fastjson源码分析(番外篇):一个偶然发现的反序列化“bug”
背景
项目中,有一个需求是需要传递一些数据到别的项目方,如果是基本类型或者java自带的类,那么可以直接传递对应的对象,如果是目标项目的类,那么传递json字符串,所以就有了下面这段测试代码:
package test;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.TypeReference;
import com.alibaba.fastjson.parser.ParserConfig;
import com.alibaba.fastjson.serializer.SerializerFeature;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
public class WeiTest {
private Date gmtCreate;
private Date gmtModified;
public Date getGmtCreate() {
return gmtCreate;
}
public void setGmtCreate(Date gmtCreate) {
this.gmtCreate = gmtCreate;
}
public Date getGmtModified() {
return gmtModified;
}
public void setGmtModified(Date gmtModified) {
this.gmtModified = gmtModified;
}
public static void main(String[] args) throws ParseException {
/*SerializeConfig mapping = new SerializeConfig();
mapping.put(Date.class, new DateObjectSerializer());*/
Map map = new HashMap<>(16);
Date date = new SimpleDateFormat("yyyy-MM-dd").parse("2019-07-09");
map.put("gmtCreate", date);
map.put("gmtModified", date);
map.put("@type", "test.WeiTest");
//
//WeiTest weiTest = new WeiTest();
//weiTest.setGmtCreate(new Date());
//weiTest.setGmtModified(new Date());
String jsonStr = JSON.toJSONString(map, SerializerFeature.WriteClassName);
System.out.println(jsonStr);
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
Object object = JSON.parseObject(jsonStr, new TypeReference 用map模拟javaBean,手动设置“@type”的值,指定了类型。
问题
运行在JSON.parseObject的时候失败了, 报错:
{"gmtModified":new Date(1562601600000),"@type":"test.WeiTest","gmtCreate":new Date(1562601600000)}
Exception in thread "main" com.alibaba.fastjson.JSONException: syntax error, expect ,, actual new
at com.alibaba.fastjson.parser.DefaultJSONParser.accept(DefaultJSONParser.java:1469)
at com.alibaba.fastjson.parser.deserializer.AbstractDateDeserializer.deserialze(AbstractDateDeserializer.java:140)
at com.alibaba.fastjson.parser.deserializer.AbstractDateDeserializer.deserialze(AbstractDateDeserializer.java:16)
at com.alibaba.fastjson.parser.DefaultJSONParser.parseObject(DefaultJSONParser.java:954)
at com.alibaba.fastjson.parser.DefaultJSONParser.parseObject(DefaultJSONParser.java:373)
at com.alibaba.fastjson.parser.DefaultJSONParser.parse(DefaultJSONParser.java:1367)
at com.alibaba.fastjson.parser.deserializer.JavaObjectDeserializer.deserialze(JavaObjectDeserializer.java:51)
at com.alibaba.fastjson.parser.DefaultJSONParser.parseObject(DefaultJSONParser.java:671)
at com.alibaba.fastjson.JSON.parseObject(JSON.java:365)
at com.alibaba.fastjson.JSON.parseObject(JSON.java:333)
at com.alibaba.fastjson.JSON.parseObject(JSON.java:247)
at test.WeiTest.main(WeiTest.java:51)看起来是格式错了,解析失败。但是很奇怪的是,如果去掉其中一个,变成这样:
map.put("gmtModified", date);
map.put("@type", "test.WeiTest");或者修改一个属性(属性名和get和set全部修改),变成这样:
map.put("gmtCreate", date);
map.put("gmtCreate1", date);
map.put("@type", "test.WeiTest");得到的却是正确的反序列化结果。 这种现象看着是很神奇的,字段名称竟然能决定反序列化的结果?抱着“打破沙锅问到底”的心态,决定探究下源码,解释这个现象。
解析
1.直接跟进去,到DefaultJSONParser的parseObject方法:
