extension, but useful here to explore a change. This attribute returns a class’s MRO—the order in which inheritance searches classes in a new-style class tree. This MRO is based on the C3 superclass linearization algorithm initially developed in the Dylan programming language, but later adopted by other languages including Python 2.3 and Perl 6.
6-4-3) New-Style Class Extensions
6-4-3-1) Slots: Attribute Declarations
By assigning a sequence of string attribute names to a special slots class attribute, we can enable a new-style class to both limit the set of legal attributes that instances of the class will have, and optimize memory usage and possibly program speed. As we’ll find, though, slots should be used only in applications that clearly warrant the added complexity. They will complicate your code, may complicate or break code you may use, and require universal deployment to be effective.
6-4-3-1-1) Slot basics
To use slots, assign a sequence of string names to the special slots variable and attribute at the top level of a class statement: only those names in the slots list can be assigned as instance attributes. However, like all names in Python, instance attribute names must still be assigned before they can be referenced, even if they’re listed in slots:
>>> class limiter(object):
__slots__ = ['age', 'name', 'job']
>>> x = limiter()
>>> x.age # Must assign before use
AttributeError: age
>>> x.age = 40 # Looks like instance data
>>> x.age
40
>>> x.ape = 1000 # Illegal: not in __slots__
AttributeError: 'limiter' object has no attribute 'ape'This feature is envisioned as both a way to catch typo errors like this (assignments to illegal attribute names not in slots are detected) as well as an optimization mechanism.
6-4-3-1-2) Slots and namespace dictionaries
Potential benefits aside, slots can complicate the class model—and code that relies on it—substantially. In fact, some instances with slots may not have a dict attribute namespace dictionary at all, and others will have data attributes that this dictionary does not include. To be clear: this is a major incompatibility with the traditional class model—one that can complicate any code that accesses attributes generically, and may even cause some programs to fail altogether.
Let’s see what this means in terms of code, and explore more about slots along the way. First off, when slots are used, instances do not normally have an attribute dictionary —instead, Python uses the class descriptors feature introduced ahead to allocate and manage space reserved for slot attributes in the instance. In Python 3.X, and in 2.X for new-style classes derived from object:
>>> class C: # Requires "(object)" in 2.X only
__slots__ = ['a', 'b'] # __slots__ means no __dict__ by default
>>> X = C()
>>> X.a = 1
>>> X.a
1
>>> X.__dict__
AttributeError: 'C' object has no attribute '__dict__'However, we can still fetch and set slot-based attributes by name string using storage- neutral tools such as getattr and setattr (which look beyond the instance dict and thus include class-level names like slots) and dir (which collects all inherited names throughout a class tree):
>>> getattr(X, 'a')
1
>>> setattr(X, 'b', 2) # But getattr() and setattr() still work
>>> X.b
2
>>> 'a' in dir(X) # And dir() finds slot attributes too
True
>>> 'b' in dir(X)
TrueAlso keep in mind that without an attribute namespace dictionary, it’s not possible to assign new names to instances that are not names in the slots list:
>>> class D: # Use D(object) for same result in 2.X
__slots__ = ['a', 'b']
def __init__(self):
self.d = 4 # Cannot add new names if no __dict__
>>> X = D()
AttributeError: 'D' object has no attribute 'd'We can still accommodate extra attributes, though, by including dict explicitly in slots, in order to create an attribute namespace dictionary too:
>>> class D:
__slots__ = ['a', 'b', '__dict__'] # Name __dict__ to include one too
c = 3 # Class attrs work normally
def __init__(self):
self.d = 4 # d stored in __dict__, a is a slot
>>> X = D()
>>> X.d
4
>>> X.c
3
>>> X.a
AttributeError: a # All instance attrs undefined until assigned
>>> X.a = 1
>>> X.b = 2In this case, both storage mechanisms are used. This renders dict too limited for code that wishes to treat slots as instance data, but generic tools such as getattr still allow us to process both storage forms as a single set of attributes:
>>> X.__dict__ # Some objects have both __dict__ and slot names {'d': 4} # getattr() can fetch either type of attr
>>> X.__slots__
['a', 'b', '__dict__']
>>> getattr(X, 'a'), getattr(X, 'c'), getattr(X, 'd') # Fetches all 3 forms
(1, 3, 4)6-4-3-1-3) Multiple slot lists in superclasses
The preceding code works in this specific case, but in general it’s not entirely accu- rate. Specifically, this code addresses only slot names in the lowest slots attribute inherited by an instance, but slot lists may appear more than once in a class tree. That is, a name’s absence in the lowest slots list does not preclude its existence in a higher slots. Because slot names become class-level attributes, instances acquire the union of all slot names anywhere in the tree, by the normal inheritance rule:
>>> class E:
__slots__ = ['c', 'd'] # Superclass has slots
>>> class D(E):
__slots__ = ['a', '__dict__'] # But so does its subclass
>>> X = D()
>>> X.a = 1; X.b = 2; X.c = 3 # The instance is the union (slots: a, c)
>>> X.a, X.c
(1, 3)Inspecting just the inherited slots list won’t pick up slots defined higher in a class tree:
>>> E.__slots__ # But slots are not concatenated
['c', 'd']
>>> D.__slots__
['a', '__dict__']
>>> X.__slots__ # Instance inherits *lowest* __slots__
['a', '__dict__']
>>> X.__dict__ # And has its own an attr dict
{'b': 2}
>>> for attr in list(getattr(X, '__dict__', [])) + getattr(X, '__slots__', []):
print(attr, '=>', getattr(X, attr))
b => 2 # Other superclass slots missed!
a => 1
__dict__ => {'b': 2}
>>> dir(X) # But dir() includes all slot names
[...many names omitted... 'a', 'b', 'c', 'd']6-4-3-1-4) Slot usage rules
Slots in subs are pointless when absent in supers : If a subclass inherits from a superclass without a slots, the instance dict attribute created for the superclass will always be accessible, making a slots in the subclass largely point- less. The subclass still manages its slots, but doesn’t compute their values in any way, and doesn’t avoid a dictionary—the main reason to use slots.
Slots in supers are pointless when absent in subs : Similarly, because the meaning of a slots declaration is limited to the class in which it appears, subclasses will produce an instance dict if they do not define a slots, rendering a slots in a superclass largely pointless.
Redefinition renders super slots pointless: If a class defines the same slot name as a superclass, its redefinition hides the slot in the superclass per normal inheritance. You can access the version of the name defined by the superclass slot only by fetching its descriptor directly from the superclass.
Slots prevent class-level defaults: Because slots are implemented as class-level descriptors (along with per-instance space), you cannot use class attributes of the same name to provide defaults as you can for normal instance attributes: assigning the same name in the class overwrites the slot descriptor.
Slots and dict: As shown earlier, slots preclude both an instance dict and assigning names not listed, unless dict is listed explicitly too.
6-4-3-2) Properties: Attribute Accessors
6-4-3-2-1) Property basics
As a brief introduction, though, a property is a type of object assigned to a class attribute name. You generate a property by calling the property built-in function, passing in up to three accessor methods—handlers for get, set, and delete operations—as well as an optional docstring for the property. If any argument is passed as None or omitted, that operation is not supported.
The resulting property object is typically assigned to a name at the top level of a class statement (e.g., name=property()), and a special @ syntax we’ll meet later is avail- able to automate this step. When thus assigned, later accesses to the class property name itself as an object attribute (e.g., obj.name) are automatically routed to one of the accessor methods passed into the property call.
For example, we’ve seen how the getattr operator overloading method allows classes to intercept undefined attribute references in both classic and new-style classes:
>>> class operators:
def __getattr__(self, name):
if name == 'age':
return 40
else:
raise AttributeError(name)
>>> x = operators()
>>> x.age # Runs __getattr__
40
>>> x.name # Runs __getattr__
AttributeError: nameHere is the same example, coded with properties instead; note that properties are available for all classes but require the new-style object derivation in 2.X to work prop- erly for intercepting attribute assignments (and won’t complain if you forget this—but will silently overwrite your property with the new data!):
>>> class properties(object): # Need object in 2.X for setters
def getage(self):
return 40
age = property(getage, None, None, None) # (get, set, del, docs), or use @
>>> x = properties()
>>> x.age # Runs getage
40
>>> x.name # Normal fetch
AttributeError: 'properties' object has no attribute 'name'For some coding tasks, properties can be less complex and quicker to run than the traditional techniques. For example, when we add attribute assignment support, prop- erties become more attractive—there’s less code to type, and no extra method calls are incurred for assignments to attributes we don’t wish to compute dynamically:
>>> class properties(object): # Need object in 2.X for setters
def getage(self):
return 40
def setage(self, value):
print('set age: %s' % value)
self._age = value
age = property(getage, setage, None, None)
>>> x = properties()
>>> x.age # Runs getage
40
>>> x.age = 42 # Runs setage
set age: 42
>>> x._age # Normal fetch: no getage call
42
>>> x.age # Runs getage
40
>>> x.job = 'trainer' # Normal assign: no setage call
>>> x.job # Normal fetch: no getage call
'trainer'>>> class operators:
def __getattr__(self, name): # On undefined reference
if name == 'age':
return 40
else:
raise AttributeError(name)
def __setattr__(self, name, value): # On all assignments
print('set: %s %s' % (name, value))
if name == 'age':
self.__dict__['_age'] = value # Or object.__setattr__()
else:
self.__dict__[name] = value
>>> x = operators()
>>> x.age # Runs __getattr__
40
>>> x.age = 41 # Runs __setattr__
set: age 41
>>> x._age # Defined: no __getattr__ call
41
>>> x.age # Runs __getattr__
40
>>> x.job = 'trainer' # Runs __setattr__ again
set: job trainer
>>> x.job # Defined: no __getattr__ call
'trainer'Properties seem like a win for this simple example. However, some applications of getattr and setattr still require more dynamic or generic interfaces than properties directly provide.
