【转载】postgresql存储过程中返回类型
前言
假如需要在pg上面写存储过程,那么返回类型必定是一个疑问点。
一般而言,对于一个查询语句,为了可以统一动态返回各种数据,我们是不会蠢到每一个存储过程都额外编写一个返回类型 譬如:
(id,name,password)
之类的,所以在写的时候肯定会考虑 setof record这个动态返回结果集,可惜,这是pg的一个坑,具体请看:
存储过程的结果集返回大概类型
参考如下:
postgresql 函数返回结果集
postgresql 函数返回结果集
2011年11月26日 22:56:07 oemoon 阅读数:12269 标签: postgresql function jdbc security table 语言 更多
个人分类: 数据库
pgsql function 系列之一:返回结果集
--------------------------------------------------------------------------------
我们在编写postgresql数据库的函数(或称为存储过程)时,时常会遇到需要返回一个结果集的情况,如何返回一个结果集,返回一个结果集有多少种方式,以及如何选择一个合适的方式返回结果集,这是一个需要仔细考虑的问题。本文仅简单的罗列出各种返回结果集的方式并试图分析他们的特点,而采用何种方式则留给大家自己去判断。
阅读本文需要一定的postgresql数据库端编程知识,如果你缺乏这方面的知识,请先翻阅postgresql文档。
----------------------------------------------------分割线-------------------------------------------------------
第一种选择:声明setof 某表/某视图 返回类型
这是postgresql官方推荐的返回结果集的形式,当你查阅postgresql官方文档的时候,你会看到的就是这种形式。如果采用这种形式,你的function代码看起来会像这样:CREATE OR REPLACE FUNCTION function1 () RETURNS setof table1 AS
$body$
DECLARE
result record;
BEGIN
for result in select * from table1 loop
return next result;
end loop;
return;
END;
$body$
LANGUAGE 'plpgsql' VOLATILE CALLED ON NULL INPUT SECURITY INVOKER;
这是使用pl/pgsql语言的风格,你甚至可以使用sql语言让代码看起来更简单:
CREATE OR REPLACE FUNCTION function1 () RETURNS SETOF table1 AS
$body$
SELECT * from table1;
$body$
LANGUAGE 'sql' VOLATILE CALLED ON NULL INPUT SECURITY INVOKER;
以下是分析:
首先我们说优点,第一、这是官方推荐的;第二、当使用pl/pgsql语言的时候,我们可以在循环中加上判断语句,仅返回我们需要的行;第三、在jdbc调用中,我们可以像查询普通的表一样使用这个function,例如:"select * from function1()"。
其次我们说缺点,第一、当使用pl/pgsql语言的时候,即使我们需要返回所有行,仍然要进行循环导致不必要的开销。当然你可以使用sql语言避免这个问题,但显然sql语言的控制能力太弱以至于我们无法使用它实现哪怕稍微复杂一点的逻辑。第二、返回的字段必须是在function定义时就确定了的,这意味着我们无法动态的返回我们想要返回的字段。
------------------------------------------------继续分割线-------------------------------------------------
第二种选择:声明setof record返回类型
总的说起来这种方式和上一种没什么不同,它唯一的用处在于“一定程度上”解决了动态返回结果集字段的问题。之所以说“一定程度”是因为使用setof record返回类型将会导致极度恶心的jdbc端编码——你不得不在sql语句后面显式的说明所选字段的名称和类型,并且你会发现你无法使用jdbc call的方式调用function(关于jdbc call的部分在另外的篇幅描述)。具体的来说,如果你返回一个结果集字段按照:a bigint,b varchar,c timestamp排列,则你的jdbc端编码看起来会像这样:
select * from function1() as (a bigint,b varchar,c timestamp);
问题在于,如果你不知道function将要返回的字段类型是什么,则你根本无法在jdbc端调用该function!!!