lexer是一个词法分析器,里面持有各种参数, text是传入jsonStr;len是jsonStr长度;token是当前探测到的符号;features是特征值;
此时,type传进来的是class java.lang.Object,fieldName为null。
public T parseObject(Type type, Object fieldName) {
int token = lexer.token();
if (token == JSONToken.NULL) {
lexer.nextToken();
return null;
}
if (token == JSONToken.LITERAL_STRING) {
if (type == byte[].class) {
byte[] bytes = lexer.bytesValue();
lexer.nextToken();
return (T) bytes;
}
if (type == char[].class) {
String strVal = lexer.stringVal();
lexer.nextToken();
return (T) strVal.toCharArray();
}
}
//type传进来的是class java.lang.Object,所以得到的反序列化器是JavaObjectDeserializer
//跟ObjectDeserializer区分开
ObjectDeserializer derializer = config.getDeserializer(type);
try {
if (derializer.getClass() == JavaBeanDeserializer.class) {
return (T) ((JavaBeanDeserializer) derializer).deserialze(this, type, fieldName, 0);
} else {
//在这里执行JavaObjectDeserializer的deserialze方法
return (T) derializer.deserialze(this, type, fieldName);
}
} catch (JSONException e) {
throw e;
} catch (Throwable e) {
throw new JSONException(e.getMessage(), e);
}
} 进入到JavaObjectDeserializer反序列化器,发现并没有满足条件,又执行了DefaultJSONParser的parse方法:
public class JavaObjectDeserializer implements ObjectDeserializer {
public final static JavaObjectDeserializer instance = new JavaObjectDeserializer();
@SuppressWarnings("unchecked")
public T deserialze(DefaultJSONParser parser, Type type, Object fieldName) {
if (type instanceof GenericArrayType) {
。。。
}
if (type instanceof Class
&& type != Object.class
&& type != Serializable.class
&& type != Cloneable.class
&& type != Closeable.class
&& type != Comparable.class) {
return (T) parser.parseObject(type);
}
//直接进入到 的parse方法。
return (T) parser.parse(fieldName);
}
public int getFastMatchToken() {
return JSONToken.LBRACE;
}
} 看一下parse方法:
//text: {"gmtModified":new Date(1562601600000),"@type":"test.WeiTest","gmtCreate":new Date(1562601600000)}
public Object parse(Object fieldName) {
final JSONLexer lexer = this.lexer;
switch (lexer.token()) {
//。。。
case LBRACE:
//第一次检测到“{”,判断是一个对象类型,所以生成一个JSONObject对象,这里会有一个检测的步骤,判断传进来的feature是否有Feature.OrderedField特征值,生成有序JSONObject
//然后执行parseObject方法
JSONObject object = new JSONObject(lexer.isEnabled(Feature.OrderedField));
return parseObject(object, fieldName);
// case LBRACE: {
// Map map = lexer.isEnabled(Feature.OrderedField)
// ? new LinkedHashMap()
// : new HashMap();
// Object obj = parseObject(map, fieldName);
// if (obj != map) {
// return obj;
// }
// return new JSONObject(map);
// }
//。。。
case NEW:
//第二次检测到NEW这个token,这个是专门处理时间的token。
//nextToken验证参数token和当前字符ch的关系,并赋值给lexer的token
lexer.nextToken(JSONToken.IDENTIFIER);
//如果token没有赋值成功,不是要求的IDENTIFIER,直接抛异常
if (lexer.token() != JSONToken.IDENTIFIER) {
throw new JSONException("syntax error");
}
lexer.nextToken(JSONToken.LPAREN);
//accept中会有一个lexer.nextToken()操作,此操作会根据当前的字符ch,向后扫描得到一个token。
accept(JSONToken.LPAREN);
long time = lexer.integerValue().longValue();
//验证整型数
accept(JSONToken.LITERAL_INT);
//验证“)”
accept(JSONToken.RPAREN);
//做完上面那一步,token已经变成了","