As we’ll see there, it’s also possible to code properties using the @ symbol function decorator syntax—a topic introduced later in this chapter, and an equivalent and au- tomatic alternative to manual assignment in the class scope:
class properties(object):
@property # Coding properties with decorators: ahead
def age(self):
...
@age.setter
def age(self, value):
...6-4-3-2-2) getattribute and Descriptors: Attribute Tools
Also in the class extensions department, the getattribute operator overloading method, available for new-style classes only, allows a class to intercept all attribute references, not just undefined references. This makes it more potent than its get attr cousin we used in the prior section, but also trickier to use—it’s prone to loops much like setattr, but in different ways.
For more specialized attribute interception goals, in addition to properties and operator overloading methods, Python supports the notion of attribute descriptors—classes with get and set methods, assigned to class attributes and inherited by instances, that intercept read and write accesses to specific attributes. As a preview, here’s one of the simplest descriptors you’re likely to encounter:
>>> class AgeDesc(object):
def __get__(self, instance, owner): return 40
def __set__(self, instance, value): instance._age = value
>>> class descriptors(object):
age = AgeDesc()
>>> x = descriptors()
>>> x.age # Runs AgeDesc.__get__
40
>>> x.age = 42 # Runs AgeDesc.__set__
>>> x._age # Normal fetch: no AgeDesc call
42Descriptors have access to state in instances of themselves as well as their client class, and are in a sense a more general form of properties; in fact, properties are a simplified way to define a specific type of descriptor—one that runs functions on access. De- scriptors are also used to implement the slots feature we met earlier, and other Python tools.
6-4-4) Static and Class Methods
As of Python 2.2, it is possible to define two kinds of methods within a class that can be called without an instance: static methods work roughly like simple instance-less functions inside a class, and class methods are passed a class instead of an instance. Both are similar to tools in other languages (e.g., C++ static methods). Although this feature was added in conjunction with the new-style classes discussed in the prior sec- tions, static and class methods work for classic classes too.
To enable these method modes, you must call special built-in functions named staticmethod and classmethod within the class, or invoke them with the special @name decoration syntax we’ll meet later in this chapter. These functions are required to enable these special method modes in Python 2.X, and are generally needed in 3.X. In Python 3.X, a staticmethod declaration is not required for instance-less methods called only through a class name, but is still required if such methods are called through instances.
6-4-4-1) Static Methods in 2.X and 3.X
- In Python 2.X, we must always declare a method as static in order to call it without an instance, whether it is called through a class or an instance.
• InPython3.X, we need not declare such methods as static if they will be called through a class only, but we must do so in order to call them through an instance.
class Spam: numInstances = 0 def __init__(self):
Spam.numInstances = Spam.numInstances + 1 def printNumInstances():
print("Number of instances created: %s" % Spam.numInstances)
>>> from spam import Spam
>>> a = Spam()
>>> b = Spam()
>>> c = Spam()
Spam.printNumInstances() # Fails in 2.X, works in 3.X
instance.printNumInstances() # Fails in both 2.X and 3.X (unless static)6-4-4-2) Static Method Alternatives
Short of marking a self-less method as special, you can sometimes achieve similar results with different coding structures. For example, if you just want to call functions that access class members without an instance, perhaps the simplest idea is to use normal functions outside the class, not class methods. This way, an instance isn’t ex- pected in the call. The following mutation of spam.py illustrates, and works the same in Python 3.X and 2.X:
def printNumInstances():
print("Number of instances created: %s" % Spam.numInstances)
class Spam:
numInstances = 0
def __init__(self):
Spam.numInstances = Spam.numInstances + 1
C:\code> c:\python33\python
>>> import spam
>>> a = spam.Spam()
>>> b = spam.Spam()
>>> c = spam.Spam()
>>> spam.printNumInstances() # But function may be too far removed
Number of instances created: 3 # And cannot be changed via inheritance
>>> spam.Spam.numInstances
3Unfortunately, this approach is still less than ideal. For one thing, it adds to this file’s scope an extra name that is used only for processing a single class. For another, the function is much less directly associated with the class by structure; in fact, its definition could be hundreds of lines away. Perhaps worse, simple functions like this cannot be customized by inheritance, since they live outside a class’s namespace: subclasses cannot directly replace or extend such a function by redefining it.
6-4-4-3) Using Static and Class Methods
Today, there is another option for coding simple functions associated with a class that may be called through either the class or its instances. As of Python 2.2, we can code classes with static and class methods, neither of which requires an instance argument to be passed in when invoked. To designate such methods, classes call the built-in functions staticmethod and classmethod, as hinted in the earlier discussion of new-style classes. Both mark a function object as special—that is, as requiring no instance if static and requiring a class argument if a class method. For example, in the file bothmethods.py (which unifies 2.X and 3.X printing with lists, though displays still vary slightly for 2.X classic classes):
# File bothmethods.py
class Methods:
def imeth(self, x): # Normal instance method: passed a self
print([self, x])
def smeth(x): # Static: no instance passed
print([x])
def cmeth(cls, x): # Class: gets class, not instance
print([cls, x])
smeth = staticmethod(smeth) # Make smeth a static method (or @: ahead)
cmeth = classmethod(cmeth) # Make cmeth a class method (or @: ahead)Technically, Python now supports three kinds of class-related methods, with differing argument protocols:
- Instance methods, passed a self instance object (the default)
- Static methods, passed no extra object (via staticmethod)
- Classmethods, passed a class object (via classmethod, and inherent in metaclasses)
6-4-5) Decorators and Metaclasses: Part 1
Because the staticmethod and classmethod call technique described in the prior section initially seemed obscure to some observers, a device was eventually added to make the operation simpler. Python decorators—similar to the notion and syntax of annotations in Java—both addressed this specific need and provided a general tool for adding logic that manages both functions and classes, or later calls to them.
This is called a “decoration,” but in more concrete terms is really just a way to run extra processing steps at function and class definition time with explicit syntax. It comes in two flavors:
Function decorators—the initial entry in this set, added in Python2.4—augment function definitions. They specify special operation modes for both simple functions and classes’ methods by wrapping them in an extra layer of logic implemented as another function, usually called a metafunction.
Class decorators—a later extension, added in Python 2.6 and 3.0—augment class definitions. They do the same for classes, adding support for management of whole objects and their interfaces. Though perhaps simpler, they often overlap in roles with metaclasses.
Function decorators turn out to be very general tools: they are useful for adding many types of logic to functions besides the static and class method use cases. For instance, they may be used to augment functions with code that logs calls made to them, checks the types of passed arguments during debugging, and so on. Function decorators can be used to manage either functions themselves or later calls to them. In the latter mode, function decorators are similar to the delegation design pattern, but they are designed to augment a specific function or method call, not an entire object interface.
6-4-5-1) Function Decorator Basics
Syntactically, a function decorator is a sort of runtime declaration about the function that follows. A function decorator is coded on a line by itself just before the def state- ment that defines a function or method. It consists of the @ symbol, followed by what we call a metafunction—a function (or other callable object) that manages another function. Static methods since Python 2.4, for example, may be coded with decorator syntax like this:
class C:
@staticmethod # Function decoration syntax
def meth():
...Internally, this syntax has the same effect as the following—passing the function through the decorator and assigning the result back to the original name:
class C:
def meth():
...
meth = staticmethod(meth) # Name rebinding equivalentDecoration rebinds the method name to the decorator’s result. The net effect is that calling the method function’s name later actually triggers the result of its staticme thod decorator first. Because a decorator can return any sort of object, this allows the decorator to insert a layer of logic to be run on every call. The decorator function is free to return either the original function itself, or a new proxy object that saves the original function passed to the decorator to be invoked indirectly after the extra logic layer runs.
