02:API的理解和使用
02:API的理解和使用
文章目录
- 02:API的理解和使用
- 1、预备内容:
- 1.1 预备知识
- 1.2 了解学习redis主要体现在两个方面:
- 1.3 重点
- 1.4 全局命令
- 1.4.1 查看所有key
- 1.4.2键总数
- 1.4.3检查键是否存在
- 1.4.4删除键
- 1.4.5键过期
- 1.4.6建的数据结构类型
- 2、数据结构
- 2.1 字符串
- 2.1.1 常用命令
- 2.1.2 批量操作性能对比
- 2.1.3 计数
- 2.1.5 其他命令
- 2.1.4 使用场景
- 2.2 哈希
- 2.2.1 常用命令
- 2.2.2 使用场景
- 2.3 列表
- 2.3.1 常用命令
- 2.3.2 阻塞操作
- 2.3.3 使用场景
- 2.4 集合
- 2.4.1 命令
- 2.4.2 使用场景
- 2.5 有序集合
- 2.5.1 命令
- 2.5.2 使用场景
- 2.6 键管理
- 2.6.1 单个键管理
- 2.6.2 遍历键
- 2.6.3 数据库管理
1、预备内容:
1.1 预备知识
- 几个简单全局命令、数据结构、内部编码、单线程命令处理机制分析。
- 五种数据结构的特点、命令使用、应用场景。
- 键管理、遍历键、数据库管理。
- redis_version:3.2.8
1.2 了解学习redis主要体现在两个方面:
- 第一、Redis的命令有上百个,如果纯靠死记硬背比较困难,但是如果理解Redis的一些机制,会发现 这些命令有很强的通用性。
- 第二、Redis不是万金油,有些数据结构和命令 必须在特定场景下使用,一旦使用不当可能对Redis本身或者应用本身造成 致命伤害。
1.3 重点
- 1)Redis提供5种数据结构,每种数据结构都有多种内部编码实现。
- 2)纯内存存储、IO多路复用技术、单线程架构是造就Redis高性能的三 个因素。
- 3)由于Redis的单线程架构,所以需要每个命令能被快速执行完,否则 会存在阻塞Redis的可能,理解Redis单线程命令处理机制是开发和运维Redis 的核心之一。
- 4)批量操作(例如mget、mset、hmset等)能够有效提高命令执行的效 率,但要注意每次批量操作的个数和字节数。
- 5)了解每个命令的时间复杂度在开发中至关重要,例如在使用keys、 hgetall、smembers、zrange等时间复杂度较高的命令时,需要考虑数据规模 对于Redis的影响。
- 6)persist命令可以删除任意类型键的过期时间,但是set命令也会删除 字符串类型键的过期时间,这在开发时容易被忽视。
- 7)move、dump restore、migrate是Redis发展过程中三种迁移键的方 式,其中move命令基本废弃,migrate命令用原子性的方式实现了 dump restore,并且支持批量操作,是Redis Cluster实现水平扩容的重要工 具。
- 8)scan命令可以解决keys命令可能带来的阻塞问题,同时Redis还提供了hscan、sscan、zscan渐进式地遍历hash、set、zset。
1.4 全局命令
1.4.1 查看所有key
192.168.49.171:6392> mset baobao xiaomidou bieming1 xiaopijiu bieming2 tuoyouping bieming3 xiaolaoye --批量插入四对字符串类型键值
OK
192.168.49.171:6392> keys * --查看所有键
1) "bieming1"
2) "baobao"
3) "bieming3"
4) "bieming2"
192.168.49.171:6392> dbsize --键总数
(integer) 4
192.168.49.171:6392> get baobao
"xiaomidou"
192.168.49.171:6392> get bieming2
"tuoyouping"
192.168.49.171:6392>
- dbsize和 keys * 的区别:
dbsize是直接获取Redis内置的键总数变量,所以dbsize命令的时间复杂度是O(1)。而keys命令会遍历所有键,所以它的时间复杂度是O(n),当Redis保存了大量键时,线上环境禁止使用。
1.4.2键总数
192.168.49.171:6392> rpush wenju dianzigo che qiu mofeng --添加玩具列表
(integer) 4
192.168.49.171:6392> lrange wenju 0 -1
1) "dianzigo"
2) "che"
3) "qiu"
4) "mofeng"
192.168.49.171:6392> dbsize --redis内置键总数 1,列表是一个键
(integer) 5
192.168.49.171:6392>
1.4.3检查键是否存在
192.168.49.171:6392> exists baobao 键存返回1
(integer) 1
192.168.49.171:6392> exists not_exists 键存不存在则返回0
(integer) 0
192.168.49.171:6392>
1.4.4删除键
del是一个通用命令,无论值是什么数据结构类型,del命令都可以将其 删除,例如下面将字符串类型的键bieming3和列表类型的键wenju分别删除
192.168.49.171:6392> keys *
1) "bieming3"
2) "baobao"
3) "bieming1"
4) "wenju"
5) "bieming2"
192.168.49.171:6392> del wenju --删除存在返回1
(integer) 1
192.168.49.171:6392> del beming3 --删除不存在则返回0
(integer) 0
192.168.49.171:6392> del bieming3
(integer) 1
192.168.49.171:6392> keys *
1) "baobao"
2) "bieming1"
3) "bieming2"
192.168.49.171:6392> del bieming1 bieming2 --时del命令可以支持删除多个键
(integer) 2
192.168.49.171:6392> keys *
1) "baobao"
192.168.49.171:6392>
1.4.5键过期
redis支持对键添加过期时间,当过期会自动删除
192.168.49.171:6392> set midoubaobao taipile
OK
192.168.49.171:6392> EXPIRE midoubaobao 10 --设置10秒超时
(integer) 1
192.168.49.171:6392> ttl midoubaobao --ttl返回键的剩余时间7秒
(integer) 7
192.168.49.171:6392> ttl midoubaobao
(integer) 6
192.168.49.171:6392> ttl midoubaobao
(integer) 5
192.168.49.171:6392> ttl midoubaobao
(integer) 5
192.168.49.171:6392> ttl midoubaobao --表示已被删除
(integer) -2
- ttl命令有3种返回值
- 大于等于0的整数,表示剩余的过期时间
- -1 表示键没有设置过期时间
- -2 表示键不存在
- 特别注意
- 过期时间是以对象为单位,例如一个hash结构的过期桑整个hash对象过期,而不是某个子key过期