return new Date(time);
。。。
}
} np是当前的起始位置,sp是当前扫描到的长度。
第一次检测跟进到parseObject方法:
public final Object parseObject(final Map object, Object fieldName) {
final JSONLexer lexer = this.lexer;
if (lexer.token() == JSONToken.NULL) {
lexer.nextToken();
return null;
}
if (lexer.token() == JSONToken.RBRACE) {
lexer.nextToken();
return object;
}
if (lexer.token() == JSONToken.LITERAL_STRING && lexer.stringVal().length() == 0) {
lexer.nextToken();
return object;
}
if (lexer.token() != JSONToken.LBRACE && lexer.token() != JSONToken.COMMA) {
throw new JSONException("syntax error, expect {, actual " + lexer.tokenName() + ", " + lexer.info());
}
ParseContext context = this.context;
try {
Map map = object instanceof JSONObject ? ((JSONObject) object).getInnerMap() : object;
boolean setContextFlag = false;
//每一次循环都会把key和value扫描出来。
for (;;) {
。。。
boolean isObjectKey = false;
Object key;
//对于Object对象来说,遇到 '"'双引号,意味着一个新的KV对开始解析。
if (ch == '"') {
key = lexer.scanSymbol(symbolTable, '"');
lexer.skipWhitespace();
ch = lexer.getCurrent();
//如果不是标准的K:V格式嘛,直接抛异常
if (ch != ':') {
throw new JSONException("expect ':' at " + lexer.pos() + ", name " + key);
}
}
。。。
//2.第二次的时候,扫描得到的key为“@type”,会进入到此逻辑
if (key == JSON.DEFAULT_TYPE_KEY
&& !lexer.isEnabled(Feature.DisableSpecialKeyDetect)) {
//scanSymbol扫描值,'"'是终止符
//得到配置的type名称,“test.WeiTest”
String typeName = lexer.scanSymbol(symbolTable, '"');
//是否有特征值忽略“@type”
if (lexer.isEnabled(Feature.IgnoreAutoType)) {
continue;
}
//这时候的object类型是JSONObject,所以这时候会调checkAutoType方法
Class clazz = null;
if (object != null
&& object.getClass().getName().equals(typeName)) {
clazz = object.getClass();
} else {
//进入此逻辑,根据“test.WeiTest”去找对应的类
clazz = config.checkAutoType(typeName, null, lexer.getFeatures());
}
if (clazz == null) {
map.put(JSON.DEFAULT_TYPE_KEY, typeName);
continue;
}
lexer.nextToken(JSONToken.COMMA);
if (lexer.token() == JSONToken.RBRACE) {
//略。。。
}
//走到这,设置resolveStatus的值为TypeNameRedirect,代表type是指定的。
this.setResolveStatus(TypeNameRedirect);
if (this.context != null
&& fieldName != null
&& !(fieldName instanceof Integer)
&& !(this.context.fieldName instanceof Integer)) {
this.popContext();
}
//重点来了,这时候object已经有字段了,会进入逻辑
//并且按照clazz类型返回了一个“test.WeiTest”类实例
if (object.size() > 0) {
Object newObj = TypeUtils.cast(object, clazz, this.config);
this.parseObject(newObj);
return newObj;
}
ObjectDeserializer deserializer = config.getDeserializer(clazz);
Class deserClass = deserializer.getClass();
if (JavaBeanDeserializer.class.isAssignableFrom(deserClass)
&& deserClass != JavaBeanDeserializer.class
&& deserClass != ThrowableDeserializer.class) {
this.setResolveStatus(NONE);
} else if (deserializer instanceof MapDeserializer) {
this.setResolveStatus(NONE);
}
Object obj = deserializer.deserialze(this, clazz, fieldName);
return obj;
}
//1.第一次的时候,对当前字符ch和扫描出来的key做判断
//最终进入到最后的逻辑
。。。
else {
lexer.nextToken();
//在这部分又调用上方的parse方法,参数fieldName为null。此时的token是NEW。
value = parse();
//扫描第一个字段“ gmtModified”已经完成,返回一个Date类型,并放到map中
map.put(key, value);