----------------------------------------------还是分割线-------------------------------------------------
第三种选择:声明refcursor返回类型
事情到这里将揭过新的一页,这里我们放弃使用setof ××× ,而使用一个全新的返回类型——refcursor(游标)。关于什么是游标本文不再累述,请自己翻阅相关文档,这里仅描述如何使用。
首先,要使用游标,你的function编码看起来会像这样:
CREATE OR REPLACE FUNCTION function1 () RETURNS refcursor AS
$body$
DECLARE
result refcursor;
BEGIN
open result for select * from table1,table2; --你可以任意选择你想要返回的表和字段
return result;
END;
$body$
LANGUAGE 'plpgsql' VOLATILE CALLED ON NULL INPUT SECURITY INVOKER;
你的jdbc端编码推荐使用call方式,看起来会像这样:
Connection conn = ConnectionPool.getConn();
CallableStatement proc = conn.prepareCall("{ ? = call function1() }");
proc.execute();
ResultSet rs = (ResultSet) proc.getObject(1);
如此我们就获得了一个结果集,并且该结果集所包含的字段可以是任意你想要的字段,并且jdbc端编码也很简洁。
然而这种方式的缺点依然很明显:我们不能对要返回的结果集做进一步的筛选(参考第一种选择的优点二)。
----------------------------------------------最后分割线------------------------------------------------
总的来说,上述三种方法各有特点,我们在实际应用中应该秉着“合适的就是最好的”的原则来看待问题。
存储过程返回游标时候的demo例子
postgreSQL中function返回结果集
postgresql对于各种游标的使用示例
CREATE OR REPLACE FUNCTION cursor_demo()
RETURNS refcursor AS
$BODY$
declare
unbound_refcursor refcursor;
v_id int;
v_step_desc varchar(1000);
begin
open unbound_refcursor for execute 'select id,step_desc from t_runtime_step_log';
loop
fetch unbound_refcursor into v_id,v_step_desc;
if found then
raise notice '%-%',v_id,v_step_desc;
else
exit;
end if;
end loop;
close unbound_refcursor;
raise notice 'the end of msg...';
return unbound_refcursor;
exception when others then
raise exception 'error--(%)',sqlerrm;
end;
$BODY$
LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION cursor_demo1(refcursor)
RETURNS refcursor AS
$$
begin
open $1 for select * from t_runtime_step_log;
return $1;
exception when others then
raise exception 'sql exception--%',sqlerrm;
end;
$$
LANGUAGE plpgsql;
begin;
select cursor_demo1('a');
fetch all in a;
--commit;
CREATE OR REPLACE FUNCTION cursor_demo2()
RETURNS refcursor AS
$$
declare
bound_cursor cursor for select * from t_runtime_step_log;
begin
open bound_cursor;
return bound_cursor;
end;
$$
LANGUAGE plpgsql;
begin;
select cursor_demo2();
fetch all in bound_cursor;
--commit;
CREATE OR REPLACE FUNCTION cursor_demo3(p_condition integer)
RETURNS refcursor AS
$BODY$
declare
bound_param_cursor cursor(id_condition integer) for select * from t_runtime_step_log where id > id_condition;
begin
open bound_param_cursor(p_condition);
return bound_param_cursor;
end;
$BODY$
LANGUAGE plpgsql;
begin;
select cursor_demo3(5);
fetch all in bound_param_cursor;
--commit;
CREATE OR REPLACE FUNCTION cursor_demo4(p_condition integer)
RETURNS refcursor AS
$$
declare
bound_param_cursor cursor for select * from t_runtime_step_log where id > p_condition;
begin
open bound_param_cursor;
return bound_param_cursor;
end;
$$
LANGUAGE plpgsql;
begin;
select cursor_demo4(5);
fetch all in bound_param_cursor;
--commit;
---------------------
作者:jsjw18
来源:CSDN
原文:https://blog.csdn.net/victor_ww/article/details/44240063
版权声明:本文为博主原创文章,转载请附上博文链接!
postgresql数据库的游标使用例子说明
部分内容参考了http://blog.csdn.net/victor_ww/article/details/44240063
但是由于上面的文章,在我那里不能完全执行,所以我这边整理了一份可以运行成功的例子。
有的时候,我们会使用到函数,并且想使用函数中查询一些数据,并且当是多条结果集的时候,就需要使用游标了。
使用游标分为两种方式,这个也是自己参考上面的文章,然后自己瞎摸索出来的,多试几次。
1、没有where 条件的
CREATE OR REPLACE FUNCTION cursor_demo()
RETURNS refcursor AS
$BODY$
declare
unbound_refcursor refcursor;
v_id int;
v_step_desc varchar(1000);
begin
open unbound_refcursor for execute 'select id,step_desc from t_runtime_step_log';
loop
fetch unbound_refcursor into v_id,v_step_desc;
if found then
raise notice '%-%',v_id,v_step_desc;
else
exit;
end if;
end loop;
close unbound_refcursor;
raise notice 'the end of msg...';
return unbound_refcursor;
exception when others then
raise exception 'error--(%)',sqlerrm;
end;
$BODY$
LANGUAGE plpgsql;
上面只是声明了一个函数,外部调用需要采用下面的方式。
begin;
select cursor_demo();
commit;
调用时,如果不使用begin和commit的话,会提示错误。
当然也可以再封装一个函数, 该函数中写上上面的代码。
unnamed portal
2、附带where条件的
CREATE OR REPLACE FUNCTION cursor_demo3(p_condition integer)
RETURNS refcursor AS
$BODY$
declare
bound_param_cursor cursor(id_condition integer) for select * from t_runtime_step_log where id > id_condition;
begin
open bound_param_cursor(p_condition);
return bound_param_cursor;
end;
$BODY$
LANGUAGE plpgsql;
上面只是声明了一个函数,外部调用需要采用下面的方式。
begin;
select cursor_demo();
commit;
调用时,如果不使用begin和commit的话,会提示错误。
当然也可以再封装一个函数, 该函数中写上上面的代码。
unnamed portal
---------------------
作者:跨时代135
来源:CSDN
原文:https://blog.csdn.net/baidu_18607183/article/details/56012327
版权声明:本文为博主原创文章,转载请附上博文链接!
