生产服务内存高问题
问题描述
-
1、“计算中心” 服务堆内存分配4g,在生产环境运行一段时间后,实际占用内存4.8G,业务运行正常,未出现OOM。(本文以此服务进行排查)
-
2、生产环境的老项目,均出现运行一段时间后,内存被占满但未OOM的情况。部分实例因内存占用过高导致被系统kill,一般需要通过增加机器、实例进行解决(资源浪费)。
造成的影响
-
1、服务器物理内存15g,部署了三个服务。如实际占用内存都超过4.8g,导致服务器物理内存不够用,出现告警而将占用内存最大进程kill掉,影响生产服务的可用性,后果十分严重。
-
2、如服务申请的内存超出了JVM能提供的内存大小(内存泄漏),将会导致java堆内存溢出,从而发生full gc,导致服务响应大幅度变慢,卡机等状态。
-
3、在公司大促等场景的情况下,内存占用很高的服务会带来很大风险,通常需提前联系运维同事对“计算中心”进行重启,增加了开发及运维同事维护的工作量。
排查过程
代码
(1)根据cat监控,获取“计算中心”中的热点方法,进行REVIEW,修正了部分可能会导致内存泄露的方法。并进行了观察。
(2)通过VisualVM监控,定位到部分耗时较久的操作DB热点方法,通过增加索引等方式,把查询性能控制在毫秒级。
(3)dump“计算中心”的内存镜像,通过MAT等工具观察各个对象在堆空间中所占用的内存大小、类实例数量、对象引用关系。
结论:通过以上三点,未解决和定位“计算中心”内存高问题。由此可以认为,“计算中心”的内存占用问题与代码无关。
系统
通过java ps| aux java 查看,“计算中心”服务实际占用的内存在4.9G左右,超过了JVM堆内存设置的大小但并未出现OOM,业务正常运行。通过free -g命令,可以发现buff/cache,3个g左右。centos中内存的分配是buff/cache + free + used=物理内存大小,系统分配给临时文件系统的大小默认是用掉一半的物理内存,这样会造成buff/cache很大,而free很小。最终结论可能为服务内存没有释放使用了buff/cache。导致服务内存占用很高。

结论:和SRE沟通实际重启服务后,内存使用率立刻降低,但是buff/cache的大小没有变化。由此可以认为,“计算中心”的内存占用问题与系统缓存无关。
JVM
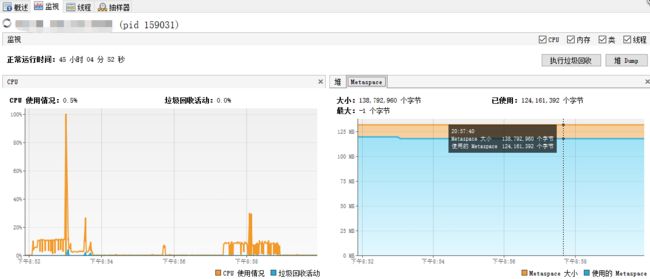
1、通过VisualVM监控生产环境computing内存使用情况得出,在服务内存占用4.8g的情况下,堆内存(新生代 + 老年代)正常GC,在增长到2g左右会GC到300~500m,Matespace仅使用了120m左右。检查了生产JVM参数。项目启动参数没有配置:-XX:MaxDirectMemorySize,来指定最大的堆外内存大小。这个阈值不配置的话,默认占用-Xmx相同的内存。在堆内内存正常的情况下,怀疑是堆外内存占用了大部分内存,导致服务内存占用很高。
结论:和SRE沟通,在生产环境找了两台计算中心服务实例配置 -XX:MaxDirectMemorySize 参数后实际观察后,仍未解决“计算中心”内存高问题。由此可以认为,“计算中心”的内存占用问题与堆外内存无关。
2、在发现-XX:MaxDirectMemorySize 指定堆外内存大小的参数没有配置后。我检查了“计算中心”服务的启动参数并且和之前生产环境的服务进行了对比,发现了以下问题。
1)生产及测试环境JVM参数配置混乱,同一应用不同实例多套启动参数配置。
2)服务启动参数,未区分JDK版本。如:JDK1.7、JDK1.8参数混用。
3)生产服务根据模板部署,导致必要JVM参数未配置,部分参数配置不需要、不合理。
4)不同类型的应用,采用统一的启动参数配置,不具有针对性。
在以上问题的基础上,基于目前生产环境各项目统一使用的"CMS垃圾回收器"进行参数调整。针对计算中心的JDK版本(1.8),出了一套JVM配置方案。并在生产服务器调整后重启观察。
结论:“计算中心”生产环境服务,在运行一段时间后,仍出现内存占用高问题。由此可以认为,“计算中心”的内存占用问题与不同JDK版本的参数混用问题无关。
3、经调研,逐渐被淘汰的垃圾回收器比如ParallelOldGC和CMS,只要JVM申请过的内存,即使发生了GC回收了很多内存空间,JVM也不会把这些内存归还给操作系统。这就会导致top命令中看到的RSS(进程RAM中实际保存的总内存)只会越来越高,而且一般都会超过Xmx的值。JDK1.9以后。默认的垃圾回收器已经选择了G1。
G1相比CMS有更清晰的优势:
1)CMS采用"标记-清理"算法,所以它不能压缩,最终导致内存碎片化问题。而G1采用了复制算法,它通过把对象从若干个Region(独立区域)拷贝到新的Region(独立区域)过程中,执行了压缩处理,垃圾回收后会整合空间,无内存碎片。
2)在G1中,堆是由Region(独立区域)组成的,因此碎片化问题比CMS肯定要少的多。而且,当碎片化出现的时候,它只影响特定的Region(独立区域),而不是影响整个堆中的老年代。
3)而且CMS必须扫描整个堆来确认存活对象,所以,长时间停顿是非常常见的,无法预测停顿时间。而G1的停顿时间取决于收集的Region(独立区域)集合数量,在指定时间内只回收部分价值最大的空间,而不是整个堆的大小,所以相比起CMS,长时间停顿要少很多,可控很多。
4)G1选回收阶段不会产生“浮动垃圾”,由于只回收部分Region(独立区域),所以STW(stop-The-World机制简称STW,是在执行垃圾收集算法时,Java应用程序的其他所有线程都被挂起)时间我们可控,所以不需要与用户线程并发争抢CPU资源。而CMS并发清理需要占据一部分的CPU,会降低吞吐量。G1由于STW,所以不会产生"浮动垃圾",CMS在并发清理阶段会产生的无法回收的垃圾。
因此在以下场景下G1更适合:
1)服务端多核CPU、JVM内存占用较大的应用。
2)应用在运行过程中会产生大量内存碎片、需要经常压缩空间。
3)想要更可控、可预期的GC停顿周期;防止高并发下应用雪崩现象。
结论:将”计算中心“使用的垃圾回收机制升级为G1,并增加G1相关的优化内存的参数,在生产服务器进行观察一周后发现服务内存始终稳定在了3.3G左右,业务处理性能稳定,成功解决了“计算中心”服务占用内存较高的问题,提升了系统的可用性,无需通过增加物理资源来提升服务整体性能。
CMS升级为G1方式
计算中心“生产全部服务实例部署的服务器,使用的是JDK1.8,JDK1.8支持G1垃圾回收器,故将服务启动参数进行统一调整:
1)原参数(主要问题:使用CMS版本,JDK1.7,1.8参数混用,未指定堆外内存大小)
/opt/java/jdk1.8.0_102/bin/java -Dapp.home=${APP_HOME} -Dspring.profiles.active=prd -Dserver.port=${SERVER_PORT} -server -Xms4G -Xmx4G -Xmn2g -Xss256k -XX:PermSize=128m -XX:MaxPermSize=512m -Djava.awt.headless=true -Dfile.encoding=utf-8 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:AutoBoxCacheMax=20000 -XX:-OmitStackTraceInFastThrow -XX:ErrorFile=${APP_HOME}/logs/hs_err_%p.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${APP_HOME}/logs/ -Xloggc:${APP_HOME}/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -jar ${APP_HOME}/webapps/${JAR_NAME} ${SERVER_PORT}"
2)新参数(使用G1做为垃圾回收器)
/opt/java/jdk1.8.0_102/bin/java -Dapp.home=${APP_HOME} -Dspring.profiles.active=prd -Dserver.port=${SERVER_PORT} -server -Xms4g -Xmx4g -Xss256k -XX:NewSize=512m -XX:MaxNewSize=512m -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=40 -XX:G1HeapRegionSize=8m -XX:+ExplicitGCInvokesConcurrent -XX:ParallelGCThreads=4 -Dsun.rmi.dgc.server.gcInterval=36000000-Dsun.rmi.dgc.client.gcInterval=36000000-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m -XX:+UseCodeCacheFlushing -XX:ReservedCodeCacheSize=256m -XX:MaxDirectMemorySize=512m -XX:GCTimeRatio=19 -XX:MinHeapFreeRatio=20 -XX:MaxHeapFreeRatio=30 -XX:ErrorFile=${APP_HOME}/logs/hs_err_%p.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${APP_HOME}/logs/ -Xloggc:${APP_HOME}/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -jar ${APP_HOME}/webapps/${JAR_NAME} ${SERVER_PORT}"