if (lexer.token() == JSONToken.RBRACE) {
lexer.nextToken();
return object;
} else if (lexer.token() == JSONToken.COMMA) {
continue;
} else {
throw new JSONException("syntax error, position at " + lexer.pos() + ", name " + key);
}
}
。。。
}
}finally {
this.setContext(context);
}
}跟进去看一下TypeUtils的cast方法:
public static T cast(Object obj, Class clazz, ParserConfig config){
。。。
//到这里的时候,obj的类型是JSONObject,因为JSONObject继承了Map接口,所以进入此逻辑
if(obj instanceof Map){
//clazz的类型是"test.WeiTest",所以跳过此逻辑
if(clazz == Map.class){
return (T) obj;
}
Map map = (Map) obj;
if(clazz == Object.class && !map.containsKey(JSON.DEFAULT_TYPE_KEY)){
return (T) obj;
}
//进入此逻辑
return castToJavaBean((Map) obj, clazz, config);
}
}
---------------------------------------------------------
public static T castToJavaBean(Map map, Class clazz, ParserConfig config){
//根据clazz的类型做判断
。。。
//到最后的逻辑
JavaBeanDeserializer javaBeanDeser = null;
ObjectDeserializer deserizer = config.getDeserializer(clazz);
if (deserizer instanceof JavaBeanDeserializer) {
javaBeanDeser = (JavaBeanDeserializer) deserizer;
}
if(javaBeanDeser == null){
throw new JSONException("can not get javaBeanDeserializer. " + clazz.getName());
}
//返回了类实例
return (T) javaBeanDeser.createInstance(map, config);
}
---------------------------------------------------------
public ObjectDeserializer getDeserializer (Type type){
ObjectDeserializer derializer = this.deserializers.get(type);
if (derializer != null) {
return derializer;
}
//进入此逻辑
if (type instanceof Class) {
return getDeserializer((Class)type, type);
}
。。。。
}
---------------------------------------------------------
public ObjectDeserializer getDeserializer(Class clazz, Type type) {
//前面的操作都没有拿到deserializer,直到
else{
//asm框架造了一个derializer
derializer = createJavaBeanDeserializer(clazz, type);
}
//放到缓存deserializers里,下次就可以从本地缓存中读取。
putDeserializer(type, derializer);
return derializer;
}
---------------------------------------------------------
//通常自定义的bean反序列化会走到这
public ObjectDeserializer createJavaBeanDeserializer(Class clazz, Type type) {
。。。
JavaBeanInfo beanInfo = JavaBeanInfo.build(clazz, type, propertyNamingStrategy);
try {
//上面一堆判断asmEnable
if (!asmEnable) {
return new JavaBeanDeserializer(this, clazz, type);
}
//走到这,采用asm框架的类加载器加载反序列化类。
return asmFactory.createJavaBeanDeserializer(this, beanInfo);
// } catch (VerifyError e) {
// e.printStackTrace();
// return new JavaBeanDeserializer(this, clazz, type);
} catch (NoSuchMethodException ex) {
return new JavaBeanDeserializer(this, clazz, type);
} catch (JSONException asmError) {
return new JavaBeanDeserializer(this, beanInfo);
} catch (Exception e) {
throw new JSONException("create asm deserializer error, " + clazz.getName(), e);
}
} //parseObject方法,参数是一个对象实体
//到这个逻辑的时候,意味着解析'@type'成功,开始按照一个JavaBean的属性去解析json字符串了。
public void parseObject(Object object) {
Class clazz = object.getClass();
JavaBeanDeserializer beanDeser = null;
//这一步再根据clazz去拿反序列化器的时候,从缓存中可以直接获得
ObjectDeserializer deserizer = config.getDeserializer(clazz);