如何直接在在sql语句中调用游标并且得到结果集
好了,你会发现根据上面写的返回的结果是:
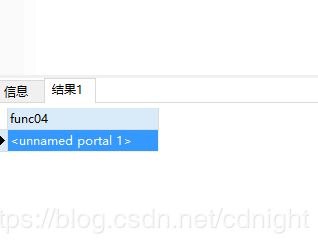
所以,还差一步:
postgres直接查看function返回的游标数据
在一些复杂的返回cursor的function中,经常需要查看返回的cursor的具体数据,已验证自己是否读懂了原先的sql,或者验证自己书写的是否正确,如果启动一个调用程序就比较麻烦了,pgAdmin可以是直接查看。
pgAdmin支持在sql窗口直接解析游标数据,就是直接查看游标的具体数据,不过需要特殊的查询sql,具体如下:
1、首先需要开启事务:执行begin;语句。
2、执行select function_name();语句。此语句会返回一个类似于的东西。
3、查看游标代表的具体数据:执行语句:fetch all from "";(双引号不能少)
此语句中双引号的里面是第二步返回的数据,返回值就是此游标代表的数据。
4、最后记得把此事务commit或者rollback了。
---------------------
作者:suiyue_cxg
来源:CSDN
原文:https://blog.csdn.net/suiyue_cxg/article/details/54429392
版权声明:本文为博主原创文章,转载请附上博文链接!
于是就有了:
begin;
select func04();
fetch all from "";
commit;
好,试试结果:
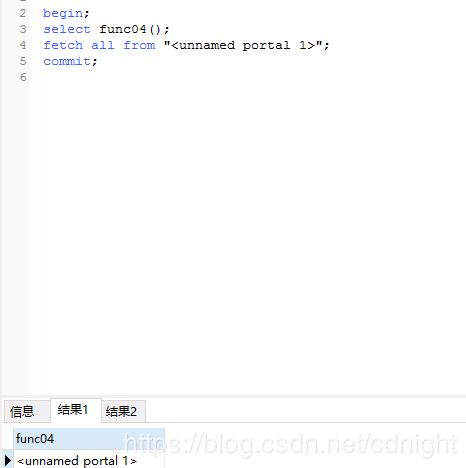
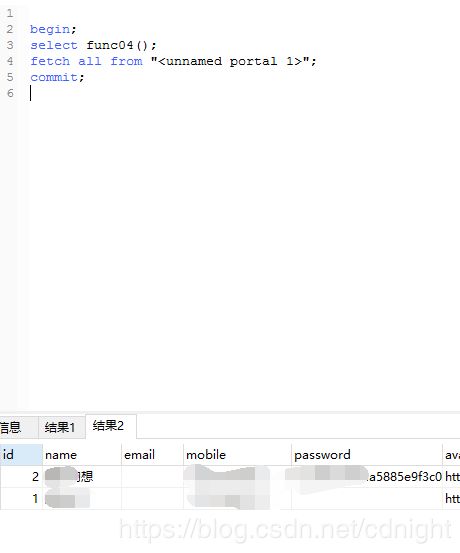
好了,游标的用法以及大体调用方式已经整理得差不多了。
如何在存储过程中调用其他存储过程返回的游标且得到结果
我们先来看看旧版本的做法:
postgresql 8.0.0中文文档的 35.8. 游标介绍
PL/pgSQL 函数可以向调用者返回游标。 这个功能用于从函数里返回多行或多列。要想这么做的时候, 该函数打开游标并且把该游标的名字返回给调用者。 调用者然后从游标里FETCH行。 游标可以由调用者关闭,或者是在事务结束的时候自动关闭。
函数返回的游标名可以由调用者声明或者自动生成。 要声明一个信使的名字,只要再打开游标之前,给 refcursor 变量赋予一个字串就可以了。 refcursor 变量的字串值将被 OPEN 当作下层的信使的名字使用。 不过,如果 refcursor 变量是空,那么 OPEN 将自动生成一个和现有信使不冲突的名字, 然后将它赋予 refcursor 变量。
注意: 一个绑定的游标变量其名字初始化为对应的字串值,因此信使的名字和游标变量名同名, 除非程序员再打开游标之前通过赋值覆盖了这个名字。但是一个未绑定的游标变量初始化的时候缺省是空, 因此它会收到一个自动生成的唯一的名字,除非被覆盖。
下面的例子显示了一个调用者声明游标名字的方法:
CREATE TABLE test (col text);
INSERT INTO test VALUES ('123');
CREATE FUNCTION reffunc(refcursor) RETURNS refcursor AS '
BEGIN
OPEN $1 FOR SELECT col FROM test;
RETURN $1;
END;
' LANGUAGE plpgsql;
BEGIN;
SELECT reffunc('funccursor');
FETCH ALL IN funccursor;
COMMIT;
下面的例子使用了自动生成的游标名:
CREATE FUNCTION reffunc2() RETURNS refcursor AS '
DECLARE
ref refcursor;
BEGIN
OPEN ref FOR SELECT col FROM test;
RETURN ref;
END;
' LANGUAGE plpgsql;
BEGIN;
SELECT reffunc2();
reffunc2
--------------------
(1 row)
FETCH ALL IN "";
COMMIT;
下面的例子显示了从一个函数里返回多个游标的方法:
CREATE FUNCTION myfunc(refcursor, refcursor) RETURNS SETOF refcursor AS $$
BEGIN
OPEN $1 FOR SELECT * FROM table_1;
RETURN NEXT $1;
OPEN $2 FOR SELECT * FROM table_2;
RETURN NEXT $2;
RETURN;
END;
$$ LANGUAGE plpgsql;
-- 需要在事务里使用游标。
BEGIN;
SELECT * FROM myfunc('a', 'b');
FETCH ALL FROM a;
FETCH ALL FROM b;
COMMIT;
不过你会发现,新版本(我的是pg10)已经没办法这样用了,例如这个例子:
create or replace function func05(varchar(50))
returns refcursor as
$$
BEGIN
open $1 for select * from member;
return $1;
END;
$$LANGUAGE plpgsql volatile ;
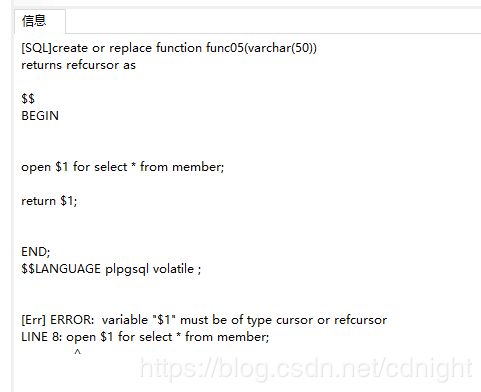
好了,直接找到文档来看看,是9.4的文档:
Cursors
40.7. Cursors
