SparkStreaming入门及数据丢失处理、容错
目录
1、SparkStreaming
2、SparkStreaming程序入口
3、SparkStreaming初始理解
4、什么是DStream
5、数据源
5.1、Socket数据源
5.2、HDFS数据源
5.3、自定义数据源
5.4、kafka数据源
6、Spark任务设置自动重启
步骤一:设置自动重启Driver程序
步骤二:设置HDFS的checkpoint目录
步骤三:代码实现
7、数据丢失如何处理
步骤一:设置checkpoint目录
步骤二:开启WAL日志
步骤三:需要reliable receiver
步骤四:取消备份
8、SparkStreaming的容错(当一个task非常慢的时候)
方案一:开启推测机制:(首先保障没有数据倾斜)
方案二:sparkStreaming与kafka整合(具体参数下一篇博客)
1、SparkStreaming
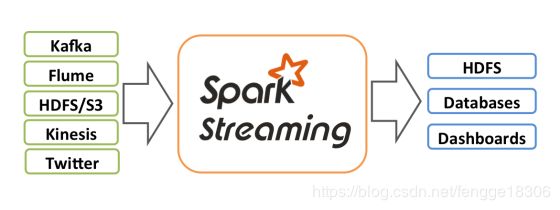
Spark流是对于Spark核心API的拓展,从而支持对于实时数据流的可拓展,高吞吐量和容错性流处理。数据可以由多个源取得,例如:Kafka,Flume,socket等,同时可以使用由如map,reduce,join和window这样的高层接口描述的复杂算法进行处理。最终,处理过的数据可以被推送到文件系统,数据库和HDFS。
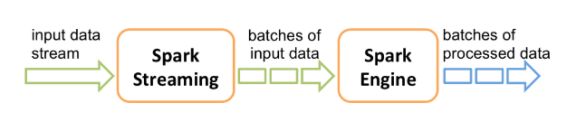
在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批处理,然后由Spark引擎进行处理,以生成批处理的最终结果流。
2、SparkStreaming程序入口
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
3、SparkStreaming初始理解
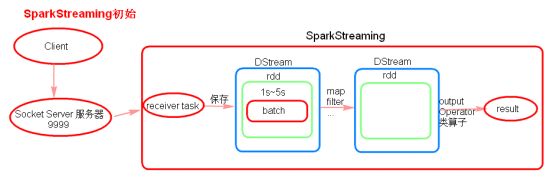
- receiver task是7*24小时一直在执行,一直接受数据,将一段时间内接收来的数据保存到batch中。
- 假设batchInterval为5s,那么会将接收来的数据每隔5秒封装到一个batch中,batch没有分布式计算特性,这一个batch的数据又被封装到一个RDD中,RDD最终封装到一个DStream中。
4、什么是DStream
离散数据流或者DStream是SparkStreaming提供的基本抽象。其表现数据的连续流,这个输入数据流可以来自于源,也可以来自于转换输入流产生的已处理数据流。内部而言,一个DStream以一系列连续的RDDs所展现,这些RDD是Spark对于不变的,分布式数据集的抽象。一个DStream中的每个RDD都包含来自一定间隔的数据,如下图:
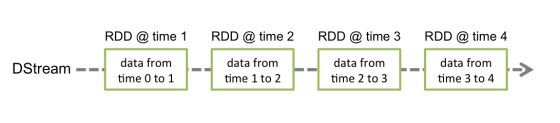
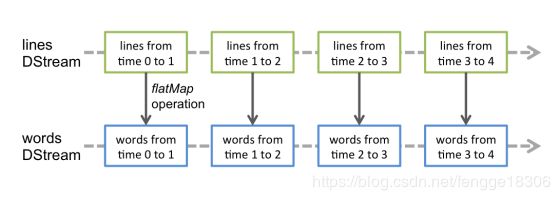
在DStream上使用的任何操作都会转换为针对底层RDD的操作。例如:将行的流转变为词流,flatMap操作应用于行DStream的每个RDD上 从而产生words DStream的RDD。如下图:
5、数据源
5.1、Socket数据源
val lines = ssc.socketTextStream("node01", 9999) //scala代码
或
JavaReceiverInputDStream
lines = jssc.socketTextStream("node01", 9999); //java代码
5.2、HDFS数据源
val lines = ssc.textFileStream("/tmp");
5.3、自定义数据源
// 调用 receiverStream api,将自定义的Receiver传进去
val lines = ssc.receiverStream(new CustomReceiver("10.148.15.10", 9999))定义类CustomReceiver继承Reciever类