if (deserizer instanceof JavaBeanDeserializer) {
beanDeser = (JavaBeanDeserializer) deserizer;
}
if (lexer.token() != JSONToken.LBRACE && lexer.token() != JSONToken.COMMA) {
throw new JSONException("syntax error, expect {, actual " + lexer.tokenName());
}
for (;;) {
// lexer.scanSymbol
//再往下解析,此时扫描得到的key是“gmtCreate”
String key = lexer.scanSymbol(symbolTable);
//跳过此逻辑
if (key == null) {
。。。
}
//得到FieldDeserializer,对每个字段进行解析,见图1,fieldDeser包含了对每个字段的解析属性。
FieldDeserializer fieldDeser = null;
if (beanDeser != null) {
//用sortedFieldDeserializers二分查找,提升查找速度,当javaBean的字段很多时,优化的效果很明显。
fieldDeser = beanDeser.getFieldDeserializer(key);
}
if (fieldDeser == null) {
。。。
} else {
//得到当前字段的类型
Class fieldClass = fieldDeser.fieldInfo.fieldClass;
Type fieldType = fieldDeser.fieldInfo.fieldType;
Object fieldValue;
if (fieldClass == int.class) {
lexer.nextTokenWithColon(JSONToken.LITERAL_INT);
fieldValue = IntegerCodec.instance.deserialze(this, fieldType, null);
} else if (fieldClass == String.class) {
。。。
} else if (fieldClass == long.class) {
。。。
} else {
//根据字段的类型得到对应的反序列化器
ObjectDeserializer fieldValueDeserializer = config.getDeserializer(fieldClass, fieldType);
lexer.nextTokenWithColon(fieldValueDeserializer.getFastMatchToken());
// 根据“test.WeiTest”类得到的‘gmtCreate’的fieldType是‘java.util.Date’类型。看到这里,应该有同学猜到是咋回事了。别急,接着往下看
//这步是反序列化的过程,Date类型的反序列化器是SqlDateDeserializer
fieldValue = fieldValueDeserializer.deserialze(this, fieldType, null);
}
fieldDeser.setValue(object, fieldValue);
}
if (lexer.token() == JSONToken.COMMA) {
continue;
}
if (lexer.token() == JSONToken.RBRACE) {
lexer.nextToken(JSONToken.COMMA);
return;
}
}
}图一:fieldDeserializer
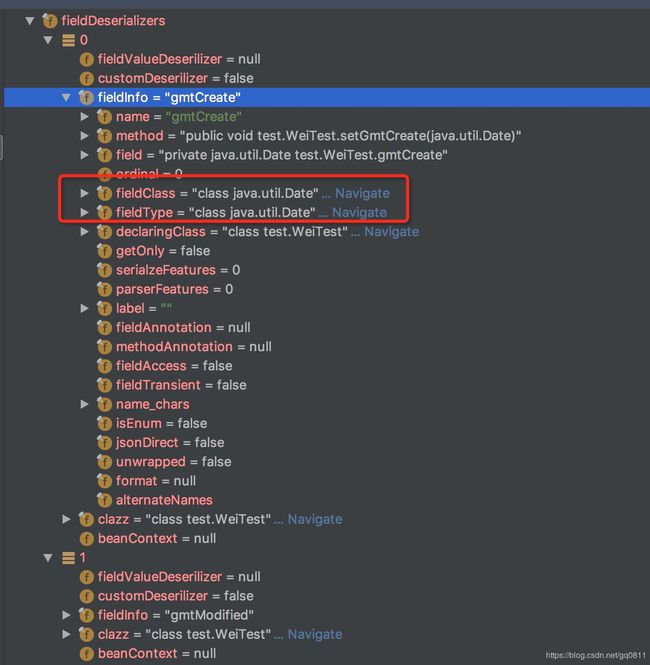
根据“test.WeiTest”类得到的‘gmtCreate’的fieldType是‘java.util.Date’类型。看到这里,应该有同学猜到是咋回事了。别急,接着往下看,Date类型的反序列化器是SqlDateDeserializer:
public class SqlDateDeserializer extends AbstractDateDeserializer implements ObjectDeserializer {
。。。
}deserialze方法在AbstractDateDeserializer中:
public T deserialze(DefaultJSONParser parser, Type clazz, Object fieldName, String format, int features) {
JSONLexer lexer = parser.lexer;
//此时扫描得到的token是JSONToken.NEW
Object val;
if (lexer.token() == JSONToken.LITERAL_INT) {
//
} else if (lexer.token() == JSONToken.LITERAL_STRING) {
//
} else if (lexer.token() == JSONToken.NULL) {
//
} else if (lexer.token() == JSONToken.LBRACE) {
//
} else if (parser.getResolveStatus() == DefaultJSONParser.TypeNameRedirect) {
//最后进入此逻辑
parser.setResolveStatus(DefaultJSONParser.NONE);
//在此步骤抛出异常。预期的token是JSONToken.COMMA,而实际的JSONToken.NEW。
parser.accept(JSONToken.COMMA);
。。。
} else {
val = parser.parse();
}
return (T) cast(parser, clazz, fieldName, val);
} 在parseObject(final Map object, Object fieldName)方法里,已经设置了resolveStatus为TypeNameRedirect。然后在parser.accept时抛出异常。
此时终于“真相大白”了,传进去的日期字段gmtCreate的值序列化的结果是“new Date(1562601600000)}”。在解析了“@type”类型之后,按照指定的类得到类的实例和每个字段的反序列化器。然后用Date的反序列化器去解析“new Date(1562601600000)}”的时候解析失败。
正常情况下,如果直接用javabean的序列化方式,序列化得到的日期格式为一个Long型的时间戳,这样解析是没问题的。
复盘
1.首先解释现象:
Q1:为什么去掉其中一个就成功了?