- 如果一个字符串已经设置了过期时间,然后你调用DEL命令或者SET命令或者GETSET方法修改它,它的过期时间会消失
1.4.6建的数据结构类型
- type key 获取键的类型
192.168.49.171:6392> keys *
1) "baobao"
192.168.49.171:6392> rpush midou_list dianzigo che qiu mofeng
(integer) 4
192.168.49.171:6392> type baobao
string --返回字符串类型
192.168.49.171:6392> type midou_list
list --返回列表类型
192.168.49.171:6392> type midoubaobao
none --不存在则返回none
192.168.49.171:6392>
2、数据结构
- Redis 5种基础数据结构分别为:
- string (字符串)
- list (列表)
- hash (字典)
- set (集合)
- zset 有序集合
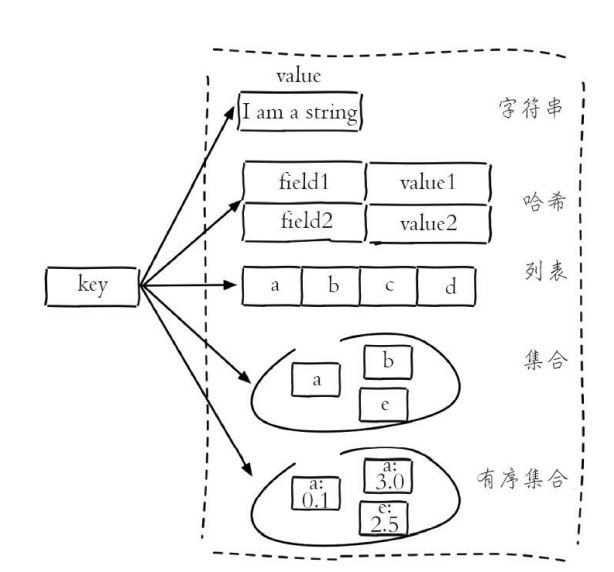
2.1 字符串
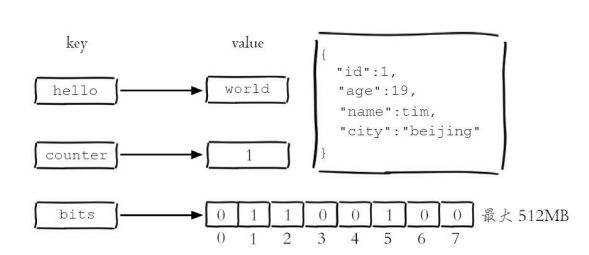
字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能 超过512MB。
语法:set key value [EX seconds] [PX milliseconds] [NX|XX]
- set命令有几个选项:
- ex seconds:为键设置秒级过期时间。
- px milliseconds:为键设置毫秒级过期时间。
- nx:键必须不存在,才可以设置成功,用于添加。
- xx:与nx相反,键必须存在,才可以设置成功,用于更新。
- 除了set选项,Redis还提供了setex和setnx两个命令
2.1.1 常用命令
192.168.49.171:6392> EXISTS hello
(integer) 0
192.168.49.171:6392> set hello xiaomidou
OK
192.168.49.171:6392> setnx hello xiaomidou --因为键hello已存在,所以setnx失败,返回结果为0
(integer) 0
192.168.49.171:6392> set hello jedis xx --因为键hello已存在,所以set xx成功,返回结果为OK
OK
192.168.49.171:6392> get hello
"jedis"
192.168.49.171:6392> mset a 1 b 2 c 3 d 4 e 5 --批量设置值
OK
192.168.49.171:6392> mget a b c d e --批量获取值
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
192.168.49.171:6392> mget a e f e
1) "1"
2) "5"
3) (nil) --如果要获取的键不存在,则返回nil(空)
4) "5"
192.168.49.171:6392>
2.1.2 批量操作性能对比
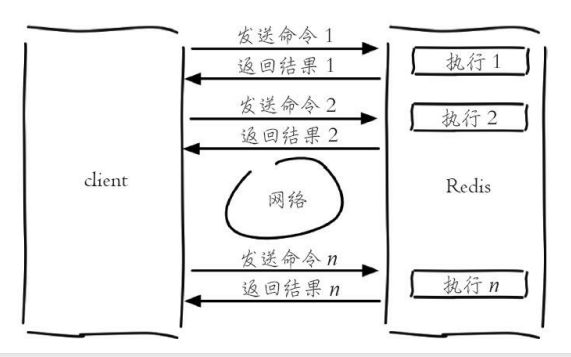
批量操作命令可以有效提高开发效率,假如没有mget这样的命令,要执行n次get命令需要按照下图的方式来执行,具体耗时如下:
n次get时间 = n次网络时间 n次命令时间
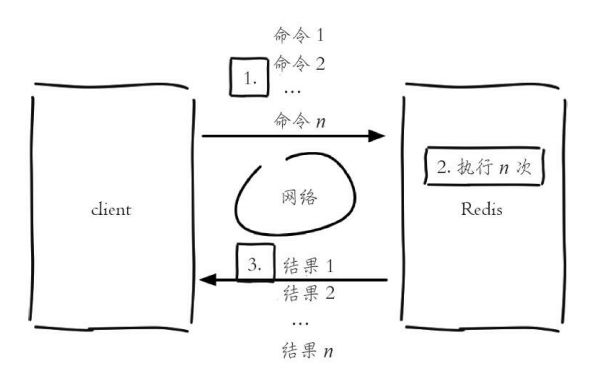
使用mget命令后,要执行n次get命令操作只需要按照下图的方式来执行,具体耗时如下:
n次get时间 = 1次网络时间 n次命令时间
假设网络 时间为1毫秒,命令时间为0.1毫秒(按照每秒处理1万条命令算)
1000次get和1次get对比表
2.1.3 计数
除了incr命令,Redis提供了decr(自减)、incrby(自增指定数字)、 decrby(自减指定数字)、incrbyfloat(自增浮点数)
incr对值做自增,返回结果分为三种情况,值不是整数返回错误,值是整数,返回自增后的结果,键不存在按照值为0自增,返回结果为1
192.168.49.171:6392> incr dianji
(integer) 1
192.168.49.171:6392> exists dianji
(integer) 1
192.168.49.171:6392> incr dianji --返回结果为2
(integer) 2
192.168.49.171:6392> incr dianji --返回结果为3
(integer) 3
192.168.49.171:6392> incr dianji
(integer) 4
192.168.49.171:6392> incr dianji --返回结果为5
(integer) 5
192.168.49.171:6392> set db redis
OK
192.168.49.171:6392> type db
string
192.168.49.171:6392> decr dianji --自减返回结果为4
(integer) 4
192.168.49.171:6392> decr dianji --自减返回结果为3
(integer) 3
192.168.49.171:6392> set mykey "100" --自增指定数字
OK
192.168.49.171:6392> incrby mykey 1 --自增100 1
(integer) 101
192.168.49.171:6392> incrby mykey 2
(integer) 103
192.168.49.171:6392> incrby mykey 2
(integer) 105
192.168.49.171:6392> set decrkey 100 --自减指定数字
OK
192.168.49.171:6392> decrby decrkey 5 --自减5
(integer) 95
192.168.49.171:6392> decrby decrkey 10
(integer) 85
192.168.49.171:6392> set incrfloat 11.23 --自增浮点数
OK
192.168.49.171:6392> INCRBYFLOAT incrfloat 0.1 --自增浮点数0.1
"11.33"
192.168.49.171:6392> INCRBYFLOAT incrfloat 0.2 --自增浮点数0.2
"11.53"
192.168.49.171:6392>
2.1.5 其他命令
192.168.49.171:6392> get baobao
"xiaomidou"
192.168.49.171:6392> append baobao shihuaidan --后面追加shihuaidan
(integer) 19
192.168.49.171:6392> get baobao
"xiaomidoushihuaidan"
192.168.49.171:6392> strlen baobao --获取字符长度
(integer) 19
192.168.49.171:6392> set midou "貔貅" --设置中文
OK
192.168.49.171:6392> get midou
"\xe8\xb2\x94\xe8\xb2\x85"
192.168.49.171:6392> strlen midou
(integer) 6 --一个中文3个字符
