redis源码分析系列文章
[Redis源码系列]在Liunx安装和常见API
为什么要从Redis源码分析
String底层实现——动态字符串SDS
双向链表都不懂,还说懂Redis?
面试官:说说Redis的Hash底层 我:......(来自阅文的面试题)
Redis的跳跃表确定不了解下
多图解释Redis的整数集合intset升级过程
前言
hello,大家好,又见面啦。
前面几周我们一起看了Redis底层数据结构,如动态字符串SDS,双向链表Adlist,字典Dict,跳跃表,整数集合intset,如果有对Redis常见的类型或底层数据结构不明白的请看上面传送门。
今天来说下zset的底层实现压缩表(在数据库量小的时候用),如果有对zset不明白的,看上面的传送门哈。
压缩列表的概念提出
传统的数组
同之前的底层数据一样,压缩列表也是由Redis设计的一种数据存储结构。
他有点类似于数组,都是通过一片连续的内存空间来存储数据。但是其和数组也有点区别,数组存储不同长度的字符时,会选择最大的字符长度作为每个节点的内存大小。
如下图,一共五个元素,每个元素的长度都是不一样的,这个时候选择最大值5作为每个元素的内存大小,如果选择小于5的,那么第一个元素hello,第二个元素world就不能完整存储,数据会丢失。

存在的问题
上面已经提到了需要用最大长度的字符串大小作为整个数组所有元素的内存大小,如果只有一个元素的长度超大,但是其他的元素长度都比较小,那么我们所有元素的内存都用超大的数字就会导致内存的浪费。
那么我们应该如何改进呢?
引出压缩列表
Redis引入了压缩列表的概念,即多大的元素使用多大的内存,一切从实际出发,拒绝浪费。
如下图,根据每个节点的实际存储的内容决定内存的大小,即第一个节点占用5个字节,第二个节点占用5个字节,第三个节点占用1个字节,第四个节点占用4个字节,第五个节点占用3个字节。
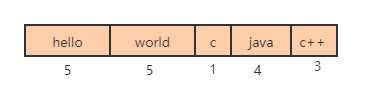
还有一个问题,我们在遍历的时候不知道每个元素的大小,无法准确计算出下一个节点的具体位置。实际存储不会出现上图的横线,我们并不知道什么时候当前节点结束,什么时候到了下一个节点。所以在redis中添加length属性,用来记录前一个节点的长度。
如下图,如果需要从头开始遍历,取某个节点后面的数字,比如取“hello”的起始地址,但是不知道其结束地址在哪里,我们取后面数字5,即可知道"hello"占用了5个字节,即可顺利找到下一节点“world”的起始位置。

压缩列表图解分析
整个压缩列表图解如下,大家可以大概看下,具体的后面部分会详细说明。


表头
表头包括四个部分,分别是内存字节数zlbytes,尾节点距离起始地址的字节数zltail_offset,节点数量zllength,标志结束的记号zlend。
![]()
![]()
- zlbytes:记录整个压缩列表占用的内存字节数。
- zltail_offset:记录压缩列表尾节点距离压缩列表的起始地址的字节数
(目的是为了直接定位到尾节点,方便反向查询)。 - zllength:记录了压缩列表的节点数量。即在上图中节点数量为2。
- zlend:保存一个常数255(0xFF),标记压缩列表的末端。
数据节点
数据节点包括三个部分,分别是前一个节点的长度prev_entry_len,当前数据类型和编码格式encoding,具体数据指针value。
![]()
- prev_entry_len:记录前驱节点的长度。
- encoding:记录当前数据类型和编码格式。
- value:存放具体的数据。
压缩列表的具体实现
压缩列表的构成
Redis并没有像之前的字符串SDS,字典,跳跃表等结构一样,封装一个结构体来保存压缩列表的信息。而是通过定义一系列宏来对数据进行操作。
也就是说压缩列表是一堆字节码,咱也看不懂,Redis通过字节之间的定位和计算来获取数据的。
//返回整个压缩列表的总字节 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //返回压缩列表的tail_offset变量,方便获取最后一个节点的位置 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //返回压缩列表的节点数量 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //返回压缩列表的表头的字节数 //(内存字节数zlbytes,最后一个节点地址ztail_offset,节点总数量zllength) #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //返回压缩列表最后结尾的字节数 #define ZIPLIST_END_SIZE (sizeof(uint8_t)) //返回压缩列表首节点地址 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) //返回压缩列表尾节点地址 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) //返回压缩列表最后结尾的地址 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
压缩列表节点的构成
我们看下面的代码,重点看注释,Note that this is not how the data is actually encoded,这句话说明这并不是数据的实际存储格式。
是不是有点逗,定义了却没使用。