A1:因为序列化得到的jsonStr是“{"gmtModified":new Date(1562601600000),"@type":"test.WeiTest"}”,当解析到“@type”的时候,后续已经没有KV对了,这时候就正常结束了。
------------------------------------------------
Q2:为什么修改其中一个属性名称就成功了?
A2:因为序列化得到的jsonStr是"{"@type":"test.WeiTest","gmtCreate1":new Date(1562601600000),"gmtCreate":new Date(1562601600000)}",在下parseObject(final Map object, Object fieldName)的逻辑中,走了另外一个逻辑:
if (object.size() > 0) {
Object newObj = TypeUtils.cast(object, clazz, this.config);
this.parseObject(newObj);
return newObj;
}
//object.size为0时走此逻辑。
ObjectDeserializer deserializer = config.getDeserializer(clazz);
Class deserClass = deserializer.getClass();
if (JavaBeanDeserializer.class.isAssignableFrom(deserClass)
&& deserClass != JavaBeanDeserializer.class
&& deserClass != ThrowableDeserializer.class) {
this.setResolveStatus(NONE);
} else if (deserializer instanceof MapDeserializer) {
this.setResolveStatus(NONE);
}
Object obj = deserializer.deserialze(this, clazz, fieldName);
return obj;此时的deserClass是class com.alibaba.fastjson.parser.deserializer.FastjsonASMDeserializer_1_WeiTest,是用asm框架创建的反序列化器,JavaBeanDeserializer的子类。而这个序列化器是走JavaBeanDeserializer的deserialize方法的,每次都会识别NEW这个token,分别对gmtCreate和gmtCreate1字段做了解析。从而返回正确结果。
所以说,关键点是序列化得到的结果,巧妙的触发了不同的逻辑。
(至于为什么会有这样的序列化结果,可以参考的我的另一片文章,看一下map的序列化逻辑。https://blog.csdn.net/gq0811/article/details/93412102)
2.对fastJson的逻辑严谨性表达敬意,对词法分析器的设计表达敬佩。一些算法的优化点很值得学习和研究。
3.Actually,我并不知道这个算不算“bug”,毕竟这种用法也比较少见。但是我想,在JavaBeanDeserializer中严格的按照分析逻辑解析了“NEW”这个token,说明fastJSON的反序列化是支持“NEW”这种格式。这里提议是否在日期的反序列化器中,也就是是在AbstractDateDeserializer的deserialze方法中,支持对“NEW”这个token的解析呢?
附:
解决办法:
1.LinkedHashMap保证序列化时key的顺序
Map map = new LinkedHashMap(16);
map.put("@type", "test.WeiTest");
map.put("gmtCreate", date);
map.put("gmtModified", date);"@type"在最前面就可以保证解析流程的往下进行。
2.重新定义一个DateObjectSerializer,对时间类型做处理,把时间转化为long类型,而不是new Date的形式:
class DateObjectSerializer implements ObjectSerializer{
@Override
public void write(JSONSerializer serializer, Object object, Object fieldName, Type fieldType, int features) throws
IOException {
SerializeWriter out = serializer.out;
if (object == null) {
out.writeNull();
return;
}
Date date;
if (object instanceof Date) {
date = (Date) object;
} else {
date = TypeUtils.castToDate(object);
}
if (out.isEnabled(SerializerFeature.WriteClassName)) {
if (object.getClass() != fieldType) {
if (object.getClass() == java.util.Date.class) {
out.writeLong(((Date) object).getTime());
} else {
out.write('{');
out.writeFieldName(JSON.DEFAULT_TYPE_KEY);
serializer.write(object.getClass().getName());
out.writeFieldValue(',', "val", ((Date) object).getTime());
out.write('}');
}
return;
}
}
long time = date.getTime();
out.writeLong(time);
}
}然后在序列化的时候,
SerializeConfig mapping = new SerializeConfig();
mapping.put(Date.class, new DateObjectSerializer());
...
//定义好一个SerializeConfig后,放到参数里
String jsonStr = JSON.toJSONString(map,mapping, SerializerFeature.WriteClassName);也可以解决此问题。