192.168.49.171:6392> get hello
"jedis"
192.168.49.171:6392> getset hello world --getset和set一样会设置值,但是不同的是,它同时会返回键原来的值
"jedis"
192.168.49.171:6392> get hello
"world"
192.168.49.171:6392> get baobao
"xiaomidoushihuaidan"
192.168.49.171:6392> setrange baobao 0 j --设置第一个字母为j
(integer) 19
192.168.49.171:6392> get baobao
"jiaomidoushihuaidan"
192.168.49.171:6392> getrange baobao 1 4 --获取位置1~4部分字符串
"iaom"
192.168.49.171:6392>
- 字符串类型命令的时间复杂度
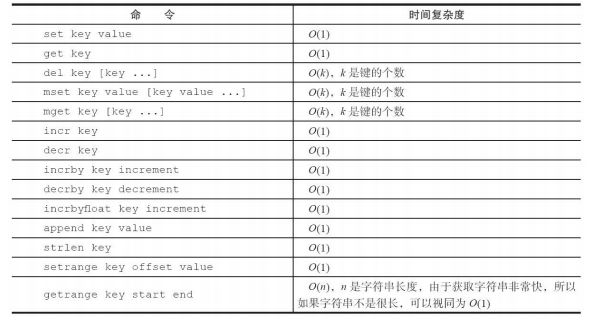
2.1.4 使用场景
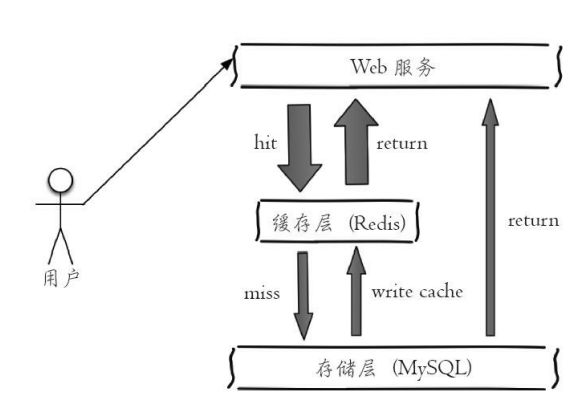
- 缓存功能
比较典型的缓存使用场景,其中Redis作为缓存层,MySQL作 为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高 并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
- 计数
许多应用都会使用Redis作为计数的基础工具,它可以实现快速计数、 查询缓存的功能,同时数据可以异步落地到其他数据源。搜狐的视频播放数系统就是使用Redis作为视频播放数计数的基础组件,用户每播放一次视频,相应的视频播放数就会自增1
- 共享Session
一个分布式Web服务将用户的Session信息(例如用户登 录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可 能会发现需要重新登录,这个问题是用户无法容忍的。
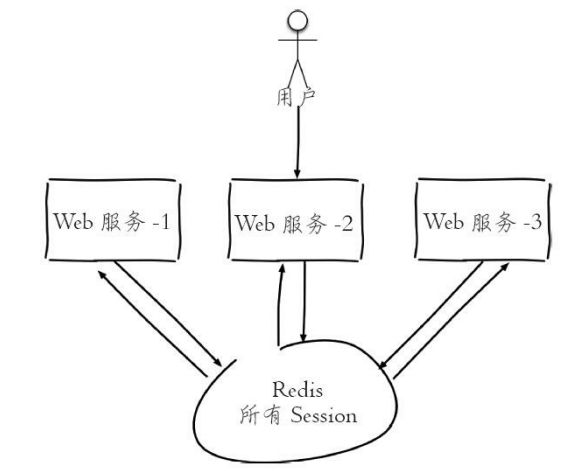
为了解决这个问题,可以使用Redis将用户的Session进行集中管理,下图所示,在这种模式下只要保证Redis是高可用和扩展性的,每次用户 更新或者查询登录信息都直接从Redis中集中获取。
- 限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用 户每分钟获取验证码的频率,例如一分钟不能超过5次,如图短信验证码限速
利用Redis实现了限速功能,例如一些网站限制一个IP地址不 能在一秒钟之内访问超过n次也可以采用类似的思路
2.2 哈希
在Redis中,哈希类型是指键值本身又是一个键值对 结构,形如value={{field1,value1},…{fieldN,valueN}},Redis键值对和 哈希类型二者的关系可以用下图来表示:
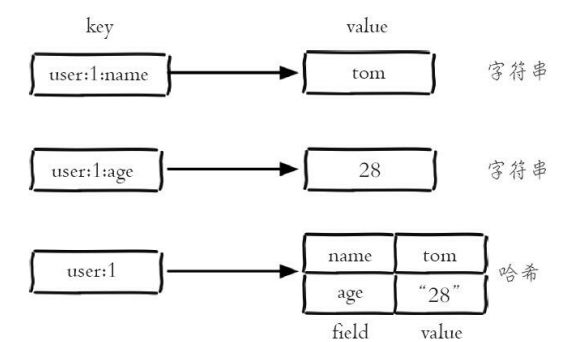
哈希类型中的映射关系叫作field-value,注意这里的value是指field对应 的值,不是键对应的值
2.2.1 常用命令
192.168.49.171:6392> hset xiaomidou age 1 --设置值
(integer) 1
192.168.49.171:6392> hget xiaomidou age --获取值
"1"
192.168.49.171:6392> hset xiaomidou birthday 20190210
(integer) 1
192.168.49.171:6392> hset xiaomidou nick_name "tuoyouping"
(integer) 0
192.168.49.171:6392> hexists xiaomidou address --判断值是否存在
(integer) 0
192.168.49.171:6392> hdel xiaomidou age --删除值,存在返回1
(integer) 1
192.168.49.171:6392> hdel xiaomidou age --删除值,不存在返回0
(integer) 0
192.168.49.171:6392> hlen xiaomidou --计算field个数
(integer) 2
192.168.49.171:6392> hmget xiaomidou birthday nick_name --hmset和hmget分别是批量设置和获取field-value
1) "20190210"
2) "tuoyouping"
192.168.49.171:6392> hmset xiaomidou mobile 15976880000 email [email protected]
OK
192.168.49.171:6392> hkeys xiaomidou --获取所有field
1) "birthday"
2) "nick_name"
3) "mobile"
4) "email"
192.168.49.171:6392> hvals xiaomidou --获取所有value
1) "20190210"
2) "tuoyouping"
3) "15976880000"
4) "[email protected]"
192.168.49.171:6392> hgetall xiaomidou --获取所有的field-value
1) "birthday"
2) "20190210"
3) "nick_name"
4) "tuoyouping"
5) "mobile"
6) "15976880000"
7) "email"
8) "[email protected]"
192.168.49.171:6392> hincrby xiaomidou age 1
(integer) 1
192.168.49.171:6392> hgetall xiaomidou
1) "birthday"
2) "20190210"
3) "nick_name"
4) "tuoyouping"
5) "mobile"
6) "15976880000"
7) "email"
8) "[email protected]"
9) "age"
10) "1"
192.168.49.171:6392> hincrby xiaomidou age 1 --增加 key 指定的哈希集中指定字段的数值
(integer) 2
192.168.49.171:6392> hincrby xiaomidou age 1
(integer) 3
192.168.49.171:6392> hincrby xiaomidou age 1
(integer) 4
192.168.49.171:6392> hincrby xiaomidou age -2
(integer) 2
192.168.49.171:6392> hincrbyfloat xiaomidou ukey 10.50 --为指定key的hash的field字段值执行float类型的increment加
192.168.49.171:6392> hincrbyfloat xiaomidou ukey 0.10
"10.6"
192.168.49.171:6392> hincrbyfloat xiaomidou ukey 0.11
"10.71"
192.168.49.171:6392> hstrlen xiaomidou email --计算value的字符串长度
(integer) 21
192.168.49.171:6392>