6-4-5-2) A First Look at User-Defined Function Decorators
The call operator overloading method implements a function-call interface for class instances. The following code uses this to define a call proxy class that saves the decorated function in the instance and catches calls to the original name. Because this is a class, it also has state information—a counter of calls made:
class tracer:
def __init__(self, func): # Remember original, init counter
self.calls = 0
self.func = func
def __call__(self, *args): # On later calls: add logic, run original
self.calls += 1
print('call %s to %s' % (self.calls, self.func.__name__))
return self.func(*args)
@tracer # Same as spam = tracer(spam)
def spam(a, b, c): # Wrap spam in a decorator object
return a + b + c
print(spam(1, 2, 3)) # Really calls the tracer wrapper object
print(spam('a', 'b', 'c')) # Invokes __call__ in class
c:\code> python tracer1.py
call 1 to spam
6
call 2 to spam
abcBecause the spam function is run through the tracer decorator, when the original spam name is called it actually triggers the call method in the class. This method counts and logs the call, and then dispatches it to the original wrapped function. Note how the *name argument syntax is used to pack and unpack the passed-in arguments; because of this, this decorator can be used to wrap any function with any number of positional arguments.
For example, by using nested functions with enclosing scopes for state, instead of call- able class instances with attributes, function decorators often become more broadly applicable to class-level methods too. We’ll postpone the full details on this, but here’s a brief look at this closure based coding model; it uses function attributes for counter state for portability, but could leverage variables and nonlocal instead in 3.X only:
def tracer(func): # Remember original
def oncall(*args): # On later calls
oncall.calls += 1
print('call %s to %s' % (oncall.calls, func.__name__))
return func(*args)
oncall.calls = 0
return oncall
class C:
@tracer
def spam(self,a, b, c):
return a + b + c
x = C()
print(x.spam(1, 2, 3))
print(x.spam('a', 'b', 'c')) # Same output as tracer1 (in tracer2.py)6-4-5-3) A First Look at Class Decorators and Metaclasses
Function decorators turned out to be so useful that Python 2.6 and 3.0 expanded the model, allowing decorators to be applied to classes as well as functions. In short, class decorators are similar to function decorators, but they are run at the end of a class statement to rebind a class name to a callable. As such, they can be used to either manage classes just after they are created, or insert a layer of wrapper logic to manage instances when they are later created. Symbolically, the code structure:
def decorator(aClass): ...
@decorator # Class decoration syntax
class C: ...is mapped to the following equivalent:
def decorator(aClass): ...
class C: ... # Name rebinding equivalent
C = decorator(C)class decorators can also manage an object’s entire interface by intercepting construction calls, and wrapping the new instance object in a proxy that deploys attribute accessor tools to intercept later requests—a multilevel coding technique we’ll use to implement class attribute privacy in later chaper. Here’s a preview of the model:
def decorator(cls): # On @ decoration
class Proxy:
def __init__(self, *args): # On instance creation: make a cls
self.wrapped = cls(*args)
def __getattr__(self, name): # On attribute fetch: extra ops here
return getattr(self.wrapped, name)
return Proxy
@decorator
class C: ... # Like C = decorator(C)
X = C() # Makes a Proxy that wraps a C, and catches later X.attrMetaclasses, mentioned briefly earlier, are a similarly advanced class-based tool whose roles often intersect with those of class decorators. They provide an alternate model, which routes the creation of a class object to a subclass of the top-level type class, at the conclusion of a class statement:
class Meta(type):
def __new__(meta, classname, supers, classdict):
...extra logic + class creation via type call...
class C(metaclass=Meta):
...my creation routed to Meta... # Like C = Meta('C', (), {...})In Python 2.X, the effect is the same, but the coding differs—use a class attribute instead of a keyword argument in the class header:
class C:
__metaclass__ = Meta
... my creation routed to Meta...To assume control of the creation or initialization of a new class object, a metaclass generally redefines the new or init method of the type class that normally intercepts this call. The net effect, as with class decorators, is to define code to be run automatically at class creation time.
6-4-6) The super Built-in Function: For Better or Worse?
6-4-6-1) The Great super Debate
Python has a super built-in function that can be used to invoke superclass methods generically, but was deferred until this point of the book. This was deliberate—because super has substantial downsides in typical code, and a sole use case that seems obscure and complex to many observers, most beginners are better served by the traditional explicit-name call scheme used so far.
The Python community itself seems split on this subject, with online articles about it running the gamut from “Python’s Super Considered Harmful” to “Python’s super() considered super!”3 Frankly, in my live classes this call seems to be most often of interest to Java programmers starting to use Python anew, because of its conceptual similarity to a tool in that language (many a new Python feature ultimately owes its existence to programmers of other languages bringing their old habits to a new model). Python’s super is not Java’s—it translates differently to Python’s multiple inheritance, and has a use case beyond Java’s—but it has managed to generate both controversy and misunderstanding since its conception.
6-4-6-2) Traditional Superclass Call Form: Portable, General
In general, this book’s examples prefer to call back to superclass methods when needed by naming the superclass explicitly, because this technique is traditional in Python, because it works the same in both Python 2.X and 3.X, and because it sidesteps limi- tations and complexities related to this call in both 2.X and 3.X. As shown earlier, the traditional superclass method call scheme to augment a superclass method works as follows:
>>> class C: # In Python 2.X and 3.X
def act(self):
print('spam')
>>> class D(C):
def act(self):
C.act(self) # Name superclass explicitly, pass self
print('eggs')
>>> X = D()
>>> X.act()
spam
eggsThis form works the same in 2.X and 3.X, follows Python’s normal method call map- ping model, applies to all inheritance tree forms, and does not lead to confusing be- havior when operator overloading is used. To see why these distinctions matter, let’s see how super compares.
6-4-6-3) Basic super Usage and Its Tradeoffs
In this section, we’ll both introduce super in basic, single-inheritance mode, and look at its perceived downsides in this role. As we’ll find, in this context super does work as advertised, but is not much different from traditional calls, relies on unusual semantics, and is cumbersome to deploy in 2.X. More critically, as soon as your classes grow to use multiple inheritance, this super usage mode can both mask problems in your code and route calls in ways you may not expect.
6-4-6-3-1) Odd semantics: A magic proxy in Python 3.X
The role we’re interested in here is more commonly used, and more frequently reques- ted by people with Java backgrounds—to allow superclasses to be named generically in inheritance trees. This is intended to promote simpler code maintenance, and to avoid having to type long superclass reference paths in calls. In Python 3.X, this call seems at least at first glance to achieve this purpose well:
>>> class C: # In Python 3.X (only: see 2.X super form ahead)
def act(self):
print('spam')
>>> class D(C):
def act(self):
super().act() # Reference superclass generically, omit self
print('eggs')
>>> X = D()
>>> X.act()
spam
eggsThis works, and minimizes code changes—you don’t need to update the call if D’s superclass changes in the future. One of the biggest downsides of this call in 3.X, though, is its reliance on deep magic: though prone to change, it operates today by inspecting the call stack in order to automatically locate the self argument and find the superclass, and pairs the two in a special proxy object that routes the later call to the superclass version of the method. If that sounds complicated and strange, it’s be- cause it is. In fact, this call form doesn’t work at all outside the context of a class’s method:
>>> super # A "magic" proxy object that routes later calls Really, this call’s semantics resembles nothing else in Python—it’s neither a bound nor unbound method, and somehow finds a self even though you omit one in the call. In single inheritance trees, a superclass is available from self via the path self.class.bases[0], but the heavily implicit nature of this call makes this difficult to see, and even flies in the face of Python’s explicit self policy that holds true everywhere else. That is, this call violates a fundamental Python idiom for a single use case. It also soundly contradicts Python’s longstanding EIBTI design rule (run an “im- port this” for more on this rule).
6-4-6-3-2) Pitfall: Adding multiple inheritance naively
Besides its unusual semantics, even in 3.X this super role applies most directly to single inheritance trees, and can become problematic as soon as classes employ multiple in- heritance with traditionally coded classes. This seems a major limitation of scope; due to the utility of mix-in classes in Python, multiple inheritance from disjoint and inde- pendent superclasses is probably more the norm than the exception in realistic code. The super call seems a recipe for disaster in classes coded to naively use its basic mode, without allowing for its much more subtle implications in multiple inheritance trees.
If such classes later grow to use more than one superclass, though, super can become error-prone, and even unusable—it does not raise an exception for multiple inheritance trees, but will naively pick just the leftmost superclass having the method being run (technically, the first per the MRO), which may or may not be the one that you want:
>>> class C(A, B): # Add a B mix-in class with the same method
def act(self):
super().act() # Doesn't fail on multi-inher, but picks just one!
>>> X = C()
>>> X.act()
A
>>> class C(B, A):
def act(self):
super().act() # If B is listed first, A.act() is no longer run!
>>> X = C()
>>> X.act()
BThe crucial point here is that using super for just the single inheritance cases where it applies most clearly is a potential source of error and confusion, and means that programmers must remember two ways to accomplish the same goal, when just one— explicit direct calls—could suffice for all cases.
7) Exceptions and Tools
7-1) Exception Basics
In Python, exceptions are triggered automatically on errors, and they can be triggered and intercepted by your code. They are processed by four statements we’ll study in this part, the first of which has two variations (listed separately here) and the last of which was an optional extension until Python 2.6 and 3.0:
try/except
Catch and recover from exceptions raised by Python, or by you.try/finally
Perform cleanup actions, whether exceptions occur or not.raise
Trigger an exception manually in your code.assert
Conditionally trigger an exception in your code.with/as
Implement context managers in Python 2.6, 3.0, and later (optional in 2.5).