注:不同服务器环境,不同容器,脚本配置各不相同,要在对应脚本的基础上进行针对性升级。
生产G1回收器主要参数说明

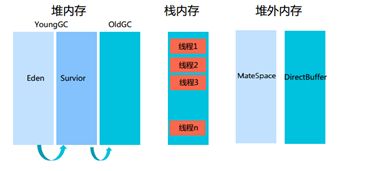
JVM相关概念说明
JDK1.7内存模型
实际占用内存大小(参数):-XX:MaxPermSize(非堆) + -Xmx(堆) + -Xss(栈) + -XX:MaxDirectMemorySize(堆外)

JDK1.8内存模型
实际占用内存大小(参数):-XX:MaxMateSpaceSize(堆外) + -Xmx(堆) + -Xss(栈) + -XX:MaxDirectMemorySize(堆外)
GC流程图
1、什么时候触发Minor GC
2、触发Minor GC 的过程
3、Full GC 的过程
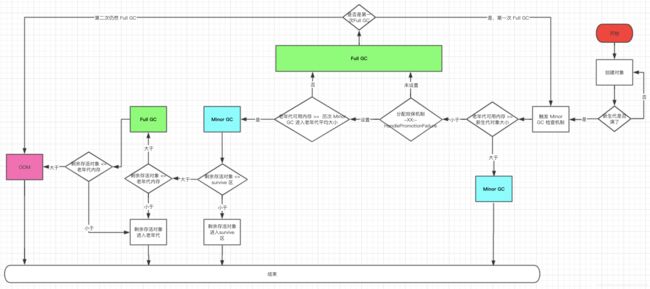
1、新创建的对象一般会被分配在新生代中。常用的新生代的垃圾回收器是 ParNew 垃圾回收器,它按照 8:1:1 将新生代分成 Eden 区,以及两个 Survivor 区。创建的对象将 Eden 区全部挤满,这个对象就是「挤满新生代的最后一个对象」。此时,Minor GC 就触发了。
2、在正式 Minor GC 前,JVM 会先检查新生代中对象,是比老年代中剩余空间大还是小。Minor GC 之后 Survivor 区放不下剩余对象,这些对象就要进入到老年代,所以要提前检查老年代是不是够用。
3、老年代剩余空间大于新生代中的对象大小,那就直接 Minor GC,GC 完 survivor 不够放,老年代也绝对够放。老年代剩余空间小于新生代中的对象大小,这时候就要进入老年代空间分配担保规则。
4、老年代空间分配担保规则:如果老年代中剩余空间大小,大于历次 Minor GC 之后剩余对象的大小,那就允许进行 Minor GC。因为从概率上来说,以前的放的下,这次的也应该放的下。那就有两种情况:
-
老年代中剩余空间大小,大于历次 Minor GC 之后剩余对象的大小,进行 Minor GC
-
老年代中剩余空间大小,小于历次 Minor GC 之后剩余对象的大小,进行 Full GC,把老年代空出来再检查。
-
结合第四步,开启老年代空间分配担保规则只能说是大概率上来说,Minor GC 剩余后的对象够放到老年代,如果放不下:Minor GC 后会有这样三种情况:
-
Minor GC 之后的对象足够放到 Survivor 区,GC 结束。
-
Minor GC 之后的对象不够放到 Survivor 区,接着进入到老年代,老年代能放下,那也可以,GC 结束。
-
Minor GC 之后的对象不够放到 Survivor 区,老年代也放不下,那就只能 Full GC。
-
以上是成功 GC 的例子,以下3 中情况,会导致 GC 失败,报 OOM:
紧接上一节 Full GC 之后,老年代任然放不下剩余对象,就只能 OOM。
未开启老年代分配担保机制,且一次 Full GC 后,老年代任然放不下剩余对象,也只能 OOM。
开启老年代分配担保机制,但是担保不通过,一次 Full GC 后,老年代任然放不下剩余对象,也是能 OOM。
注:
- 老年代分配担保机制在JDK1.5以及之前版本中默认是关闭的,需要通过HandlePromotionFailure手动指定,JDK1.6之后就默认开启。如果我们生产环境服务使用的是JDK/1.7JDK1.8,所以不用再手动去开启担保机制。
- Full GC主要指新生代、老年代、metaspace上的全部GC。
感谢以下作者给与我的帮助
- 图解GC流程:https://www.cnblogs.com/shuiyj/p/12640692.html
- CMS垃圾回收升级G1回收器实践:http://arick.net/content/44
- JAVA常见问题分析:https://blog.51cto.com/hmtk520/2067043