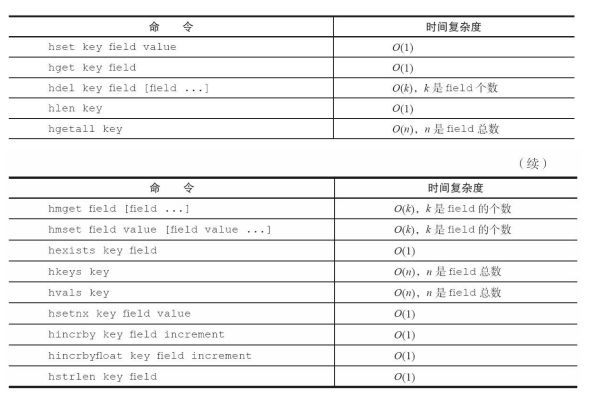
- 哈希类型命令的时间复杂度
2.2.2 使用场景
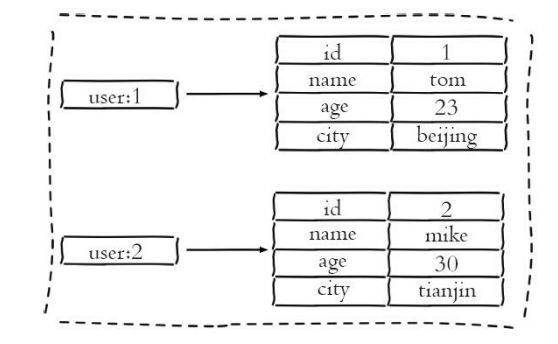
把关系型数据表转成哈希类型存储
关系型数据库表保存用户信息
使用哈希类型缓存用户信息
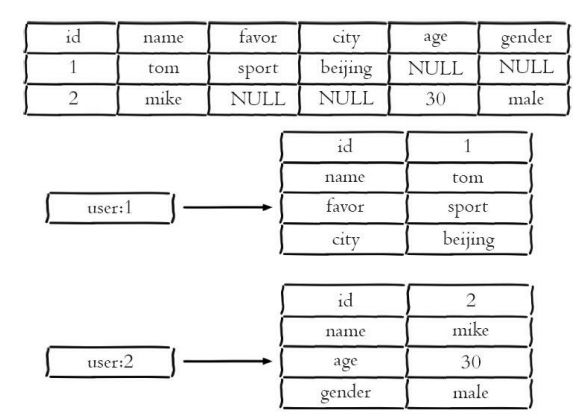
- 注意: 哈希类型和关系型数据库有两点不同之处
- 哈希类型是稀疏的,而关系型数据库是完全结构化的,例如哈希类型 每个键可以有不同的field,而关系型数据库一旦添加新的列,所有行都要为 其设置值(即使为NULL)
- 关系型数据库可以做复杂的关系查询,而Redis去模拟关系型复杂查询 开发困难,维护成本高
-
可以用三种方法缓存用户信息,下面给出三种方案的实现方法和优缺点分析
- 1)原生字符串类型:每个属性一个键。
set user:1:name xiaomidou set user:1:age 1 set user:1:city shenzhen优点:简单直观,每个属性都支持更新操作。 缺点:占用过多的键,内存占用量较大,同时用户信息内聚性比较差, 所以此种方案一般不会在生产环境使用。
- 2)序列化字符串类型:将用户信息序列化后用一个键保存。
set user:1 serialize(userInfo)优点:简化编程,如果合理的使用序列化可以提高内存的使用效率。 缺点:序列化和反序列化有一定的开销,同时每次更新属性都需要把全 部数据取出进行反序列化,更新后再序列化到Redis中。
- 3)哈希类型:每个用户属性使用一对field-value,但是只用一个键保 存。
hmset user:1 name xiaomidou age 1 city shenzhen优点:简单直观,如果使用合理可以减少内存空间的使用。 缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
2.3 列表
- 列表定义
列表(list)类型是用来存储多个有序的字符串
下图所示,a、 b、c、d、e五个元素从左到右组成了一个有序的列表,列表中的每个字符串 称为元素(element),一个列表最多可以存储232-1个元素
列表两端插入和弹出操作
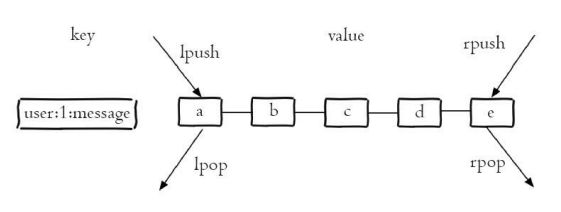
在Redis中,可 以对列表两端插入(push)和弹出(pop);还可以获取指定范围的元素列 表、获取指定索引下标的元素等。
子列表获取、删除等操作
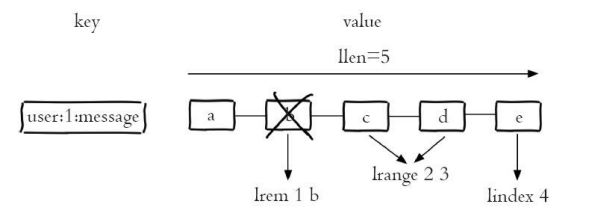
- 列表的特点
- 列表中的元素是有序的
- 列表中的元素可以是重复的
获取上图的第5个元素,可以执行lindex user:1:message4(索引从0算起)就可以得到元素e。
2.3.1 常用命令
列表的5种操作类型
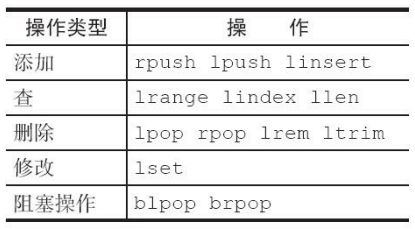
- 增删改查
192.168.49.171:6392> lpush listkey a b c --从左边插入a b c
(integer) 3
192.168.49.171:6392> lrange listkey 0 -1 --lrange操作会获取列表指定索引范围所有的元素
1) "c"
2) "b"
3) "a"
192.168.49.171:6392> rpush listkey d --从右边插入d
(integer) 4
192.168.49.171:6392> lrange listkey 0 -1
1) "c"
2) "b"
3) "a"
4) "d"
192.168.49.171:6392> linsert listkey before b redis --在b之前插入redis
(integer) 5
192.168.49.171:6392> lrange listkey 0 -1
1) "c"
2) "redis"
3) "b"
4) "a"
5) "d"
192.168.49.171:6392> linsert listkey after a jedis --a 之后插入jedis
(integer) 6
192.168.49.171:6392> lrange listkey 0 -1
1) "c"
2) "redis"
3) "b"
4) "a"
5) "jedis"
6) "d"
- lrange操作会获取列表指定索引范围所有的元素
- 第一,索引下标从左到右分别是0到N-1,但是从右到左分别是-1到-N
- 第二,lrange中的end选项包含了自身,这个和很多编程语言不包含end不太相同
192.168.49.171:6392> lrange listkey 2 4 --获取列表的第3到第5个元素
1) "b"
2) "a"
3) "jedis"
192.168.49.171:6392> rpop listkey --从列表右侧弹出元素
"d"
192.168.49.171:6392> lrange listkey 0 -1
1) "c"
2) "redis"
3) "b"
4) "a"
5) "jedis"
192.168.49.171:6392> lpop listkey --从列表左侧弹出元素
"c"
192.168.49.171:6392> lrange listkey 0 -1
1) "redis"
2) "b"
3) "a"
4) "jedis"
- lrem命令(lrem key count value)会从列表中找到等于value的元素进行删除,根据count的不同 分为三种情况:
- count>0,从左到右,删除最多count个元素。
- count<0,从右到左,删除最多count绝对值个元素。
- count=0,删除所有。
192.168.49.171:6392> lpush listkey a a a
(integer) 7
192.168.49.171:6392> lrange listkey 0 -1
1) "a"
2) "a"
3) "a"
4) "redis"
5) "b"
6) "a"
7) "jedis"
192.168.49.171:6392> lrem listkey 2 a --从左到右边,删除2个a
(integer) 2
192.168.49.171:6392> lrange listkey 0 -1
1) "a"
2) "redis"
3) "b"
4) "a"
5) "jedis"
192.168.49.171:6392> ltrim listkey 1 3 --按照索引范围修剪列
OK
192.168.49.171:6392> lrange listkey 0 -1
1) "redis"
2) "b"
3) "a"
192.168.49.171:6392> lset listkey 0 python --将列表listkey中的第1个元素设置为python
OK
192.168.49.171:6392> lrange listkey 0 -1
1) "python"
2) "b"
3) "a"
阻塞操作
192.168.49.171:6392>
2.3.2 阻塞操作
- blpop和brpop是lpop和rpop的阻塞版本,它们除了弹出方向不同,使用 方法基本相同,所以下面以brpop命令进行说明,brpop命令包含两个参数:
- key[key…]:多个列表的键。
- timeout:阻塞时间(单位:秒)。
--客户端A
192.168.49.171:6392> brpop list:test 3 --列表为空:如果timeout=3,那么客户端要等到3秒后返回,如果 timeout=0,那么客户端一直阻塞等下去