7-1-1) Exception Roles
In Python programs, exceptions are typically used for a variety of purposes. Here are some of their most common roles:
Error handling
Python raises exceptions whenever it detects errors in programs at runtime. You can catch and respond to the errors in your code, or ignore the exceptions that are raised. If an error is ignored, Python’s default exception-handling behavior kicks in: it stops the program and prints an error message. If you don’t want this default behavior, code a try statement to catch and recover from the exception—Python will jump to your try handler when the error is detected, and your program will resume execution after the try.Event notification
Exceptions can also be used to signal valid conditions without you having to pass result flags around a program or test them explicitly. For instance, a search routine might raise an exception on failure, rather than returning an integer result code— and hoping that the code will never be a valid result!Special-case handling
Sometimes a condition may occur so rarely that it’s hard to justify convoluting your code to handle it in multiple places. You can often eliminate special-case code by handling unusual cases in exception handlers in higher levels of your program. An assert can similarly be used to check that conditions are as expected during de- velopment.Termination actions
As you’ll see, the try/finally statement allows you to guarantee that required closing-time operations will be performed, regardless of the presence or absence of exceptions in your programs. The newer with statement offers an alternative in this department for objects that support it.Unusual control flows
Finally, because exceptions are a sort of high-level and structured “go to,” you can use them as the basis for implementing exotic control flows. For instance, although the language does not explicitly support backtracking, you can implement it in Python by using exceptions and a bit of support logic to unwind assignments.1 There is no “go to” statement in Python (thankfully!), but exceptions can some- times serve similar roles; a raise, for instance, can be used to jump out of multiple loops.
7-1-2) User-Defined Exceptions
User-defined exceptions are coded with classes, which inherit from a built-in exception class: usually the class named Exception:
class AlreadyGotOne(Exception): pass # User-defined exception
def grail():
raise AlreadyGotOne() # Raise an instance
try:
grail()
except AlreadyGotOne: # Catch class name
print('got exception')
exceptionClass-based exceptions allow scripts to build exception categories, which can inherit behavior, and have attached state information and methods. They can also customize their error message text displayed if they’re not caught:
>>> class Career(Exception):
def __str__(self): return 'So I became a waiter...'
>>> raise Career()
Traceback (most recent call last):
File "" , line 1, in __main__.Career: So I became a waiter...
>>> 7-1-3) Termination Actions
Finally, try statements can say “finally”—that is, they may include finally blocks. These look like except handlers for exceptions, but the try/finally combination speci- fies termination actions that always execute “on the way out,” regardless of whether an exception occurs in the try block or not
try:
fetcher(x, 3)
finally:
print('after fetch')7-2) Exception Coding Details
7-2-1) Try Statement Clauses
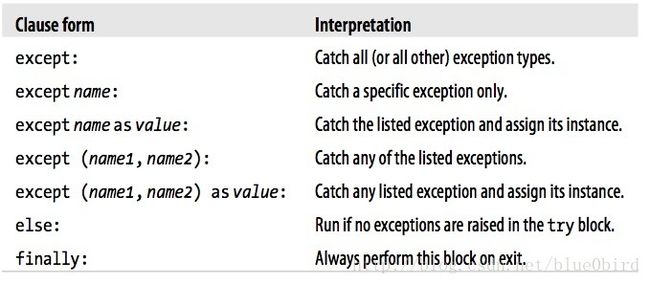
7-2-2) Catching any and all exceptions
except clauses that list no exception name (except:) catch all exceptions not previously listed in the try statement.
except clauses that list a set of exceptions in parentheses (except (e1, e2, e3):)
catch any of the listed exceptions.
Python 3.X more strongly supports an alternative that solves one of these problems— catching an exception named Exception has almost the same effect as an empty except, but ignores exceptions related to system exits:
try:
action()
except Exception:
... # Catch all possible exceptions, except exits7-2-3) The try else Clause
try:
...run code...
except IndexError:
...handle exception...
else:
...no exception occurred...You can almost emulate an else clause by moving its code into the try block:
try:
...run code...
...no exception occurred...
except IndexError:
...handle exception...7-2-4) The raise Statement
To trigger exceptions explicitly, you can code raise statements. Their general form is simple—a raise statement consists of the word raise, optionally followed by the class to be raised or an instance of it:
raise instance # Raise instance of class
raise class # Make and raise instance of class: makes an instance
raise # Reraise the most recent exception
raise IndexError # Class (instance created)
raise IndexError() # Instance (created in statement)
exc = IndexError() # Create instance ahead of time
raise exc
excs = [IndexError, TypeError]
raise excs[0]7-2-4) Python 3.X Exception Chaining: raise from
Exceptions can sometimes be triggered in response to other exceptions—both delib- erately and by new program errors. To support full disclosure in such cases, Python 3.X (but not 2.X) also allows raise statements to have an optional from clause:
raise newexception from otherexceptionWhen the from is used in an explicit raise request, the expression following from speci- fies another exception class or instance to attach to the cause attribute of the new exception being raised. If the raised exception is not caught, Python prints both ex- ceptions as part of the standard error message:
>>> try:
... 1 / 0
... except Exception as E:
... raise TypeError('Bad') from E # Explicitly chained exceptions
...
Traceback (most recent call last):
File "" , line 2, in ZeroDivisionError: division by zero
The above exception was the direct cause of the following exception:
Traceback (most recent call last): File "" , line 4, in
TypeError: Bad
7-2-5) The assert Statement
As a somewhat special case for debugging purposes, Python includes the assert state-ment. It is mostly just syntactic shorthand for a common raise usage pattern, and an assert can be thought of as a conditional raise statement. A statement of the form:
assert test, data # The data part is optionalworks like the following code:
if __debug__:
if not test:
raise AssertionError(data)As an added feature, assert statements may be removed from a compiled program’s byte code if the -O Python command-line flag is used, thereby optimizing the program. AssertionError is a built-in exception, and the debug flag is a built-in name that is automatically set to True unless the -O flag is used. Use a command line like python –O main.py to run in optimized mode and disable (and hence skip) asserts.
7-2-6) with/as Context Managers
Python 2.6 and 3.0 introduced a new exception-related statement—the with, and its optional as clause. This statement is designed to work with context manager objects, which support a new method-based protocol, similar in spirit to the way that iteration tools work with methods of the iteration protocol. This feature is also available as an option in 2.5, but must be enabled there with an import of this form:
from __future__ import with_statementThe with statement is also similar to a “using” statement in the C# language. Although a somewhat optional and advanced tools-oriented topic (and once a candidate for the next part of the book), context managers are lightweight and useful enough to group with the rest of the exception toolset here.
In short, the with/as statement is designed to be an alternative to a common try/ finally usage idiom; like that statement, with is in large part intended for specifying termination-time or “cleanup” activities that must run regardless of whether an excep- tion occurs during a processing step.
Unlike try/finally, the with statement is based upon an object protocol for specifying actions to be run around a block of code. This makes with less general, qualifies it as redundant in termination roles, and requires coding classes for objects that do not support its protocol. On the other hand, with also handles entry actions, can reduce code size, and allows code contexts to be managed with full OOP.
Python enhances some built-in tools with context managers, such as files that auto- matically close themselves and thread locks that automatically lock and unlock, but programmers can code context managers of their own with classes, too. Let’s take a brief look at the statement and its implicit protocol.
7-2-6-1) Basic Usage
The basic format of the with statement looks like this, with an optional part in square brackets here:
with expression [as variable]:
with-blockThe expression here is assumed to return an object that supports the context management protocol (more on this protocol in a moment). This object may also return a value that will be assigned to the name variable if the optional as clause is present.
7-2-6-2) The Context Management Protocol
Here’s how the with statement actually works:
- The expression is evaluated, resulting in an object known as a context manager that must have enter and exit methods.
- The context’s enter method is called. The value it returns is assigned to the variable in the as clause if present, or simply discarded otherwise.
- The code is nested in the with block is executed.
- If the with block raises an exception, the exit (type, value, traceback) method is called with the exception details. These are the same three values returned by sys.exc_info. If this method returns a false value, the exception is raised; otherwise, the exception is terminated. The exception should normally be reraised so that it is propagated outside the with statement.
- If the with block doesn’t raise an exception, the exit method is still called, but its type, value and traceback arguments are all passed in as None.