Rather than executing a whole query at once, it is possible to set up a cursor that encapsulates the query, and then read the query result a few rows at a time. One reason for doing this is to avoid memory overrun when the result contains a large number of rows. (However, PL/pgSQL users do not normally need to worry about that, since FOR loops automatically use a cursor internally to avoid memory problems.) A more interesting usage is to return a reference to a cursor that a function has created, allowing the caller to read the rows. This provides an efficient way to return large row sets from functions.
40.7.1. Declaring Cursor Variables
All access to cursors in PL/pgSQL goes through cursor variables, which are always of the special data type refcursor. One way to create a cursor variable is just to declare it as a variable of type refcursor. Another way is to use the cursor declaration syntax, which in general is:
name [ [ NO ] SCROLL ] CURSOR [ ( arguments ) ] FOR query;
(FOR can be replaced by IS for Oracle compatibility.) If SCROLL is specified, the cursor will be capable of scrolling backward; if NO SCROLL is specified, backward fetches will be rejected; if neither specification appears, it is query-dependent whether backward fetches will be allowed. arguments, if specified, is a comma-separated list of pairs name datatype that define names to be replaced by parameter values in the given query. The actual values to substitute for these names will be specified later, when the cursor is opened.
Some examples:
DECLARE
curs1 refcursor;
curs2 CURSOR FOR SELECT * FROM tenk1;
curs3 CURSOR (key integer) FOR SELECT * FROM tenk1 WHERE unique1 = key;
All three of these variables have the data type refcursor, but the first can be used with any query, while the second has a fully specified query already bound to it, and the last has a parameterized query bound to it. (key will be replaced by an integer parameter value when the cursor is opened.) The variable curs1 is said to be unbound since it is not bound to any particular query.
40.7.2. Opening Cursors
Before a cursor can be used to retrieve rows, it must be opened. (This is the equivalent action to the SQL command DECLARE CURSOR.) PL/pgSQL has three forms of the OPEN statement, two of which use unbound cursor variables while the third uses a bound cursor variable.
Note: Bound cursor variables can also be used without explicitly opening the cursor, via the FOR statement described in Section 40.7.4.