(nil)
(3.03s)
192.168.49.171:6392> brpop list:test 0
--客户端B
[root@manager01 ~]# redis-cli -h 192.168.49.171 -p 6392 -- 如果此期间客户端B添加了数据element1,客户端A立即返回
192.168.49.171:6392> lpush list:test ttest1
(integer) 1
192.168.49.171:6392>
--客户端A
192.168.49.171:6392> brpop list:test 0
1) "list:test"
2) "ttest1"
(32.87s)
192.168.49.171:6392>
192.168.49.171:6392> brpop listkey 0 --列表不为空:客户端会立即返回
1) "listkey"
2) "a"
192.168.49.171:6392>
-
在使用brpop时,有两点需要注意。
- 第一点,如果是多个键,那么brpop会从左至右遍历键,一旦有一个键能弹出元素,客户端立即返回
- 第二点,如果多个客户端对同一个键执行brpop,那么最先执行brpop命 令的客户端可以获取到弹出的值
-
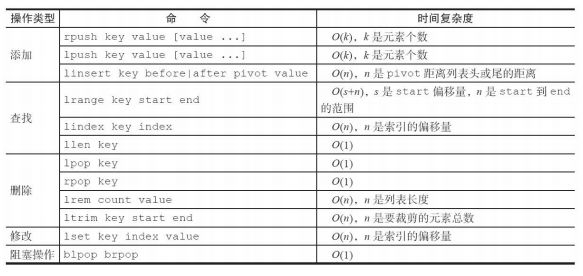
列表命令时间复杂度
2.3.3 使用场景
- 消息队列
Redis的lpush brpop命令组合即可实现阻塞队列,生产者客户端使用lrpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的“抢”列表尾部的元素,多个客户端保证了消费的负载均衡和高可用 性。
Redis消息队列模型
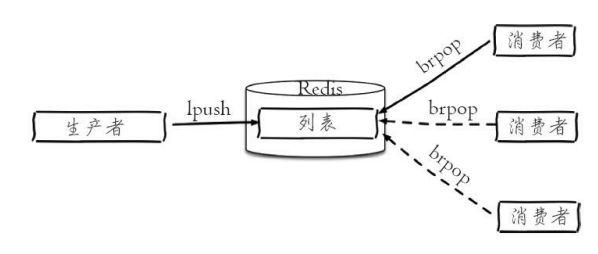
- 列表使用场景很多,在选择时可以参考以下口诀:
- lpush lpop=Stack(栈)
- lpush rpop=Queue(队列)
- lpsh ltrim=Capped Collection(有限集合)
- lpush brpop=Message Queue(消息队列)
2.4 集合
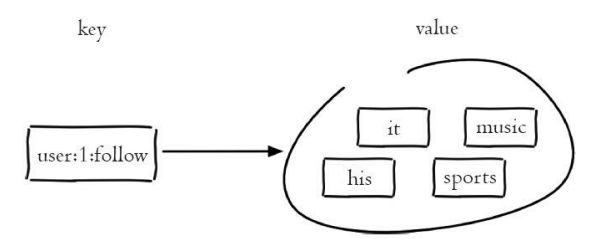
集合(set)类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素,并且集合中的元素是无序的,不能通过索引下标获取元素
Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并 集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题
2.4.1 命令
- 集合内操作
192.168.49.171:6392> sadd assemble mysql redis tidb oracle mongodb --往集合中添加5个元素(mysql redis tidb oracle mongodb)
(integer) 5
192.168.49.171:6392> srem assemble mysql --删除元素mysql
(integer) 1
192.168.49.171:6392> smembers assemble --获取所有元素
1) "redis"
2) "oracle"
3) "tidb"
4) "mongodb"
192.168.49.171:6392> scard assemble --计算元素个数
(integer) 4
192.168.49.171:6392> sismember assemble mysql --判断mysql是否在集合中,在集合内返回1,反之返回0
(integer) 0
192.168.49.171:6392> srandmember assemble 2 --随机从集合返回2个元素
1) "mongodb"
2) "redis"
192.168.49.171:6392> srandmember assemble 2 --随机从集合返回2个元素
1) "redis"
2) "oracle"
192.168.49.171:6392> spop assemble 1 --从集合随机弹出1个元素
1) "tidb"
192.168.49.171:6392> spop assemble 1 --从集合随机弹出1个元素
1) "redis"
192.168.49.171:6392>
- 集合间操作
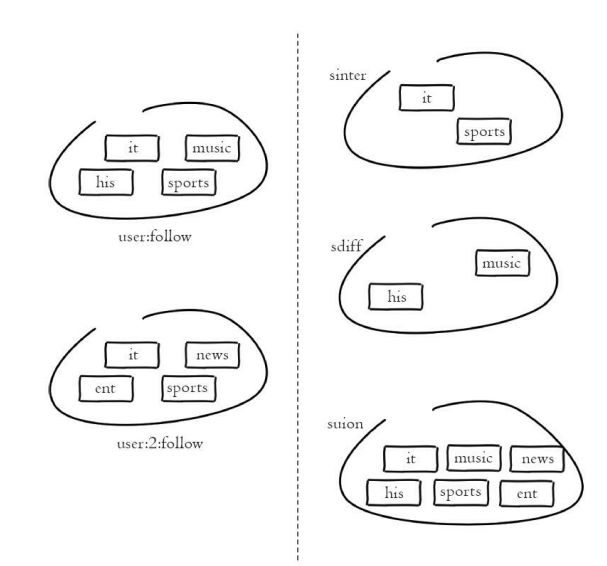
集合求交集、并集、差集
--现在有两个集合,它们分别是user:1:follow和user:2:follow
192.168.49.171:6392> sadd user:1:follow it music sprots his
(integer) 4
192.168.49.171:6392> sadd user:2:follow it news sprots ent
(integer) 4
192.168.49.171:6392> sinter user:1:follow user:2:follow --求多个集合的交集
1) "it"
2) "sprots"
192.168.49.171:6392> sunion user:1:follow user:2:follow --求多个集合的并集
1) "ent"
2) "news"
3) "his"
4) "sprots"
5) "it"
6) "music"
192.168.49.171:6392> sdiff user:1:follow user:2:follow --求多个集合的差集
1) "music"
2) "his"
192.168.49.171:6392>
将交集、并集、差集的结果保存
sinterstore destination key [key …] suionstore destination key [key …] sdiffstore destination key [key …]
192.168.49.171:6392> sinterstore user:1_2:inter user:1:follow user:2:follow
(integer) 2
192.168.49.171:6392> smembers user:1_2:inter
1) "it"
2) "sprots"
192.168.49.171:6392>
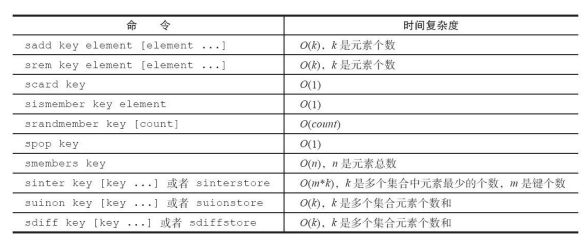
集合常用命令时间复杂度
2.4.2 使用场景
集合类型比较典型的使用场景是标签(tag)例如一个用户可能对娱 乐、体育比较感兴趣,另一个用户可能对历史、新闻比较感兴趣,这些兴趣 点就是标签。有了这些数据就可以得到喜欢同一个标签的人,以及用户的共 同喜好的标签,这些数据对于用户体验以及增强用户黏度比较重要。例如一 个电子商务的网站会对不同标签的用户做不同类型的推荐,比如对数码产品 比较感兴趣的人,在各个页面或者通过邮件的形式给他们推荐最新的数码产 品,通常会为网站带来更多的利益。
- 集合类型的应用场景通常为以下几种:
- sadd=Tagging(标签)
- spop/srandmember=Random item(生成随机数,比如抽奖)
- sadd sinter=Social Graph(社交需求)
2.5 有序集合
有序集合相对于哈希、列表、集合来说会有一点点陌生,但既然叫有序集合,那么它和集合必然有着联系,它保留了集合不能有重复成员的特性, 但不同的是,有序集合中的元素可以排序。但是它和列表使用索引下标作为 排序依据不同的是,它给每个元素设置一个分数(score)作为排序的依据。