Let’s look at a quick demo of the protocol in action. The following, file withas.py, defines a context manager object that traces the entry and exit of the with block in any with statement it is used for:
class TraceBlock:
def message(self, arg):
print('running ' + arg)
def __enter__(self):
print('starting with block')
return self
def __exit__(self, exc_type, exc_value, exc_tb):
if exc_type is None:
print('exited normally\n')
else:
print('raise an exception! ' + str(exc_type))
return False # Propagate
if __name__ == '__main__':
with TraceBlock() as action:
action.message('test 1')
print('reached')
with TraceBlock() as action:
action.message('test 2')
print('not reached')7-2-6-3) Multiple Context Managers in 3.1, 2.7, and Later
Python 3.1 introduced a with extension that eventually appeared in Python 2.7 as well. In these and later Pythons, the with statement may also specify multiple (sometimes referred to as “nested”) context managers with new comma syntax. In the following, for example, both files’ exit actions are automatically run when the statement block exits, regardless of exception outcomes:
with open('data') as fin, open('res', 'w') as fout:
for line in fin:
if 'some key' in line:
fout.write(line)Any number of context manager items may be listed, and multiple items work the same as nested with statements. In Pythons that support this, the following code:
with A() as a, B() as b:
...statements...is equivalent to the following, which also works in 3.0 and 2.6:
with A() as a:
with B() as b:
...statements...7-3) Exception Objects
Basing exceptions on classes and OOP offers a number of benefits. Among them, class-based exceptions:
- Can be organized into categories. Exceptions coded as classes support future changes by providing categories—adding new exceptions in the future won’t generally require changes in try statements.
- Have state information and behavior. Exception classes provide a natural place for us to store context information and tools for use in the try handler—instances have access to both attached state information and callable methods.
- Support inheritance. Class-based exceptions can participate in inheritance hierarchies to obtain and customize common behavior—inherited display methods, for example, can provide a common look and feel for error messages.
7-3-1) Exceptions: Back to the future
7-3-1-1) String Exceptions Are Right Out
Prior to Python 2.6 and 3.0, it was possible to define exceptions with both class in- stances and string objects. String-based exceptions began issuing deprecation warnings in 2.5 and were removed in 2.6 and 3.0, so today you should use class-based exceptions.
String exceptions were straightforward to use—any string would do, and they matched by object identity, not value (that is, using is, not ==):
C:\code> C:\Python25\python
>>> myexc = "My exception string"
>>> try:
... raise myexc
... except myexc:
... print('caught')
...
caught7-3-1-2) Class-Based Exceptions
Coding details aside, the chief difference between string and class exceptions has to do with the way that exceptions raised are matched against except clauses in try statements:
- String exceptions were matched by simple object identity: the raised exception was matched to except clauses by Python’s is test.
- Class exceptions are matched by superclass relationships: the raised exception matches an except clause if that except clause names the exception instance’s class or any superclass of it.
7-3-1-3) Coding Exceptions Classes
class General(Exception): pass
class Specific1(General): pass
class Specific2(General): pass
def raiser0():
X = General() # Raise superclass instance
raise X
def raiser1():
X = Specific1() # Raise subclass instance
raise X
def raiser2():
X = Specific2() # Raise different subclass instance
raise X
for func in (raiser0, raiser1, raiser2):
try:
func()
except General: # Match General or any subclass of it
import sys
print('caught: %s' % sys.exc_info()[0])
C:\code> python classexc.py
caught: <class '__main__.General'>
caught: <class '__main__.Specific1'>
caught: <class '__main__.Specific2'>7-3-2) Built-in Exception Classes
In Python 3.X, all the familiar exceptions you’ve seen (e.g., SyntaxError) are really just predefined classes, available as built-in names in the module named builtins; in Python 2.X, they instead live in builtin and are also attributes of the standard library module exceptions. In addition, Python organizes the built-in exceptions into a hierarchy, to support a variety of catching modes. For example:
BaseException: topmost root, printing and constructor defaults
The top-level root superclass of exceptions. This class is not supposed to be directly inherited by user-defined classes (use Exception instead). It provides default print- ing and state retention behavior inherited by subclasses. If the str built-in is called on an instance of this class (e.g., by print), the class returns the display strings of the constructor arguments passed when the instance was created (or an empty string if there were no arguments). In addition, unless subclasses replace this class’s constructor, all of the arguments passed to this class at instance construction time are stored in its args attribute as a tuple.Exception: root of user-defined exceptions
The top-level root superclass of application-related exceptions. This is an imme- diate subclass of BaseException and is a superclass to every other built-in exception, except the system exit event classes (SystemExit, KeyboardInterrupt, and Genera torExit). Nearly all user-defined classes should inherit from this class, not BaseEx ception. When this convention is followed, naming Exception in a try statement’s handler ensures that your program will catch everything but system exit events, which should normally be allowed to pass. In effect, Exception becomes a catchall in try statements and is more accurate than an empty except.ArithmeticError: root of numeric errors
A subclass of Exception, and the superclass of all numeric errors. Its subclasses identify specific numeric errors: OverflowError, ZeroDivisionError, and Floating PointError.LookupError: root of indexing errors
A subclass of Exception, and the superclass category for indexing errors for both sequences and mappings—IndexError and KeyError—as well as some Unicode lookup errors.
7-3-3) Custom Data and Behavior
7-3-3-1) Providing Exception Details
class FormatError(Exception):
def __init__(self, line, file):
self.line = line
self.file = file
def parser():
raise FormatError(42, file='spam.txt') # When error found
try:
parser()
except FormatError as X:
print('Error at: %s %s ' % (X.file, X.line))
Error at: spam.txt 427-3-3-2) Providing Exception Methods
from __future__ import print_function
class FormatError(Exception):
logfile = 'formaterror.txt'
def __init__(self, line, file):
self.line = line
self.file = file
def logerror(self):
log = open(self.logfile, 'a')
print('Error at:', self.file, self.line, file=log)
def parser():
raise FormatError(40, 'spam.txt')
if __name__ == '__main__':
try:
parser()
except FormatError as exc:
exc.logerror()7-4) Designing with Exceptions
7-4-1) Exception idioms
7-4-1-1) Breaking Out of Multiple Nested Loops
class Exitloop(Exception): pass
try:
while True:
while True:
for i in range(10):
if i > 3: raise Exitloop # break exits just one level
print('loop3: %s' % i) print('loop2')
print('loop1')
except Exitloop:
print('continuing') # Or just pass, to move on
...
loop3: 0
loop3: 1
loop3: 2
loop3: 3
continuing
>>> i
47-4-1-2) Exceptions Aren’t Always Errors
In Python, all errors are exceptions, but not all exceptions are errors.
while True:
try:
line = input() # Read line from stdin (raw_input in 2.X)
except EOFError:
break # Exit loop at end-of-file
else:
...process next line here...7-4-1-3) Functions Can Signal Conditions with raise
User-defined exceptions can also signal nonerror conditions. For instance, a search routine can be coded to raise an exception when a match is found instead of returning a status flag for the caller to interpret. In the following, the try/except/else exception handler does the work of an if/else return-value tester:
class Found(Exception): pass
def searcher():
if ...success...:
raise Found() # Raise exceptions instead of returning flags
else:
return
try:
searcher()
except Found: # Exception if item was found
...success...
else: # else returned: not found
...failure...7-4-1-4) Closing Files and Server Connections
myfile = open(r'C:\code\textdata', 'w')
try:
...process myfile...
finally:
myfile.close()7-4-1-5) Debugging with Outer try Statements
try:
...run program...
except: # All uncaught exceptions come here
import sys
print('uncaught!', sys.exc_info()[0], sys.exc_info()[1])7-4-1-6) Running In-Process Tests
import sys
log = open('testlog', 'a')
from testapi import moreTests, runNextTest, testName
def testdriver():
while moreTests():
try:
runNextTest()
except:
print('FAILED', testName(), sys.exc_info()[:2], file=log)
else:
print('PASSED', testName(), file=log) testdriver()7-4-1-7) More on sys.exc_info
The sys.exc_info result used in the last two sections allows an exception handler to gain access to the most recently raised exception generically. This is especially useful when using the empty except clause to catch everything blindly, to determine what was raised:
try:
...
except:
# sys.exc_info()[0:2] are the exception class and instanceIf no exception is being handled, this call returns a tuple containing three None values. Otherwise, the values returned are (type, value, traceback), where:
- type is the exception class of the exception being handled.
- value is the exception class instance that was raised.
- traceback is a traceback object that represents the call stack at the point where the exception originally occurred, and used by the traceback module to generate error messages.
7-4-1-8) Displaying Errors and Tracebacks
Finally, the exception traceback object available in the prior section’s sys.exc_info result is also used by the standard library’s traceback module to generate the standard error message and stack display manually. This file has a handful of interfaces that support wide customization, which we don’t have space to cover usefully here, but the basics are simple. Consider the following aptly named file, badly.py:
import traceback
def inverse(x):
return 1 / x
try:
inverse(0)
except Exception:
traceback.print_exc(file=open('badly.exc', 'w'))
print('Bye')
c:\code> python badly.py
Bye
c:\code> type badly.exc
Traceback (most recent call last):
File "badly.py", line 7, in
inverse(0)
File "badly.py", line 4, in inverse
return 1 / x
ZeroDivisionError: division by zero 8) Advanced Topics
8-1) Unicode and Byte Strings
Specifically, we’ll explore the basics of Python’s support for Unicode text—rich char- acter strings used in internationalized applications—as well as binary data—strings that represent absolute byte values. As we’ll see, the advanced string representation story has diverged in recent versions of Python:
- Python 3.X provides an alternative string type for binary data, and supports Uni- code text (including ASCII) in its normal string type.