40.7.2.1. OPEN FOR query
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR query;
The cursor variable is opened and given the specified query to execute. The cursor cannot be open already, and it must have been declared as an unbound cursor variable (that is, as a simple refcursor variable). The query must be a SELECT, or something else that returns rows (such as EXPLAIN). The query is treated in the same way as other SQL commands in PL/pgSQL: PL/pgSQL variable names are substituted, and the query plan is cached for possible reuse. When a PL/pgSQL variable is substituted into the cursor query, the value that is substituted is the one it has at the time of the OPEN; subsequent changes to the variable will not affect the cursor's behavior. The SCROLL and NO SCROLL options have the same meanings as for a bound cursor.
An example:
OPEN curs1 FOR SELECT * FROM foo WHERE key = mykey;
40.7.2.2. OPEN FOR EXECUTE
OPEN unbound_cursorvar [ [ NO ] SCROLL ] FOR EXECUTE query_string
[ USING expression [, ... ] ];
The cursor variable is opened and given the specified query to execute. The cursor cannot be open already, and it must have been declared as an unbound cursor variable (that is, as a simple refcursor variable). The query is specified as a string expression, in the same way as in the EXECUTE command. As usual, this gives flexibility so the query plan can vary from one run to the next (see Section 40.10.2), and it also means that variable substitution is not done on the command string. As with EXECUTE, parameter values can be inserted into the dynamic command via USING. The SCROLL and NO SCROLL options have the same meanings as for a bound cursor.
An example:
OPEN curs1 FOR EXECUTE 'SELECT * FROM ' || quote_ident(tabname)
|| ' WHERE col1 = $1' USING keyvalue;
In this example, the table name is inserted into the query textually, so use of quote_ident() is recommended to guard against SQL injection. The comparison value for col1 is inserted via a USING parameter, so it needs no quoting.
40.7.2.3. Opening a Bound Cursor
OPEN bound_cursorvar [ ( [ argument_name := ] argument_value [, ...] ) ];
This form of OPEN is used to open a cursor variable whose query was bound to it when it was declared. The cursor cannot be open already. A list of actual argument value expressions must appear if and only if the cursor was declared to take arguments. These values will be substituted in the query.
The query plan for a bound cursor is always considered cacheable; there is no equivalent of EXECUTE in this case. Notice that SCROLL and NO SCROLL cannot be specified in OPEN, as the cursor's scrolling behavior was already determined.
Argument values can be passed using either positional or named notation. In positional notation, all arguments are specified in order. In named notation, each argument's name is specified using := to separate it from the argument expression. Similar to calling functions, described in Section 4.3, it is also allowed to mix positional and named notation.
Examples (these use the cursor declaration examples above):
OPEN curs2;
OPEN curs3(42);
OPEN curs3(key := 42);
Because variable substitution is done on a bound cursor's query, there are really two ways to pass values into the cursor: either with an explicit argument to OPEN, or implicitly by referencing a PL/pgSQL variable in the query. However, only variables declared before the bound cursor was declared will be substituted into it. In either case the value to be passed is determined at the time of the OPEN. For example, another way to get the same effect as the curs3 example above is
DECLARE
key integer;
curs4 CURSOR FOR SELECT * FROM tenk1 WHERE unique1 = key;
BEGIN
key := 42;
OPEN curs4;
40.7.3. Using Cursors
Once a cursor has been opened, it can be manipulated with the statements described here.
These manipulations need not occur in the same function that opened the cursor to begin with. You can return a refcursor value out of a function and let the caller operate on the cursor. (Internally, a refcursor value is simply the string name of a so-called portal containing the active query for the cursor. This name can be passed around, assigned to other refcursor variables, and so on, without disturbing the portal.)
All portals are implicitly closed at transaction end. Therefore a refcursor value is usable to reference an open cursor only until the end of the transaction.
40.7.3.1. FETCH
FETCH [ direction { FROM | IN } ] cursor INTO target;
FETCH retrieves the next row from the cursor into a target, which might be a row variable, a record variable, or a comma-separated list of simple variables, just like SELECT INTO. If there is no next row, the target is set to NULL(s). As with SELECT INTO, the special variable FOUND can be checked to see whether a row was obtained or not.
The direction clause can be any of the variants allowed in the SQL FETCH command except the ones that can fetch more than one row; namely, it can be NEXT, PRIOR, FIRST, LAST, ABSOLUTE count, RELATIVE count, FORWARD, or BACKWARD. Omitting direction is the same as specifying NEXT. In the forms using a count, the count can be any integer-valued expression (unlike the SQL FETCH command, which only allows an integer constant). direction values that require moving backward are likely to fail unless the cursor was declared or opened with the SCROLL option.
cursor must be the name of a refcursor variable that references an open cursor portal.