下图所示,该有序集合包含kris、mike、frank、tim、martin、tom, 它们的分数分别是1、91、200、220、250、251,有序集合提供了获取指定 分数和元素范围查询、计算成员排名等功能,合理的利用有序集合,能帮助 我们在实际开发中解决很多问题。
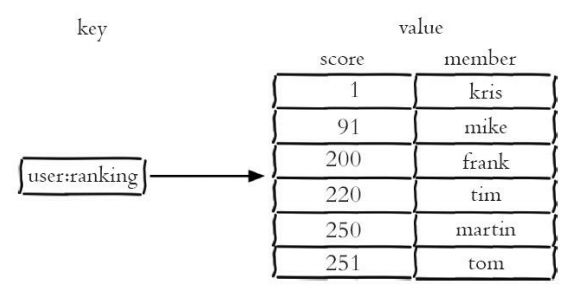
有序集合中的元素不能重复,但是score可以重复
*列表、集合和有序集合三者的异同点

2.5.1 命令
- 集合内操作
192.168.49.171:6392> zadd user:ranking 1 kris 91 mike 200 frank 220 tim 250 martin --往user:ranking 添加成员
(integer) 5
192.168.49.171:6392> zcard user:ranking --计算有多少成员
(integer) 5
192.168.49.171:6392> zscore user:ranking mike --计算某个成员的分数
"91"
192.168.49.171:6392> zrank user:ranking frank --计算成员的排名,zrank是从分数从低到高返回排名,zrevrank反之。
(integer) 2
192.168.49.171:6392> zrem user:ranking frank --删除成员
(integer) 1
192.168.49.171:6392> zincrby user:ranking 9 mike --增加成员的分数
"100"
192.168.49.171:6392> zrange user:ranking 0 2 withscores --返回指定排名范围的成员,zrange是从低到高返回,zrevrange反之
1) "kris"
2) "1"
3) "mike"
4) "100"
5) "tim"
6) "220"
192.168.49.171:6392> zrevrange user:ranking 0 2 withscores
1) "martin"
2) "250"
3) "tim"
4) "220"
5) "mike"
6) "100"
192.168.49.171:6392> zrange user:ranking 0 -1 withscores --获取全部成员
1) "kris"
2) "1"
3) "mike"
4) "100"
5) "tim"
6) "220"
7) "martin"
8) "250"
192.168.49.171:6392> zrangebyscore user:ranking 0 200 withscores --返回指定分数范围的成员,中zrangebyscore按照分数从低到高返回,zrevrangebyscore反之,withscores选项会同时返回每个成员的分数
1) "kris"
2) "1"
3) "mike"
4) "100"
192.168.49.171:6392> zrangebyscore user:ranking 200 251 withscores
1) "tim"
2) "220"
3) "martin"
4) "250"
192.168.49.171:6392> zrevrangebyscore user:ranking 251 200 withscores
1) "martin"
2) "250"
3) "tim"
4) "220"
192.168.49.171:6392> zrangebyscore user:ranking 30 inf withscores --同时min和max还支持开区间(小括号)和闭区间(中括号),-inf和 inf分别代表无限小和无限大
1) "mike"
2) "100"
3) "tim"
4) "220"
5) "martin"
6) "250"
192.168.49.171:6392> zrangebyscore user:ranking -inf 110 withscores
1) "kris"
2) "1"
3) "mike"
4) "100"
192.168.49.171:6392> zcount user:ranking 200 221 --返回指定分数范围成员个数
(integer) 1
192.168.49.171:6392> zremrangebyrank user:ranking 0 2 --删除指定排名内的升序元素
(integer) 3
192.168.49.171:6392> zrange user:ranking 0 -1 withscores
1) "martin"
2) "250"
192.168.49.171:6392> zremrangebyscore user:ranking (240 inf --删除指定排名内的升序元素
(integer) 1
192.168.49.171:6392> zremrangebyrank user:ranking 0 -1
(integer) 0
192.168.49.171:6392>
- 集合间操作
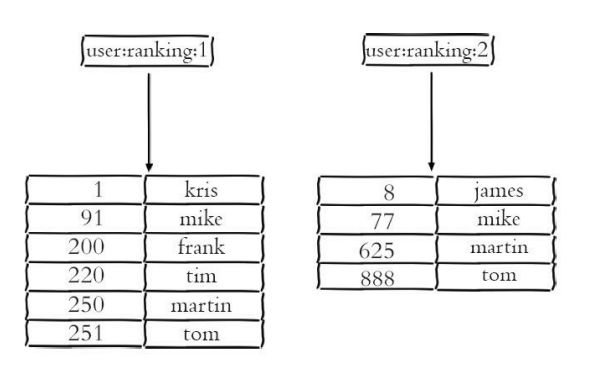
(1)交集
zinterstore destination numkeys key [key …] [weights weight [weight …]] [aggregate sum|min|max]
- 命令参数说明:
- destination:交集计算结果保存到这个键。
- numkeys:需要做交集计算键的个数。
- key[key…]:需要做交集计算的键。
- weights weight[weight…]:每个键的权重,在做交集计算时,每个键中 的每个member会将自己分数乘以这个权重,每个键的权重默认是1。
- aggregate sum|min|max:计算成员交集后,分值可以按照sum(和)、 min(最小值)、max(最大值)做汇总,默认值是sum。
192.168.49.171:6392> zadd user:ranking:1 1 kris 91 mike 200 frank 220 tim 250 martin 251 tom
(integer) 6
192.168.49.171:6392> zadd user:ranking:2 8 james 77 mike 625 martin 888 tom
(integer) 4
192.168.49.171:6392> zinterstore user:ranking:1_inter_2 2 user:ranking:1 user:ranking:2 --到目标键user:ranking:1_inter_2对分值 做了sum操作
(integer) 3
192.168.49.171:6392> zrange user:ranking:1_inter_2 0 -1 withscores
1) "mike"
2) "168"
3) "martin"
4) "875"
5) "tom"
6) "1139"
192.168.49.171:6392> zinterstore user:ranking:1_inter_2 2 user:ranking:1 user:ranking:2 weights 1 0.5 aggregate max --让user:ranking:2的权重变为0.5,并且聚合效果使用max
(integer) 3
192.168.49.171:6392> zrange user:ranking:1_inter_2 0 -1 withscores
1) "mike"
2) "91"
3) "martin"
4) "312.5"