- Python 2.X provides an alternative string type for non-ASCII Unicode text, and supports both simple text and binary data in its normal string type.
8-1-1) String Basics
8-1-1-1) Character Encoding Schemes
Character sets are standards that assign integer codes to individual characters so they can be represented in computer memory. The ASCII standard, for example, was created in the U.S., and it defines many U.S. programmers’ notion of text strings. ASCII defines character codes from 0 through 127 and allows each character to be stored in one 8- bit byte, only 7 bits of which are actually used.
For example, the ASCII standard maps the character ‘a’ to the integer value 97 (0x61 in hex), which can be stored in a single byte in memory and files. If you wish to see how this works, Python’s ord built-in function gives the binary identifying value for a character, and chr returns the character for a given integer code value:
>>> ord('a') # 'a' is a byte with binary value 97 in ASCII (and others)
97
>>> hex(97)
'0x61'
>>> chr(97) # Binary value 97 stands for character 'a'
'a'Sometimes one byte per character isn’t enough, though. Various symbols and accented characters, for instance, do not fit into the range of possible characters defined by ASCII. To accommodate special characters, some standards use all the possible values in an 8-bit byte, 0 through 255, to represent characters, and assign the values 128 through 255 (outside ASCII’s range) to special characters.
One such standard, known as the Latin-1 character set, is widely used in Western Europe. In Latin-1, character codes above 127 are assigned to accented and otherwise special characters. The character assigned to byte value 196, for example, is a specially marked non-ASCII character:
>>> 0xC4
196
>>> chr(196) # Python 3.X result form shown
'Ä'This standard allows for a wide array of extra special characters, but still supports ASCII as a 7-bit subset of its 8-bit representation.
Still, some alphabets define so many characters that it is impossible to represent each of them as one byte. Unicode allows more flexibility. Unicode text is sometimes referred to as “wide-character” strings, because characters may be represented with multiple bytes if needed. Unicode is typically used in internationalized programs, to represent European, Asian, and other non-English character sets that have more characters than 8-bit bytes can represent.
To store such rich text in computer memory, we say that characters are translated to and from raw bytes using an encoding—the rules for translating a string of Unicode characters to a sequence of bytes, and extracting a string from a sequence of bytes. More procedurally, this translation back and forth between bytes and strings is defined by two terms:
- Encoding is the process of translating a string of characters into its raw bytes form, according to a desired encoding name.
- Decoding is the process of translating a raw string of bytes into its character string form, according to its encoding name.
8-2) Managed Attributes
This chapter expands on the attribute interception techniques introduced earlier, introduces another, and employs them in a handful of larger examples.
8-2-1) Why Manage Attributes?
Object attributes are central to most Python programs—they are where we often store information about the entities our scripts process. Normally, attributes are simply names for objects; a person’s name attribute, for example, might be a simple string, fetched and set with basic attribute syntax:
person.name # Fetch attribute value
person.name = value # Change attribute valueSometimes, though, more flexibility is required. Suppose you’ve written a program to use a name attribute directly, but then your requirements change—for example, you decide that names should be validated with logic when set or mutated in some way when fetched. It’s straightforward to code methods to manage access to the attribute’s value (valid and transform are abstract here):
class Person:
def getName(self):
if not valid():
raise TypeError('cannot fetch name')
else:
return self.name.transform()
def setName(self, value):
if not valid(value):
raise TypeError('cannot change name')
else:
self.name = transform(value)
person = Person()
person.getName()
person.setName('value')However, this also requires changing all the places where names are used in the entire program—a possibly nontrivial task. Moreover, this approach requires the program to be aware of how values are exported: as simple names or called methods. If you begin with a method-based interface to data, clients are immune to changes; if you do not, they can become problematic.
This issue can crop up more often than you might expect. The value of a cell in a spreadsheet-like program, for instance, might begin its life as a simple discrete value, but later mutate into an arbitrary calculation. Since an object’s interface should be flexible enough to support such future changes without breaking existing code, switch- ing to methods later is less than ideal.
8-2-1-1) Inserting Code to Run on Attribute Access
A better solution would allow you to run code automatically on attribute access, if needed. That’s one of the main roles of managed attributes—they provide ways to add attribute accessor logic after the fact. More generally, they support arbitrary attribute usage modes that go beyond simple data storage.
At various points in this book, we’ve met Python tools that allow our scripts to dynamically compute attribute values when fetching them and validate or change at- tribute values when storing them. In this chapter, we’re going to expand on the tools already introduced, explore other available tools, and study some larger use-case examples in this domain. Specifically, this chapter presents four accessor techniques:
- The getattr and setattr method, for routing undefined attribute fetches and all attribute assignments to generic handler methods.
- The getattribute method, for routing all attribute fetches to a generic handler method.
- The property built-in, for routing specific attribute access to get and set handler functions.
- The descriptor protocol, for routing specific attribute accesses to instance of classes with arbitrary get and set handler methods, and the basis for other tools such as properties and slots.
As we’ll see, all four techniques share goals to some degree, and it’s usually possible to code a given problem using any one of them. They do differ in some important ways, though. For example, the last two techniques listed here apply to specific attributes, whereas the first two are generic enough to be used by delegation-based proxy classes that must route arbitrary attributes to wrapped objects. As we’ll see, all four schemes also differ in both complexity and aesthetics, in ways you must see in action to judge for yourself.
8-2-2) Properties
8-2-2-1) The Basics
A property is created by assigning the result of a built-in function to a class attribute:
attribute = property(fget, fset, fdel, doc)None of this built-in’s arguments are required, and all default to None if not passed. For the first three, this None means that the corresponding operation is not supported, and attempting it will raise an AttributeError exception automatically.
When these arguments are given, we pass fget a function for intercepting attribute fetches, fset a function for assignments, and fdel a function for attribute deletions. Technically, all three of these arguments accept any callable, including a class’s method, having a first argument to receive the instance being qualified. When later invoked, the fget function returns the computed attribute value, fset and fdel return nothing (really, None), and all three may raise exceptions to reject access requests.
The doc argument receive a documentation string for the attribute, if desired; otherwise, the property copies the docstring of the fget functon, which as usual defaults to None.
This built-in property call returns a property object, which we assign to the name of the attribute to be managed in the class scope, where it will be inherited by every in- stance.
8-2-2-2) A First Example
class Person: # Add (object) in 2.X
def __init__(self, name):
self._name = name
def getName(self):
print('fetch...')
return self._name
def setName(self, value):
print('change...')
self._name = value
def delName(self):
print('remove...')
del self._name
bob = Person('Bob Smith') # bob has a managed attribute
print(bob.name) # Runs getName
bob.name = 'Robert Smith' # Runs setName
print(bob.name)
del bob.name # Runs delName
print('-'*20)
sue = Person('Sue Jones') # sue inherits property too
print(sue.name)
print(Person.name.__doc__) # Or help(Person.name)Properties are available in both 2.X and 3.X, but they require new-style object derivation in 2.X to work correctly for assignments—add object as a superclass here to run this in 2.X. You can list the superclass in 3.X too, but it’s implied and not required.
class PropSquare:
def __init__(self, start):
self.value = start
def getX(self): # On attr fetch
return self.value ** 2
def setX(self, value): # On attr assign
self.value = value
X = property(getX, setX) # No delete or docs
P= PropSquare(3) # Two instances of class with property
Q= PropSquare(32) # Each has different state information
print(P.X) # 3 ** 2
P.X = 4
print(P.X) # 4 ** 2
print(Q.X) # 32 ** 2 (1024)Notice that we’ve made two different instances—because property methods automatically receive a self argument, they have access to the state information stored in in- stances. In our case, this means the fetch computes the square of the subject instance’s own data.
8-2-2-3) Coding Properties with Decorators
As of Python 2.6 and 3.0, property objects also have getter, setter, and deleter meth- ods that assign the corresponding property accessor methods and return a copy of the property itself. We can use these to specify components of properties by decorating normal methods too, though the getter component is usually filled in automatically by the act of creating the property itself:
class Person:
def __init__(self, name):
self._name = name
@property
def name(self): # name = property(name)
"name property docs" print('fetch...')
return self._name
@name.setter # name = name.setter(name)
def name(self, value):
print('change...')
self._name = value
@name.deleter def name(self): # name = name.deleter(name)
print('remove...')
del self._name
bob = Person('Bob Smith')
print(bob.name)
bob.name = 'Robert Smith'
print(bob.name)
del bob.name
print('-'*20)
sue = Person('Sue Jones')
print(sue.name)
print(Person.name.__doc__)8-2-3) Descriptors
Descriptors provide an alternative way to intercept attribute access; they are strongly related to the properties discussed in the prior section. Really, a property is a kind of descriptor—technically speaking, the property built-in is just a simplified way to create a specific type of descriptor that runs method functions on attribute accesses. In fact, descriptors are the underlying implementation mechanism for a variety of class tools, including both properties and slots.