Examples:
FETCH curs1 INTO rowvar;
FETCH curs2 INTO foo, bar, baz;
FETCH LAST FROM curs3 INTO x, y;
FETCH RELATIVE -2 FROM curs4 INTO x;
40.7.3.2. MOVE
MOVE [ direction { FROM | IN } ] cursor;
MOVE repositions a cursor without retrieving any data. MOVE works exactly like the FETCH command, except it only repositions the cursor and does not return the row moved to. As with SELECT INTO, the special variable FOUND can be checked to see whether there was a next row to move to.
Examples:
MOVE curs1;
MOVE LAST FROM curs3;
MOVE RELATIVE -2 FROM curs4;
MOVE FORWARD 2 FROM curs4;
40.7.3.3. UPDATE/DELETE WHERE CURRENT OF
UPDATE table SET ... WHERE CURRENT OF cursor;
DELETE FROM table WHERE CURRENT OF cursor;
When a cursor is positioned on a table row, that row can be updated or deleted using the cursor to identify the row. There are restrictions on what the cursor's query can be (in particular, no grouping) and it's best to use FOR UPDATE in the cursor. For more information see the DECLARE reference page.
An example:
UPDATE foo SET dataval = myval WHERE CURRENT OF curs1;
40.7.3.4. CLOSE
CLOSE cursor;
CLOSE closes the portal underlying an open cursor. This can be used to release resources earlier than end of transaction, or to free up the cursor variable to be opened again.
An example:
CLOSE curs1;
40.7.3.5. Returning Cursors
PL/pgSQL functions can return cursors to the caller. This is useful to return multiple rows or columns, especially with very large result sets. To do this, the function opens the cursor and returns the cursor name to the caller (or simply opens the cursor using a portal name specified by or otherwise known to the caller). The caller can then fetch rows from the cursor. The cursor can be closed by the caller, or it will be closed automatically when the transaction closes.
The portal name used for a cursor can be specified by the programmer or automatically generated. To specify a portal name, simply assign a string to the refcursor variable before opening it. The string value of the refcursor variable will be used by OPEN as the name of the underlying portal. However, if the refcursor variable is null, OPEN automatically generates a name that does not conflict with any existing portal, and assigns it to the refcursor variable.
Note: A bound cursor variable is initialized to the string value representing its name, so that the portal name is the same as the cursor variable name, unless the programmer overrides it by assignment before opening the cursor. But an unbound cursor variable defaults to the null value initially, so it will receive an automatically-generated unique name, unless overridden.
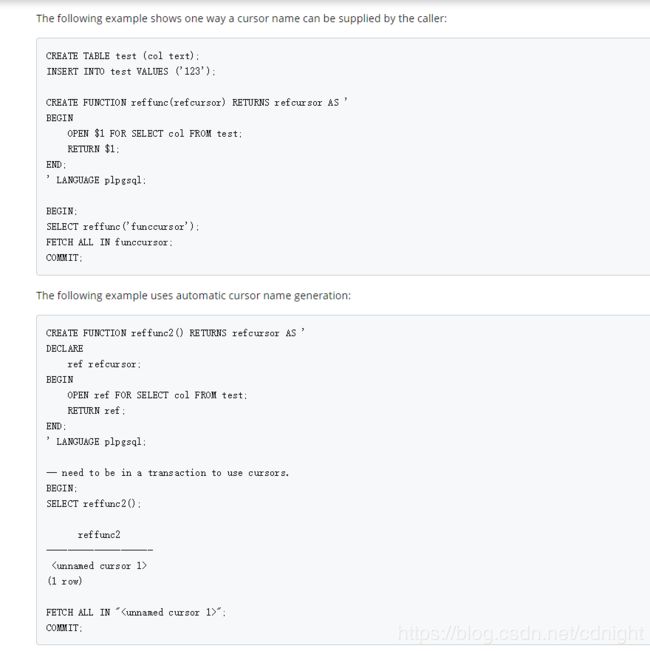
The following example shows one way a cursor name can be supplied by the caller:
CREATE TABLE test (col text);
INSERT INTO test VALUES ('123');
CREATE FUNCTION reffunc(refcursor) RETURNS refcursor AS '
BEGIN
OPEN $1 FOR SELECT col FROM test;
RETURN $1;
END;
' LANGUAGE plpgsql;
BEGIN;
SELECT reffunc('funccursor');
FETCH ALL IN funccursor;
COMMIT;
The following example uses automatic cursor name generation:
CREATE FUNCTION reffunc2() RETURNS refcursor AS '
DECLARE
ref refcursor;
BEGIN
OPEN ref FOR SELECT col FROM test;
RETURN ref;
END;
' LANGUAGE plpgsql;
-- need to be in a transaction to use cursors.