5) "tom"
6) "444"
192.168.49.171:6392>
(2)并集
zunionstore destination numkeys key [key …] [weights weight [weight …]] [aggregate sum|min|max]
该命令的所有参数和zinterstore是一致的,只不过是做并集计算
192.168.49.171:6392> zunionstore user:ranking:1_union_2 2 user:ranking:1 user:ranking:2
(integer) 7
192.168.49.171:6392> zrange user:ranking:1_union_2 0 -1 withscores
1) "kris"
2) "1"
3) "james"
4) "8"
5) "mike"
6) "168"
7) "frank"
8) "200"
9) "tim"
10) "220"
11) "martin"
12) "875"
13) "tom"
14) "1139"
192.168.49.171:6392>
有序集合命令的时间复杂度
有序集合命令的时间复杂度
2.5.2 使用场景
有序集合比较典型的使用场景就是排行榜系统,例如视频网站需要对用 户上传的视频做排行榜,榜单的维度可能是多个方面的:按照时间、按照播 放数量、按照获得的赞数。本节使用赞数这个维度,记录每天用户上传视频的排行榜
2.6 键管理
2.6.1 单个键管理
- 键重命名
192.168.49.171:6392> set python jedis
OK
192.168.49.171:6392> get python
"jedis"
192.168.49.171:6392> rename python java
OK
192.168.49.171:6392> get java
"jedis"
如果在rename之前,键java已经存在,那么它的值也将被覆盖
192.168.49.171:6392> set a b
OK
192.168.49.171:6392> set c d
OK
192.168.49.171:6392> rename a c
OK
192.168.49.171:6392> get a
(nil)
192.168.49.171:6392> get c
"b"
为了防止被强行rename,Redis提供了renamenx命令,确保只有newKey 不存在时候才被覆盖
192.168.49.171:6392> get java
"jedis"
192.168.49.171:6392> set python redis-py
OK
192.168.49.171:6392> renamenx java python --操作renamenx时,newkey=python已经存在, 返回结果是0代表没有完成重命名,所以键java和python的值没变
(integer) 0
192.168.49.171:6392> get java
"jedis"
192.168.49.171:6392> get python
"redis-py"
- 重命名命令时,有两点需要注意:
- 由于重命名键期间会执行del命令删除旧的键,如果键对应的值比较 大,会存在阻塞Redis的可能性,这点不要忽视
- 如果rename和renamenx中的key和newkey如果是相同的,在Redis3.2和之 前版本返回结果略有不同(Redis3.2中会返回OK,Redis3.2之前的版本会提示错误)
* 随机返回一个键
192.168.49.171:6392> dbsize
(integer) 27
192.168.49.171:6392> randomkey
"java"
192.168.49.171:6392> randomkey
"user:ranking:1_union_2"
192.168.49.171:6392> randomkey
"incrfloat"
- 迁移键
move-内部迁移
192.168.49.171:6392> move midou 1 --迁移1号数据库
(integer) 1
192.168.49.171:6392> select 1 --切换到1号数据库
OK
192.168.49.171:6392[1]> get midou
"\xe8\xb2\x94\xe8\xb2\x85"
192.168.49.171:6392[1]>
dump restore可以实现在不同的Redis实例之间进行数据迁移的功能
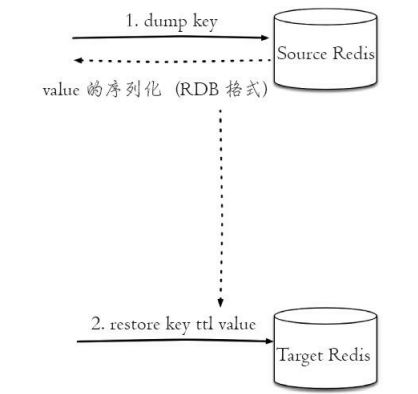
--在源Redis上执行dump:
192.168.49.171:6392> dump python
"\x00\bredis-py\a\x00\xb3o\xc2\xdf\xf5P\xf9@"
--在目标Redis上执行restore:
192.168.49.171:6393> restore python 0 "\x00\bredis-py\a\x00\xb3o\xc2\xdf\xf5P\xf9@"
OK
192.168.49.171:6393> get python
"redis-py"
migrate命令也是用于在Redis实例间进行数据迁移的,实际上migrate命 令就是将dump、restore、del三个命令进行组合
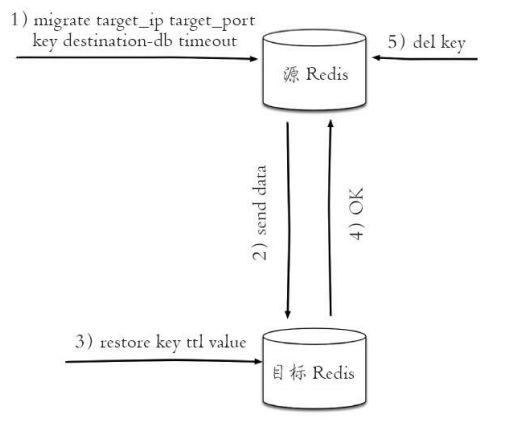
- migrate的参数说明
- host:目标Redis的IP地址。
- port:目标Redis的端口。
- key|"":在Redis3.0.6版本之前,migrate只支持迁移一个键,所以此处是 要迁移的键,但Redis3.0.6版本之后支持迁移多个键,如果当前需要迁移多个键,此处为空字符串""。
- destination-db:目标Redis的数据库索引,例如要迁移到0号数据库,这里就写0。
- timeout:迁移的超时时间(单位为毫秒)。
- [copy]:如果添加此选项,迁移后并不删除源键。
- [replace]:如果添加此选项,migrate不管目标Redis是否存在该键都会 正常迁移进行数据覆盖。
- [keys key[key…]]:迁移多个键,例如要迁移key1、key2、key3,此处填 写“keys key1 key2 key3”。
情况1:源Redis有键hello,目标Redis没有
192.168.49.171:6392> get python
"redis-py"
192.168.49.171:6392> get baobao
"jiaomidoushihuaidan"
192.168.49.171:6392> migrate 192.168.49.171 6393 baobao 0 1000
OK
--目标Redis
192.168.49.171:6393> get baobao
(nil)
192.168.49.171:6393> get baobao
"jiaomidoushihuaidan"
情况2:源Redis和目标Redis都有键hello
--源Redis
192.168.49.171:6392> get hello
"world"
192.168.49.171:6392> migrate 192.168.49.171 6393 hello 0 1000 --如果migrate命令没有加replace选项会收到错误提示,如果加了replace会 返回OK表明迁移成功:
(error) ERR Target instance replied with error: BUSYKEY Target key name already exists.