Functionally speaking, the descriptor protocol allows us to route a specific attribute’s get, set, and delete operations to methods of a separate class’s instance object that we provide. This allows us to insert code to be run automatically on attribute fetches and assignments, intercept attribute deletions, and provide documentation for the attributes if desired.
8-2-3-1) The Basics
As mentioned previously, descriptors are coded as separate classes and provide specially named accessor methods for the attribute access operations they wish to intercept —get, set, and deletion methods in the descriptor class are automatically run when the attribute assigned to the descriptor class instance is accessed in the corresponding way:
class Descriptor:
"docstring goes here"
def __get__(self, instance, owner): ... # Return attr value
def __set__(self, instance, value): ... # Return nothing (None)
def __delete__(self, instance): ... # Return nothing (None)Classes with any of these methods are considered descriptors, and their methods are special when one of their instances is assigned to another class’s attribute—when the attribute is accessed, they are automatically invoked. If any of these methods are absent, it generally means that the corresponding type of access is not supported. Unlike properties, however, omitting a set allows the descriptor attribute’s name to be assigned and thus redefined in an instance, thereby hiding the descriptor—to make an attribute read-only, you must define set to catch assignments and raise an exception.
8-2-3-1-1) Descriptor method arguments
Before we code anything realistic, let’s take a brief look at some fundamentals. All three descriptor methods outlined in the prior section are passed both the descriptor class instance (self), and the instance of the client class to which the descriptor instance is attached (instance).
The get access method additionally receives an owner argument, specifying the class to which the descriptor instance is attached. Its instance argument is either the instance through which the attribute was accessed (for instance.attr), or None when the attribute is accessed through the owner class directly (for class.attr). The former of these generally computes a value for instance access, and the latter usually returns self if descriptor object access is supported.
For example, in the following 3.X session, when X.attr is fetched, Python automatically runs the get method of the Descriptor class instance to which the Subject.attr class attribute is assigned. In 2.X, use the print statement equivalent, and derive both classes here from object, as descriptors are a new-style class tool; in 3.X this derivation is implied and can be omitted, but doesn’t hurt:
>>> class Descriptor: # Add "(object)" in 2.X
def __get__(self, instance, owner):
print(self, instance, owner, sep='\n')
>>> class Subject: # Add "(object)" in 2.X
attr = Descriptor() # Descriptor instance is class attr
>>> X = Subject()
>>> X.attr
<__main__.Descriptor object at 0x0281E690>
<__main__.Subject object at 0x028289B0>
<class '__main__.Subject'>
>>> Subject.attr
<__main__.Descriptor object at 0x0281E690>
None
<class '__main__.Subject'>Notice the arguments automatically passed in to the get method in the first at- tribute fetch—when X.attr is fetched, it’s as though the following translation occurs (though the Subject.attr here doesn’t invoke get again):
X.attr -> Descriptor.__get__(Subject.attr, X, Subject8-2-3-1-2) Read-only descriptors
This is the way all instance attribute assignments work in Python, and it allows classes to selectively override class-level defaults in their instances. To make a descriptor-based attribute read-only, catch the assignment in the descriptor class and raise an exception to prevent attribute assignment—when assigning an attribute that is a descriptor, Python effectively bypasses the normal instance-level assignment behavior and routes the operation to the descriptor object:
>>> class D:
def __get__(*args): print('get')
def __set__(*args): raise AttributeError('cannot set')
>>> class C:
a = D()
>>> X = C()
>>> X.a
get
>>> X.a = 99
AttributeError: cannot set8-2-3-2) A First Example
class Name: # Use (object) in 2.X
"name descriptor docs"
def __get__(self, instance, owner):
print('fetch...')
return instance._name
def __set__(self, instance, value):
print('change...')
instance._name = value
def __delete__(self, instance):
print('remove...')
del instance._name
class Person: # Use (object) in 2.X
def __init__(self, name):
self._name = name
name = Name() # Assign descriptor to attr
bob = Person('Bob Smith') # bob has a managed attribute
print(bob.name) # Runs Name.__get__
bob.name = 'Robert Smith' # Runs Name.__set__
print(bob.name)
del bob.name # Runs Name.__delete__
print('-'*20)
sue = Person('Sue Jones') # sue inherits descriptor too
print(sue.name)
print(Name.__doc__) # Or help(Name)Also note that when a descriptor class is not useful outside the client class, it’s perfectly reasonable to embed the descriptor’s definition inside its client syntactically. Here’s what our example looks like if we use a nested class:
class Person:
def __init__(self, name):
self._name = name
class Name: # Using a nested class
"name descriptor docs"
def __get__(self, instance, owner):
print('fetch...')
return instance._name
def __set__(self, instance, value):
print('change...')
instance._name = value
def __delete__(self, instance):
print('remove...')
del instance._name
name = Name()8-2-3-3) Using State Information in Descriptors
In fact, descriptors can use both instance state and descriptor state, or any combination thereof:
Descriptor state isused to manage either data internal to the workings of the descriptor, or data that spans all instances. It can vary per attribute appearance (often, per client class).
Instance state records information related to and possibly created by the client class. It can vary per client class instance (that is, per application object).
class DescState:
def __init__(self, value):
self.value = value
def __get__(self, instance, owner):
print('DescState get')
return self.value * 10
def __set__(self, instance, value):
print('DescState set')
self.value = value
# Client class
class CalcAttrs:
X= DescState(2) # Descriptor class attr
Y= 3 # Class attr
def __init__(self):
self.Z = 4 # Instance attr
obj = CalcAttrs()
print(obj.X, obj.Y, obj.Z) # X is computed, others are not
obj.X = 5 # X assignment is intercepted
CalcAttrs.Y = 6 # Y reassigned in class
obj.Z = 7 # Z assigned in instance
print(obj.X, obj.Y, obj.Z)
obj2 = CalcAttrs() # But X uses shared data, like Y!
print(obj2.X, obj2.Y, obj2.Z)It’s also feasible for a descriptor to store or use an attribute attached to the client class’s instance, instead of itself. Crucially, unlike data stored in the descriptor itself, this allows for data that can vary per client class instance. The descriptor in the following example assumes the instance has an attribute _X attached by the client class, and uses it to compute the value of the attribute it represents:
class InstState:
def __get__(self, instance, owner):
print('InstState get')
return instance._X * 10
def __set__(self, instance, value):
print('InstState set')
instance._X = value
# Client class
class CalcAttrs:
X= InstState()
Y= 3
def __init__(self):
self._X = 2
self.Z = 4
obj = CalcAttrs()
print(obj.X, obj.Y, obj.Z)
obj.X = 5
CalcAttrs.Y = 6
obj.Z = 7
print(obj.X, obj.Y, obj.Z)
obj2 = CalcAttrs()
print(obj2.X, obj2.Y, obj2.Z)8-2-3-4) How Properties and Descriptors Relate
As mentioned earlier, properties and descriptors are strongly related—the property built-in is just a convenient way to create a descriptor. Now that you know how both work, you should also be able to see that it’s possible to simulate the property built-in with a descriptor class like the following:
class Property:
def __init__(self, fget=None, fset=None, fdel=None, doc=None):
self.fget = fget
self.fset = fset
self.fdel = fdel # Save unbound methods
self.__doc__ = doc # or other callables
def __get__(self, instance, instancetype=None):
if instance is None:
return self
if self.fget is None:
raise AttributeError("can't get attribute")
return self.fget(instance)
def __set__(self, instance, value):
if self.fset is None:
raise AttributeError("can't set attribute")
self.fset(instance, value)
def __delete__(self, instance):
if self.fdel is None:
raise AttributeError("can't delete attribute")
self.fdel(instance)
class Person:
def getName(self): print('getName...')
def setName(self, value): print('setName...')
name = Property(getName, setName) # Use like property()
x = Person()
x.name
x.name = 'Bob'
del x.name8-2-4) getattr and getattribute
Attribute fetch interception comes in two flavors, coded with two different methods:
- getattr is run for undefined attributes—because it is run only for attributes not stored on an instance or inherited from one of its classes, its use is straightfor- ward.
- getattribute is run for every attribute—because it is all-inclusive, you must be cautious when using this method to avoid recursive loops by passing attribute accesses to a superclass.
8-2-4-1) The Basics
- def getattr(self, name): # On undefined attribute fetch [obj.name]
- def getattribute(self, name): # On all attribute fetch [obj.name]
- def setattr(self, name, value): # On all attribute assignment [obj.name=value]
- def delattr(self, name): # On all attribute deletion [del obj.name]
Avoiding loops in attribute interception methods:
These methods are generally straightforward to use; their only substantially complex aspect is the potential for looping (a.k.a. recursing). Because getattr is called for undefined attributes only, it can freely fetch other attributes within its own code. How- ever, because getattribute and setattr are run for all attributes, their code needs to be careful when accessing other attributes to avoid calling themselves again and triggering a recursive loop.