BEGIN;
SELECT reffunc2();
reffunc2
--------------------
(1 row)
FETCH ALL IN "";
COMMIT;
The following example shows one way to return multiple cursors from a single function:
CREATE FUNCTION myfunc(refcursor, refcursor) RETURNS SETOF refcursor AS $$
BEGIN
OPEN $1 FOR SELECT * FROM table_1;
RETURN NEXT $1;
OPEN $2 FOR SELECT * FROM table_2;
RETURN NEXT $2;
END;
$$ LANGUAGE plpgsql;
-- need to be in a transaction to use cursors.
BEGIN;
SELECT * FROM myfunc('a', 'b');
FETCH ALL FROM a;
FETCH ALL FROM b;
COMMIT;
40.7.4. Looping Through a Cursor's Result
There is a variant of the FOR statement that allows iterating through the rows returned by a cursor. The syntax is:
[ < 注意到,共有两种方式可以调用游标:
好了,下面改改例子:
create or replace function func05(caller_cursor refcursor)
returns refcursor as
$$
BEGIN
open caller_cursor for select * from member;
return caller_cursor;
END;
$$LANGUAGE plpgsql volatile ;
接下来,运行:
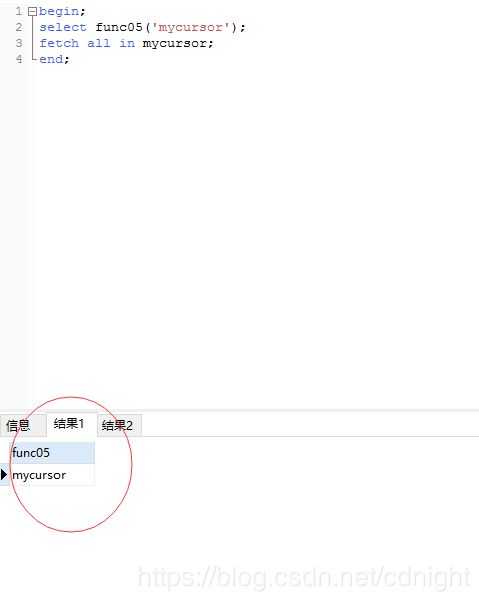
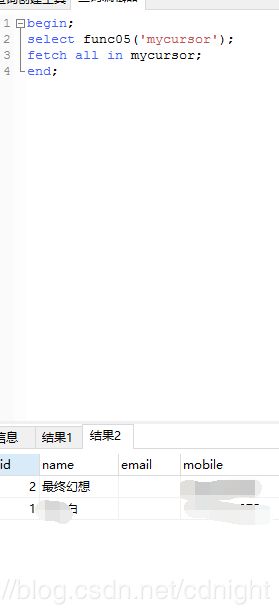
注意,字符串中是不分大小写的!
返回复合结果的处理方式
下面以一个例子说明情况:
对于一个分页的存储过程,要求能够返回总记录数量,总共多少页,还有要返回记录结果集,如下:
代码如下:
CREATE OR REPLACE FUNCTION public.test_pager(
in pageIndex integer,
in pageSize integer,
records_cursor refcursor,
OUT total_size integer,
OUT total_pages integer
)
RETURNS refcursor
/*
* 该函数用于试验如何一次返回多个结果。
*/
AS $BODY$