192.168.49.171:6392> migrate 192.168.49.171 6393 hello 0 1000 replace
OK
--目标Redis
192.168.49.171:6393> get hello
"xxxxx"
192.168.49.171:6393> get hello
"world"
情况3:源Redis没有键hello。如下所示,此种情况会收到nokey的提示
192.168.49.171:6392> migrate 192.168.49.171 6393 hello_2 0 1000 replace --源Redis没有键hello,会收到nokey的提示
NOKEY
192.168.49.171:6392> mset key1 value1 key2 value2 key3 value3 --源Redis批量添加多个键
OK
192.168.49.171:6392> migrate 192.168.49.171 6393 "" 0 1000 keys key1 key2 key3 --源Redis执行如下命令完成多个键的迁移
OK
192.168.49.171:6392>
--目标Redis
192.168.49.171:6393> mget key1 key2 key3
1) "value1"
2) "value2"
3) "value3"
192.168.49.171:6393>
- move、dump restore、migrate三个命令比较
2.6.2 遍历键
-
全量遍历键
-
获取所有的键,可以使用keys pattern命令,pattern使用的 是glob风格的通配符:
*代表匹配任意字符。- '-'代表匹配一个字符。
- []代表匹配部分字符,例如[1,3]代表匹配1,3,[1-10]代表匹配1到10 的任意数字。
- \x用来做转义,例如要匹配星号、问号需要进行转义。
192.168.49.171:6392> dbsize
(integer) 24
192.168.49.171:6392> keys *
1) "xiaomidou"
2) "dianji"
3) "db"
4) "mykey"
5) "decrkey"
6) "mkkey"
7) "d"
8) "redis"
9) "user:1:follow"
10) "e"
11) "listkey"
12) "b"
13) "assemble"
14) "user:1_2:inter"
15) "user:ranking:1_inter_2"
16) "user:ranking:2"
17) "java"
18) "user:2:follow"
19) "midou_list"
20) "user:ranking:1"
21) "user:ranking:1_union_2"
22) "incrfloat"
23) "python"
24) "c"
192.168.49.171:6392> keys user:ranking:[1,2]
1) "user:ranking:2"
2) "user:ranking:1"
192.168.49.171:6392> keys list*ey
1) "listkey"
192.168.49.171:6392> keys m*
1) "mykey"
2) "mkkey"
3) "midou_list"
当需要遍历所有键时,例如想删除所有以m字符串开头的键,可以执行:redis-cli keys m* | xargs redis-cli del
-
如果Redis包含了大量的键,执行keys命令很可能会造成Redis阻塞,所以一般建议不要在生 产环境下使用keys命令。但有时候确实有遍历键的需求该怎么办,可以在以 下三种情况使用:
- 在一个不对外提供服务的Redis从节点上执行,这样不会阻塞到客户端 的请求,但是会影响到主从复制
- 如果确认键值总数确实比较少,可以执行该命令。
- 使用下面要介绍的scan命令渐进式的遍历所有键,可以有效防止阻 塞。
-
渐进式遍历
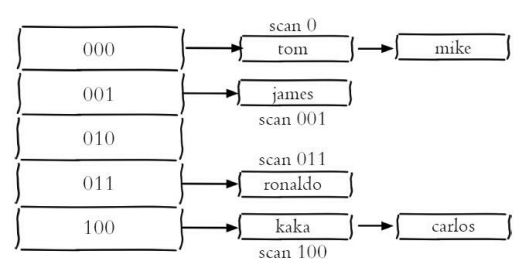
scan命令,它能有效的解决keys命 令存在的问题。和keys命令执行时会遍历所有键不同,scan采用渐进式遍历 的方式来解决keys命令可能带来的阻塞问题,每次scan命令的时间复杂度是 O(1),但是要真正实现keys的功能,需要执行多次scan。Redis存储键值对 实际使用的是hashtable的数据结构,其简化模型如图
scan cursor [match pattern] [count number]
- scan的用法:
- cursor是必需参数,实际上cursor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
- match pattern是可选参数,它的作用的是做模式的匹配,这点和keys的模式匹配很像。
- count number是可选参数,它的作用是表明每次要遍历的键个数,默认值是10,此参数可以适当增大。
192.168.49.171:6392> scan 0 --第一次执行scan 0,返回结果分为两个部分:第一个部分26就是下次scan需要的cursor,第二个部分是10个键
1) "26"
2) 1) "xiaomidou"
2) "dianji"
3) "user:ranking:1"
4) "mkkey"
5) "assemble"
6) "python"
7) "mykey"
8) "user:ranking:1_inter_2"
9) "listkey"
10) "b"
192.168.49.171:6392> scan 26
1) "29"
2) 1) "incrfloat"
2) "d"
3) "redis"
4) "java"
5) "user:2:follow"
6) "db"
7) "e"
8) "user:ranking:1_union_2"
9) "user:ranking:2"
10) "user:1_2:inter"
192.168.49.171:6392> scan 29 --这次得到的cursor="29",继续执行scan11得到结果cursor变为0,说明所有的键已经被遍历过了
1) "0"
2) 1) "decrkey"
2) "user:1:follow"
3) "midou_list"
4) "c"
192.168.49.171:6392>
除了scan以外,Redis提供了面向哈希类型、集合类型、有序集合的扫 描遍历命令,解决诸如hgetall、smembers、zrange可能产生的阻塞问题,对 应的命令分别是hscan、sscan、zscan,它们的用法和scan基本类似
2.6.3 数据库管理
- 使用select命令切换数据库
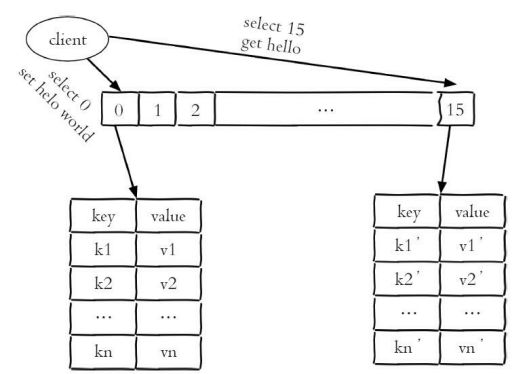
192.168.49.171:6392> select 1 #切换到1号数据库 OK
OK
192.168.49.171:6392[1]> dbsize
(integer) 1
192.168.49.171:6392[1]> keys *
1) "midou"
192.168.49.171:6392[1]> get midou
"\xe8\xb2\x94\xe8\xb2\x85"
- flushdb/flushall
flushdb/flushall命令用于清除数据库,两者的区别的是flushdb只清除当 前数据库,flushall会清除所有数据库。
192.168.49.171:6392[1]> flushdb --如果在1号数据库执行flushdb,0号数据库的数据依然还在
OK
192.168.49.171:6392[1]> keys *
(empty list or set)
192.168.49.171:6392[1]> dbsize
(integer) 0
192.168.49.171:6392[1]> flushall -在任意数据库执行flushall会将所有数据库清除
OK
192.168.49.171:6392[1]> select 0
OK
192.168.49.171:6392> dbsize
(integer) 0
192.168.49.171:6392>
- flushdb/flushall命令可以非常方便的清理数据,但是也带来两个问题:
- flushdb/flushall命令会将所有数据清除,一旦误操作后果不堪设想
- 如果当前数据库键值数量比较多,flushdb/flushall存在阻塞Redis的可能 性。所以在使用flushdb/flushall一定要小心谨慎。