5.4、kafka数据源
//0.8版
val lines = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topics)
//0.10版
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
6、Spark任务设置自动重启
Spark任务是可以设置自动重启的,但是client模式是不支持自动重启功能,只能是cluster模式支持。
而且不同的运行场景,设置自动重启的方式不一样。
步骤一:设置自动重启Driver程序
(1)Standalone:
在spark-submit中增加以下两个参数:
--deploy-mode cluster
--supervise
(2)Yarn:
在spark-submit中增加以下参数:
--deploy-mode cluster
在yarn配置中设置yarn.resourcemanager.am.max-attemps 3
一定要设置,因为我们是分布式的程序,有些时候我们的任务就是因为网络发送抖动,
步骤二:设置HDFS的checkpoint目录
val checkpointDirectory:String="hdfs://node01:8020/streamingcheckpoint2";
streamingContext.setCheckpoint(checkpointDirectory)
步骤三:代码实现
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
7、数据丢失如何处理
利用WAL把数据写入到HDFS中,如下四个步骤:
WAL
WAL:Write-Ahead-Log,使用在文件系统和数据库中用于数据操作的持久性,先把数据写到一个持久化的日志中(实质上是写入checkpoint目录中),然后对数据做操作,如果操作过程中系统挂了,恢复的时候可以重新读取日志文件再次进行操作。
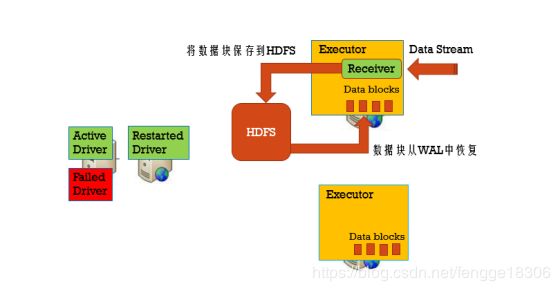
步骤一:设置checkpoint目录
streamingContext.setCheckpoint(hdfsDirectory)
步骤二:开启WAL日志
sparkConf.set(“spark.streaming.receiver.writeAheadLog.enable”, “true”)
步骤三:需要reliable receiver
当数据写完了WAL后,才告诉数据源数据已经消费;对于没有告诉数据源的数据,可以从数据源中重新消费数据。
步骤四:取消备份
使用StorageLevel.MEMORYANDDISK_SER来存储数据源,不需要后缀为2的策略了,因为HDFS已经是多副本了。
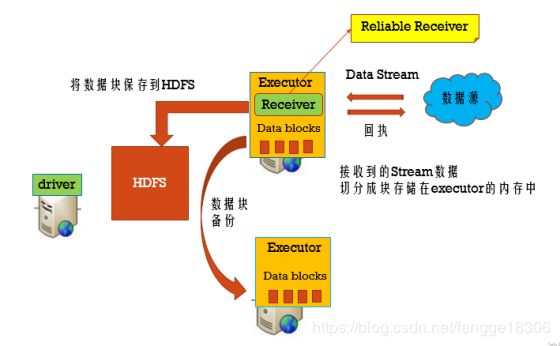
Reliable Receiver : 当数据接收到,并且已经备份存储后,再发送回执给数据源(Kafka)。
Unreliable Receiver : 不发送回执给数据源(socket)。
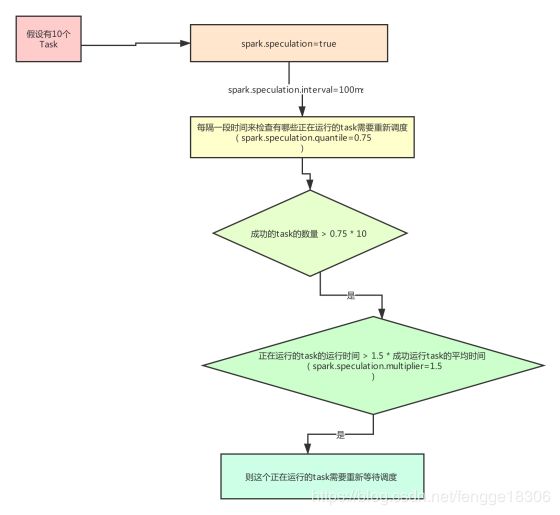
8、SparkStreaming的容错(当一个task非常慢的时候)
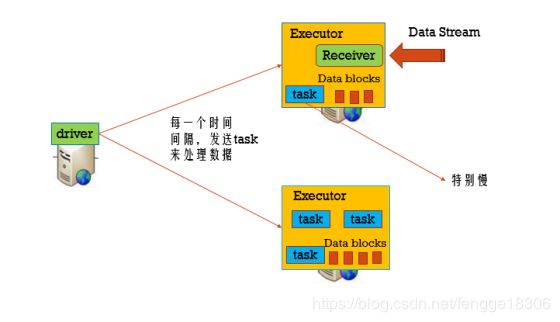
方案一:开启推测机制:(首先保障没有数据倾斜)
spark.speculation=true,每隔一段时间来检查有哪些正在运行的task需要重新调度(spark.speculation.interval=100ms),假设总的task有10个,成功的task的数量 > 0.75 * 10(spark.speculation.quantile=0.75),正在运行的task的运行时间 > 1.5 * 成功运行task的平均时间(spark.speculation.multiplier=1.5),则这个正在运行的task需要重新等待调度。