declare tmpVal vachar(200);
begin
open records_cursor for select * from member;
total_size:=2;
total_pages:=1;
tmpVal:='hello world';
RETURN records_cursor;
end;
$BODY$
LANGUAGE plpgsql volatile;
执行结果如下:
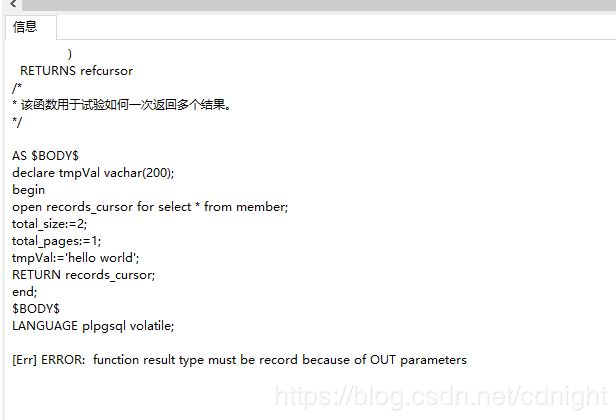
在多个结果集时候,返回的result type 必须为record。。
这。。。压根没法用。因为存储过程的一个很重要的优点是,应用服务器(譬如java)不需要多次读取数据库的数据,只需要一次取就是了,所以,必须要有自由返回任意结果或者结果集的机制。
参考资料之后,改写为 setof refcursor:
CREATE OR REPLACE FUNCTION public.test_pager(
in pageIndex integer,
in pageSize integer,
outline_cursor refcursor,
records_cursor refcursor
)
RETURNS setof refcursor
/*
* 该函数用于试验如何一次返回多个结果。
*/
AS $BODY$
declare tmpVal varchar(200);
declare total_size integer;
declare total_pages integer;
begin
open records_cursor for select * from member;
total_size:=2;
total_pages:=1;
tmpVal:='hello world';
/*返回多个结果集*/
open outline_cursor for select total_size , total_pages;
return next outline_cursor;
RETURN next records_cursor;
end;
$BODY$
LANGUAGE plpgsql volatile;
执行代码:
begin;
select test_pager(1, 1, 'outline_cursor', 'record_cursor');
fetch all in outline_cursor;
fetch all in record_cursor;
end;
执行结果:
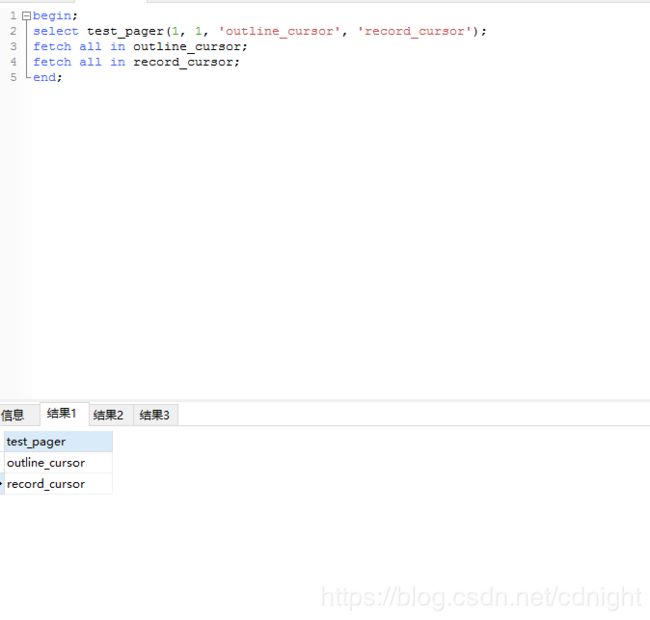
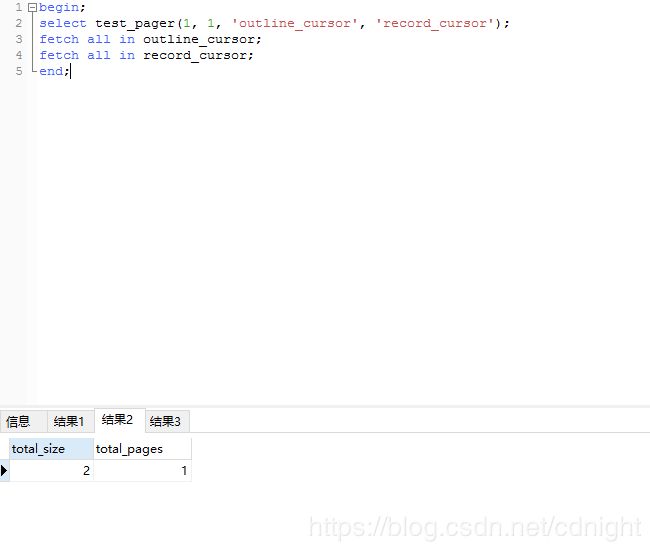
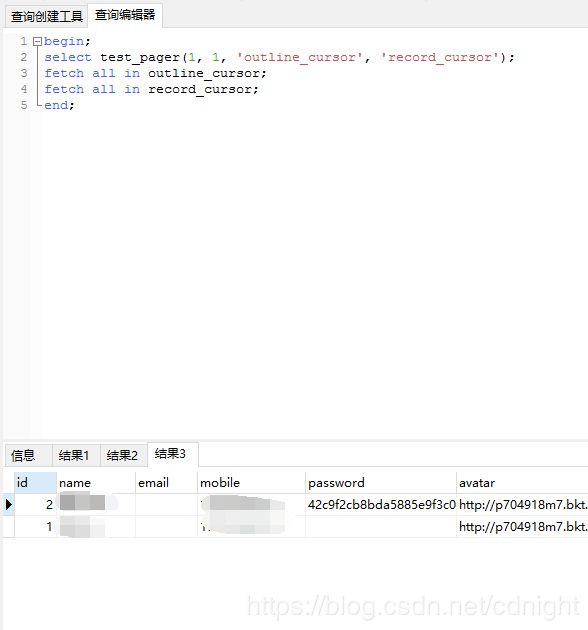
基本上算是完美解决分页存储过程返回多个结果集的难点了。
返回多个结果集的处理形式
jdbc调用存储过程获取多个结果集
Spring JdbcTemplate方法详解