For example, another attribute fetch run inside a getattribute method’s code will trigger getattribute again, and the code will usually loop until memory is exhaus- ted:
def __getattribute__(self, name):
x = self.other # LOOPS!8-3) Decorators
8-3-1) What’s a Decorator?
Decoration is a way to specify management or augmentation code for functions and classes. Decorators themselves take the form of callable objects (e.g., functions) that process other callable objects. Python decorators come in two related flavors, neither of which requires 3.X or new-style classes:
Function decorators, added in Python 2.4, do name rebinding at function definition time, providing a layer of logic that can manage functions and methods, or later calls to them.
Class decorators, added in Python 2.6 and 3.0, do name rebinding at class definition time, providing a layer of logic that can manage class, or the instance created by layer calls to them.
In short, decorators provide a way to insert automatically run code at the end of function and class definition statements - at the end of a def for function decorators, and at the end of class for class decorators. Such code can play a variety of roles, as described in the following sections.
8-3-1-1) Managing Calls and Instances
In typical use, this automatically run code may be used to augment calls to functions and classes. It arranges this by installing wrapper (a.k.a. proxy) objects to be invoked later:
Call proxies
Function decorators install wrapper objects to intercept later function calls and process them as needed, usually passing the call on to the original function to run the managed action.Interface proxies
Class decorators install wrapper objects to intercept later instance creation calls and process them as required, usually passing the call on to the original class to create a managed instance.
Decorators achieve these effects by automatically rebinding function and class names to other callables, at the end of def and class statements. When later invoked, these callables can perform tasks such as tracing and timing function calls, managing access to class instance attributes, and so on.
8-3-1-2) Managing Functions and Classes
Although most examples in this chapter deal with using wrappers to intercept later calls to functions and classes, this is not the only way decorators can be used:
Function managers
Function decorators can also be used to manage function objects, instead of or in addition to later calls to them—to register a function to an API, for instance. Our primary focus here, though, will be on their more commonly used call wrapper application.Class managers
Class decorators can also be used to manage class objects directly, instead of or in addition to instance creation calls—to augment a class with new methods, for example. Because this role intersects strongly with that of metaclasses, we’ll see additional use cases in the next chapter. As we’ll find, both tools run at the end of the class creation process, but class decorators often offer a lighter-weight solution.
8-3-2) Function Decorators
8-3-2-1) Usage
A function decorator is a kind of runtime declaration about the function whose defini- tion follows. The decorator is coded on a line just before the def statement that defines a function or method, and it consists of the @ symbol followed by a reference to a metafunction—a function (or other callable object) that manages another function.
In terms of code, function decorators automatically map the following syntax:
@decorator # Decorate function
def F(arg):
...
F(99) # Call functioninto this equivalent form, where decorator is a one-argument callable object that re- turns a callable object with the same number of arguments as F (in not F itself):
def F(arg):
...
F = decorator(F) # Rebind function name to decorator result
F(99) # Essentially calls decorator(F)(99)8-3-2-2) Implementation
A decorator itself is a callable that returns a callable. That is, it returns the object to be called later when the decorated function is invoked through its original name—either a wrapper object to intercept later calls, or the original function augmented in some way. In fact, decorators can be any type of callable and return any type of callable: any combination of functions and classes may be used, though some are better suited to certain contexts.
For example, to tap into the decoration protocol in order to manage a function just after it is created, we might code a decorator of this form:
def decorator(F):
# Process function F
return F
@decorator
def func(): ... # func = decorator(func)In skeleton terms, here’s one common coding pattern that captures this idea—the dec- orator returns a wrapper that retains the original function in an enclosing scope:
def decorator(F): # On @ decoration
def wrapper(*args): # On wrapped function call
# Use F and args
# F(*args) calls original function
return wrapper
@decorator # func = decorator(func)
def func(x, y): # func is passed to decorator's F
...
func(6, 7) # 6, 7 are passed to wrapper's *argsWhen the name func is later called, it really invokes the wrapper function returned by decorator; the wrapper function can then run the original func because it is still available in an enclosing scope. When coded this way, each decorated function produces a new scope to retain state.
To do the same with classes, we can overload the call operation and use instance at- tributes instead of enclosing scopes:
class decorator:
def __init__(self, func): # On @ decoration
self.func = func
def __call__(self, *args): # On wrapped function call
# USE self.func and args
# self.func(*args) calls original function
@decorator
def func(x, y): # func is passed to __init__
...
func(6, 7) # 6, 7 are passed to __call__'s *args8-3-2-3) Supporting method decoration
One subtle point about the prior class-based coding is that while it works to intercept simple function calls, it does not quite work when applied to class-level method functions:
class decorator:
def __init__(self, func): # func is method without instance
self.func = func
def __call__(self, *args): # self is decorator instance
# self.func(*args) fails! # C instance not in args!
class C:
@decorator
def method(self, x, y): # method = decorator(method)
... # Rebound to decorator instance8-3-3) Class Decorators
8-3-3-1) Usage
Syntactically, class decorators appear just before class statements, in the same way that function decorators appear just before def statements. In symbolic terms, for a decora tor that must be a one-argument callable that returns a callable, the class decorator syntax:
@decorator # Decorate class
class C:
...
x = C(99) # Make an instanceis equivalent to the following—the class is automatically passed to the decorator func- tion, and the decorator’s result is assigned back to the class name:
class C:
...
C = decorator(C) # Rebind class name to decorator result
x = C(99) # Essentially calls decorator(C)(99)The net effect is that calling the class name later to create an instance winds up triggering
the callable returned by the decorator, which may or may not call the original class itself.
8-3-3-2) Implementation
New class decorators are coded with many of the same techniques used for function decorators, though some may involve two levels of augmentation—to manage both instance construction calls, as well as instance interface access. Because a class deco- rator is also a callable that returns a callable, most combinations of functions and classes suffice.
However it’s coded, the decorator’s result is what runs when an instance is later created. For example, to simply manage a class just after it is created, return the original class itself:
def decorator(C):
# Process class C
return C
@decorator
class C: ... # C = decorator(C)To instead insert a wrapper layer that intercepts later instance creation calls, return a
different callable object:
def decorator(C):
# Save or use class C
# Return a different callable: nested def, class with __call__, etc.
@decorator
class C: ... # C = decorator(C)The callable returned by such a class decorator typically creates and returns a new instance of the original class, augmented in some way to manage its interface. For example, the following inserts an object that intercepts undefined attributes of a class instance:
def decorator(cls): # On @ decoration
class Wrapper:
def __init__(self, *args): # On instance creation
self.wrapped = cls(*args)
def __getattr__(self, name): # On attribute fetch
return getattr(self.wrapped, name)
return Wrapper
@decorator
class C: # C = decorator(C)
def __init__(self, x, y): # Run by Wrapper.__init__
self.attr = 'spam'
x = C(6, 7) # Really calls Wrapper(6, 7)
print(x.attr) # Runs Wrapper.__getattr__, prints "spam"8-3-3-3) Supporting multiple instances
As for function decorators, some callable type combinations work better for class dec- orators than others. Consider the following invalid alternative to the class decorator of the prior example:
class Decorator:
def __init__(self, C): # On @ decoration
self.C = C
def __call__(self, *args): # On instance creation
self.wrapped = self.C(*args)
return self
def __getattr__(self, attrname): # On atrribute fetch
return getattr(self.wrapped, attrname)
@Decorator
class C:
... # C = Decorator(C)
x = C()
y = C() # Overwrites x!8-3-4) Decorator Nesting
To support multiple nested steps of augmentation this way, decorator syntax allows you to add multiple layers of wrapper logic to a decorated function or method. When this feature is used, each decorator must appear on a line of its own. Decorator syntax of this form:
@A
@B
@C
def f(...):
...runs the same as the following:
def f(...):
...
f = A(B(C(f)))8-3-5) Decorator Arguments
Both function and class decorators can also seem to take arguments, although really these arguments are passed to a callable that in effect returns the decorator, which in turn returns a callable. By nature, this usually sets up multiple levels of state retention. The following, for instance:
@decorator(A, B)
def F(arg):
...
F(99)is automatically mapped into this equivalent form, where decorator is a callable that returns the actual decorator. The returned decorator in turn returns the callable run later for calls to the original function name:
def F(arg):
...
F = decorator(A, B)(F) # Rebind F to result of decorator's return value
F(99) # Essentially calls decorator(A, B)(F)(99)Decorator arguments are resolved before decoration ever occurs, and they are usually used to retain state information for use in later calls. The decorator function in this example, for instance, might take a form like the following:
def decorator(A, B):
# Save or use A, B
def actualDecorator(F):
# Save or use function F
# Return a callable: nested def, class with __call__, etc.
return callable
return actualDecorator8-4) Metaclasses
metaclasses allow us to intercept and augment class creation—they provide an API for inserting extra logic to be run at the conclusion of a class statement, albeit in different ways than decorators. Accordingly, they provide a general protocol for managing class objects in a program.