因为,这个结构存储实在是太浪费空间了。这个结构32位机占用了25(int类型5个,每个int占4个字节,char类型1个,每个char占用1个字节,char*类型1个,每个char*占用4个字节,所以总共5*4+1*1+1*4=25)个字节,在64位机占用了29(int类型5个,每个int占4个字节,char类型1个,每个char占用1个字节,char*类型1个,每个char*占用8个字节,所以总共5*4+1*1+1*8=29个字节)。这不符合压缩列表的设计目的。
/* We use this function to receive information about a ziplist entry. * Note that this is not how the data is actually encoded, is just what we * get filled by a function in order to operate more easily. */ typedef struct zlentry { unsigned int prevrawlensize; //记录prevrawlen需要的字节数 unsigned int prevrawlen; //记录上个节点的长度 unsigned int lensize; //记录len需要的字节数 unsigned int len; //记录节点长度 unsigned int headersize; //prevrawlensize+lensize unsigned char encoding; //编码格式 unsigned char *p; //具体的数据指针 } zlentry;
所以Redis对上述结构进行了改进了,抽象合并了三个参数。
prev_entry_len:prevrawlensize和prevrawlen的总和。
如果前一个节点长度小于254字节,那么prev_entry_len使用一个字节表示。
如果前一个节点长度大于等于254字节,那么prev_entry_len使用五个字节表示。第一个字节为常数oxff,后面四位为真正的前一个节点的长度。
encoding:lensize和len的总和。Redis通过设置了一组宏定义,使其能够具有lensize和len两种功能。(具体即不展开了)
value:具体的数据。
压缩列表的优点
压缩列表的缺点
因为压缩表是紧凑存储的,没有多余的空间。这就意味着插入一个新的元素就需要调用函数扩展内存。过程中可能需要重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址。
如果数据量太多,重新分配内存和拷贝数据会有很大的消耗。所以压缩表不适合存储大型字符串,并且数据元素不能太多。
压缩列表的连锁更新过程图解(重点)
前面提到每个节点entry都会有一个prevlen字段存储前一个节点entry的长度,如果内容小于254,prevlen用一个字节存储,如果大于254,就用五个字节存储。这意味着如果某个entry经过操作从253字节变成了254字节,那么他的下一个节点entry的pervlen字段就要更新,从1个字节扩展到5个字节;如果这个entry的长度本来也是253字节,那么后面entry的prevlen字段还得继续更新。
如果每个节点entry都存储的253个字节的内容,那么第一个entry修改后会导致后续所有的entry的级联更新,这是一个比较损耗资源的操作。
所以,发生级联更新的前提是有连续的250-253字节长度的节点。
步骤一
比如一开始的压缩表呈现下图所示(XXXX表示字符串),现在想要把第二个数据的改大点,哪个时候就会发生级联更新了。

步骤二
我们想要分配四个长度的大小给第三个数据的prevlen,因为第二个元素的prevlen字段是表示他前一个元素的大小。

步骤三
调整完发现第三个元素的长度增加了,所以第四个元素的prevlen字段也需要修改。

步骤四
调整完发现第四个元素的长度增加了,所以把第五个元素的prevlen字段也需要修改。
压缩列表的源码分析
创建空的压缩表ziplistNew
主要的步骤是分配内存空间,初始化属性,设置结束标记为常量,最后返回压缩表。
unsigned char *ziplistNew(void) { //表头加末端大小 unsigned int bytes = ZIPLIST_HEADER_SIZE+1; //为上面两部分(表头和末端)分配空间 unsigned char *zl = zmalloc(bytes); //初始化表属性 ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); ZIPLIST_LENGTH(zl) = 0; //设置模块,赋值为常量 zl[bytes-1] = ZIP_END; return zl; }
级联更新(重点)
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) { size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize; size_t offset, noffset, extra; unsigned char *np; zlentry cur, next; //while循环,当到最后一个节点的时候结束循环 while (p[0] != ZIP_END) { //将节点数据保存在cur中 zipEntry(p, &cur); //取前节点长度编码所占字节数,和当前节点长度编码所占字节数,在加上当前节点的value长度 //rawlen = prev_entry_len + encoding + value rawlen = cur.headersize + cur.len; rawlensize = zipStorePrevEntryLength(NULL,rawlen); //如果没有下一个节点则跳出循环 if (p[rawlen] == ZIP_END) break; //取出后面一个节点放在next中 zipEntry(p+rawlen, &next); //当next的prevrawlen,即保存的上一个节点等于rawlen,说明不需要调整,现在的长度合适 if (next.prevrawlen == rawlen) break; //如果next对前一个节点长度的编码所需的字节数next.prevrawlensize小于上一个节点长度进行编码所需要的长度 //因此要对next节点的header部分进行扩展,以便能够表示前一个节点的长度 if (next.prevrawlensize < rawlensize) { //记录当前指针的偏移量 offset = p-zl; ///需要扩展的字节数 extra = rawlensize-next.prevrawlensize; //调整压缩列表的空间大小 zl = ziplistResize(zl,curlen+extra); //还原p指向的位置 p = zl+offset; //next节点的新地址 np = p+rawlen; //记录next节点的偏移量 noffset = np-zl; //更新压缩列表的表头tail_offset成员,如果next节点是尾节点就不用更新 if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra); } //移动next节点到新地址,为前驱节点cur腾出空间 memmove(np+rawlensize, np+next.prevrawlensize, curlen-noffset-next.prevrawlensize-1); //将next节点的header以rawlen长度进行重新编码,更新prevrawlensize和prevrawlen zipStorePrevEntryLength(np,rawlen); //更新p指针,移动到next节点,处理next的next节点 p += rawlen; //更新压缩列表的总字节数 curlen += extra; } else { // 如果需要的内存反而更少了则强制保留现有内存不进行缩小 // 仅浪费一点内存却省去了大量移动复制操作而且后续增大时也无需再扩展 if (next.prevrawlensize > rawlensize) { zipStorePrevEntryLengthLarge(p+rawlen,rawlen); } else { zipStorePrevEntryLength(p+rawlen,rawlen); } /* Stop here, as the raw length of "next" has not changed. */ break; } } return zl; }
结语
该篇主要讲了Redis的zset数据类型的底层实现压缩表,先从压缩表是什么,剖析了其主要组成部分,进而通过多幅过程图解释了压缩表是如何层级更新的,最后结合源码对压缩表进行描述,如创建过程,升级过程,中间穿插例子和过程图。
如果觉得写得还行,麻烦给个赞,您的认可才是我写作的动力!
如果觉得有说的不对的地方,欢迎评论指出。
好了,拜拜咯。